Mockun_JPNと申します。ITコンサルタント/エンジニアとして活動しています。肩書は仕事内容や相手によって使い分けてます。IT、旅行、投資が好きです。アイコンは妻が描いたカワウソです。
以下の記事の最初の一文に共感したので、自分も書いてみることにしました。
公営競技を題材にGCPを勉強する
直接的にお金が絡まないと中々やる気が出ないため、公営競技を題材にしてGCPをざっくり勉強する。
この記事について
Google Cloud Platformについて、COURSERAで学んだ内容を使ってみようと思い立って作ったFX自動取引システムについての記事です。主にGCPのサービスを組み合わせればこんなこともできるよ、というアーキテクチャ寄りの内容になっています。
売買判定には、Scikit-learn、XGBoost、Optunaなどのライブラリを使った簡易な機械学習を用いていますが、この記事では深くは触れません。FXに機械学習を適用するという試みについては、新米データサイエンティストのFXブログが非常に参考になります。
Googleスライド版資料
発表用に作った資料はこちら。お仕事募集も書いてますので、気になる方がいればぜひ。
https://docs.google.com/presentation/d/1y6gLYuHFGN6Xv9GYFh7LgD14k0Ek0Ve-5_Z8qtVfF_g/edit?usp=sharing
システム全体像
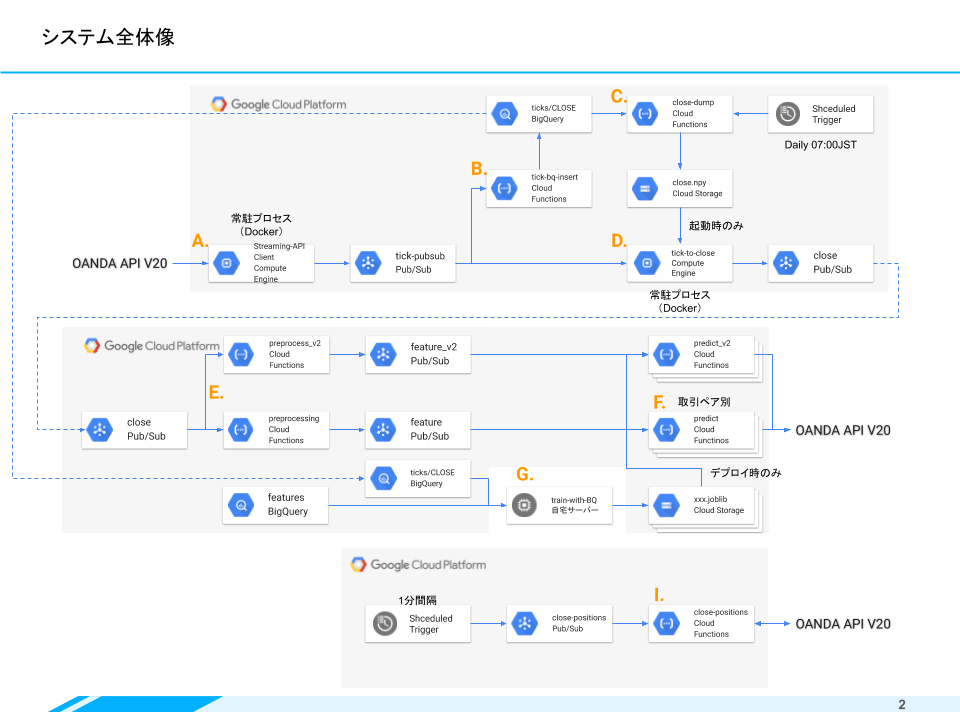
全体の構成として、価格取得(図中上段)、発注(図中中段)、ポジション(図中下段)となっています。レートを取得し、ポジションをオープン、クローズしているだけなので、自動売買としては非常にシンプルな構成です。図を見れば分かる通り、お気に入りのパターンはPub/Sub + Functionsです。Pub/Subを介してFunctionsをつなげていくことで、全体のデータフローを構築しました。
価格取得
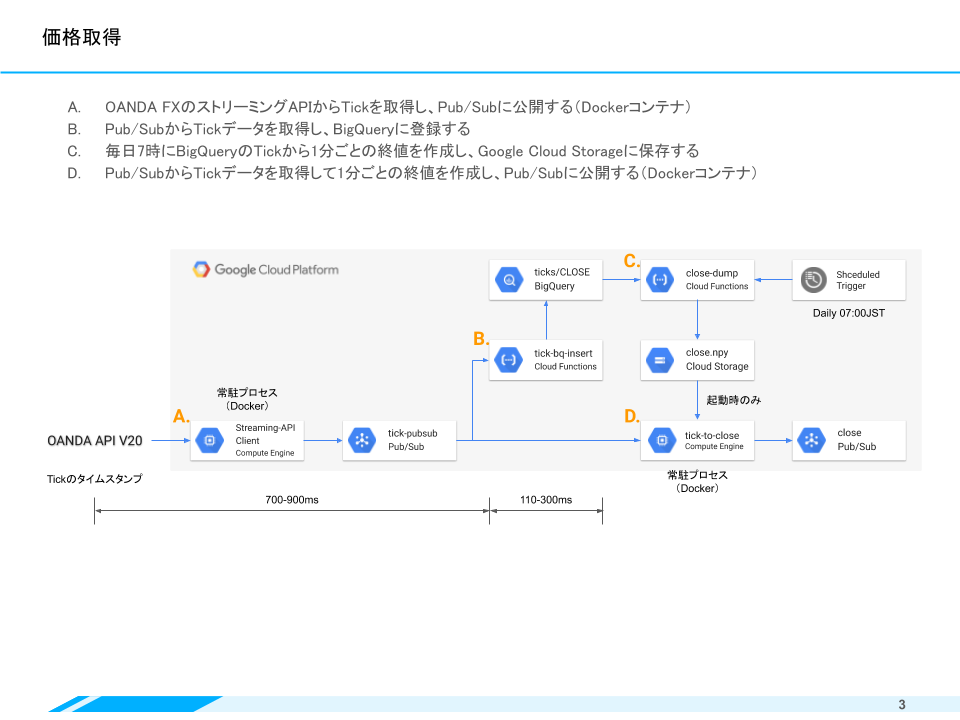
自動取引のインプットとして、まず思い浮かぶのは取引対象の価格データだと思います。リアルタイム(ストリーム)で提供されるTickデータをこのシステムに引き込む常駐プロセス(A)、分析・モデル学習用データを蓄積するBigQueryへのInser処理(B)、ファイルとしてバックアップする処理(C)、TickデータをN分足やM時間足に変換する処理(D)で構成されるのが、価格取得の領域です。
ここには、Tickデータを取得するための(A)と、そのTickデータを一定期間蓄積して「足」に変換する(D)の2つの常駐プロセスがあります。逆に他の領域には、常駐プロセスは存在しません。Tickと「足」の完成をイベントとして捉えることができれば、あとはそれに反応していければ良いわけです。
発注(ポジションのオープン)
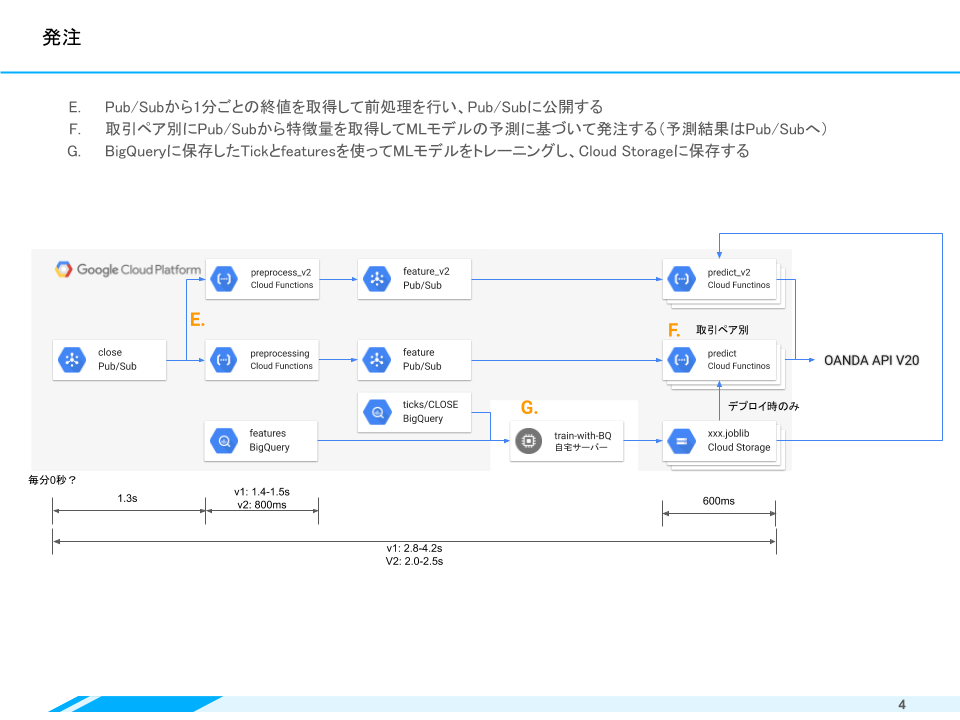
一定期間の価格情報のサマリである「足」が完成したら、Pub/Subを通じて発注処理に対象データが引き渡されてきます。価格データを予測モデルのインプットとなるよう変換する前処理(E)をした上で、通過ペアごとの売買判定モデル(F)に引き継いでいきます。
図中(E)を見ると上下に分岐していることがわかると思います。このケースでは、前処理や予測モデルを追加、変更(v1→v2)する際に、同一データを異なる後続処理に流しています。このように、Pub/Sub + Functionsを組み合わせることで、フローを分岐させるのが容易な構造にできます。
前処理(E)と予測(F)の検証とモデル構築を行う処理として、JupyterLab(G)を自宅サーバーに構築しています。当初は自宅サーバーで休みなくパラメータチューニングや学習を行っていましたが、7月後半となり、暑くなってきたので、こちらもGCPに移行していくことを検討しています。
ポジション管理(ポジションのクローズ)
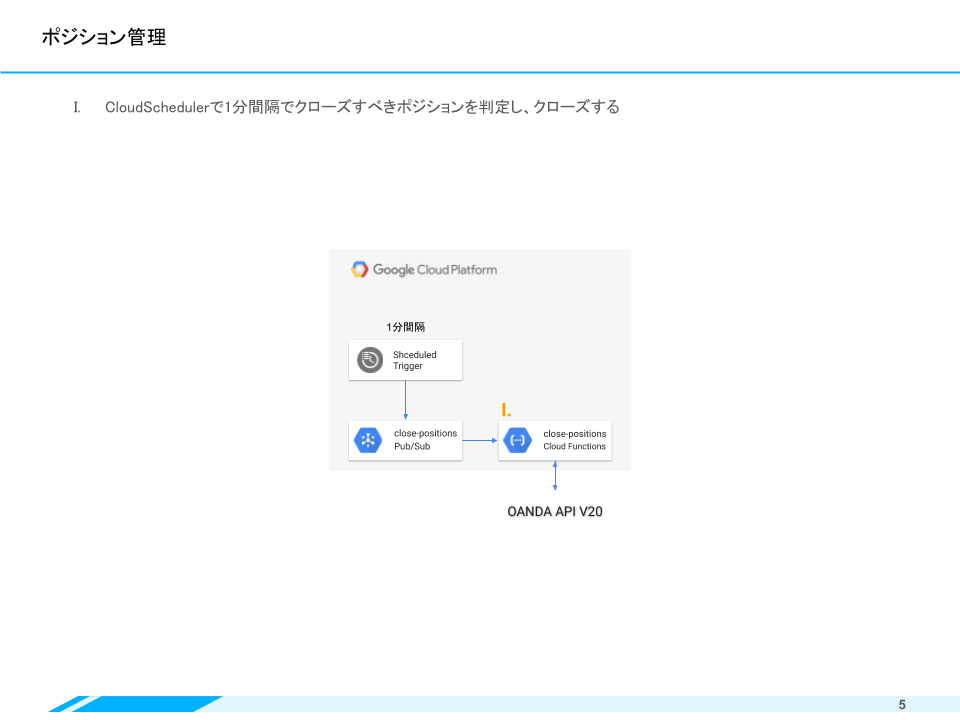
ポジション管理、と言っても一定ルールでポジションをクローズしているだけなのですが、ここもCloud Functionsで実現しています。1分に一度の間隔で処理するため、Cloud SchedulerからPub/Sub経由でFunctionsを起動しています。
感想
自動取引システムを構築するにあたって、意識したポイントは以下の通りです。
- サーバーレスを多用することでインフラ管理の手間を抑える
- 稼働後のデータフローの変更が可能なように処理をPub/Subで疎結合(?)にする
- データ処理はCloud Functionsで処理する
- 取得したデータは後から使えるようにTickデータをBigQueryに蓄積する
インフラにこだわり始めると際限なく改善点が出てくるので、サーバーレスという制約をつけることで、アプリケーションのロジックに集中するように意識しました。できる限りPub/SubとFunctionsで実現することを考えましたが、(A)と(D)の2つは、イベント起動にできませんでした。
サーバーレスは自分の中で確固たる定義があるわけではないのですが、個人的な感覚としては、「OSやミドルを操作している感覚がないこと」だと思っています。今回、処理を非同期に繋いでいくPub/SubとFunctionsを使えたのは非常に良かったと思います。