はじめに
株式会社NTTデータグループ 技術革新統括本部技術開発本部のnttd-kitabahです。
2023/12/8にデータブリックス・ジャパン株式会社主催のユーザ会、
JEDAI 2023 X'mas/忘年会 Meetup!で「Databricksチューニングあれこれ」というタイトルで従来のチューニングとDatabricksの新機能であるリキッドクラスタリング/Predictive IOを性能比較した結果をたのしくLTしてきました。
発表で使用した資料はこちらに掲載しております。
今回は登壇内容と会場の雰囲気をお伝えします!
登壇者ってだあれ?

- 左:北波 (nttd-kitabah)
- 普段はOSSを扱うチームに所属し、Apache Sparkの性能検証などを実施しています。
- Databricksの新機能でAPチューニングが楽になれば嬉しいと思い、今回の企画を進めました。
- 右:板垣 輝広さん
- データブリックス・ジャパン株式会社 Sr. Specialist Solutions Architectです。
- 製品スペシャリストエンジニアとして主にDWHからDatabricksへの移行やSQL/Sparkチューニングを実施されている方です。今回の企画を一緒に進めてくださいました。
とりあえず結論は?
Databricksの新機能であるデータの物理配置を自動調整してくれるリキッドクラスタリングは、Databricksでのクエリの性能チューニング手法として有用でした。
今までよく使われていたパーティショング+Z-Orderと同等以上の性能を出すことができ、パーティション設計によるデータ物理配置を固定で実施しない分非定型分析でも非常に有効に機能します。
自動でI/O効率を向上させる機能であるPredictive I/Oも、特にクエリにWhere条件があってもチューニングにヒットしないようなケースにおいて効果的と考えています。
さらに今後はリキッドクラスタリングはキーの自動設定機能が追加されるなど改良されるため、従来のチューニングと比べてもっと性能が良くなる可能性が高いです。
ただ、今回試せていないチューニング方法もあるため、今後継続して検証していきたいです。

こんな感じでゆるくかわいいスライドなので、ぜひ資料の方もご覧ください~。
検証ってどんなの?
Databricksの新機能と従来手法での性能チューニング方法を比較してどちらが有用か確認したいと思い検証を進めました。(Databricksの新機能については後述)
検証対象の4つのクエリは以下の表です。
| クエリ概要 | 選定観点 | |
|---|---|---|
| 1 | フルスキャン | 素早く取得できるか。 コンパクションとPredictive I/Oが有用そう。 |
| 2 | 3つのカラムでの絞り込み | これはやらないとね。 従来手法でのチューニング(パーティション+Zorder)との全力での競り合いを見たい。 |
| 3 | パーティションキー指定なし 2つのカラムでの絞り込み |
リキッドクラスタリングのかっこいいとこみてみたい♪ |
| 4 | パーティションキー指定のみ 1つのカラムでの絞り込み |
新機能と従来のパーティション設計手法どちらが有用か… |
※詳細は資料 P13-16
また、TPC-Hベンチマークデータを3つ使用しました。
CSVテキスト換算大体3.8TB、一番大きなテーブルはCSVテキスト換算:約3.7TBの約300億件のサイズ感です。
どうやって実行比較をしたの?
実行パターンは以下の表のように3つ検証しました。
| 実行パターン | 選定観点 | |
|---|---|---|
| 1 | チューニングなし | チューニングを全くしないケース。 以下2つのチューニングの効果を測るための基準値として計測。 |
| 2 | 従来のチューニング (パーティション+Z-Order) |
従来TB以上の大規模テーブルでは一般的に実施されているパーティション+Z-Orderによる鉄板チューニング。 明示的なデータパーティションをユーザ側で指定できるのが強み。 |
| 3 | 新機能のチューニング(リキッドクラスタリング) | リキッドクラスタリングでパーティション設計なしで、コンパクション+データクラスタリングを実施する。 ※ランタイム13.x以上でサポート |
Datrbricksの新機能はリキッドクラスタリングとPredictive I/Oを検証しました。
- リキッドクラスタリング
- Databricksランタイム13.2以降に追加され、クラスタリングキーを柔軟に定義してくれる、ユーザによるパーティション設計要らずかもしれない機能です。
- 詳しくは Delta テーブルにリキッドクラスタリングを使用する
- Predictice I/O
- Databricksランタイム11.2以降に追加され、ディープラーニングでクエリの検索条件の確率を計算して最適な読み込みをしたり、不要な列や行のデコードを行ってくれる機能です。
- 詳しくは 予測 I/O とは
従来のチューニング方法にはパーティショニングとZ-Orderを使用しました。
公式マニュアルにあるように、リキッドクラスタリングはパーティショニングとZ-Orderをリプレースするものである、とあったため本当なのか検証したいと思い選定しました。
結果と考察は?
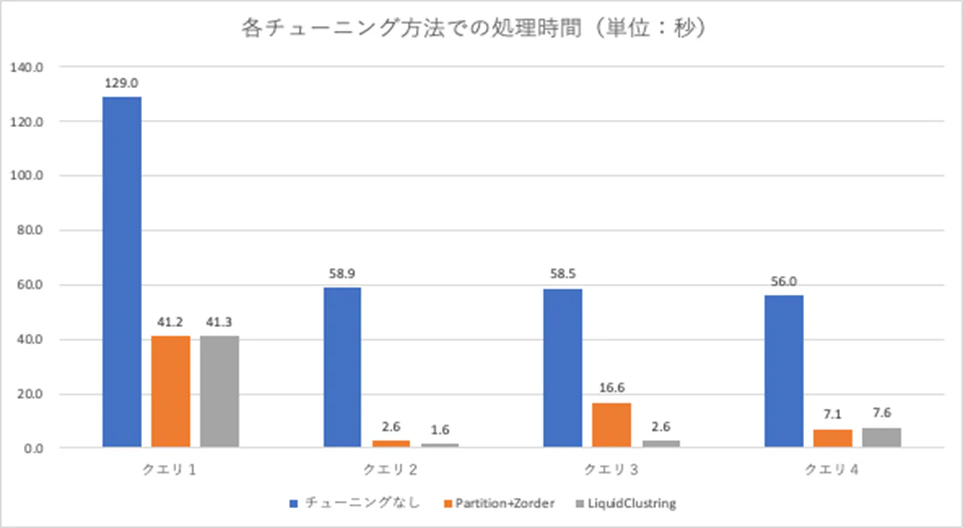
リキッドクラスタリングでの結果は従来の性能チューニング方法であるパーティショニングとZ-Orderと同等以上であり、クラスタリングキーの変更もテーブルの再作成が不要なため非常に簡単です。
| クエリ | 考察 | |
|---|---|---|
| 1 | フルスキャン | リキッドクラスタリングもZ-Orderもコンパクションによって速くなったようである。 |
| 2 | 3カラムでの絞り込み | どちらも効果があるようだが、リキッドクラスタリングの方が約1.5倍パフォーマンスが向上。 Where句で絞り込み条件を全て指定したことにより、リキッドクラスタリングによるアクセス対象ファイルの削減効率が高くなったためと考えている。 |
| 3 | パーティションキー指定なし 2つのカラムでの絞り込み |
リキッドクラスタリングのI/O削減効率がZ-Orderを上回り、6倍以上のパフォーマンス向上がみられた。 Z-Orderとパーティショニングは、やはりパーティションキーの指定がないと性能が出ないようである。 |
| 4 | パーティションキー指定のみ 1つのカラムでの絞り込み |
リキッドクラスタリングとZ-Orderは同等のパフォーマンスであった。 |
リキッドクラスタリングではクラスタリングキーに設定したキーがWhere句で使用されている数によりI/O削減効率が異なりますが、過半数のクラスタリングキーが指定されるケースではパーティションよりもI/O削減効率が良い結果となっている印象です。
また、チューニング設定したカラムを徐々に絞り込み条件から減らしていった場合でもI/O効率の低下は緩やかで、パーティションテーブルのようにパーティションキーで指定したカラムが絞り込み条件に指定されていないと急激に遅くなることもないため、定型・非定型どちらのクエリにも適しています。
ちなみに、Predictice I/Oが有効なランタイム(11.2以上) にするだけで約1.5〜2.9倍のパフォーマンス向上が見られました。
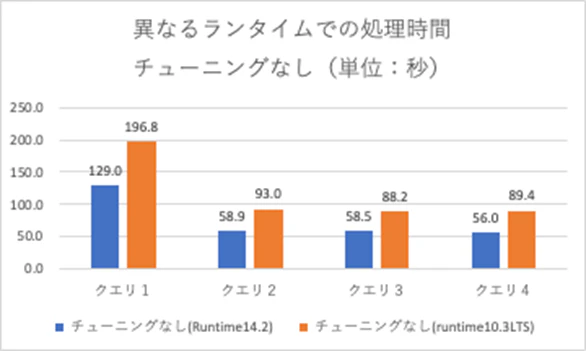
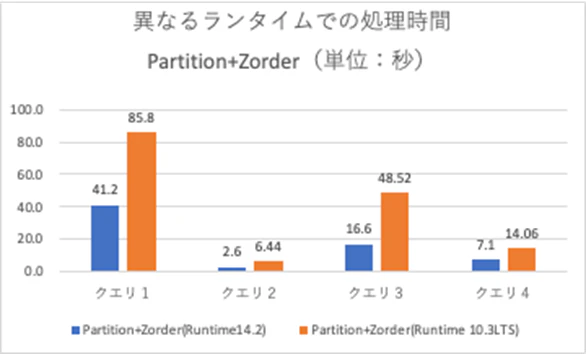
新しいランタイムはどんどん使っていきましょう!

さて、今回の検証ではチューニングの有無で最大37倍の差が出てでいるケースもありました。
リキッドクラスタリングとPredictice I/Oは簡単に利用できますので是非試してみるのはいかがでしょうか。
すでにZ-Orderを使いこなしている方はリキッドクラスタリングとZ-Orderには大きな違いはないように感じられるかもしれませんが、リキッドクラスタリングにはいくつかのアドバンテージがあるようです。
Z-OrderとリキッドクラスタリングのI/O削減効率は基本的には同程度ですが、リキッドクラスタリングの方が長期運用でもパフォーマンスの劣化が起きにくく、明示的な最適化処理(Optimize)の時間短縮が可能なエンハンス(データ書き込み時のクラスタリング)により、大規模テーブルにも対応できるようになるようです。
詳細は資料のP21をご確認ください。
他にもチューニングポイントはある!今後の展開について
- 従来のチューニングについて
- 今回はパーティショニングとZ-Orderを従来の性能チューニングとして実施しましたが、もっと性能チューニングできるポイントもあります。こちらにDatabricksの性能に関する新機能をほかのチューニング方法とも競わせてみたいです。
- リキッドクラスタリングについて
- リキッドクラスタリングは今後も改修予定で、Predictive Optimizationによるデルタテーブルの最適化により、オペレーションを自動的に識別し管理オペレーションの自動化が可能になるようです。
簡単に言うと、クエリや扱うデータが変化した場合でも常に最適なパフォーマンスを維持できるよう、利用状況からDatabricksがクラスタリングキーを自動選定し、まさにリキッド(水)のように柔軟にデータの物理配置を最適化してくれるようになります。統計情報の取得やバキュームも同時にやってくれるようになるので楽しみですね!
詳細は資料のP22をご確認ください。
このような形で今後もっと面白い機能も追加されるので、追加機能の検証をしていきたいです。
会場の雰囲気と登壇した感想!

会場は広くて、とても綺麗でした。立食スペースもあり、ご飯がおいしかったです。
私は登壇前にも関わらずケーキを制覇しました。幸せでした。

沢山の普段Databricksを使用している方々がいらっしゃったのですが、登壇してみて意外と性能チューニング話は受けが良かったです。皆さん同じく性能に関しては気になるところなのだと思いました。
Databricksを導入するだけでなく、導入後扱うデータ量の変化やソースコードの改修が入った際にはどのように性能改善していくかが重要という意識を持たれていました。
質問してくださった皆さん、ありがとうございました!
今後どこかで追加発表出来れば嬉しいです。

おわりに
株式会社NTTデータグループ・NTTデータでは、Databricksに関わらず様々なOSSのサポートをしています。
お困りの際にはぜひお問い合わせください。
楽しいクリスマスを!

仲間募集
NTTデータ テクノロジーコンサルティング事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、
お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、
お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。
https://nttdata.jposting.net/u/job.phtml?job_code=804
4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
NTTデータとDatabricksについて
NTTデータは、お客様企業のデジタル変革・DXの成功に向けて、「databricks」のソリューションの提供に加え、情報活用戦略の立案から、AI技術の活用も含めたアナリティクス、分析基盤構築・運用、分析業務のアウトソースまで、ワンストップの支援を提供いたします。TDF-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~https://enterprise-aiiot.nttdata.com/service/tdf/tdf_am
TDF-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとSnowflakeについて
NTTデータでは、Snowflake Inc.とソリューションパートナー契約を締結し、クラウド・データプラットフォーム「Snowflake」の導入・構築、および活用支援を開始しています。 NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。 Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
NTTデータとAlteryxについて
Alteryxは、業務ユーザーからIT部門まで誰でも使えるセルフサービス分析プラットフォームです。 Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。