こんにちにゃんです。
水色桜(みずいろさくら)です。
今回は前回までの記事でJCommonsenseQAを解くために作ったluke-japanese-baseのファインチューニングモデルと、deberta-v2-japanese-baseのファインチューニングモデルを利用して、アンサンブルモデルを作成してみました。
手法としては単純にvoting(多数決や学習器の平均をとる手法)を用いました。
アンサンブルモデルの精度は、以下のようになりました。
0.8480786416443361
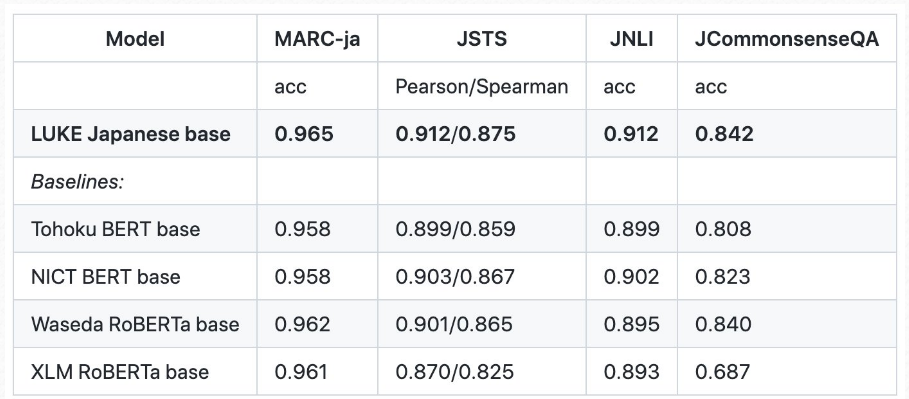
以下の表からもわかる通り、今回作成したアンサンブルbaseモデルは既存のbaseモデルのSOTAを超える性能となりました(個々のモデルの精度は約0.800だったため、まさかSOTAを超えられるとは夢にも思っていませんでした!!)。
参考:既存のbaseモデルの性能(studio ousiaさんのホームページ( https://www.ousia.jp/ja/page/ja/2022/11/17/luke-japanese/ )
より引用)
では使用したコードなどについてみていきます(実装はかなり簡単です)
環境
pandas 1.4.4
numpy 1.23.4
torch 1.12.1
transformer 4.24.0
Python 3.9.13
sentencepiece 0.1.97
LUKE

2020年4月当時、5つのタスクで世界最高精度を達成した新しい言語モデル。
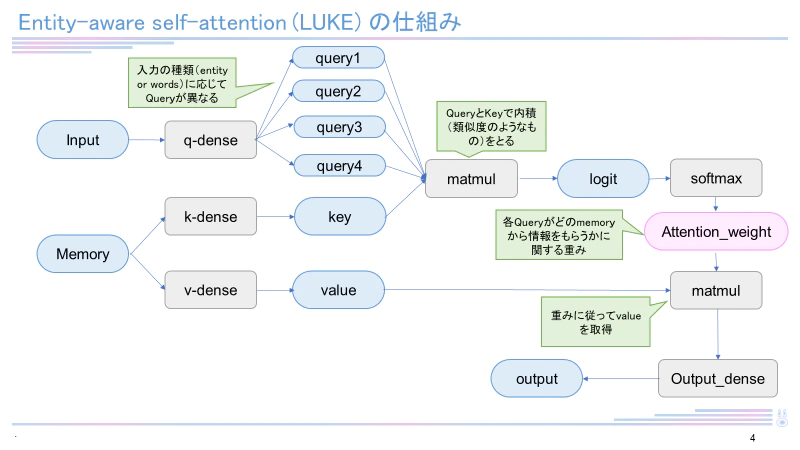
日本語バージョンのLUKE-baseモデルは執筆現在(2022年12月)も4つのタスク(MARC-ja, JSTS, JNLI, JCommonsenseQA)で最高スコアを有しています。LUKEはRoBERTaを元として構成され、entity-aware self-attentionという独自のメカニズムを用いています。LUKEに関して詳しくは下記記事をご覧ください。
deberta-v2-japanese
日本語Wikipedeia(3.2GB)および、cc100(85GB)、oscar(54GB)を用いて訓練されたモデルです。京都大学黒橋研究室が公表されました。
検証に使用したコード
以下のようなコードで精度の検証を行いました。
accuracyは0.848であり、既存のSOTAを超える値となりました(個々のモデルのハイパーパラメータを工夫するともう少し上がるかもしれません)
ensemble.py
from transformers import AutoTokenizer, AutoModelForMultipleChoice
import torch
tokenizer1=AutoTokenizer.from_pretrained('Mizuiro-sakura/deberta-v2-japanese-base-finetuned-commonsenseqa')
model1=AutoModelForMultipleChoice.from_pretrained('Mizuiro-sakura/deberta-v2-japanese-base-finetuned-commonsenseqa')
import pandas as pd
import json
import os
import numpy as np
# JCommonsenseQAの読み込み
dataset_v = [json.loads(line)
for line in open("CommonsenseQA_valid.json", 'r', encoding='utf-8')]
tokenizer2 = AutoTokenizer.from_pretrained('Mizuiro-sakura/luke-japanese-base-commonsenseqa')
model2 = AutoModelForMultipleChoice.from_pretrained('Mizuiro-sakura/luke-japanese-base-commonsenseqa')
acc=0
for i in range(len(dataset_v)):
question=dataset_v[i]['question']
x1=tokenizer1([question,question,question,question,question],[dataset_v[i]['choice0'],dataset_v[i]['choice1'],dataset_v[i]['choice2'],dataset_v[i]['choice3'],dataset_v[i]['choice4']]
,return_tensors='pt',padding=True)
leng=len(x1['input_ids'][0])
X1 = np.empty(shape=(1, 5, leng))
X2 = np.empty(shape=(1, 5, leng))
X1[0, :, :] = x1['input_ids']
X2[0, :, :] = x1['attention_mask']
result_deberta = model1(torch.tensor(X1).to(torch.int64),torch.tensor(X2).to(torch.int64))
question=dataset_v[i]['question']
x1=tokenizer2([question,question,question,question,question],[dataset_v[i]['choice0'],dataset_v[i]['choice1'],dataset_v[i]['choice2'],dataset_v[i]['choice3'],dataset_v[i]['choice4']]
,return_tensors='pt',padding=True)
leng=len(x1['input_ids'][0])
X1 = np.empty(shape=(1, 5, leng))
X2 = np.empty(shape=(1, 5, leng))
X1[0, :, :] = x1['input_ids']
X2[0, :, :] = x1['attention_mask']
result_luke = model2(torch.tensor(X1).to(torch.int64),torch.tensor(X2).to(torch.int64))
results=torch.tensor(result_deberta.logits)+torch.tensor(result_luke.logits)
max_r=torch.argmax(results)
if max_r==dataset_v[i]['label']:
acc=acc+1/len(dataset_v)
print(acc)
実際にモデルを使用してみる
以下のコードを用いることで、アンサンブルモデルによる解析が行えます。
exe.py
from transformers import AutoTokenizer, AutoModelForMultipleChoice
import torch
import numpy as np
# modelのロード
tokenizer1=AutoTokenizer.from_pretrained('Mizuiro-sakura/deberta-v2-japanese-base-finetuned-commonsenseqa')#('Mizuiro-sakura/deberta-v2-base-juman-finetuned-commonsenseqa')
model1=AutoModelForMultipleChoice.from_pretrained('Mizuiro-sakura/deberta-v2-japanese-base-finetuned-commonsenseqa')
tokenizer2 = AutoTokenizer.from_pretrained('Mizuiro-sakura/luke-large-commonsenseqa-japanese')
model2 = AutoModelForMultipleChoice.from_pretrained('Mizuiro-sakura/luke-large-commonsenseqa-japanese')
# 質問と選択肢の代入
question = '電子機器で使用される最も主要な電子回路基板の事をなんと言う?'
choice1 = '掲示板'
choice2 = 'パソコン'
choice3 = 'マザーボード'
choice4 = 'ハードディスク'
choice5 = 'まな板'
# トークン化(エンコーディング・形態素解析)する
token = tokenizer1([question,question,question,question,question],[choice1,choice2,choice3,choice4,choice5],return_tensors='pt',padding=True)
leng=len(token['input_ids'][0])
# modelに入力するための下準備
X1 = np.empty(shape=(1, 5, leng))
X2 = np.empty(shape=(1, 5, leng))
X1[0, :, :] = token['input_ids']
X2[0, :, :] = token['attention_mask']
# modelにトークンを入力する
result_deberta = model1(torch.tensor(X1).to(torch.int64),torch.tensor(X2).to(torch.int64))
token = tokenizer2([question,question,question,question,question],[choice1,choice2,choice3,choice4,choice5],return_tensors='pt',padding=True)
leng=len(token['input_ids'][0])
# modelに入力するための下準備
X1 = np.empty(shape=(1, 5, leng))
X2 = np.empty(shape=(1, 5, leng))
X1[0, :, :] = token['input_ids']
X2[0, :, :] = token['attention_mask']
# modelにトークンを入力する
result_luke = model2(torch.tensor(X1).to(torch.int64),torch.tensor(X2).to(torch.int64))
results=result_deberta.logits+result_luke.logits
# 最も高い値のインデックスを取得する
max_result=torch.argmax(results)
print(max_result)
終わりに
アンサンブルモデルという存在は知っていましたが、ここまで精度が向上するものだとは、驚きました。
アンサンブルモデルの作成方法としてはほかにブースティングやスタッキングなどがあるため、まだ精度向上の余地があるかもしれません。
ぜひ皆さんもいろいろ試してみてください。
今回はここまでにしようと思います。
では、ばいにゃん~。