MNISTの手書き数字分類タスク
畳み込みニューラルネットワーク(CNN)覚えたので投稿
各層の処理、最適化アルゴリズム、専門単語など、
メモ書きとしてですが、こちらの記事に記載してます。
【 機械学習用語_memo 】
Chat-GPTやWeb上で調べましたが、初心者故間違っている内容があるかもしれません。
条件 教師有り学習、10クラスの分類タスク、学習データ 60000枚、テストデータ 10000枚
動作環境
- Pythonのバージョン 3.10.9
使用ライブラリのインストール
!pip install keras==2.12.0
!pip install pandas==1.5.3
!pip install numpy==1.23.5
!pip install matplotlib==3.7.0
!pip install IPython==8.10.0
"""
urllib.request : 標準ライブラリ
gzip : 標準ライブラリ
os : 標準ライブラリ
"""
処理順序
- 使用ライブラリのインポート
- データセットのダウンロード
- 正規化(データの前処理)
- 深層学習モデルの構築
- モデルの訓練
- モデルの評価
使用ライブラリのインポート
import keras as ks #機械学習モデル
from keras.utils import np_utils # One-hotベクトル化
from keras.models import Sequential # Kerasモデルの定義
from keras.layers import Conv2D # 畳み込み層
from keras.layers import MaxPooling2D # プーリング層
from keras.layers import Dropout # ドロップアウト層
from keras.layers import Flatten # フラット化
from keras.layers import Dense # 全層結合
import pandas as pd # データフレーム
import numpy as np # 数値演算
import matplotlib.pyplot as plt # グラフ
from IPython.display import display #データフレーム表示
from urllib.request import urlopen # リモートサーバーに対してHTTPリクエスト
import gzip # .gz(GZIP 圧縮ファイル)の圧縮/展開
import os # 環境変数 KERAS_BACKEND 設定
os.environ['KERAS_BACKEND'] = 'TensorFlow' # Keras のバックエンドとして TensorFlow を設定
データセットのダウンロード
MNISTの手書き数字画像データをダウンロードする
url_train_images = 'http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz'
url_train_labels = 'http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz'
url_test_images = 'http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz'
url_test_labels = 'http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz'
MINSTの手書き数字データは、
縦28px × 横28px のグレースケール画像、ラベルデータ(正解を示したもの)となっている
- 学習データ用の画像(60000枚)
- 学習データ用のラベル(60000枚)
- テスト用の画像(10000枚)
- テスト用のラベル(10000枚)
web上のMINSTデータを変数に格納し、NumPy配列に変換する関数を定義
def load_mnist_images(url):
with urlopen(url) as response:
with gzip.GzipFile(fileobj=response) as f:
return np.frombuffer(f.read(), np.uint8, offset=16).reshape(-1, 28, 28)
def load_mnist_labels(url):
with urlopen(url) as response:
with gzip.GzipFile(fileobj=response) as f:
return np.frombuffer(f.read(), np.uint8, offset=8)
| メソッド名 | 引数 | 説明 |
|---|---|---|
| urlopen(url) as response | URLにアクセスし、web上に存在する .gzファイル(画像・ラベルデータ) fileobject を response に格納 |
|
| url | MINSTの.gzファイルのURL | |
| gzip.GzipFile(fileobj=response) as f |
response に格納された画像・ラベルデータ fileobject を f に展開 |
|
| fileobj=response | fileobject を response に指定 | |
| np.frombuffer(...) | バイト列(バッファ) から NumPy配列(1次元配列) に変換 2次元配列にすることができる |
|
| f.read(), np.uint8 | f に格納されたデータをバイト列(unit8)として読込 | |
| offset=8, offset=16 | 開始位置を指定 8,16バイト目からデータを読取 MNISTデータセット.npy ファイルは 最初のバイト列にメタデータ、 画像データは8,16バイト目から格納されている |
|
| .reshape(-1, 28, 28) | 読み込んだデータを指定された形状に変形 (-1, 28, 28) = 軸のサイズ自動的計算, 残りの2つの軸は28×28の形状に変形 MNISTの画像データは28×28ピクセルの2次元配列に格納される |
x_train = load_mnist_images(url_train_images) # 学習データ用の画像(60000枚)
y_train = load_mnist_labels(url_train_labels) # 学習データ用のラベル(60000枚)
x_test = load_mnist_images(url_test_images) # テスト用の画像(10000枚)
y_test = load_mnist_labels(url_test_labels) # テスト用のラベル(10000枚)
- urlopenで.gzファイルにアクセスし、変数 response とする
- gzipで変数 response とした.gzファイルを展開し、変数 f とする
- np.frombufferで展開した.gzファイルのデータをNumpy配列に変換し、変数を還す
- x,y_train,testに還された変数が格納される
ダウンロードした手書き数字データを保存する
train_data_path = '../data/train/' # 学習データを保存するフォルダパス
test_data_path = '../data/test/' # テストデータを保存するフォルダパス
np.save(train_data_path + 'X_train.npy', x_train) # 学習データの画像を保存
np.save(train_data_path + 'y_train.npy', y_train) # 学習データのラベルを保存
np.save(test_data_path + 'X_test.npy', x_test) # テストデータの画像を保存
np.save(test_data_path + 'y_test.npy', y_test) # テストデータのラベルを保存
データのサイズを確認する
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)
(60000, 28, 28) 学習データの画像枚数, 縦のサイズ(px), 横のサイズ(px)
(60000,) 学習データのラベル枚数
(10000, 28, 28) テストデータの画像枚数, 縦のサイズ(px), 横のサイズ(px)
(10000,) テストデータのラベル枚数
画像を確認する
現在は Numpy配列として保存されている
matplotlibでプロットして表示する
plt.imshow(x_train[53238], cmap = plt.cm.binary,interpolation='nearest')
plt.show() #プロットの表示
camp = カラーマップを指定
plt.cm.binary = バイナリーチャンネル(白黒画像)を指定
interpolation = 画像の補間方法を指定
nearest = 最近傍補間(不足データを一番近いデータ値で補う)
正規化(データの前処理)
現在の画像データ(Numpy配列)を確認する
pd.options.display.max_columns = 28 # pandasのカラム表示の設定を変更
df_display = pd.DataFrame(x_train[53238]) # Numpy配列からPandasのデータフレームへ変換
display(df_display) # df_displayの表示

黒色のところが255付近の値となっている
画像データのデータ型を unit8(符号なし8ビット整数) から float32(32ビット浮動小数点数) に変換する
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
データ型 float32 は機械学習において、入力データや重みなどの数値計算で用いるデータ型。
6,7桁の精度を持つ
正規化(画像データのピクセル値をスケーリングする)
x_train /= 255
x_test /= 255
正規化することにより、モデルの学習や予測などの数値演算が効率的に行える
現在のラベルデータを確認する
print(y_train[53238]) # 9
ラベル y を One-hot Vector に変換
y_train = np_utils.to_categorical(y_train, num_classes=10)
y_test = np_utils.to_categorical(y_test, num_classes=10)
print(y_train[53238]) # [0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
-
One-hotベクトル
一つのデータ要素に対して、それが属するカテゴリを表す要素が1であり、
それ以外の要素は0であるベクトル表現変換前 変換後 0 [1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] 1 [0. 1. 0. 0. 0. 0. 0. 0. 0. 0.] 2 [0. 0. 1. 0. 0. 0. 0. 0. 0. 0.] 3 [0. 0. 0. 1. 0. 0. 0. 0. 0. 0.] 4 [0. 0. 0. 0. 1. 0. 0. 0. 0. 0.] 5 [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.] 6 [0. 0. 0. 0. 0. 0. 1. 0. 0. 0.] 7 [0. 0. 0. 0. 0. 0. 0. 1. 0. 0.] 8 [0. 0. 0. 0. 0. 0. 0. 0. 1. 0.] 9 [0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
深層学習モデルの構築
# モデルの宣言
model = Sequential() # Sequentialクラスのインスタンスを作成
# モデルへレイヤーを追加
model.add(Conv2D(filters=32, kernel_size=(3, 3),activation='relu',input_shape=(28,28,1)))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(1, 1), padding="valid"))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(units=128, activation='relu'))
model.add(Dense(units=10, activation='softmax'))
# Learnig Processの設定
model.compile(loss='categorical_crossentropy',optimizer='sgd',metrics=['accuracy'])
- Conv2D:
2次元の畳み込み層:
畳み込み層は画像データなどの空間的な特徴を学習するために使用、
このクラスでは、畳み込みフィルタの数、カーネルサイズ、活性化関数などを指定する- filters=32
フィルタの数 = 出力される特徴マップの数 - kernel_size=(3, 3)
3 × 3のカーネルを指定。カーネルサイズが3x3なら、
画像データのサイズは 28px × 28px → 26px × 26px に変換される - activation='relu'
ReLU関数が適用 - input_shape=(28,28,1)
入力データの形状を指定、28px × 28pxのグレースケール画像
- filters=32
畳み込み層入力: [1, 28px, 28px,1]の画像データ1枚
畳み込み層出力: [1, 26px, 26px,1]の特徴マップ32枚
- MaxPooling2D:
プーリング層:
特徴マップのサイズ圧縮、Maxプーリングを指定
(縦横2*2のプーリング領域の中で、最大ピクセル値がプーリング後のピクセル値となる)- pool_size=(2, 2)
プーリングウィンドウのサイズを指定、2 × 2のウィンドウでプーリングを行う - strides=(1, 1)
スライドサイズを指定、(1, 1) なら縦横1マスずつ移動する - padding="valid"
パディングを指定、"vaild" 入力画像よりも出力画像が小さくなる。
"same" 入力画像の周囲をピクセル値 0 でパディングすることにより、
入力画像と出力画像のサイズが同じとなる。
- pool_size=(2, 2)
プーリング層出力 [1, 13px, 13px,1]の特徴マップ32枚
- Dropout:
ドロップアウト層:
過学習を防止用- (0.25)
25% の確率でランダムにノードの出力を 0 にする
- (0.25)
ドロップアウト層出力 [1, 13px, 13px,1]の特徴マップ32枚
- Flatten
フラット化層:
多次元行列データを1次元に変換する
例 [1, 13, 13 ,1] → [1, 169]
[batch_size, high, width, channel] → [batch_size, high × width × channel]
フラット化層出力 [1, 169]の1次元配列32個
※1 は width ではなく batch_size
- Dence:
全結合層:
入力ノード数 169- (128, activation='relu')
出力ノード数 units = 128、全結合層の活性化関数 = ReLU関数
入力ベクトル * パラメータ行列 = 出力ベクトル
[ 縦128 × 横169 ] * [ 縦169 × 横1 ] = [ 縦128 × 横1 ]
出力ノード数 128
- (128, activation='relu')
全層結合出力 [1, 128]の1次元配列32個
- Dence:
全結合層:
入力ノード数 128- (10, activation='softmax')
出力ノード数 units = 10、最終層の活性化関数 = softmax関数(クラスの確率分布)
パラメータ行列 * 入力ベクトル = 出力ベクトル
[ 縦10 × 横128 ] * [ 縦128 × 横1 ] = [ 縦10 × 横1 ]
出力ノード数 10
- (10, activation='softmax')
全層結合出力 [1, 10]の1次元配列32個 ← (32個)
- compile:
コンパイル:- loss='categorical_crossentropy'
損失関数 = 交差エントロピー誤差 - optimizer='sgd'
最適化アルゴリズム = 確率的勾配降下法 - metrics=['accuracy']
モデル評価指標 = 正解率(Accuracy)
- loss='categorical_crossentropy'
モデルの訓練
# 注意 - 10〜15分程度かかります
model.fit(x=x_train, y=y_train, epochs=10)
- fit:
モデルをトレーニングするためのメソッド- x=x_train : データの特徴量
- y=y_train : ラベル
- epochs=10 : データセットを10週学習する (60000枚×10回)
Epoch 1/10
1875/1875 [==============================] - 36s 19ms/step - loss: 0.3676 - accuracy: 0.8946
Epoch 2/10
1875/1875 [==============================] - 34s 18ms/step - loss: 0.1771 - accuracy: 0.9470
Epoch 3/10
1875/1875 [==============================] - 34s 18ms/step - loss: 0.1262 - accuracy: 0.9631
Epoch 4/10
1875/1875 [==============================] - 34s 18ms/step - loss: 0.0984 - accuracy: 0.9711
Epoch 5/10
1875/1875 [==============================] - 41s 22ms/step - loss: 0.0807 - accuracy: 0.9768
Epoch 6/10
1875/1875 [==============================] - 41s 22ms/step - loss: 0.0699 - accuracy: 0.9797
Epoch 7/10
1875/1875 [==============================] - 38s 20ms/step - loss: 0.0597 - accuracy: 0.9827
Epoch 8/10
1875/1875 [==============================] - 40s 21ms/step - loss: 0.0534 - accuracy: 0.9841
Epoch 9/10
1875/1875 [==============================] - 43s 23ms/step - loss: 0.0482 - accuracy: 0.9858
Epoch 10/10
1875/1875 [==============================] - 40s 21ms/step - loss: 0.0435 - accuracy: 0.9870
学習データの損失値 0.0435、正解率 98.7%
学習の進行に伴い、loss(損失値)が収束し、正解率が上昇している
発散せずに学習出来ている
モデルの評価
loss_and_metrics = model.evaluate(x=x_test, y=y_test, batch_size=128)
print(loss_and_metrics)
- evaluate:
テストデータで評価するためのメソッド- x=x_test : データの特徴量
- y=y_test : ラベル
- batch_size=128: データを128個ずつのバッチに分割して評価
79/79 [==============================] - 1s 12ms/step - loss: 0.0448 - accuracy: 0.9842
[0.04481068253517151, 0.9842000007629395]
テストデータの損失値 0.0448、正解率 98.4%
結論
学習データの正解率 98.7%
テストデータの正解率 98.4%
差が0.3%であるため、 過学習していない と思われる
間違い判定データの確認
画像表示の準備
# 予測ラベルと正解ラベルの取得
predictions = model.predict(x_test)
predicted_labels = np.argmax(predictions, axis=1)
true_labels = np.argmax(y_test, axis=1)
# 予測結果と正解ラベルを比較し、間違っている画像のインデックスを取得
misclassified_indices = np.where(predicted_labels != true_labels)[0]
# 間違っている画像のインデックスをランダムに5つ選択
num_images_to_show = 5 # 抽出するインデックスの数
selected_indices = np.random.choice(misclassified_indices, size=num_images_to_show, replace=False)
- predict:
predict() メソッドは、入力データに対する予測結果を返す。- x_test:
10クラスの確率分布10000個が、predictions 変数に配列として格納される。
- x_test:
- np.argmax:
画像に対する予測されたラベル、正解のラベルを取得。- predictions:
各確率分布毎に最も高い確率を持つクラスラベル10000個が、
predicted_labels 変数に格納される。 - y_test:
one-hot ベクトル型の正解ラベル10000個が、
true_labels 変数に格納される。 - axis=:
axis=0 行方向のインデックス数、
axis=1 行方向の最大値インデックス番号、
axis=2 列方向のインデックス数
- predictions:
- np.where:
- predicted_labels != true_labels:
予測ラベル predicted_labels と 正解ラベル true_labels の
不一致している要素を misclassified_indices 変数に格納される。
- predicted_labels != true_labels:
- np.random.choice():
ランダムに画像のインデックスを抽出。
結果は selected_indices 変数に格納される。- misclassified_indices:
間違って分類されたインデックスのみが格納されている変数 - size=num_images_to_show:
抽出するインデックスの数を指定 - replace=False:
抽出するインデックスの重複、True 重複有り、False 重複無し。
- misclassified_indices:
間違い判定画像を確認する
for index in selected_indices:
plt.imshow(x_test[index].reshape(28, 28), cmap='gray')
plt.axis('off')
plt.show()
| 画像 |  |
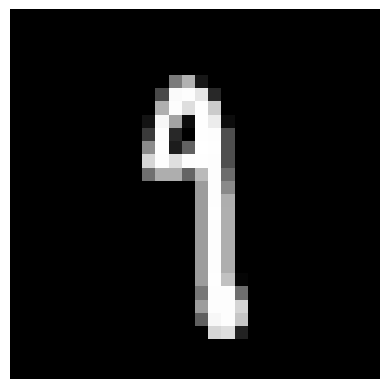 |
 |
 |
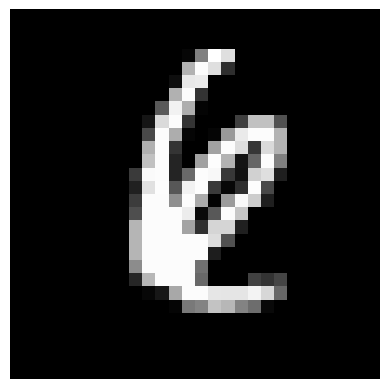 |
左から 6、9、3、2、6 かな?
for index in selected_indices:
print(f'model: {predicted_labels[index]}, true: {true_labels[index]}')
| 画像 | |
|
|
|
|
| モデル 予想 |
8 | 1 | 7 | 2 | 8 |
| 正解 | 6 | 9 | 1 | 1 | 6 |
皆さんはいくつ正解しましたか?
わたしは3つです。
最後までお読みいただき、ありがとうございました。
MINST Database of hand written digits 手書き数字MINSTデータベース
- Yann LeCun, Corinna Cortes, Christopher J.C. Burges. (n.d.). THE MNIST DATABASE of handwritten digits.
Retrieved from http://yann.lecun.com/exdb/mnist/ (Accessed on 14 June 2023).
References 参考文献
- CODEXA Team. (2018). 初心者のための畳み込みニューラルネットワーク(MNISTデータセット + Kerasを使ってCNNを構築).
Retrieved from https://www.codexa.net/cnn-mnist-keras-beginner/ (Accessed on 14 June 2023).
Licence ライセンス
このプロジェクトは以下のオープンソースライブラリを使用しています。
それぞれのライブラリは個別のライセンスで提供されています。
ライセンスの詳細については、各ライブラリの公式ウェブサイトを参照してください。
- Name : License : Home-page : Author
- TensorFlow : Apache License 2.0 : https://www.tensorflow.org/ : Google Inc.
- Keras : MIT License : https://keras.io/ : Keras team.
- pandas : BSD License : https://pandas.pydata.org/ : The Pandas Development Team.
- NumPy : BSD License : https://numpy.org/ : Travis E. Oliphant et al.
- Matplotlib : PSF License : https://matplotlib.org/ : John D. Hunter, Michael Droettboom
- IPython : BSD-3-Clause License : https://ipython.org : The IPython Development Team.