こんにちにゃんです。
水色桜(みずいろさくら)です。
今回はJGLUEのMARC-ja(negative or positiveの二値分類タスク)でLUKEをファインチューニングしてみようと思います。
今回作成したモデルはこちら(hugging face)で公開しています。
サンプルコードも用意してあるので、ぜひ用いてみてください。
もし記事中で不明な点や間違いなどありましたら、コメントもしくはTwitter(@Mizuiro__sakura)までお寄せいただけると嬉しいです。
LUKE

2020年4月当時、5つのタスクで世界最高精度を達成した新しい言語モデル。
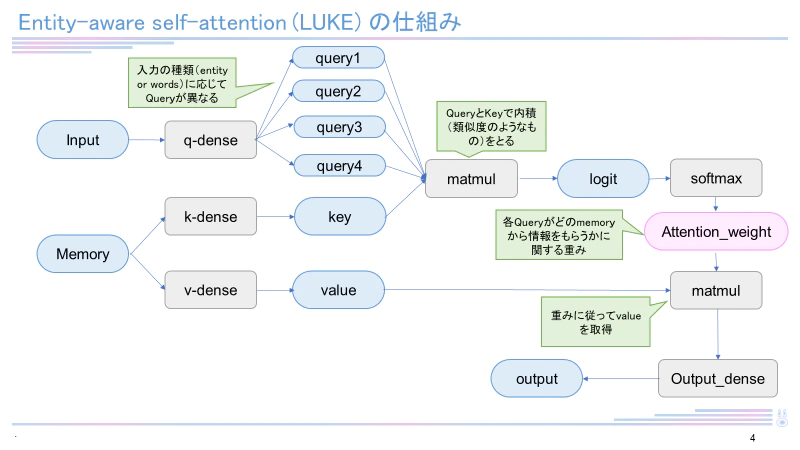
日本語バージョンのLUKE-baseモデルは執筆現在(2022年12月)も4つのタスク(MARC-ja, JSTS, JNLI, JCommonsenseQA)で最高スコアを有しています。LUKEはRoBERTaを元として構成され、entity-aware self-attentionという独自のメカニズムを用いています。LUKEに関して詳しくは下記記事をご覧ください。
JGLUE
yahoo JAPAN株式会社さんと早稲田大学河原研究室の共同研究で構築された、日本語言語理解ベンチマーク。言語モデルの包括的な評価のために作成されました。各データはクラウドソーシングにより収集されています。評価データの種類はMARC-ja(二値分類タスク)、JSTS(文章の類似度計算)、JNLI(文章の関係性判別)、JSQuAD(抜き出し型のQAタスク)、JCommonsenseQA(常識を問う5択の選択問題)があります。
環境
pandas 1.4.4
numpy 1.23.4
torch 1.12.1
transformer 4.24.0
Python 3.9.13
sentencepiece 0.1.97
準備(ライブラリのインストール)
pip install transformers
pip install sentencepiece
データのロード
今回は @shunk031 さんが公開しているHuggingface datasets版のJGLUEを用いました。以下のコードを用いてJGLUE/MARC-jaをダウンロードして、ファイルに保存しました。
from datasets import load_dataset
dataset = load_dataset("shunk031/JGLUE", name="MARC-ja")
print(dataset['validation'])
with open('marcja_valid.txt', 'w', encoding='utf-8') as f:
for i in range(len(dataset['validation'])):
f.write(str(dataset['validation'][i]))
print(dataset['train'])
with open('marcja_train.txt', 'w', encoding='utf-8') as f:
for i in range(len(dataset['train'])):
f.write(str(dataset['train'][i]))
学習
以下のコードを用いて学習を行いました。
import pandas as pd
import json
# marc-jaの読み込み
with open("marcja_train.txt", 'r', encoding='utf-8') as f:
dataset_t=f.read().split('}{')
for i in range(len(dataset_t)):
dataset_t[i]=dataset_t[i].replace('{','')
dataset_t[i]=dataset_t[i].replace('}','')
with open("marcja_valid.txt", 'r', encoding='utf-8') as g:
dataset_v=g.read().split('}{')
for i in range(len(dataset_v)):
dataset_v[i]=dataset_v[i].replace('{','')
dataset_v[i]=dataset_v[i].replace('}','')
# dictからdataframeに変換
train_df = pd.DataFrame.from_dict(dataset_t)
val_df = pd.DataFrame.from_dict(dataset_v)
all_df = pd.concat([train_df, val_df], ignore_index=True, axis=0)
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("studio-ousia/luke-japanese-base")
from tqdm import tqdm
tqdm.pandas()
# データセットを作成するための下準備
import ast
data_dict=[]
for i in range(len(all_df)):
data_line=ast.literal_eval('{'+all_df[0][i]+'}')
data_dict.append(data_line['sentence'])
max_seq_length = 128
data=tokenizer(
data_dict,
truncation=True,
max_length=max_seq_length,
padding="max_length"
)
import torch
tensor_input_ids = torch.tensor(data["input_ids"])
tensor_attention_masks = torch.tensor(data["attention_mask"])
# 正解データの取得
labels=[]
for i in range(len(all_df)):
data_line=ast.literal_eval('{'+all_df[0][i]+'}')
labels.append(data_line['label'])
tensor_labels = torch.tensor(labels)
import numpy as np
from torch.utils.data import Dataset, Subset
# データセットの作成
class CQADataset(Dataset):
def __init__(self, input,attention,label, is_test=False):
self.input = input
self.attention=attention
self.label=label
self.is_test = is_test
def __getitem__(self, idx):
data = {'input_ids': torch.tensor(self.input[idx])}
data['attention_mask']= torch.tensor(self.attention[idx])
data['label']= torch.tensor(self.label[idx])
return data
def __len__(self):
return len(self.input)
dataset = CQADataset(tensor_input_ids,tensor_attention_masks,tensor_labels)
indices = np.arange(len(dataset))
# 訓練データ、評価データに分割
train_dataset = Subset(dataset, indices[:int(len(train_df)*1.0)])
val_dataset = Subset(dataset, indices[-len(val_df):])
from transformers import AutoModelForSequenceClassification
from transformers import Trainer, TrainingArguments
model=AutoModelForSequenceClassification.from_pretrained("studio-ousia/luke-japanese-base")
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='weighted', zero_division=0)
acc = accuracy_score(labels, preds)
return {
'accuracy': acc,
'precision': precision,
'recall': recall,
'f1': f1,
}
# トレーニングの設定を記述する
training_config = TrainingArguments(
output_dir = 'C://Users//desktop//Python',
num_train_epochs = 5,
per_device_train_batch_size = 32,
per_device_eval_batch_size = 32,
learning_rate = 1e-5,
weight_decay = 0.1,
save_steps = 2900,
evaluation_strategy = "epoch",
do_eval = True
)
# トレーニング
trainer = Trainer(
model = model,
args = training_config,
tokenizer = tokenizer,
train_dataset = train_dataset,
eval_dataset = val_dataset,
compute_metrics = compute_metrics, #compute_metrics
)
trainer.train()
trainer.evaluate()
print('saved')
結果
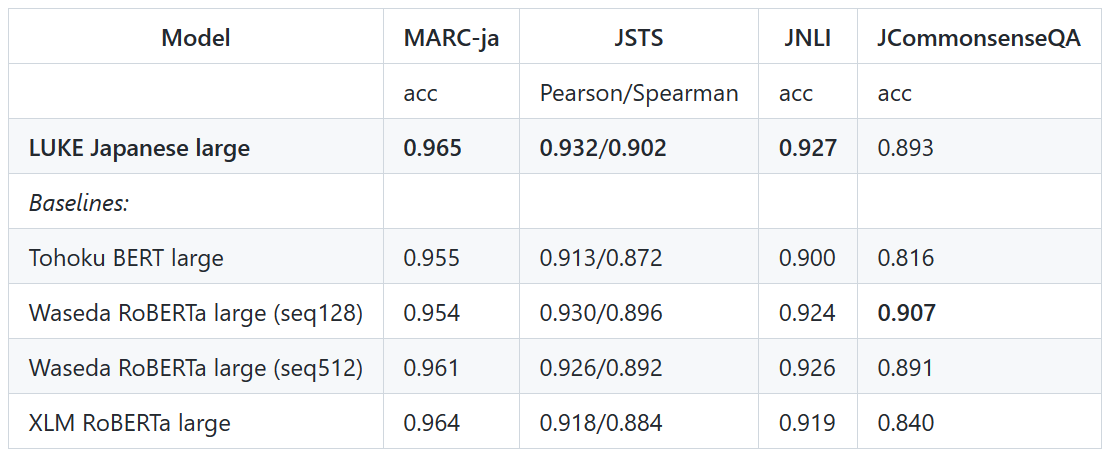
モデルの精度:0.967
参考既存のモデルの精度
推論の実行
以下のサンプルコードを用いることで推論を実行することができます。
初回時にモデルのダウンロードが行われるため、WiFi環境下をお勧めします。
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
tokenizer = AutoTokenizer.from_pretrained('Mizuiro-sakura/luke-japanese-base-marcja')
model = AutoModelForSequenceClassification.from_pretrained('Mizuiro-sakura/luke-japanese-base-marcja')
text = 'この商品は素晴らしい!とても匂いが良く、満足でした。'
token = tokenizer.encode_plus(text, truncation=True, max_length=128, padding="max_length")
result = model(torch.tensor(token['input_ids']).unsqueeze(0), torch.tensor(token['attention_mask']).unsqueeze(0))
if torch.argmax(result['logits'])==0:
print('positive')
if torch.argmax(result['logits'])==1:
print('negative')
終わりに
今回はJGLUE/MARC-jaでLUKEをファインチューニングする方法について書いてきました。
ぜひ参考にしてみてください。
では、ばいにゃん~。