オープンな化合物データを入手元として最も手軽なのは、主に論文等から収集されたデータを収録しているChEMBLやPubChemなどの公共データベースを利用する方法でした1。一方で、企業等が新薬の候補として創出した化合物の情報は特許として公開される場合が多く、これらの多くは先述の公共データベースには一部しか収録されていません。そこで、この記事では特許から化合物情報を取得する場合のノウハウについて、解説します。
なお、この記事は、創薬 (dry) Advent Calendar 2019 の3日目の記事です。
SureChEMBLを使って化合物の特許を検索する
SureChEMBLは、ChEMBLと同じくEBI (European Bioinformatics Institute)によって運営されている化合物の特許情報を集めたデータベースです。キーワードや構造式で特許とそこに紐付いた化合物の情報を検索・取得できます。特許の文章と図表はPDF、化合物の構造はSMILESを含むCSVの形式でダウンロードできます。
CheMBLが手動のキュレーションで化合物を収録しているのに対して、SureChEMBLは非常に強力なツールではありますが、人手でキュレーションされているChEMBLと比べると、OCRに頼っているようです。具体的には、(1)図表に含まれる構造式をOCRで読み取る方法と、(2)テキストをOCRで読み取って、そこに含まれるIUPAC名から構造を取得する方法の2通りの方法で、構造情報を取得しているものと思われます。OCRの読み取りエラーのせいで、PDF中に記載のある化合物の情報がCSVに含まれていないことが非常に多いです。また、一応、認識はできたものの、読み取りが不完全で誤ったSMILESが生成されているケースも散見されます。
したがって、きちんとした解析を行う場合には、SureChEMBLの中では最も信用できる生のデータであるPDFを基本として、ある程度手作業で構造情報を取得・修正していく工程が必要になってきます。
構造式のOCRツール OSRA
PDF中の構造式からSMILESを取得するのに便利なのは、OSRAというオープンソースの構造式OCRツールです。コマンドラインで動作するツールですが、webインターフェースも提供されています2。
このツールを利用しても当然、読み取りエラーは起こります。その例を見てみましょう。
特許PDFに記載された構造式 (US-20180057486-A1 Example19)
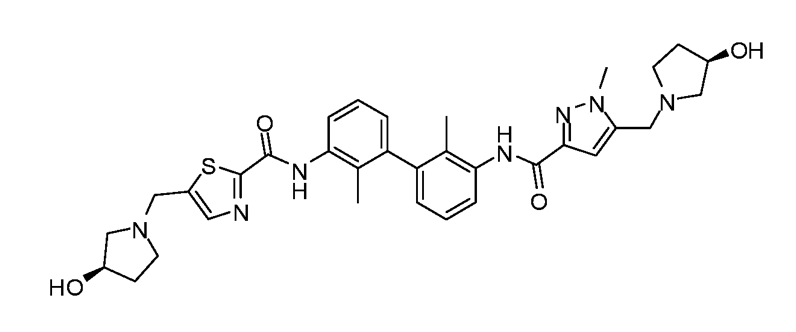
OSRAでの読み取り結果
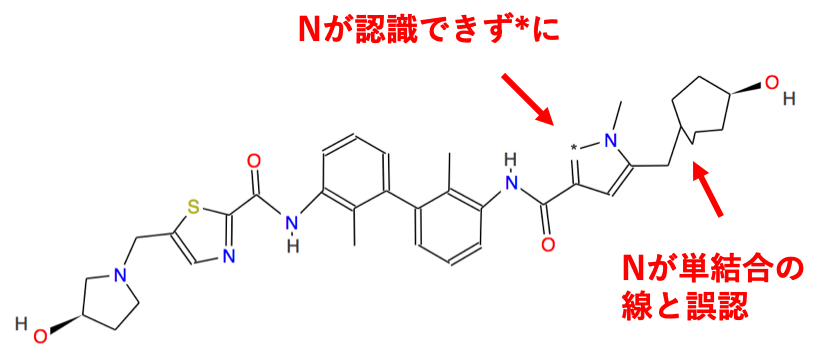
このように大部分は正しく読み取れていますが、ところどころにエラーがあります。このようなエラーを探すのはかなり神経を使う作業ではありますが、幸いOSRAのwebインターフェースでは、GUIで構造式を修正することができますし、0から構造式を入力するよりはましという印象です。
IUPAC名をSMILESに変換できるツール OPSIN
特許によっては、化合物がIUPAC名で記載されている場合があります。OPSINというツールを使えば、ここからSMILESを生成することができます。
ただし、ここで注意しなければいけないのは、SureChEMLのPDFに埋め込まれたテキスト情報自体がOCRで生成されたもので、間違いを含んでいる場合があることです。
PDFに埋め込まれたIUPAC名の読み取りエラーの例 (WO-2018013789-A1 Example 1)
(2S)-l-[(l-methyl-5-{ [(2-methylbiphenyl-3-yl)amino]carbonyl}-6-oxo-l,6-
dihydropyridin-3-yl)methyl] piperidine-2-carboxylic acid
修正結果
(2S)-1-[(1-methyl-5-{ [(2-methylbiphenyl-3-yl)amino]carbonyl}-6-oxo-1,6- dihydropyridin-3-yl)methyl] piperidine-2-carboxylic acid
ほぼ同一に見えますが、上のエラー例では数字の1が、アルファベッドのLの小文字になっています。SureChEMBLのPDFには、多くの場合、画像としてスキャンされた特許文書の情報が残っていてこちらは基本的に正確ですから、PDFを目視で確認しつつ、OPSINでエラーが出ないvalidなIUPAC名に修正していく作業をしていくことになります。
特許情報からの化合物データ収集の課題
SureChEMBLに収録された特許PDFの図表とテキストから構造情報を半手動で取得する方法について紹介しました。オープンソースツールによって一部が自動化されているとはいえ、かなり骨の折れる作業には違いありません。場合によっては、特許化合物が収録された商用データベースを利用した方がいいこともあるのでしょう。
また、特許には化合物を対象にしたアッセイの結果も掲載されていることが多いですが、このような情報は個別の化合物と紐づく形ではSureChEMBLに収録されていません。したがって、教師あり学習の訓練データを作るためには、現状では人間がPDFを読解して手作業で化合物とそのラベルの対応つけるしかなさそうです。
ちなみに、この記事は、私が創薬レイドバトル 2018のために、PD-1/PD-L1阻害剤のデータセットを作成した際の手順を整理したものです。もっと良い方法があるかもしれませんし、もしそれをご存じの方がいたらコメントをいただければ幸いです。