はじめに
この記事はこれまで実案件において実施したDatabricksSQLパフォーマンスチューニングの作業内容をベースに、実行クエリのボトルネック特定からパフォーマンス改善の手法について共通すると思われるTipsをベストプラクティスとしてまとめたものです。
DatabricksSQLの操作経験がある方を対象に記載しておりますため、DatabrickSQLの機能説明や用語解説及び設定コマンドの詳細等は割愛しておりますが、今回初めてDatabricksSQLをご検討される方でも理解いただけるよう、該当するDatabricksドキュメントリンクも併せて記載しておりますので適宜ご参照ください。
※ドキュメントへのリンクはAzure Databricksのリンクを使用していますがAWS/CGP上のDatabricksでも同様の機能を提供しています。
DatabricksSQLとは
DatabricksSQLは大規模データを高速に処理するための分散データウェアハウスであり、Databricksレイクハウスプラットフォームの主要機能の1つです。従来のDWH同様にSQLクエリ言語を使用して、データレイクに格納された大量のデータに対して高速な分析を実行することができ、標準的なANSI-SQLクエリ言語をサポートしているため、他のDWH製品やSQLに慣れている方であればすぐに活用することができます。
またDatabricks社がC++で開発した高速化エンジンであるPhotonによりクエリが実行されますので通常のSparkSQLエンジンを大幅に上回る高速処理を実現することができます。
参考リンク:https://learn.microsoft.com/ja-jp/azure/databricks/sql/
参考リンク:https://learn.microsoft.com/ja-jp/azure/databricks/runtime/photon
DatabricksSQLの概要についてはこちらの記事も併せてご参照ください。昨年末より日本リージョンで利用が可能となりましたServerlessSQLについてもご紹介しています。
https://qiita.com/kohei-arai/private/7b4e15a4cf79aa827957
チューニングステップ
それでは、以下、チューニングステップの手順を実際の事例をもとに解説していきます。
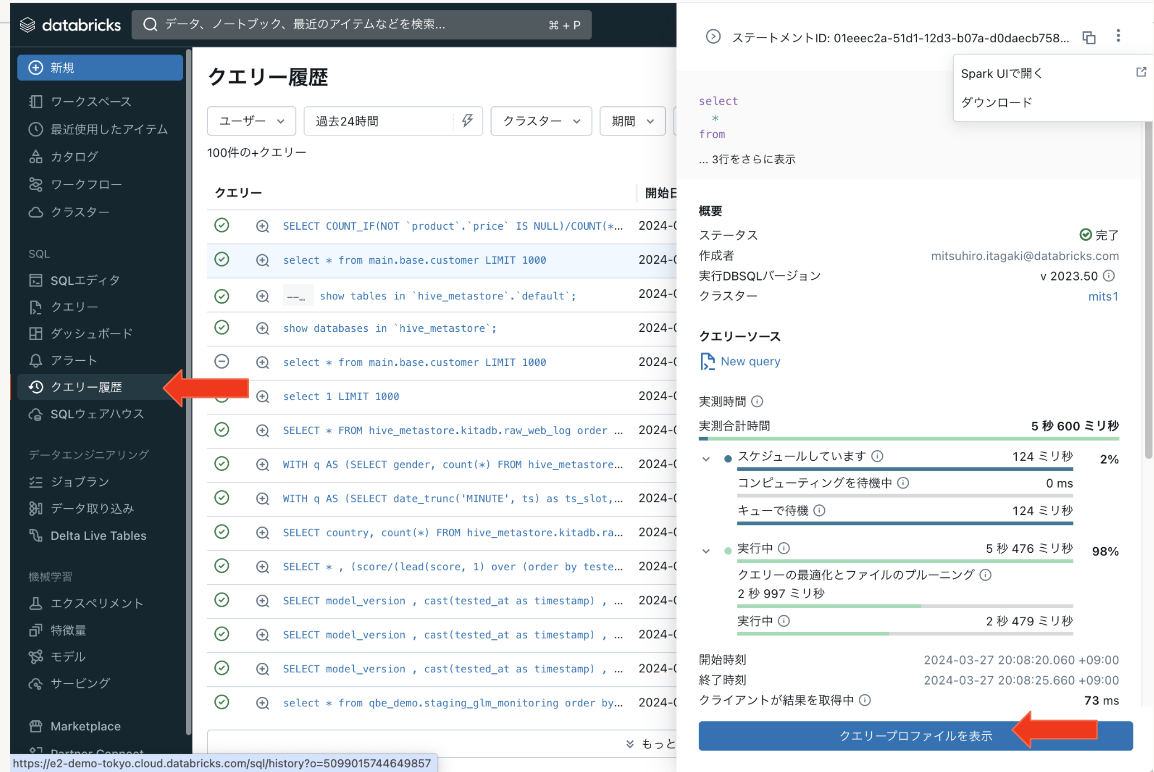
一連のチューニング作業ではクエリプロファイルを使用します。クエリプロファイルはDatabricksSQLの専用のチューニングツールで、SQLクエリの実行時間、実行計画、使用されたリソースなど、SQLクエリの詳細な情報を提供するツールです。SQLクエリのパフォーマンスの改善や、ボトルネックの特定などに役立つ各種の統計情報を確認できます。
参考リンク:https://learn.microsoft.com/ja-jp/azure/databricks/sql/user/queries/query-profile
パフォーマンスボトルネックは環境ごとに様々ですが、多くのケースではDatabricksSQLのチューニングは大きく以下の4つのステップを順に実施していくと効果的です。
参考リンク:https://learn.microsoft.com/ja-jp/azure/databricks/lakehouse-architecture/performance-efficiency/best-practices
1.I/Oの効率化
2.SQL実行プランの改善
3.Photon利用率の改善
4.クラスタサイズの調整
1. I/Oの効率化
最初に一般的なデータウェアハウスと同様、不要なストレージへのI/O削減を検討して下さい。これによりデータの読み込みやクエリの処理を効率化することができます。
クエリプロファイルの情報から指定するフィルタ対象のカラムの選定を行います。
クエリープロファイルでフィルタ条件の確認するにはクエリプロファイルを冗長化モードでの表示がお勧めです。以下のようにクエリで使用されているフィルタ条件が表示されます。
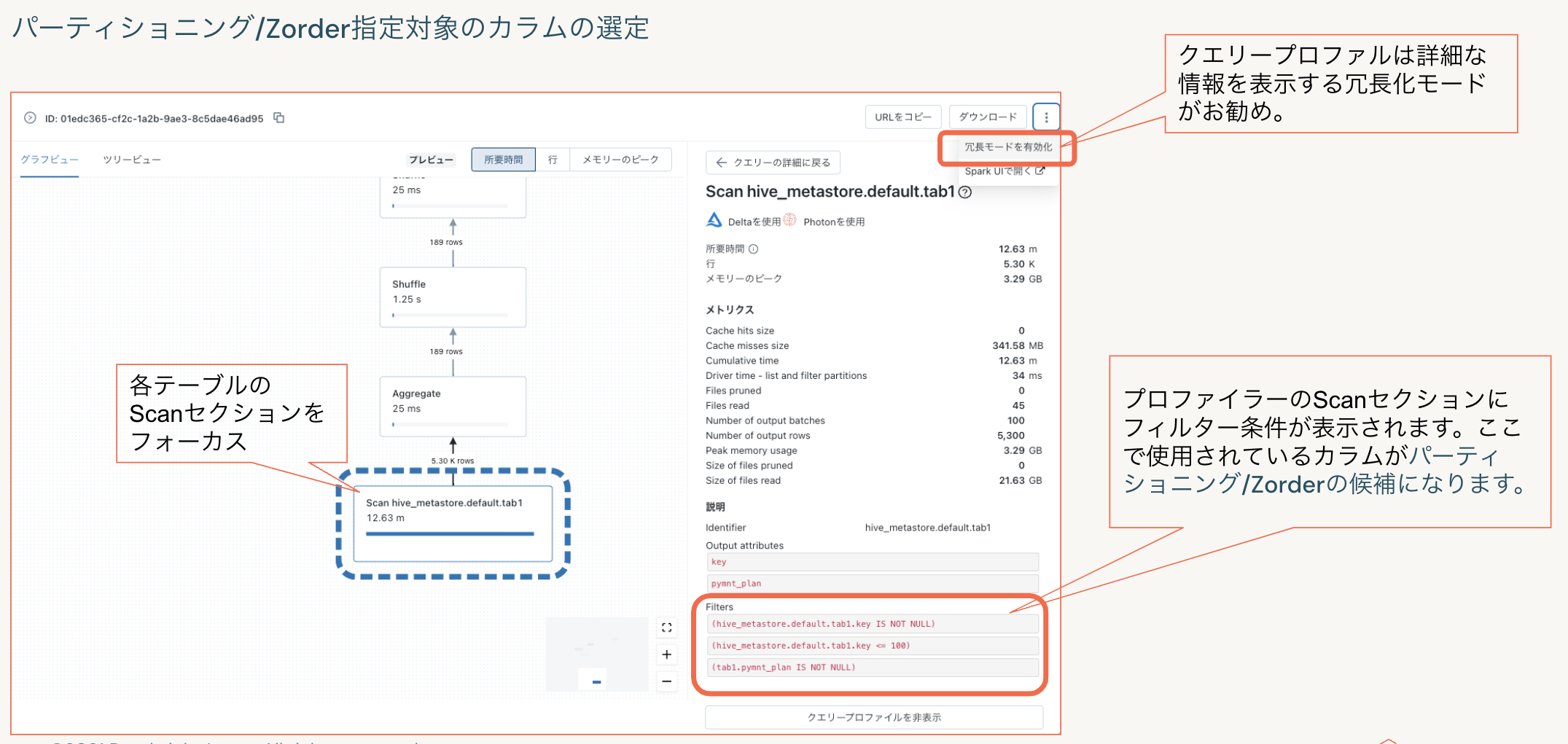
フィルタ条件を確認後、適切なI/O削減を実施するために以下の3の手法を検討します。
(1)パーティショニング
大規模データセット(目安としては1TB以上)への高速なクエリ処理時間が最優先される場合にはフィルタ条件で指定するカラムでのパーティショニング検討をします。ただし、パーティション数が数千を超えるような場合はパーティショニングを構成するディレクトリ以下に配置される物理ファイル総数が増加する可能性があるため、多くともパーティション数は2000−3000程度を目安とすると良いでしょう。
パーティションキーでフィルターできないクエリを実行した際のRead対象物理ファイル数が膨大とならないように注意してください。
一般的なデータウェアハウス設計でのデータ分析単位となる時系列カラムなど、検索時にフィルター条件として必ず指定されるカラムを選定するようにします。
複数パーティションキーも可能ですが先頭キーが指定されないとI/O削減効率が落ちるため、単一カラムでのパーティショニングを推奨します。
参考リンク:https://learn.microsoft.com/ja-jp/azure/databricks/tables/partitions
(2)Z-ORDER
OptmizeコマンドのZ-ORDERオプションで指定したカラムをキーとする特殊なデータソートで再配置することでI/Oスキッピングの効率を向上させます。
カーディナリティが高すぎてパーティショニングできない、フィルタ対象のカラムが複数ありフィルタの条件がクエリにより異なる、などパーティショニングで対応できない場合でも効率的にI/O削減することが可能です。
Zorderで指定するカラムの順番を考慮する必要はありませんが、指定したカラムがすべて指定される場合にI/O削減効率が最大となりますので、Z-ORDERで指定するフィルタ条件のカラムは絞り込み条件で使用される頻度の高いものから最大4カラム程度(先頭の32カラムから指定可能)を目安とします。
小中規模(1TB以下程度)のテーブルではZ-ORDERのみで十分な速度改善が可能ですが、大規模テーブルへの定型アクセスなどではパーティショニングと併用すると更に効果があります。
データ追加や更新によりレコードの物理配置が変化するため、10%程度のデータ更新が発生した場合にはOptimizeコマンドの定期的な実行によるレコードの再配置実行してください。
参考リンク:https://learn.microsoft.com/ja-jp/azure/databricks/sql/language-manual/delta-optimize
(3)リキッド・クラスタリング
リキッド クラスタリングは従来のパーティショニング、Z-ORDERをリプレース可能な新しいI/O削減の機能としてリリースされました。Databricks SQL及びRuntime 13.3以降のクラスタで使用でき、Zorderと同様に指定したカラム(先頭の32カラムから最大4カラムまで指定可能)を特殊なソートにより物理的に近い位置に再配置することでI/Oスキッピングの効率を向上させることが可能です。
パーティショニング、Z-Orderとの併用はできませんが、これまで従来のチューニング方式では対応が困難であったケースでも効果を発揮します。
クラスタリングのメリットが得られるシナリオの例を次に示します。
- カーディナリティが非常に高い列でフィルター処理されることが多いテーブル
- データ分散に大きな偏りがあるテーブル
- 更新頻度が高く、頻繁にメンテナンスとチューニング作業が必要なテーブル
- 同時書き込みの要件を持つテーブル
- 時間の経過と共に変化するアクセス パターンを持つテーブル
- 一般的なパーティションキーでは、パーティションが多すぎるか、少なすぎるテーブルとなってしまうテーブル
基本的なI/O削減の仕組みはZ-ORDERと同様ですが以下のアドバンテージがあります。
(1) データ書き込み時に自動クラスタリングを実施
リキッドクラスタリングでは、データが書き込まれる際にクラスタリングされ、その結果、データはすでに最適化された状態で格納されます。
Z-Order同様に10%程度のデータ更新が発生した場合にはOptimizeコマンドの定期的な実行によるレコードの再配置実行が必要ですが、データ書き込み時の自動クラスタリングによりZ-Orderと比較して実際の運用時におけるクエリパフォーマンスの劣化が軽減され、同時にOptimizeコマンドによるデータの再配置(クラスタリング)にかかる時間も短縮されます。
詳細な要件については、ドキュメントを参照してください。
(2) データ書き込み時の行レベルのコンカレンシーをサポート
クラスター化されたテーブルは従来のファイルレベルのコンカレンシーから、行レベルのコンカレンシーを提供します。これにより、OPTIMIZE、INSERT、MERGE、UPDATE、DELETE 操作を含む同時書き込み操作間の競合の数を減らすことができます。
その他、Zorderではクラスタリングに指定したカラムをテーブル情報から確認できず、カラムコメントなどに記録しておく必要がありましたが、リキッドクラスタリングではテーブルメタ情報として保存されます。
すでに従来型のパーティション+Zorderで十分なパフォーマンスが得られている場合には必ずしもリキッドクラスタリングに変更する必要はございませんが、将来的にはクエリの実行情報から最適なクラスタリングキーを選定するなどの自動チューニング対応も予定されており、Databricksではすべての新しいDeltaテーブルに対してリキッドクラスタリングをお勧めします。
参考リンク:https://learn.microsoft.com/ja-jp/azure/databricks/delta/clustering
時間と共に分析要件が変化しても柔軟に対応できるよう、クラスタリングキーが変更された後のOptimizeコマンドによる物理再配置は新規データのみが対象となります。
過去データに対する物理再配置を実行したい場合は、テーブルを新規に再作成するか以下のように一度リキッド・クラスタリング解除+最適化(Optimize)を実施後に再度クラスタリングキーを設定してください。
(1)リキッド・クラスタリングを解除 [例:Alter table xxx cluster by NONE ]
(2)ZORDERを実行 [例:Optmize xxx ZORDER by (yyy,zzz)]
(3)再度、新規のクラスタキーを設定 [例:Alter table xxx cluster by (yyy,zzz) ]
※過去データに対する再クラスタリングはロードマップで計画されています。
I/O削減効果の確認
パーティショニング/Z-Order/リキッドクラスタリングの効果はクエリプロファイラから実行時のメトリクス情報で確認できます。
- Files pruned
- Readをスキップしたファイル数
- Files read
- 実際にReadしたファイル数
- Partitions read
- Read対象なったファイル数
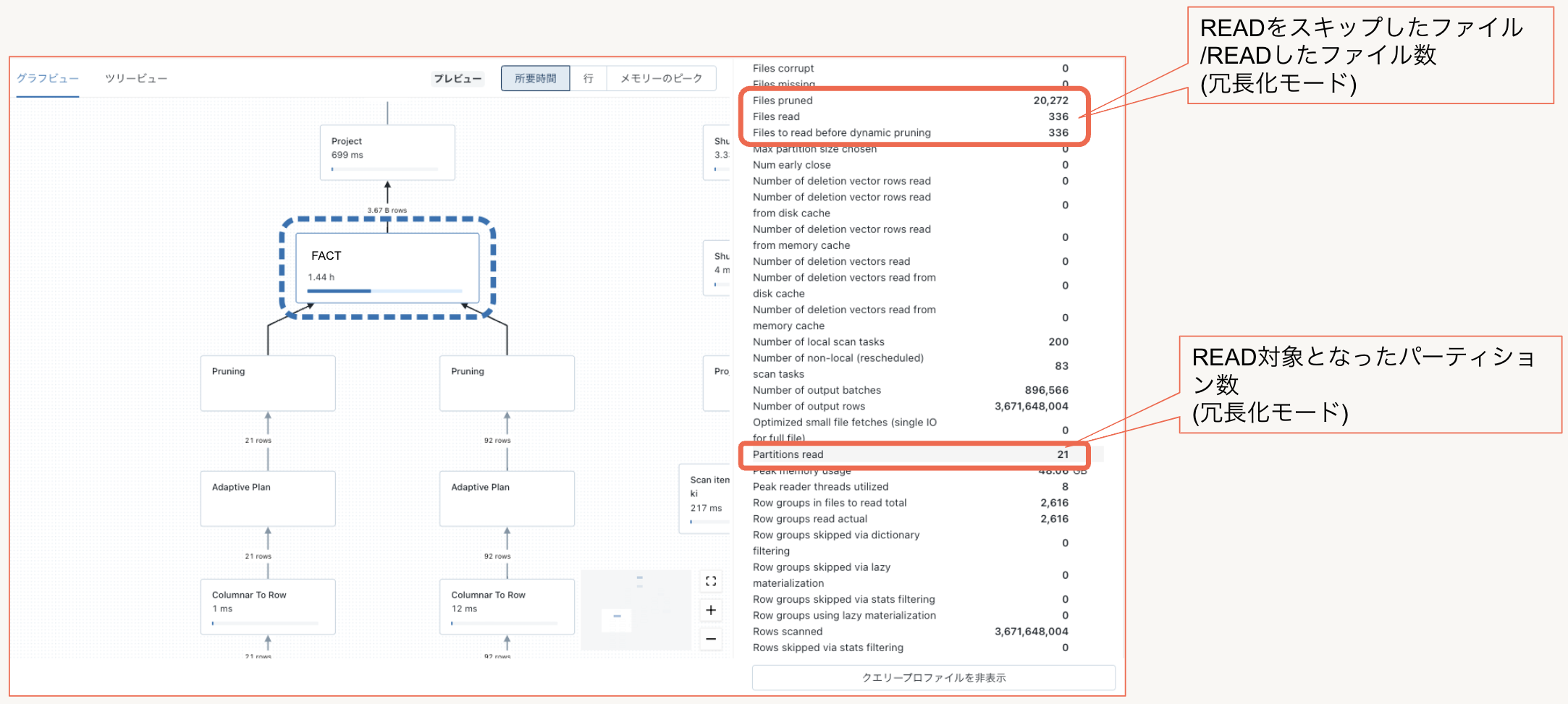
- Read対象なったファイル数
パーティショニング/Z-ORDER/リキッド・クラスタリングの比較検証の結果はこちらの記事をご参照ください。
https://qiita.com/nttd-kitabah/items/197aa6138243c5f7a082
2.SQL実行プランの改善
次に結合クエリの実行計画を最適化するため、Analyze実行やSparkコンフィグパラメータの調整方法をご説明します。
ここではボトルネックとなりやすい複数テーブル結合時の非効率な結合プランを最適化する方法とDiskスピルアウトの解消方法にフォーカスしてご説明します。
データ量などの条件にも依存しますが多くの場合、以下の4つの結合方式のうち、高速なPhotonエンジンで処理可能なブロードキャスト結合/シャッフルハッシュ結合のどちらかで結合処理が行われており、ディスクへのスピルアウトは発生していない状態が望ましいです。

非効率な結合プランの改善方法について実際の例をもとにご説明します。
SQL実行プランの確認
まず最初にクエリプロファイルでテーブル結合処理のプランを確認しましょう。
参考リンク:https://learn.microsoft.com/ja-jp/azure/databricks/sql/user/queries/query-profile#view-a-query-profile
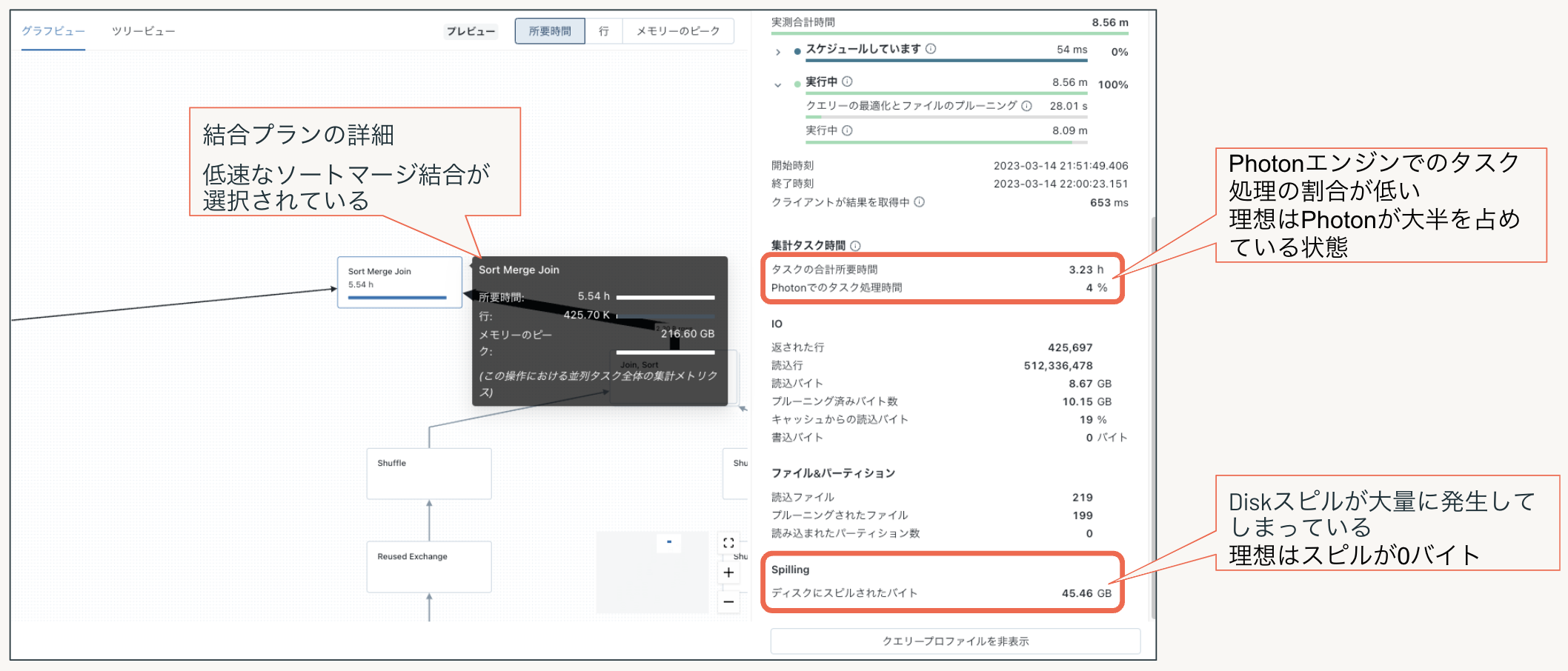
以下は典型的な低速なクエリプラン例ですが、ソートマージ結合が選択され、大量のDiskへのスピルが発生し、Photoneエンジンが使用されないためPhotonでのタスク処理の比率も非常に低い状態のクエリプロファイルでの表示例です。
Photonエンジンが使用されないソートマージ結合のため全体的にPhoton利用率が低く、同時にDiskスピルが大量に発生してしまっている状態を示しています。
理想はPhotonが大半を占めていて、ディスクへのスピルが0バイトの状態です。
最適な実行プラン生成のための次のチューニングを実施します。
(1)Analyze実行
各クエリで使用しているテーブルは小規模マスターテーブルを含め最新の統計情報を取得してください。統計情報はコストベースにおける最適なテーブル結合方式と結合順序を決定するために使用されます。
Sparkエンジン/PhotonではAQE (Adaptive Query Execution)によりクエリー実行中に収集される実行時の統計情報に基づきクエリプランの最適化が行われますが、実際にデータ読み込みが行われてからのプラン変更になりますので、クエリ実行前に最新の統計情報により最適なプランが作成されている状態である方が効率的です。
通常の運用ではテーブルの10%程度のデータ更新が発生した場合に、クエリ内で使用されるカラムの統計情報をリフレッシュすることが推奨されています。
※前述のZ-ORDER/リキッドクラスタリングでWhere句のフィルター条件に使用される先頭32列の統計はデータスキップ専用であり、Analyzeコマンドでカラムを指定して取得する統計情報は適切なプランを生成するために使用されます。
(2)Optimize実行
更新頻度の高いテーブルはファイルのフラグメンテーションが発生している場合がありますので定期的な物理ファイルの最適化を実行しておきます。
また、パーティショニングテーブル全体に対するOptimize実行はパーティション数が多い場合にはリソース使用量が増加し長時間を要する場合があリます。その場合には更新が発生したパーティションのみをWhere条件で指定することが可能です。
※Optimizeでは最適化処理により物理ファイルサイズはテーブルのサイズにより256MB-1GBの間で自動調整されます。テーブルプロパティで明示的にターゲットサイズを指定することも可能です。
参考リンク:https://learn.microsoft.com/ja-jp/azure/databricks/delta/tune-file-size
(3)Sparkコンフィグパラメータ調整
DatabricksSQL(Classic/Pro)では上記のAnalyze/Optmizeを実行しても期待したパフォーマンスを得られない場合はSparkコンフィグパラメータを調整することも可能です。
(注意)ServerlessではSparkコンフィグパラメータの変更することはできません。
ここでは代表的なパラメータを3つ紹介します。
参考リンク:https://learn.microsoft.com/ja-jp/azure/databricks/optimizations/aqe#configuration
-
spark.databricks.adaptive.autoBroadcastJoinThreshold(デフォルト:30MB)
推奨:100MB以下(クラスタのドライバノードのメモリサイズに依存)
ブロードキャスト結合を実行するテーブルサイズの閾値。クラスタサイズに対して設定サイズが大きすぎるとOutOfMemoryエラーの原因となるので注意してください。OutOfMemoryエラーとなった場合はクラスタサイズを大きくすることでドライバノードのメモリ搭載量が増加するためエラーを解消できますが、200MB以上に設定してもパフォーマンスはほとんど向上しません。
※spark.sql.autoBroadcastJoinThresholdパラメータと同等 -
spark.sql.join.preferSortMergeJoin(デフォルト: true)
推奨:false
データセットが大きい場合のデフォルト結合戦略にソートマージを優先的に使用するかどうかを指定します。
spark.sql.adaptive.enabled=true(デフォルト)においては特に変更せずとも高速なブロードキャスト/シャッフルハッシュの実行プランが選択されやすいのですが、trueの場合はデータ量が大きい場合などでは常にソートマージプランが選択されやすいためfalseを指定することで結合プランを改善できる場合があります。 -
spark.sql.shuffle.partitions(デフォルト:200)
推奨:auto
結合または集計のデータをシャッフルするときに使用するパーティションの既定の数。 値をautoに設定すると、自動最適化シャッフルが有効になり、クエリー プランとクエリー入力データサイズに基づいてこの数値が自動的に決定されます。
ディスクへのスピルアウトが発生している場合はSparkタスクが細分化されることでDiskスピルアウトが改善されます。
補足:Sparkコンフィグパラメータの設定方法
DatabricksSQL GUIでの”管理者設定では設定可能なSparkコンフィグパラメータに制限があり、現バージョンではここでご紹介しているSparkパラメータはGUIでは設定できません。SQL Warehouses API を使用して設定を行います。
尚、Sparkコンフィグパラメータを変更すると起動中のSQLクラスタは再起動されますのでご注意ください。
参考リンク:https://docs.databricks.com/api/azure/workspace/warehouses
以下、SQL Warehouses APIでのPythonコードサンプルです。
import requests, json
# SQLウェアハウスID
warehouse_id = 'xxx' <-- SQLウェアハウスのUIの”概要”で名前の横に表示されるID:xxxの部分)
# ワークスペースID
workspace_id = 'xxx' <-- ワークスペースの固有名称(xxx.cloud.databricks.comのxxxの部分)
# ユーザトークン
token="xxxxx"
# For Azure
workspace_name = workspace_id+".azuredatabricks.net"
# For AWS
workspace_name = workspace_id+".cloud.databricks.com"
url = "https://{}".format(workspace_name)
header_json = {'Authorization': 'Bearer ' + token, 'Content-Type': 'application/json'}
http_method = 'GET'
rest_path = f'/api/2.0/sql/warehouses/{warehouse_id}?debug=true'
resp = requests.get(url + rest_path, headers=header_json)
for line in json.dumps(resp.json(), indent=4).split('\n'):
display(line)
scale_parameters= { "confs": {
"conf_pairs": [
{"key": "spark.sql.join.preferSortMergeJoin", "value": "false"},
{"key": "spark.databricks.adaptive.autoBroadcastJoinThreshold", "value": "100MB"},
{"key": "spark.sql.shuffle.partitions", "value": "auto"},
]
} }
scale_rest_path = '/api/2.0/sql/warehouses/' + warehouse_id + '/edit'
print(json.dumps(scale_parameters))
resp = requests.post(url + scale_rest_path, headers=header_json, data = json.dumps(scale_parameters))
print(resp.json())
SQL実行プラン変更後の効果の確認
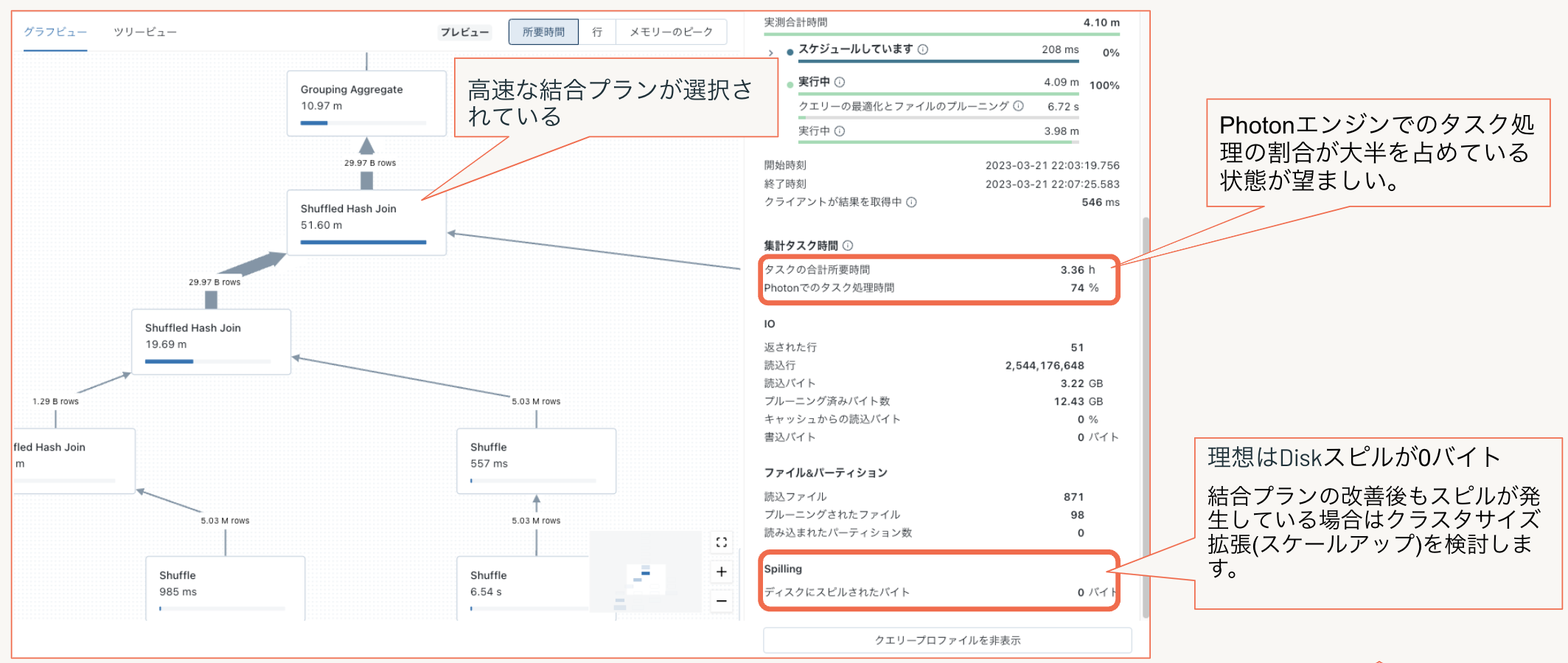
ブロードキャスト/シャッフルハッシュのクエリ実行プランへの変更によりDiskスピルがなくなり、Photonでのタスク処理の比率が高い状態となっている状態が望ましいです。
上記のチューニングを行いパフォーマンスが改善された健全なクエリプラン例を以下に示します。この例ではPhotonエンジンでのタスク処理の割合が大半を占めており、Diskへのスピルが0バイトの理想的な状態に改善されました
3. Photon利用率の改善
次にクエリプランを改善した後もPhotonエンジンの利用率が低い場合の対応方法をご紹介します。クエリのどの箇所でPhoton未対応の処理が実行されているか確認し対応策を検討します。
Photonエンジン未対応の箇所を確認
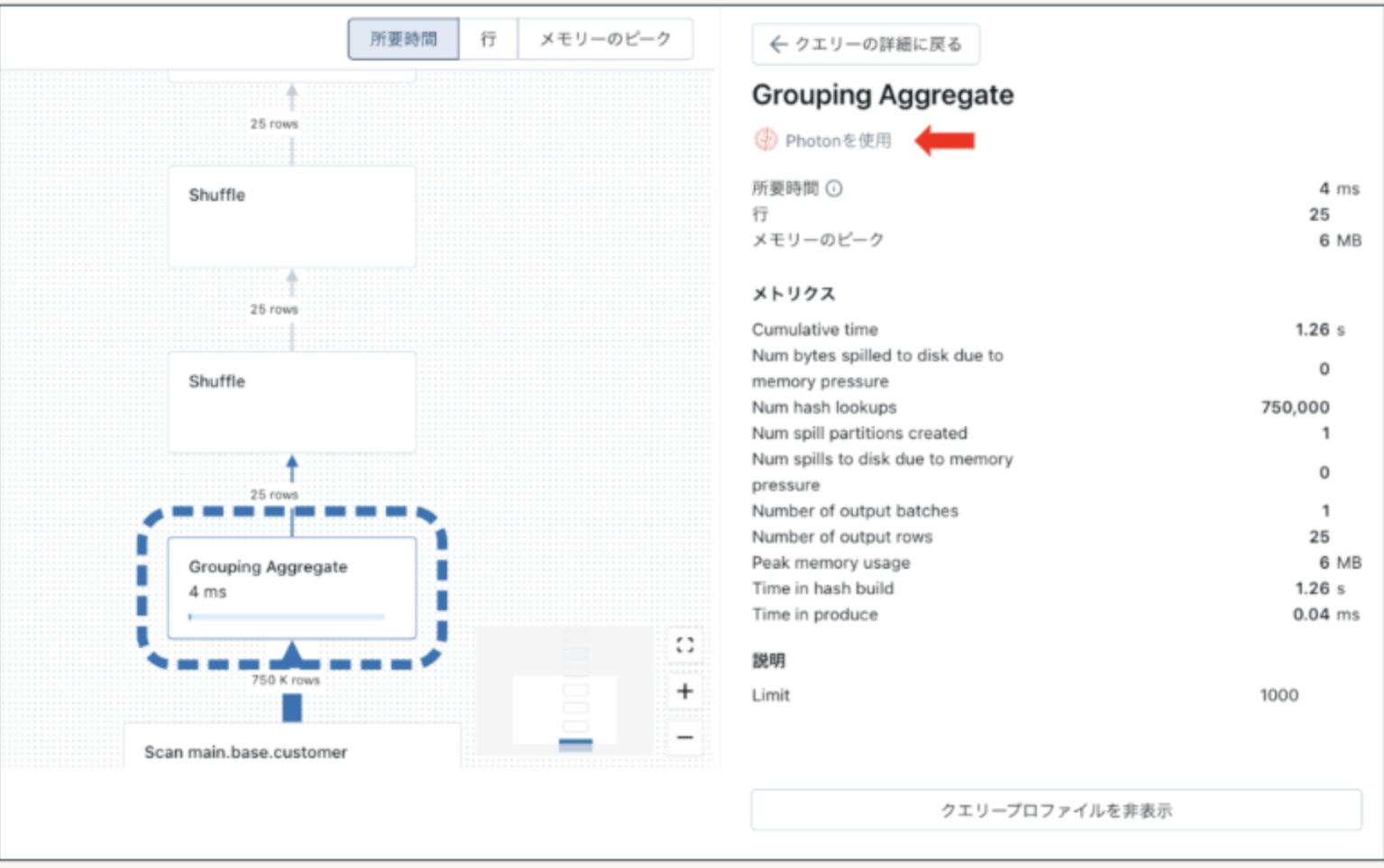
(1)クエリプロファイラでの確認方法
クエリプロファイラからはクエリプランの各ステップをクリックすると、右側の詳細表示の上段に”Photonを使用"と表示されているか確認ください。この表示がない場合はPhotonエンジンで処理が実行されていません。
(2)SparkUIでの確認方法
Photonエンジンでクエリが実行されているかの確認はSparkUIでも可能です。
以下のようにクエリプロファイルから”Spark UIで開く”をクリックし、SparkUIをオープンして確認すると詳細が確認できます。
視覚的にも見やすいためおすすめです。

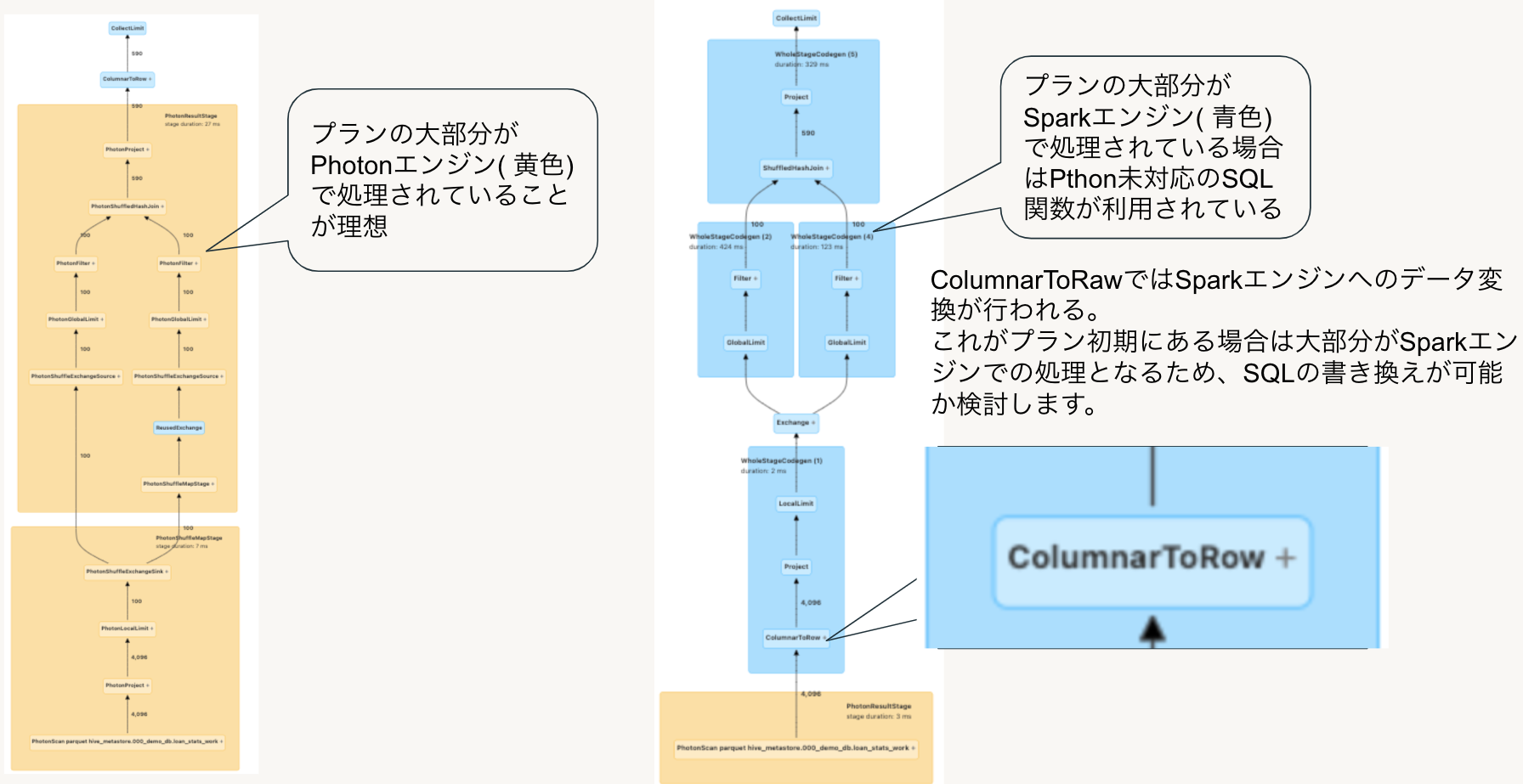
SparkUIでは以下の例のようにPhotonエンジンでの処理は黄色、Sparkエンジンでの処理は青色で表示されます。SQLウェアハウスではデフォルトでPhotonが有効化されており、可能な限りPhotonエンジンを使用してクエリを実行しますが、Photon未対応の処理が含まれる場合にはオプティマイザがSparkエンジンでの処理に切り替えます。
以下の図の左側のプランは黄色の処理が大部分を占めておりPhotonエンジンが有効に利用されていますが、右側のように処理の大半が青色のプランになっている場合はSparkエンジンで処理されています。
右側のプラン中の”ColumnarToRaw”ではSparkエンジンでの処理を行うためにデータフレームへのデータ変換が行われますが、これ以降の処理ステップではSparkエンジンでの処理となりPhotonエンジンがほとんど利用されていません。
このような場合はPhoton未対応の箇所を特定し、Photonエンジンで処理可能なSQLへの書き換えが可能かを検討します。
Photon利用率を改善する方法
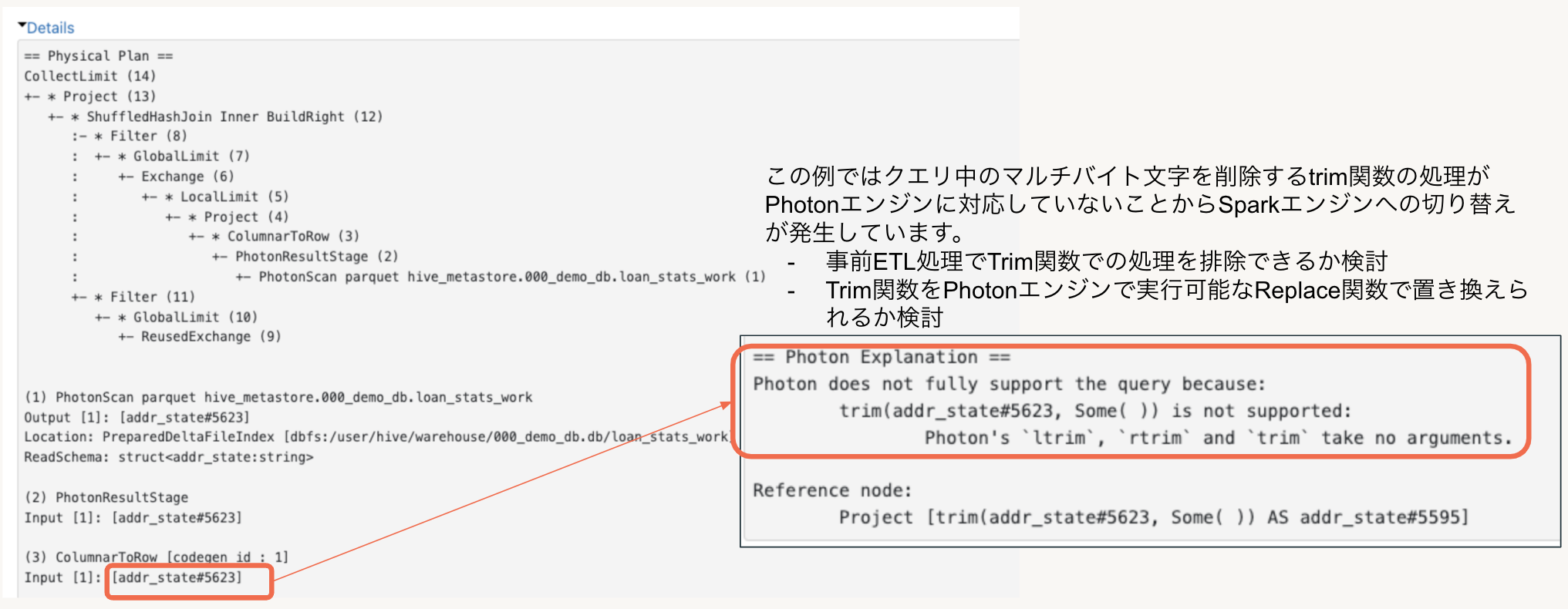
Photon未対応の処理の特定には先ほどのSparkUIのプランから”Details"リンクをオープンし詳細情報を参照します。
この詳細情報の中でPhotonエンジンからSparkエンジンへの切り替えの要因となった処理を特定する情報が出力されますので改善案を検討します。
ここでは、クエリ中のtrim関数の引数の指定がPhotonエンジンに対応していなかったことからSparkエンジンへの切り替えが発生していた際の改善方法を例としてご紹介します。
詳細情報の下の方にPhotonエンジンで処理できなかったタスクの情報が出力されます。
以下のメッセージ情報からクエリ中のtrim関数の引数指定方法の問題であることがわかりました。

このケースでは以下のいずれかの方法でPhotonエンジンを使用できるようになります。
- ユーザクエリで使用するテーブル作成時に実行するETL処理で必要なデータをカラムにセットし、クエリ実行時のTrim関数の使用が不要となるようにデータ格納しておく
- Trim関数をPhotonエンジンで実行可能なReplace関数を使用して実行する
この例のケースではクエリ内のTrim関数をReplace関数に変更することでPhotonエンジンを使用することができました。
以下のようにSparkUIのプランDetailの最下部の表示が全て”The query is fully supported by Photon.”となっていることが理想的です。

※Photon対応の拡張は継続して実行されており、現在trim関数はPhotonエンジンで処理可能です。
補足:SparkUIを使用したプランの確認方法
Databricksの汎用クラスタ・ジョブクラスタからクエリを実行している場合は、直接Spark UIからクエリプランを確認できます。
①Notebookのアウトプットからクエリ実行の結果に表示されるSpark UIへのリンクをクリックするとGUIが起動します。
②Associated SQL queryをクリックします。
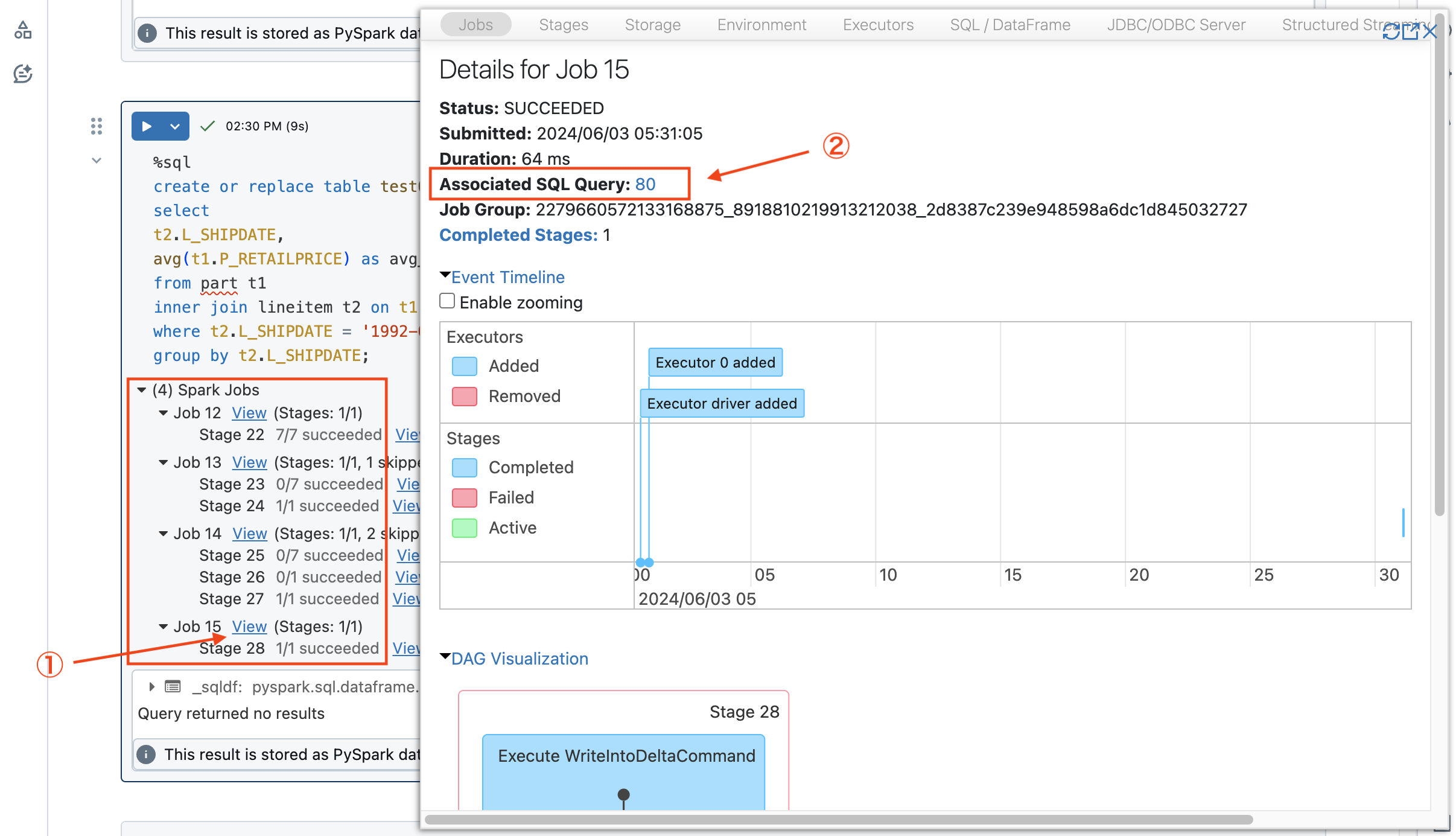
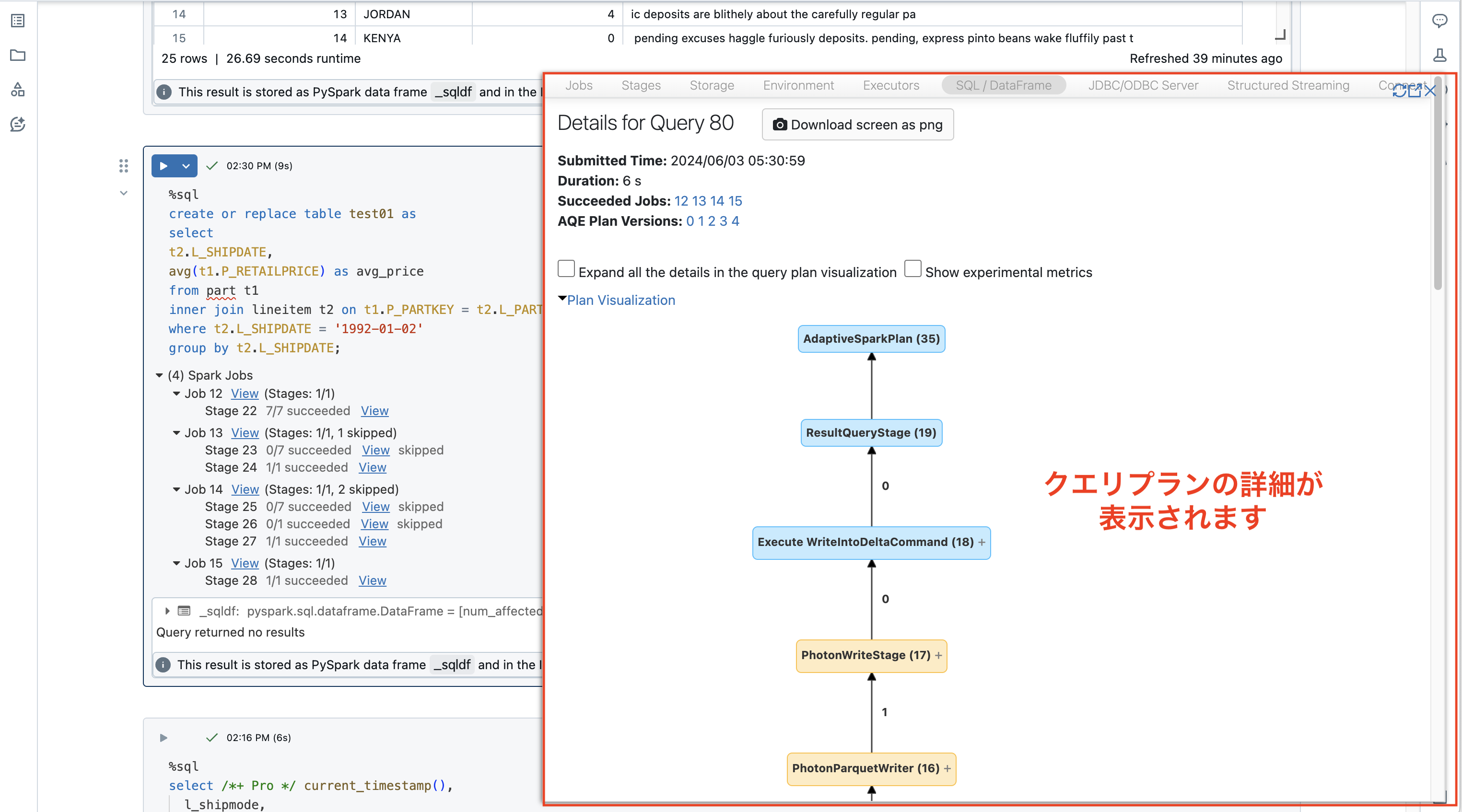
以下のように該当クエリのプランが確認可能です。
Photonの利用可否に関する情報も同様に確認できます。
4.クラスタサイズの調整
DatabricksSQLを構成するクラスタのスケールアウトやスケールアップを行うことで、クラスタのリソースを増やすことができます。DatabricksSQLではSQLクラスタを複数起動することで複数のワークロードを独立して実行し、リソースの競合を回避することもできますが、ここでは単一のDatabricksSQLサーバレスクラスタのサイジング方法について説明します。
参考リンク:https://learn.microsoft.com/ja-jp/azure/databricks/compute/sql-warehouse/create
クラスタの稼働状況のモニタリング
実運用に近いワークロードでクラスタの稼働状況を確認してください。クラスタサイズはMくらいから始めモニタリング機能でレイテンシーや同時実行性を確認します。
DatabricksSQLを構成するクラスタをモニタリングするには、SQL ウェアハウスの名前をクリックし、[モニタリング]タブをクリックします
参考リンク:https://learn.microsoft.com/ja-jp/azure/databricks/compute/sql-warehouse/monitor
以下の情報をモニタリング可能です。
- ピーク時のクエリー数
- 実行クエリ数
- キューされたクエリ数
- 実行中クラスタ数
- オートスケールの履歴
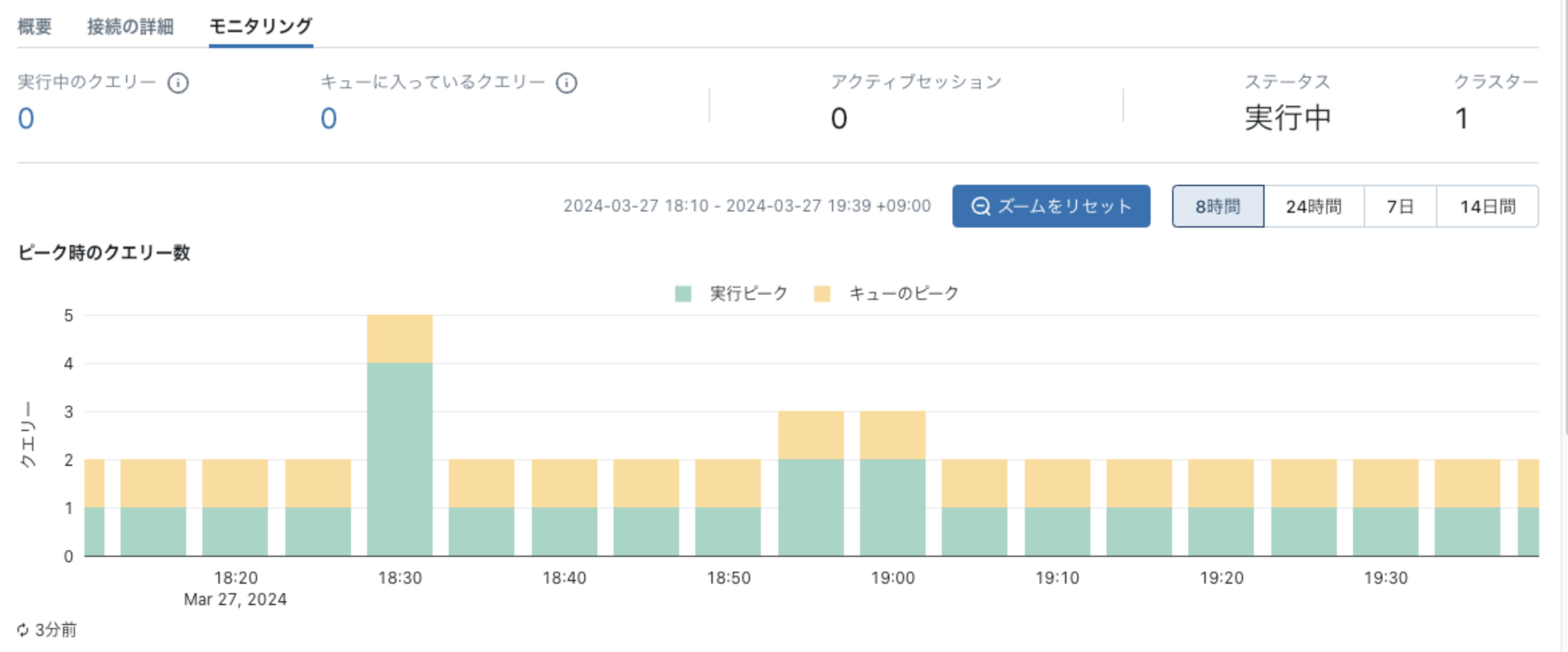
以下の状態が理想的です。
- キュー待ちしているクエリがない
- CPU/メモリ/ディスクスピルなどのリソースに起因する問題が発生していない
スケールアウト/スケールアップの選択の基準を以下に示します。
(1)スケールアウト
クエリの同時実行数が多く、多数のキュー待ちが発生している場合に適しています。SQL単体での実行ではCPU/メモリ/ディスクスピルなどのリソースに起因する問題が発生していないが、同時実行クエリ数の増加に伴いパフォーマンス劣化が発生している場合にはSQLエンドポイントを構成するクラスタ数を増加させるスケールアウトを検討してください。
DatabricksSQLのウェアハウスに割り当てられたすべてのクラスターが最大容量でクエリを実行している場合、クエリをキューに入れます。キュー待ちしているクエリ数の情報から最大クラスタ数を決定してください。
クエリパフォーマンスを優先する場合時にはキュー待ちが発生しなくなるまでクラスタを増加させることが望ましいです。
(2)スケールアップ
SQL単体での実行パフォーマンス向上が必要な場合、特にCPU/メモリ/ディスクスピルなどのリソースに起因する問題が発生している場合は単一のクラスタあたりの並列度を増加させるスケールアップを検討してください。
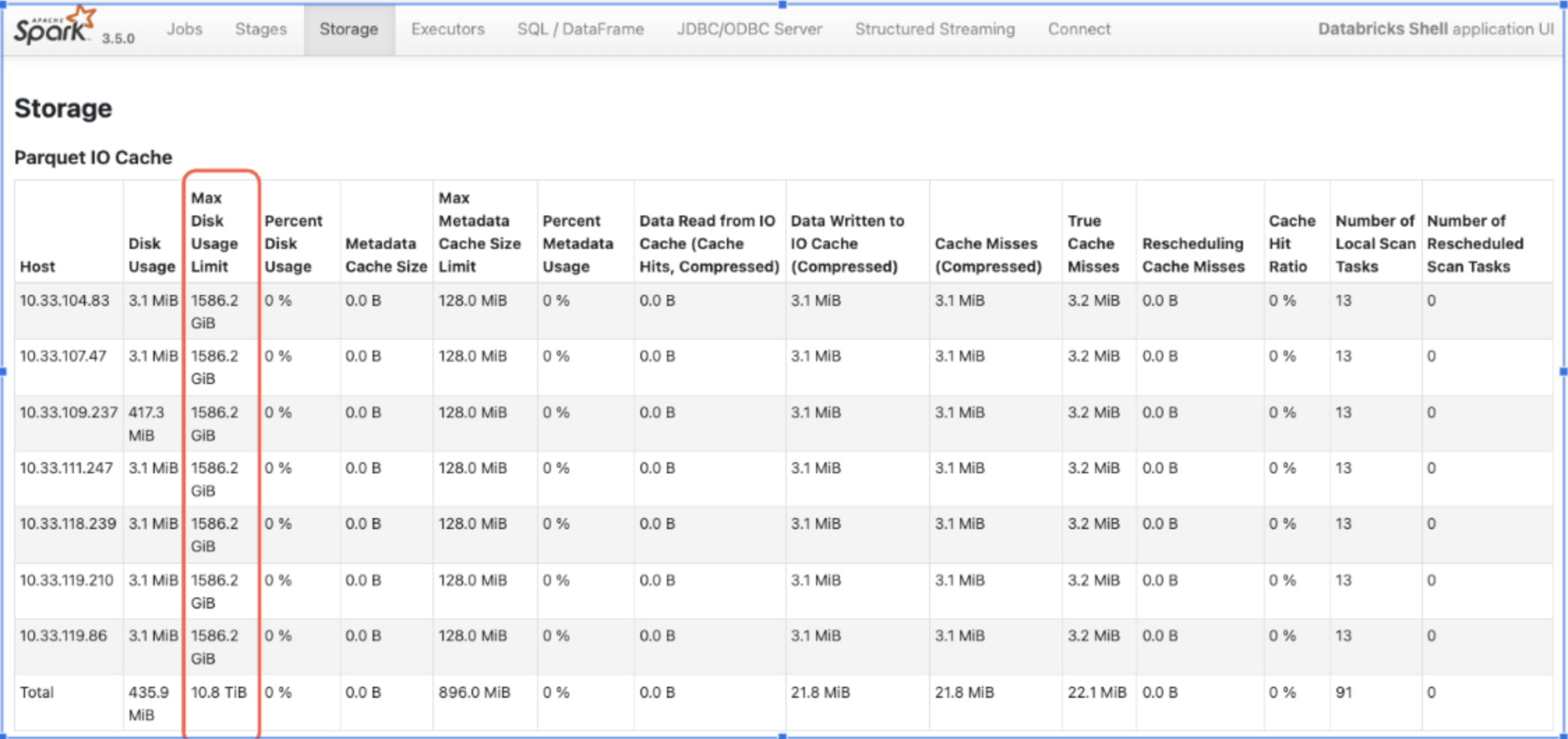
尚、DatabricksSQLではデフォルトでキャッシュが有効になっておりますが、キャッシュサイズをパラメータで調整することはできません。ディスクキャッシュヒット率が低い場合はスケールアップすることでディスクキャッシュサイズを拡張できます。
参考リンク:https://learn.microsoft.com/ja-jp/azure/databricks/optimizations/disk-cache

キャッシュサイズの確認は前述のSparkUIから"Storage"を選択するとキャッシュとして利用可能なストレージサイズを確認できます。
補足:クラウドストレージのボトルネックの有無を確認
DatabricksSQLクラスタのスケールアップ/スケールアウトを実行しても期待するパフォーマンスの向上が得られない場合、クラウドストレージでI/Oボトルネックが発生している可能性があります。
クラウドリソースがボトルネックとなっている場合はストレージ アカウントあたりの既定の最大Egresや、ストレージ アカウントあたりの最大要求レートなど、クラウドリソースの制限値を緩和することで、パフォーマンスを改善できる場合があります。
前述のI/O最適化及び結合プランの改善を実施しても期待するパフォーマンスが得られない場合、クラウドストレージへのアクセスがボトルネックとなっているかどうかを冗長化モードのプロファイラのメトリクスから確認してください。
- Cloud storage retry count (この統計値が0となっていることを確認)
- Cloud storage retry duration (この統計値が0となっていることを確認)
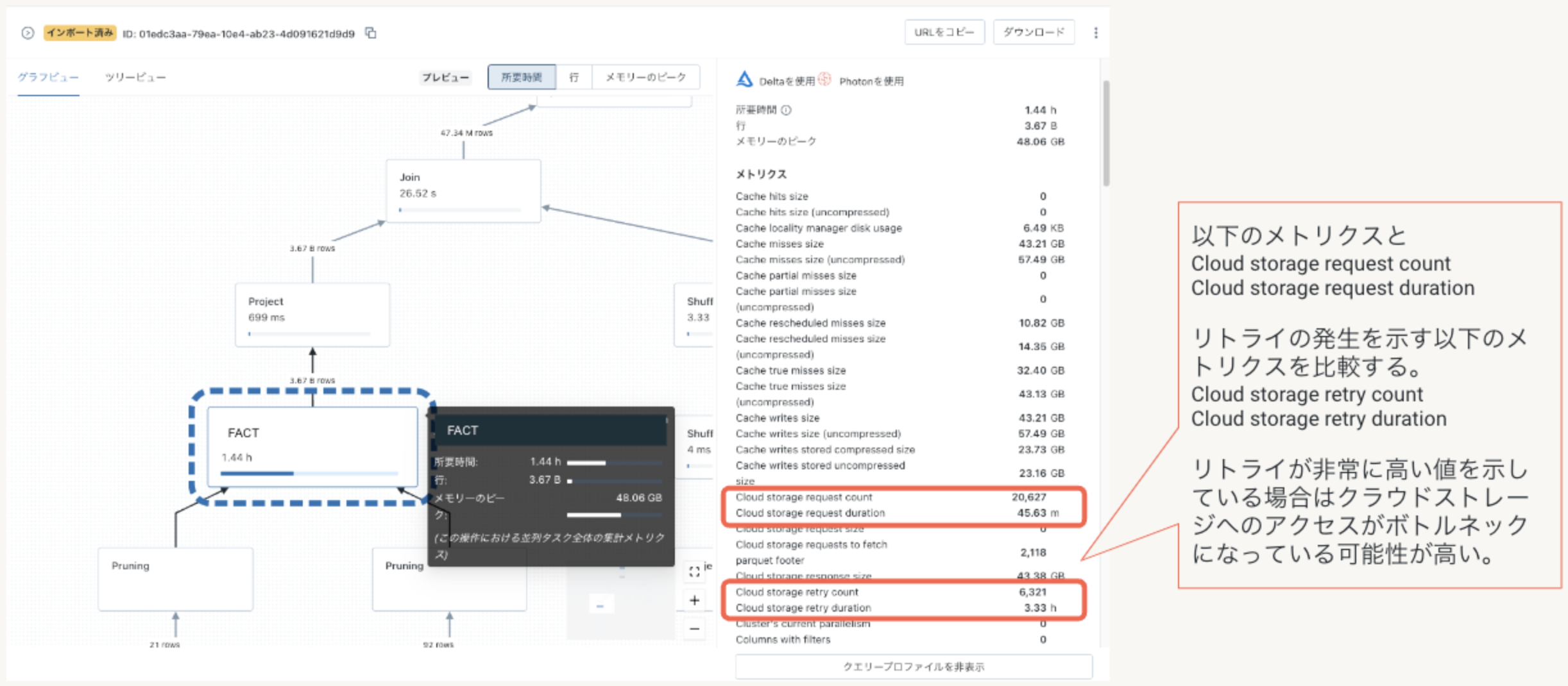
通常はDatabricksのストレージキャッシュによりクラウドストレージがボトルネックとなることはほとんどありませんが、クエリ実行時に常にリトライ発生しているような場合にはクラウドリソース(Storage IO)制限の緩和を検討します。
クラウドリソース(Storage IO)制限の緩和するには各クラウドベンダのサポートにお問い合わせください。
以下はAzure環境の例となりますが、ドキュメントに記載の以下の制限値を緩和することでストレージボトルネックの解消が期待できます。
参考リンク:https://learn.microsoft.com/ja-jp/azure/azure-resource-manager/management/azure-subscription-service-limits#storage-limits
-
汎用 v2 および BLOB ストレージ アカウントあたりの既定の最大エグレス
デフォルト: 50Gbps (ストレージの種類により異なります)
推奨値:1TBbps -
既定のストレージ アカウントあたりの最大要求レート
デフォルト:1 秒あたり 20,000 要求
推奨値:1 秒あたり 100,000 要求
さいごに
この記事ではDatabricksSQLのクエリプロファイラを使用したボトルネックの調査方法とチューニング方法を筆者の経験を元にまとめました。ボトルネックの要因はユースケースによりは様々ですが、今回ご紹介しましたボトルネックの発見方法と対応のアプローチは多くのケースで活用できるかと思います。
今回の記事ではご紹介できなったコンフィグパラメータやチューニングの手法もございますので今後も継続してご紹介できればと思っております。
本記事の内容がみなさまのお役に立てば幸いです。