はじめに
Databricksのコンポーネントの一つであるDatabricks SQLはデータウェアハウスのワークロードを非常に高速且つ低コストで実行することができます。
この記事では、既存データウェアハウスからDatabricksへ移行する場合において多くの問い合わせを受けるテーブルやプロシージャなどのデータベースオブジェクトの移行方法に焦点を当て、Databricksの各種機能を利用した実践的かつ効率的な移行手法、成功のためのヒント、注意すべきポイントをご紹介します。なお、記事中のDatabricksドキュメントへのリンクは主にAzure Databricksを参照していますが、AWSやGCP上のDatabricksでも同様の機能が提供されています。
データベースオブジェクトのマッピング
移行対象のデータウェアハウス製品によって機能に差異が存在しますが、一般的なデータウェアハウスのオブジェクトをDatabricksに移行する際の機能マッピングは以下の通りです。
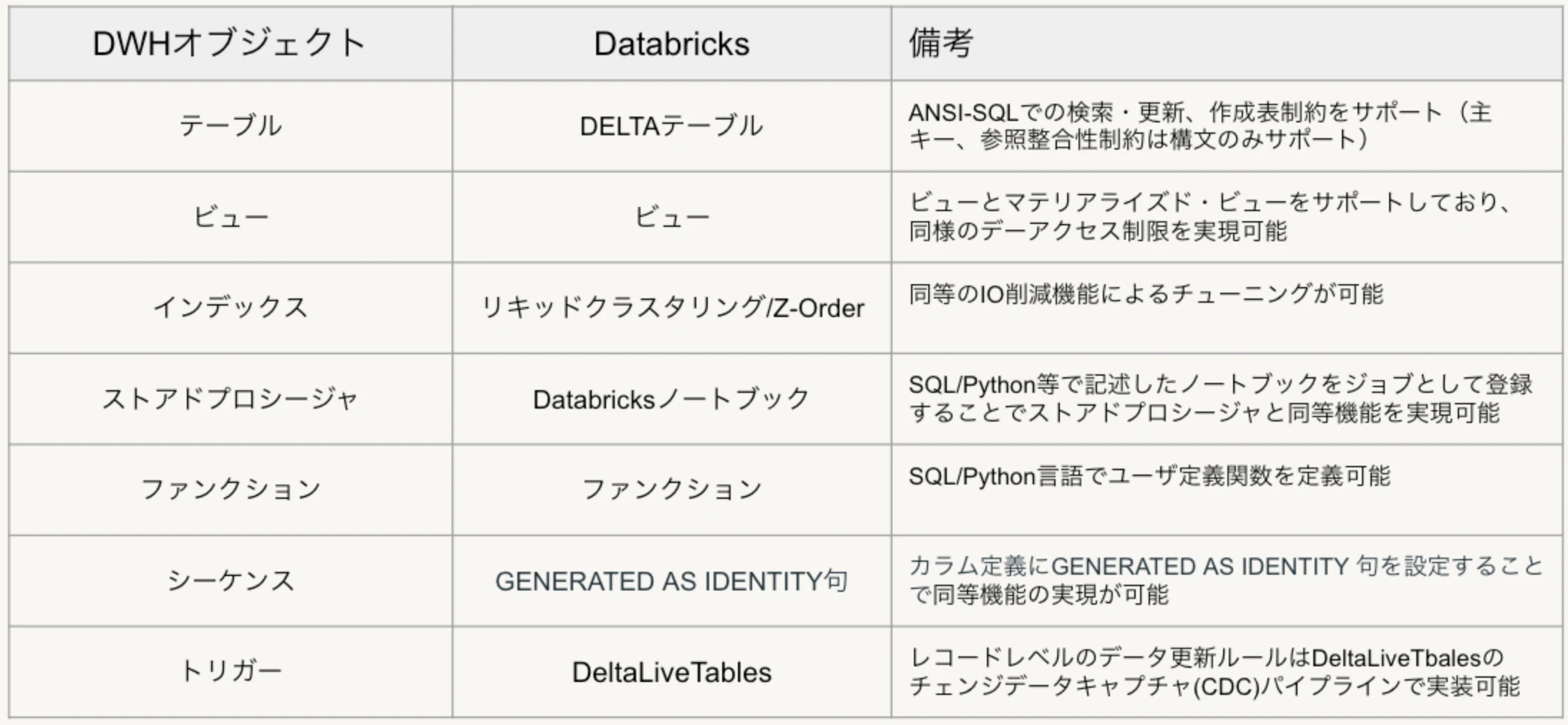
以下、データとアプリケーションの効率的な移行手法を中心に各種データベースオブジェクトの具体的な移行プロセスを解説します。
テーブルの移行
テーブル移行には以下の一般的な手法があります。
- 移行対象のデータウェアハウスからDDL文(CREATE TABLE文)をテキストで出力し、それをDatabricks用に変換します。
- Databricks上でテーブルを作成します。
- クラウドストレージに抽出したデータを出力し、Databricks上の新たに作成したテーブルにAutoloaderを使用してデータロードを実行します。
例として、以下のようなSynapseデータウェアハウスで作成されたテーブルがある場合、以下の修正を施しDatabircksにテーブルを作成します。
- Synapse固有のデータタイプ(numeric型、datetime型、nvarchar型など)を修正
- With句以下のSynapse固有のテーブルプロパティを削除
次に、移行元データウェアハウスの各テーブルのデータをDatabricksからアクセス可能なクラウドストレージに出力し、Databricks上に作成されたテーブルにデータをロードする手法が広く採用されています。
CREATE TABLE [dbo].[LINEITEM]
(
L_ORDERKEY integer
,L_QUANTITY numeric(15,2) ← Decimal型に変更
,L_LINESTATUS varchar(1)
,L_SHIPDATE datetime ← timestamp型に変更
,L_SHIPINSTRUCT nvarchar(25) ← String型に変更
,L_SHIPMODE nvarchar(10) ← String型に変更
,L_COMMENT nvarchar(44) ← String型に変更
)
WITH ←Synapse固有のテーブルプロパティの削除
(
DISTRIBUTION = HASH (L_ORDERKEY),
HEAP
)
この方法は多くのケースで効果的ですが、いくつかの課題が存在します。例えば、テーブルの数が多い場合、DDL文の抽出や修正に多くの時間が必要です。さらに、データをクラウドストレージに出力する必要があるため、運用上の制約が生じることがあります。
この記事では、レイクハウスフェデレーションを活用してテーブルを作成する方法と、データサイズや運用要件に応じて選択可能なデータロード手法をいくつか紹介します。
レイクハウスフェデレーションの活用と選択可能なデータロード手法
レイクハウスフェデレーションを使用してリモートデータウェアハウスに接続すると、そのデータベース内のテーブル一覧がUnity Catalogにリストされ、参照が可能になります。
レイクハウスフェデレーション(クエリーフェデレーション)はデータをDatabricksに移行せずに、複数のデータソースに対してDatabricksから透過的にクエリーを実行できるようにする機能です。
- サポート対象データベースと設定方法ついてはドキュメントをご参照ください。
- オンラインドキュメント
https://learn.microsoft.com/ja-jp/azure/databricks/query-federation/
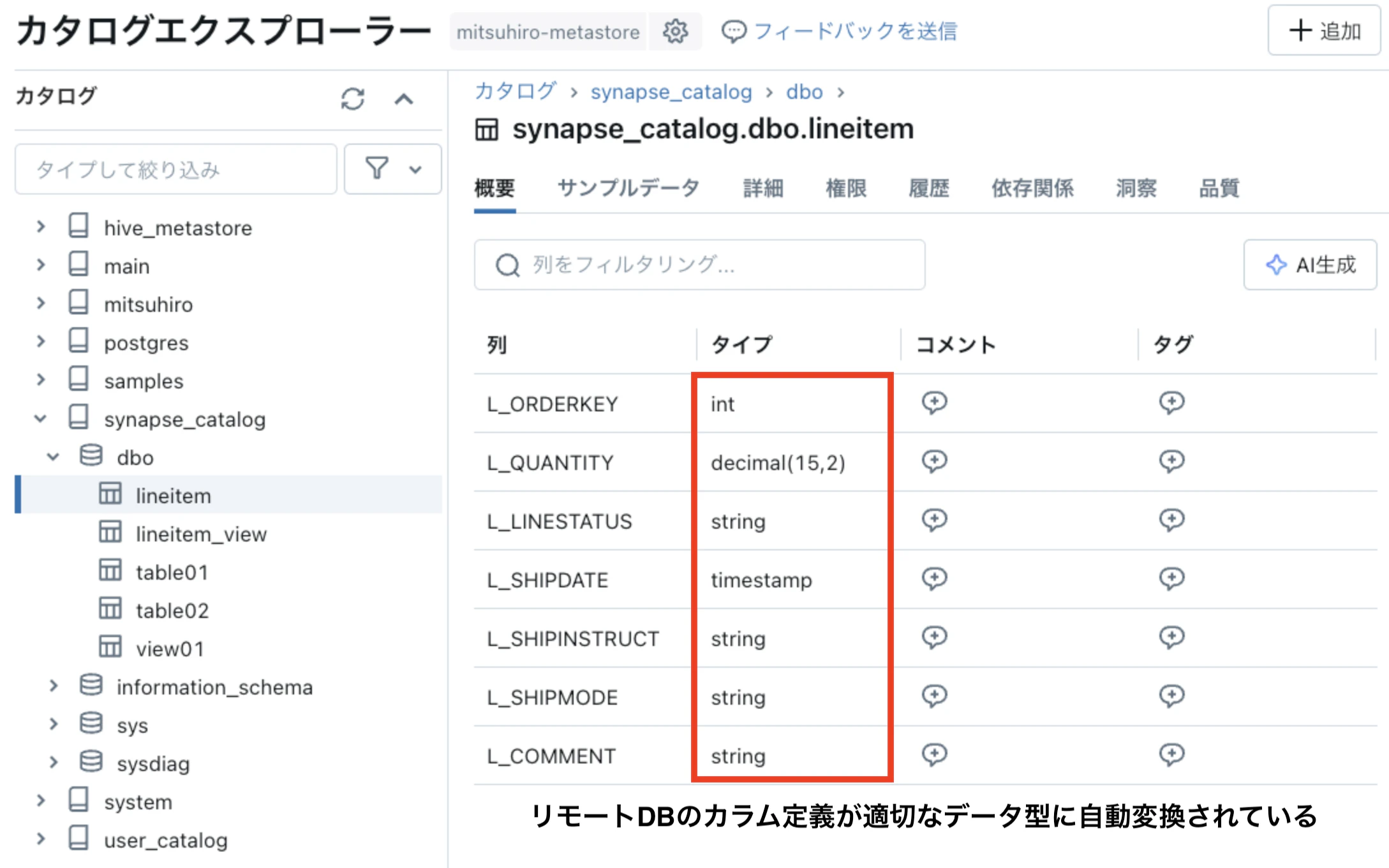
以下はレイクハウスフェデレーションを使用して移行元データウェアハウスに接続した後、Unity Catalogでのデータベース内のテーブル定義情報の表示例です。レイクハウスフェデレーションにより、リモートデータベース内の全てのテーブルがデータ型などスキーマ情報を含めて自動的に変換され、Databricksのローカルテーブルとして参照可能になっています。
テーブルの作成
Unity Catalogにリストされたリモートデータベースのテーブルは、Databricks上のデータベースで「CREATE TABLE AS SELECT」文を使用して直接参照しながらテーブルを作成することができます。これらのテーブルカラムのデータ型は既に適切なデータ型に自動変換されてリストされているため、DDL文の抽出や変換などの追加作業は不要で、全てのテーブルを簡単に作成できます。
CREATE OR REPLACE TABLE mitsuhiro.testdb01.lineitem_migrated <-- 新規テーブルを作成
AS
SELECT * FROM synapse_catalog.dbo.lineitem <-- レイクハウスフェデレーションで参照
limit 0;
レイクハウスフェデレーションを使用してデータロードを行うことも可能ですが、使用されるコネクタは内部的にシングルスレッドのJDBC接続であるため、大量データセットをリモートDBからDatabricksにネットワーク転送する処理には向いていません。このため、データロードはボトルネックにならない規模のデータやテスト目的での使用に限定することを推奨します。
レイクハウスフェデレーションではリモートDBで作成されたビューはテーブルとして認識されるため、ビューそのものをレイクハウスフェデレーションで移行することはできません。
データロード方法の選択
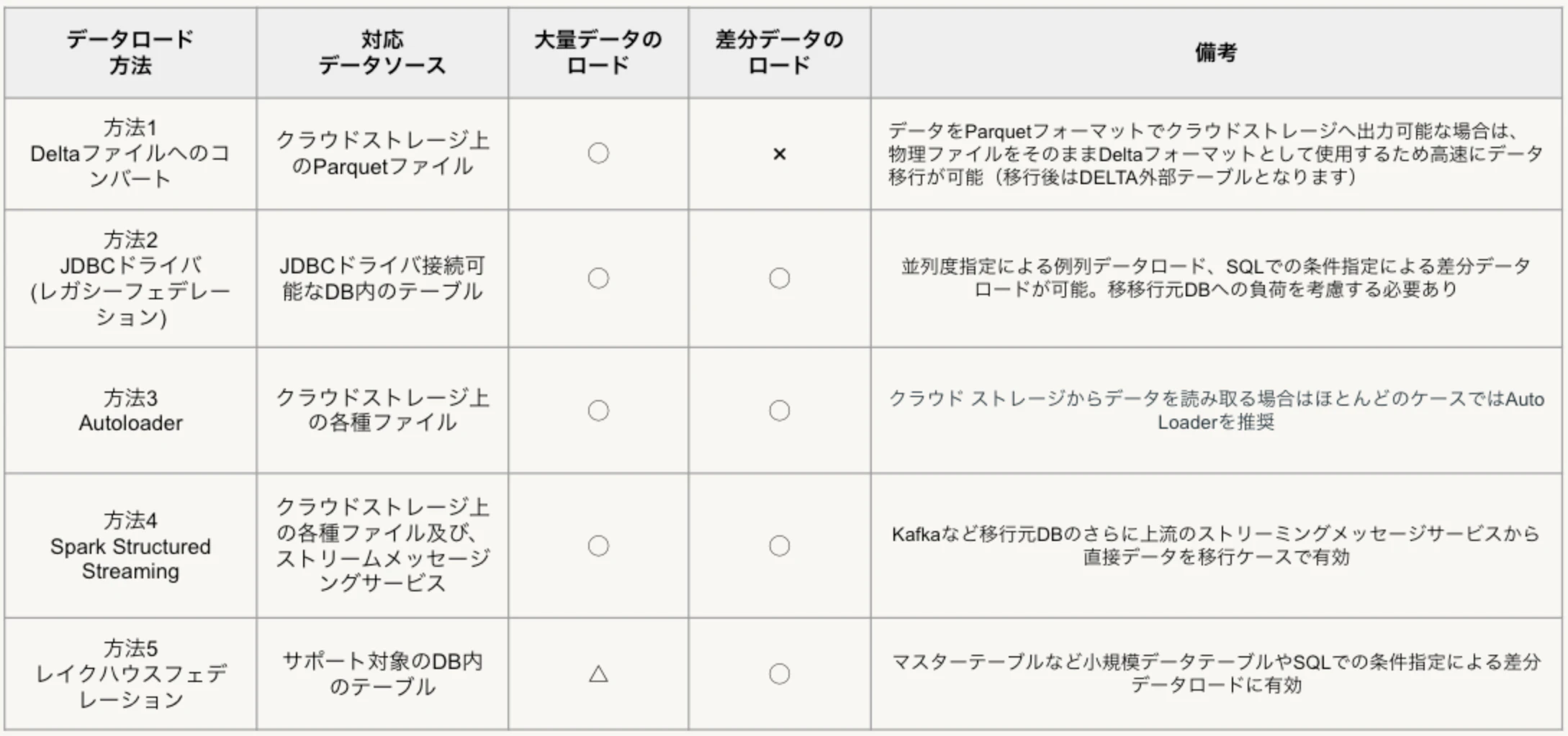
テーブルの作成が完了した後、移行要件に合わせたデータロード方法を検討します。大規模データの一括移行や継続的な差分ロードなど、要件によって最適なロード方式が異なります。検討すべきデータロードオプションには、以下のようなものがあります。
方法1:ParquetからDeltaへの変換
移行元のデータウェアハウスのデータをParquetフォーマットでDatabricksがアクセス可能なクラウドストレージに出力し、その後Deltaフォーマットに変換する方法は、大規模データの移行を一括で完了させる際に適しています。この方式は、Databricksの外部テーブルにデータを効率的に移行するのに特に有効です。
ドキュメントURL:https://learn.microsoft.com/ja-jp/azure/databricks/sql/language-manual/delta-convert-to-delta
方法2:JDBCドライバでの並列データ読み込み(レガシーフェデレーション)
移行元のデータウェアハウスにJDBCドライバを使用して接続し、spark.read を利用した並列データ読み取りによりデータを移行する方法です。この手法は大規模データのロードや、SQLで条件を指定した差分データのロードに適していますが、移行元のデータウェアハウスへの負荷を考慮する必要があります。
ドキュメントURL:
https://learn.microsoft.com/ja-jp/azure/databricks/connect/external-systems/jdbc#control-parallelism-for-jdbc-queries
方法3:Autoloaderでのデータロード
任意のフォーマットでDatabricksからアクセス可能なクラウドストレージにデータを出力する場合、Autoloaderを使用してデータロードを行います。この方法は大規模データロードや差分データロードにも適用可能です。また、ロード対象のファイル数が多い場合など、パフォーマンスを改善するためのオプションもサポートされています。
ドキュメントURL:
https://learn.microsoft.com/ja-jp/azure/databricks/ingestion/auto-loader/
方法4:Spark Structured Streamingでのデータロード
ロード対象データを移行元のデータウェアハウスやクラウドストレージ以外から直接取得したい場合は、Apache Spark Structured Streamingを使用してください。この方法は、リアルタイムでの差分データロードに特に適しており、ストリームメッセージングサービスからデータを効率的に取り込むことが可能です。
ドキュメントURL:
https://docs.databricks.com/ja/connect/streaming/index.html
方法5:レイクハウスフェデレーションでのデータロード
この方式はマスターテーブルなどの小規模データテーブルや、SQLで条件を指定した差分データのロードに適しています。ただし、前述したようにシングルスレッド接続であるため、大規模データセットのロードには不向きです。大規模データに対しては、異なるデータへアクセスするクエリを複数ジョブで実行する方法もありますが他の方式の使用が推奨されます。
新規テーブルの作成や小規模データの移行には、レイクハウスフェデレーション機能を活用することが特に効果的です。一方で、大規模データの初期ロードや、その後の差分データのロードについては、移行期間や並行稼働の要件を考慮して適切なデータロード方式を選定することが推奨されます。
さらに、これらのプロセスをサポートするために各種サードパーティツールも利用可能です。
https://docs.databricks.com/ja/integrations/index.html#technology-partners
ビューの移行
ビューの移行は一般的に以下の手法で行います:
- 移行対象のデータウェアハウスからDDL文(CREATE VIEW文)をテキストで出力します。
- 出力されたDDL文をDatabricksで実行可能な形式に変換します。これには、製品固有のSQL構文をSpark SQL構文に変換し、ビューを作成する作業が含まれます。
ビュー定義中のクエリ構文の書き換えには、Databricksアシスタントの利用が効率的です。
Databricksアシスタントは、Databricksでサポートされるプログラミング言語やフレームワークに対応したコード生成、最適化、説明、修正を行うために最適化された大規模言語モデル(LLM)による対話型サポートツールです。
例としてSynapseのビューの変換例をご紹介します。
CREATE VIEW [dbo].[LINEITEM_VIEW]
AS
SELECT TOP 3
L_ORDERKEY,
ISNULL(L_QUANTITY,0) AS L_QUANTITY,
FORMAT(GETDATE(), 'yyyy-MM-dd HH:mm') AS GETDATE,
RANK() OVER (ORDER BY L_QUANTITY DESC) AS RANK
FROM dbo.LINEITEM
WHERE L_ORDERKEY BETWEEN 1 and 100
Synapse固有の構文を含んでいるためDBアシスタントを使用してクエリを変換します。
次のようにDBアシスタントのチャットウィンドウに入力してみます。

以下の回答が生成されました。
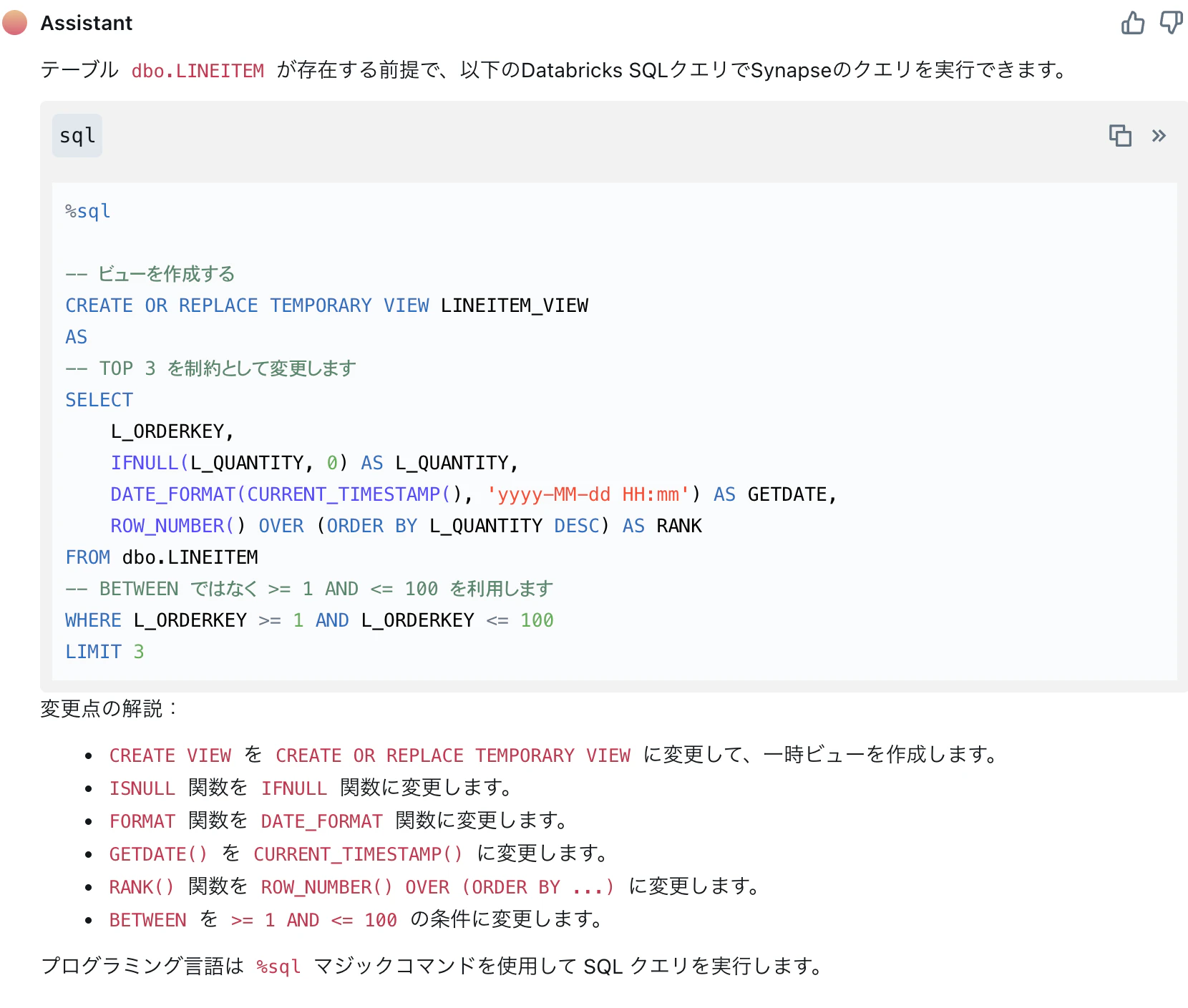
製品固有の構文の差異は正しく変換され、ほぼそのまま実行可能なクエリが生成されています。(ただし、今回テンポラリビューに関連するTEMPORARY句は削除しました。)全てのクエリが正しく変換されているかの最終確認は実データで行う必要がありますが、これまでのPoC(Proof of Concept)での実績においても、SQL構文の変更はDatabricksアシスタントによってほぼ完璧に実現できています。万が一エラーが発生しても、エラー情報からの適切なクエリ修正が可能です。SQL構文の差異も出力されるため、SQL開発者とって確認しやすくなっています。
クエリの変換・デバックはdatabricksアシスタントを活用しましょう。作業効率が格段に向上します!
インデックスの移行
Databricksではリキッドクラスタリングでインデックスと同様のI/O削減によるチューニングが可能です。
リキッドクラスタリングは従来のパーティショニング、Z-ORDERをリプレース可能な新しいI/O削減の機能としてリリースされました。機能についての説明は割愛しますが、特殊なソートにより物理的に近い位置に再配置することでI/Oスキッピングの効率を向上させることが可能です。
以下はCREATE TABLE文の例ですが、CLUSTER BY句でインデックスと同じくWhere句でフィルター条件として指定されるカラムを指定します。
CREATE TABLE LINEITEM
(
L_ORDERKEY int
,L_QUANTITY decimal(15,2)
,L_LINESTATUS timestamp
,L_SHIPDATE datetime
,L_SHIPINSTRUCT string
,L_SHIPMODE string
,L_COMMENT string
)
USING DELTA CLUSTER BY (L_ORDERKEY) <-- 最大4カラムまで指定可能
弊社ではすべてのテーブルにリキッドクラスタリングの使用を推奨していますが、リキッドクラスタリングはパーティションニングとの併用ができません。パーティショニングテーブルではZ-ORDERを使用してください。
チューニング手法の詳細については次のブログとドキュメントを参照ください。
ストアドプロシージャの移行
Databricksノートブックを使用して、ストアドプロシージャをSparkSQLとPythonで置き換えることができます。Databricksノートブックは非常に柔軟であり、外部ツールとの連携も可能です。また、Databricksのジョブとして登録することで、ストアドプロシージャと同等以上の機能と利便性を実現することができます。
- 任意のパラメータを伴う実行
- ループ処理や分岐処理などコード制御
- 入れ子構造の実装(ノートブック内で別のノートブックを実行)
- コード内で動的SQLの実行
- ノートブックIDを指定した実行
- Pythonライブラリの使用などML機能を含むSQL以上の機能の実装
- Databricksワークフローによるスケジュール実行、フェイルオーバなどの実行制御
- 該当ノートブックで参照されてるテーブルの確認などオブジェクト間の依存性の確認
- CI/CD連携 など
データウェアハウスにおけるストアドプロシージャは、SQLコードを管理しやすい単位にカプセル化し、データベース内に格納することで、トラフィックを軽減し、コードの再利用性を高めることができます。しかし、製品ごとの実装の違いやコードメンテナンスの難しさなどの課題があります。
Databricksノートブックはオープンな言語でのコーディングとCI/CD連携により、ストアドプロシージャの課題を解決しています。
Databricksアシスタントによるストアドプロシージャの変換
ストアドプロシージャの移行はSpark分散フラットフォームの特性を考慮したリファクタリングが必要となることもあり、従来はスクラッチで書き換えを実行することも多かったのですが、現在ではDatabricksアシスタントを利用した自動変換による効率化が可能です。
例として以下のSynapseのストアドプロシージャの変換例をご紹介します。
CREATE PROCEDURE PROC01 @O_ORDERPRIORITY SYSNAME
AS BEGIN
WHILE ( SELECT AVG(O_TOTALPRICE) FROM dbo.orders_w where O_ORDERPRIORITY = @O_ORDERPRIORITY) < 1300
BEGIN
UPDATE dbo.orders_w
SET O_TOTALPRICE = O_TOTALPRICE * 1.1
where O_ORDERPRIORITY = @O_ORDERPRIORITY;
SELECT MAX (O_TOTALPRICE) FROM dbo.orders_w
where O_ORDERPRIORITY = @O_ORDERPRIORITY;
IF ( SELECT MAX (O_TOTALPRICE) FROM dbo.orders_w where O_ORDERPRIORITY = @O_ORDERPRIORITY) > 1500
BREAK;
END
END;
次のようにDBアシスタントのチャットウィンドウに入力してみます。

次のような回答が生成されました。

以下はDatabricksアシスタンスの回答からコード部分を抜粋したものになります。
実際にジョブとして実装する際にはパラメータの指定部分に若干の修正は必要ですが、処理自体はそのまま実行可能なコードが生成されました。更にカラム名称と処理内容から自動生成されたコメントも正確であり、非常に精度の高いコードを生成可能であることがご理解いただけるかと思います。
# PySparkを使用した処理の実装
from pyspark.sql import functions as F
# 注文優先度を指定(例: '1-URGENT')
o_orderpriority = '1-URGENT'
# 条件を満たすまでループ
while True:
# 平均価格を計算
avg_price = spark.table("orders_w") \
.filter(F.col("O_ORDERPRIORITY") == o_orderpriority) \
.agg(F.avg("O_TOTALPRICE").alias("avg_price")) \
.collect()[0]["avg_price"]
# 平均価格が1300未満の場合、価格を10%増加
if avg_price < 1300:
spark.sql(f"""
UPDATE orders_w
SET O_TOTALPRICE = O_TOTALPRICE * 1.1
WHERE O_ORDERPRIORITY = '{o_orderpriority}'
""")
# 最大価格を計算
max_price = spark.table("orders_w") \
.filter(F.col("O_ORDERPRIORITY") == o_orderpriority) \
.agg(F.max("O_TOTALPRICE").alias("max_price")) \
.collect()[0]["max_price"]
# 最大価格が1500を超えた場合、ループを終了
if max_price > 1500:
break
else:
break
ai_query関数によるストアドプロシージャの変換
多くの大規模言語モデル(LLM)と同様に、Databricksアシスタントの出力は現在4096トークンに制限されています。これは、数千ステップを含む長いストアドプロシージャのコード変換を行う際に、最大トークン数を超えてしまうことがあるという問題を意味します。また、DatabricksアシスタントにはCLI(コマンドラインインターフェイス)やAPI(アプリケーションプログラミングインターフェイス)が提供されていないため、多くのプロシージャを手動で変換する必要があります。
このような状況に対処する方法として、簡単かつ効率的にプロシージャコードを変換するためにai-query関数を使用する方法を紹介します
ai_query関数はDatabricksSQLで利用できる組み込みのAI関数で、Databricksによってホストされる基盤モデル、外部モデル(Databricksの外部でホストされているサードパーティモデル)、モデルサービングエンドポイントによってホストされるカスタムモデルに対してSQLでアクセスすることが可能です。
以下のように3つのブロックから構成されるストアドプロシージャをai-query関数で変換する例を元にご紹介します。(誌面の都合上短いサンプルコードですがご了承くださいませ)
CREATE PROCEDURE PROC02 @O_ORDERPRIORITY SYSNAME
AS BEG
-----------
-- BLOCK1
-----------
WHILE ( SELECT AVG(O_TOTALPRICE) FROM dbo.orders_w1 where O_ORDERPRIORITY = @O_ORDERPRIORITY) < 1300
BEGIN
UPDATE dbo.orders_w1
SET O_TOTALPRICE = O_TOTALPRICE * 1.1
where O_ORDERPRIORITY = @O_ORDERPRIORITY;
IF ( SELECT MAX (O_TOTALPRICE) FROM dbo.orders_w1 where O_ORDERPRIORITY = @O_ORDERPRIORITY) > 1500
BREAK;
END
-----------
-- BLOCK2
-----------
BEGIN
DROP TABLE [dbo].[ORDERS_w2];
CREATE TABLE [dbo].[ORDERS_w2]
(
[O_ORDERKEY] [int] NULL,
[O_ORDERPRIORITY] [varchar](15) NULL,
[O_TOTALPRICE] [numeric](20,2) NULL
)
WITH
(
DISTRIBUTION = ROUND_ROBIN,
CLUSTERED COLUMNSTORE INDEX
);
END
-----------
-- BLOCK3
-----------
BEGIN
DECLARE @sql_fragment1 VARCHAR(100)=' INSERT dbo.orders_w2 '
, @sql_fragment2 VARCHAR(100)=' SELECT * FROM dbo.orders_w1 '
, @sql_fragment3 VARCHAR(100)=' WHERE O_TOTALPRICE > 1000';
EXEC( @sql_fragment1 + @sql_fragment2 + @sql_fragment3);
END
END;
Databricksアシスタントの入出力最大長を超える、長いストアドプロシージャコードの移行は次の3つのステップで実行します。
ステップ1:長大なストアドプロシージャコードの分割
プロシージャコードを適切なサイズのスニペットに分割し、コードのテキストを保存するテーブル(または外部テーブル)を作成します。
各スニペットの分割サイズはai_query関数でコールするLLMに依存します。最大は4096トークンなので正確なバイト数の算出はできませんが、サイズ感としては100-300ステップ程度を目安に分割してみてください。このアプローチにより、長いプロシージャも適切なサイズに分割して、各部分を個別に変換できるようになります。
以下は上のサンプルプロシージャコードを3つに分割し、識別IDとともに各スニペットに対応する変換指示プロンプトの入力も合わせて付与したテーブルの作成例です。
create or replace table query_list
( NO integer,
SQL_TEXT string,
INSTRUCTIONS string
);
以下は上記のテーブルに各変換対象のストアドプロシージャコードを分割してそれぞれをレコードとして格納した例です。

ステップ2:ai-query関数によるコードの変換
DatabricksSQLクラスタに接続し、上で作成した作成したテーブルのカラムをai-query関数の引数に指定してコンバートを実行します。以下はDatabircksの基盤モデルとして提供されているLlama3-70Bを使用したコード変換の実行例です。
https://learn.microsoft.com/ja-jp/azure/databricks/machine-learning/foundation-models/supported-models#meta-llama-3-70b-instruct
SELECT
NO,
ai_query(
"databricks-meta-llama-3-70b-instruct",
INSTRUCTIONS ||':'|| SQL_TEXT ) as databricks_code
FROM
query_list
Where NO between 101 and 103
上のai-query関数の実行結果の例は以下のようになります。
LLMで生成されたSparkSQL/Pythonコードがテキストでカラムに出力されています。

ステップ3:コンバート結果の統合
ai-query関数の出力結果から1つのDatabricksノートブックを作成します。
出力結果のコードテキストを1つのファイルに集約し.pyファイルで保存すると、Databricksノートブックから実行することが可能ですが、Databricksノートブックへの変換を行うためには、ファイルの冒頭に特定のコメントを追加する必要があります。
# Databricks notebook source
このコメントは、DatabricksがPythonスクリプトをノートブックセルに適切に分割して読み込むためのマーカーとなります。
# COMMAND ----------
マーカーを付与して保存した.pyファイルをDatabricksにアップロードし、インポートするとDatabricksはこのファイルをノートブックとして認識します。
databricksアシスタント、ai_query関数により自動変換で生成されるストアドプロシージャコードの変換コードの品質は細かな部分の修正とテストはまだ必要ですが、Spark分散フラットフォームに合わせた処理方式のリファクタリングもしっかりと考慮されたコードを生成することができ、非常に高品質のコードが生成できているという印象です。これまで時間がかかっていたストアドプロシージャの移行も非常に短期間で実現できる可能性がありますので今後も検証していきます!
ファンクションの移行
Databricksでは、SQLやPythonを使用して、一連の引数を受け取り、実行結果としてスカラー値や行のセットを返す関数を作成できます。これにより、他のデータウェアハウスで使われていたユーザー定義関数も、Databricksに移行して使用することが可能です。
Pythonでは、scikit-learnなどのライブラリを含むサポート対象のライブラリをインポートすることでより複雑な処理を行うことができます。さらに、REST-APIをSQLコマンドとして実行することも可能です。
CREATE FUNCTION roll_dice()
RETURNS INT
NOT DETERMINISTIC
CONTAINS SQL
COMMENT 'Roll a single 6 sided die'
RETURN (rand() * 6)::INT + 1;
CREATE FUNCTION weekdays(start DATE, end DATE)
RETURNS TABLE(day_of_week STRING, day DATE)
RETURN SELECT extract(DAYOFWEEK_ISO FROM day), day
FROM (SELECT sequence(weekdays.start, weekdays.end)) AS T(days)
LATERAL VIEW explode(days) AS day
WHERE extract(DAYOFWEEK_ISO FROM day) BETWEEN 1 AND 5;
CREATE FUNCTION main.default.isleapyear(year INT)
RETURNS BOOLEAN
LANGUAGE PYTHON
AS $$
import calendar
return calendar.isleap(year) if year else None
$$
大量のレコードセットに対して処理を実行するスカラー関数を作成する場合、パフォーマンスを優先する場合はPython関数ではなくSQL関数を使用してください。
シーケンスの移行
テーブルの行に一意のIDを自動的に割り当てるような用途において一般的なデータベースシステムでは自動インクリメントIDを生成するSequenceオブジェクトが使用されますが、Databricksではテーブルのカラム属性GENERATED ALWAYS AS IDENTITY句を指定することで同様の機能を提供します。
-- 常にシステムによりIDが生成されユーザーはセットすることはできません。
CREATE TABLE DATA_WITH_ID1
(ID LONG GENERATED ALWAYS AS IDENTITY (START WITH 1 INCREMENT BY 1),
DATA STRING
);
-- ユーザーで明示的にIDをセットすることができます。値が指定されない場合はIDが自動生成されます。
CREATE TABLE DATA_WITH_ID2
(ID LONG GENERATED BY DEFAULT AS IDENTITY (START WITH 1 INCREMENT BY 1),
DATA STRING
);
GENERATED AS IDENTITY句をでID列をセットしたカラムは次の制限があります。
- ID列が有効になっているテーブルでは、同時実行トランザクションはサポートされていません。
- ID列でテーブルをパーティション分割することはできません。
- ALTER TABLEはID列のADD、REPLACE、CHANGE に使用できません。
- 既存のレコードのID列の値を更新することはできません。
ドキュメントURL
https://learn.microsoft.com/ja-jp/azure/databricks/delta/generated-columns
トリガーの移行
データウェアハウスでは従来のデータベースシステムで見られるような行レベルのトリガー機能を利用しているケースは少ないと思われますが、従来のデータベースシステムで見られるような行レベルのトリガー機能を使用して更新ルールを実装している場合は、Deltaテーブルの行レベルの変更情報(チェンジデータフィード)を使用して行レベルのトリガーと同様の更新ルールを持つパイプラインを構築することができます。
Databricksでは変更情報(チェンジデータフィード)の記録を有効にしたDELTAテーブルには通常のカラムに加えて、変更イベントの種類を識別するメタデータ列が作成され、更新情報が自動でセットされます。

Delta Live Tablesでは、このチェンジデータフィードの情報を使用し、チェンジデータキャプチャ (CDC) のETLパイプライン(ストリーミング、バッチ)の構築を簡素化し非常にシンプルなコードのみで実装することができます。
データの更新ルールの実装はDelta Live Tablesパイプラインでの実装を推奨します。
ドキュメントURL
https://docs.databricks.com/ja/delta/delta-change-data-feed.html
https://docs.databricks.com/ja/delta-live-tables/cdc.html
その他:トランザクション処理の移行
Databricksでは、各SQL文ごとのトランザクションはサポートされておりますが、トランザクションの開始やコミット、ロールバックを直接制御する機能は提供されていません。しかし、Deltaテーブルのバージョン管理やタイムトラベル機能を利用することで複数のSQL文を使用して行われた更新処理でエラーが発生した場合でも、更新前のデータにリカバリすることが可能です。これにより、マルチセンテンスに対応するトランザクション処理と同等のデータ整合性を実現することができます。
次のSnapaseプロシージャを例にDatabricksでの実装例をご紹介します。
SET NOCOUNT ON;
DECLARE @xact_state smallint = 0;
BEGIN TRAN
BEGIN TRY
DECLARE @O_ORDERKEY INT;
SET @O_ORDERKEY = 1;
UPDATE orders_w1
SET O_TOTALPRICE = O_TOTALPRICE * 2
WHERE O_ORDERKEY = @O_ORDERKEY;
END TRY
BEGIN CATCH
SET @xact_state = XACT_STATE();
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRAN;
PRINT 'ROLLBACK';
END
END CATCH;
IF @@TRANCOUNT >0
BEGIN
PRINT 'COMMIT';
COMMIT TRAN;
END
Databricksでは、以下の手順でトランザクションの実装を実施しています。
- 処理開始直前に該当テーブルの最終更新時刻をで取得します。
- spark.sql()を使用して該当テーブルの更新処理を実行します。
- 更新処理中にエラーが発生した場合、exceptブロックが実行され、RESTORE TABLE文を使用してテーブルを処理開始直前の状態に復元します。
# Deltaテーブルの更新処理とロールバック処理の実装
# 処理開始前の最新の更新時刻を取得
latest_version_time = spark.sql("""
DESCRIBE HISTORY orders_w1 LIMIT 1;
""").collect()[0]["timestamp"]
try:
# orders_w1テーブルのO_TOTALPRICEを2倍に更新
spark.sql("""
UPDATE orders_w1
SET O_TOTALPRICE = O_TOTALPRICE * 2
WHERE O_ORDERKEY = 1
""")
# 更新が成功した場合のメッセージ
print('更新が成功しました。')
except Exception as e:
# エラーが発生した場合の処理
print('エラーが発生しました。ロールバックを実行します。')
print(e)
# テーブルを処理開始前の最新の状態に復元
spark.sql(f"""
RESTORE TABLE orders_w1 TO TIMESTAMP AS OF '{latest_version_time}'
""")
# 注意: このコードはDatabricks環境でのみ動作します。
# RESTORE TABLEコマンドはDelta Lakeのバージョン管理機能を利用しています。
尚、上記のコードもDBアシスタントで自動生成されたコードですが、修正不要で動作しました。LLMの進化には驚かされるばかりです!

タイムトラベルによるデータリカバリにより複数SQLによる更新のロールバックも可能です。また、リカバリ処理は参照するデータファイルをメタデータレベルでの切り替えで完了しますので所要時間は数秒程度です。
ドキュメントURL
https://learn.microsoft.com/ja-jp/azure/databricks/delta/history
さいごに
今回の記事では各種データベースオブジェクトの移行方法をご紹介しました。既存のデータウェアハウスからの移行に関して具体的なイメージを少しでもお持ちいただけたでしょうか?
また、弊社ではデータウェアハウスからの移行をスムーズに進めるために、無償の移行アセスメントサービスを提供しています。さらにアセスメントから本番稼働に至るまでの全過程において、Databricksへの移行をサポートするサービスも弊社プロフェッショナルサービスやSIパートナー様を通じて提供可能です。ぜひご検討ください!