この記事は クラウドワークスアドベントカレンダー2019 12日目の記事です。
概要
こんにちは、怒り駆動リファクタリングを生業としている @MinoDriven です。
弊社リファクタリング専門チーム「バグハンター」で現在実施中のリファクタリング設計について紹介致します。 ドメイン駆動設計 を用い、Railsレガシーコードに対しViewとControllerを ActiveRecord非依存 に変更する設計です。
状況
弊社ブログの過去エントリにあるように、弊社サービスcrowdworks.jpはサービスインから8年経過し、 30万行 を超えるモノリシックRailsアプリになっています。 開発生産性が低下してきています 。
生産性低下の課題を解決しようにも、大規模な上に複雑かつ密結合な構造になっており、 マイクロサービスへの移行も、リプレイスも困難な制約 があります。
そこで半年前にリファクタリング専門チーム「バグハンター」を編成しました。
我々リファクタリングチームでは、前期半年間において お金周りのリファクタリング を実施してきました。結果、リファクタリング目標として定めた お金関連Modelに多重にincludeされたConcern 全てをリファクタしきることに成功しました。 やったぜええええええええ!!!!!
このリファクタリングで得られたコードと今後将来の施策とを比較検討した結果、分かったことがあります。それは、 今後予定している機能追加等の施策を打つには、密結合になっている機能を更にプリミティブに分離する必要がある 、ということです。
例えば仕事周りModelとお金周りModelは密結合になっています。Model、即ちActiveRecord同士の密結合解消には、DBテーブル構造見直しも視野に入れたリファクタリングが必要です。
課題
しかしテーブル構造を変えたり、分解したり、より最適化した別のテーブルへ差し替えるリファクタリングを考えた場合、ModelがViewやControllerと密結合であるために、テーブルのリファクタリングが困難になっています。

また、これまでと同様にFatModel問題は引き続きリファクタ対応中の状態です。今後もリファクタしてスリムにしていかなければなりません。
従って、以下の課題への同時対応が必要になります。
- ViewやControllerとのActiveRecord密結合問題に対処する
- FatModelを解消し、各責務ごとのクラスに分解する
課題考察
ソフトウェア価値最大化に有用な設計手法として ドメイン駆動設計 (以下DDD)があります。これは変更容易性向上やビジネス価値分析をベースに長期開発力を主眼とした設計手法及び思想です。
これまでのリファクタリングではFatModelを解消するため、ドメイン駆動設計の考え方をベースに、一部の設計パターンをActiveRecordに適用する方法を採ってきました。下図に示すように、ActiveRecordから金額計算などのロジックをDomainObjectとして切り出し、ActiveRecordにぶら下げる形でした。DomainObjectがActiveRecord依存であり、問題です。

設計
そこでActiveRecord密結合に対処するため、よりDDDらしい設計でリファクタリングする方針に切り替えました。以下に示す設計となります。
全体アーキテクチャ
アーキテクチャ全体のBefore / Afterを示します。
Before
一部リファクタリングが進み、多くのDomainObjectが生み出されてはいるものの、全体としては依然MVC構造です。

After
今期は下記アーキテクチャを目標に、リファクタリングを絶賛進めています。
- Infra層を新規追加しました。
- Domain層をよりDDDの設計に近づけています。
- Clean Architectureの考えも参考に、interfaceを介して他のレイヤがDomain層へ依存する構造となっております。
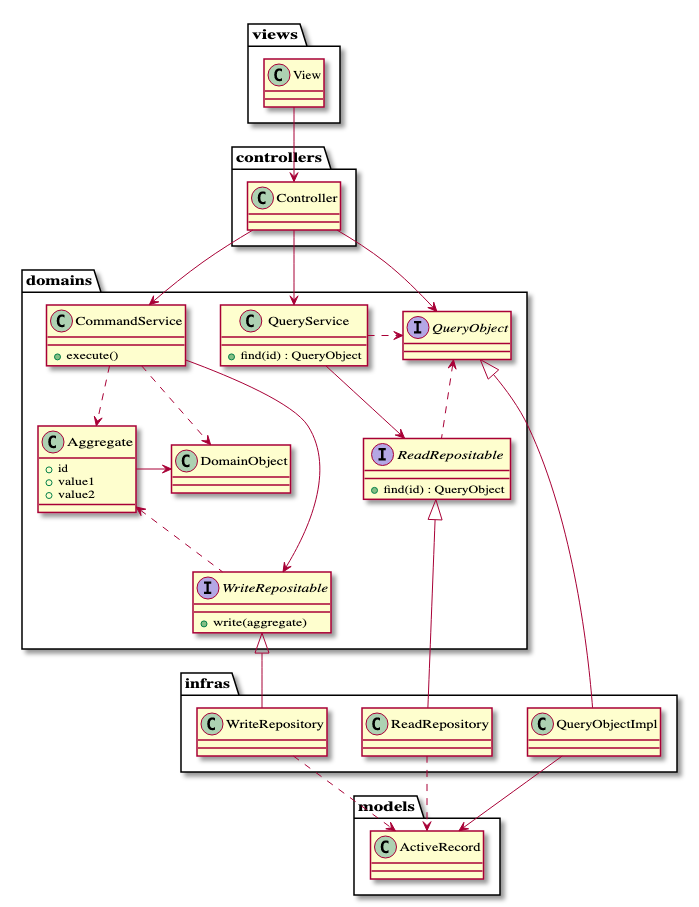
以下、各レイヤとレイヤごとのオブジェクトを説明します。
Domain層
- DDDにおける中心的なレイヤーで、ビジネス関心事のロジックの置き場所です。
- ドメイン層のクラスはActiveRecord非依存の、プレーンなRubyクラスから構成されるようにリファクタしていきます。
- ActiveRecord、即ちDBテーブル構造に依存した作りから脱却し、開発生産性の向上を目指します。
- プレーンなRubyクラスで設計することで、将来他言語のマイクロサービスへ切り出す場合の移植性向上を狙えます。
- 副作用防止のため、「コマンドクエリ分離原則」を適用したCQRS設計にしています。
- CQRSは文脈により構造に違いがありますが、この設計ではアプリケーションアーキテクチャ上のCQRSです。DDD布教者松岡さんのCQRS記事が近いです。データソースまで分離していません。
コマンド側
更新/参照の内、更新を専門で司ります。
更新データに関する業務演算もコマンド側で実施します。

CommandService
- 解決したい課題:更新と参照を分離し、ロジックの副作用をなくしたい。
更新専用サービスです。ビジネス演算や判断がカプセル化されたDomainObjectをAggregateに格納し、AggregateをRepositoryの書き込みメソッドへ渡す仕組みです。
Serviceクラス自体がファットになりがちなので、詳細な処理は原則的にDomainObjectへ委譲します。 数値演算ロジックや業務判断の条件分岐がServiceに書かれたら負けです。
(Aggregate以外の)DomainObject
- 解決したい課題:金額計算ロジックや業務判断ロジックがModelやControllerに雑多に書き殴られている状態です。永続化ロジック等とも絡まって、密結合低凝集状態になっています。どんなドメイン課題を解決したいロジックなのか理解が困難です。
業務概念を表現したオブジェクトです。
税込金額+金額計算ロジックをValueObjectパターンで表現したり、契約ワーカーさん一覧をFirstClassCollectionパターンで表現します。
サービスで扱う業務概念をそれぞれ対応するDomainObjectで設計します。そして様々な箇所に散在した関連ロジックをDomainObjectへ凝集するようリファクタします。
WriteRepository
- 解決したい課題:現在多くのModelでは、永続化(DB更新、参照)ロジックとビジネスロジックが混在しています。ActiveRecordのカラムに代入したり、トランザクションの中に、金額計算などのビジネスロジックが紛れ込んだりしています。理解が難しくなる上に、テーブルのリファクタリングが困難です。
永続化とビジネスロジックは関心事が異なります。そこで永続化を責務とするRepositoryを用意し、Repositoryへ永続化ロジックを委譲します。
Domain層をActiveRecord非依存の構造にするため、Domain層ではRepository interfaceだけを用意し、Infra層でinterfaceを実装します(interface実装クラスについては後述)。
CQRSの考えに基づき、RepositoryをReadとWriteに分け、CommandServiceからはWriteRepositoryを利用します。参照データの粒度と、更新データの粒度が異なることが多いからです。
Aggregate(集約)
- 解決したい課題:FatModelは往々にしてカラムも多いです。FatModelは様々なユースケースで用いられていますが、ユースケースそれぞれで更新されるカラムが異なります。現状のコードでは、保守の際どのユースケースでどのカラムが更新されるか、いちいちコードを追わなければならず、解析が大変です。また、DBパフォーマンスの課題が指摘されてるものの、トランザクションのロック粒度が適切かどうか見分けが困難になっています。
そこで1トランザクションスコープの単位で更新データをまとめたAggregateを用意します。Aggregateには1トランザクションで更新する最小限のデータを所有するよう設計します。
WriteRepositoryにはAggregateを渡して更新します。
何のデータが更新されるかAggregateを見れば分かり、可読性が向上します。
また、トランザクションごとの粒度が分かるので、トランザクション設計の改善にはAggregateとRepositoryに注力すれば良くなります。
クエリ側
更新/参照の内、参照を専門で司ります。
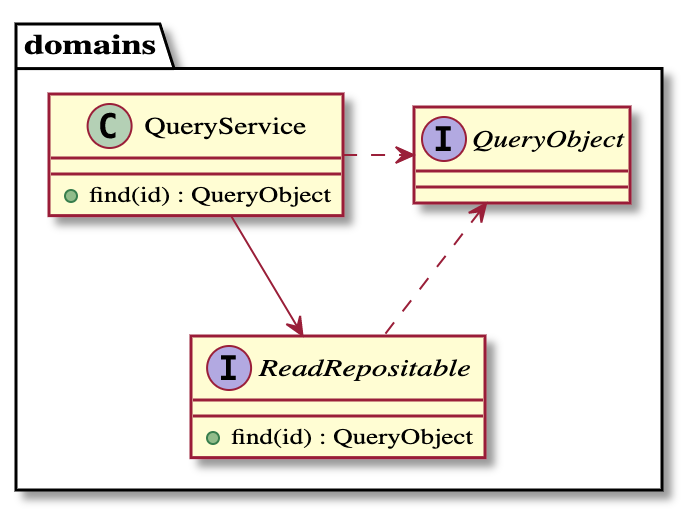
QueryService
- 解決したい課題:更新と参照を分離し、ロジックの副作用をなくしたい。
「コマンドクエリ分離原則」に基づき、データの参照を専門で実行するサービスです。
データ更新(コマンド)とは隔離することで、参照処理なのにデータ更新されてしまうような所謂「思わぬ副作用」を防止します。
DB(ActiveRecord)のクエリ処理を隠蔽したReadRepositoryに問い合わせ、ActiveRecordを隠蔽したQueryObjectをControllerやViewへ渡す役割を持ちます。
ReadRepository
- 解決したい課題:DB参照処理を隠蔽したい(ActiveRecord非依存にしたい)
上述のWriteRepositoryと同様に、ActiveRecordの永続化ロジックを隠蔽するために用います。こちらはクエリ処理です。
ModelやControllerに書かれている ActiveRecord.find や ActiveRecord.where などレコード取得処理を、ReadRepositoryへ委譲します。
Domain層はActiveRecord非依存の構造にするため、Domain層ではRepository interfaceだけを用意し、Infra層でinterfaceを実装します(interface実装クラスについては後述)。
QueryObject
- 解決したい課題:現状ActiveRecordは、テーブル構造に無駄があります。テーブルを分解したり新たなテーブルを追加したり、DBのリファクタリングも必要です。しかしViewとModelが密結合で、ViewがModelのカラムやメソッドに非常に依存している構造です。DBリファクタリングしようにも、Viewとの密結合が妨げています。
QueryObjectは 既存Modelの構造を抽象化したinterface です。(※ Railsで有名なQueryObjectパターン とは異なるため注意)
QueryObjectは、既存Viewが既存Modelにアクセスしている最小限のメンバ(メソッドやアクセサ)を持ちます。
ViewはModelのカラムやメソッドに依存している構造ですが、interfaceにより抽象化しているため、 Viewのロジックを変更せずに 、QueryObject interfaceを実装する別のクラスへ差し替えることが可能です。
interfaceはInfra層にて実装します(後述)。
また、ReadRepositoryはActiveRecordを返すのではなく、ActiveRecordをラップしたQueryObject interface実装クラスを返します。
Infra層

Domain層で用意したRepository interfaceやQueryObject interfaceはInfra層にて実装します。
WriteRepository interface 実装クラス
通常はModelに実装されるようなカラムへの代入、saveといった永続化ロジックは、WriteRepoitory interfaceの実装クラスに移動します。ユースケースごとに異なる更新粒度の知識を、Modelに持たせないようにするためです。
1トランザクション:1メソッドとなるよう設計します。
# 架空のコードであり、実際の製品コードではありません。
class JobWriteRepository
include JobWriteRepositable
def write(job_aggregate)
job = Job.new # JobはActiveRecord
job.title = job_aggregate.title
job.description = job_aggregate.description
job.save
end
end
永続化の知識をinterfaceにより抽象化しているため、将来テーブルをリファクタリングしたり、別のテーブルへの差し替えが容易になります。

ReadRepository interface 実装クラス
WriteRepository interfaceと同様に、DB参照ロジックをReadRepository interface実装クラスへ移動します。
# 架空のコードであり、実際の製品コードではありません。
class JobReadRepository
include JobReadRepositable
def development_jobs
Job.where(category_type: 'development') # JobはActiveRecord
end
end
これも永続化知識の分離や、今後のテーブル差し替え容易化を期待できます。

QueryObject interface 実装クラス
QueryObject interfaceの実装クラスはActiveRecordのラッパーとして実装します。
Repository interfaceと同様に、今後のテーブル差し替え容易化を期待できます。

特にViewは、QueryObject interfaceの境界でActiveRecord非依存になるので、テーブルの構造変化を受けなくなります。
Model層
- 責務:単なるDAO(Data Access Object)に押し留めます。
- 単にカラム構造を定義するだけで、複雑な処理は基本的になにひとつ持たせせないようリファクタしていきます。
- 既存Modelに書かれているビジネスロジックや永続化ロジックは他のクラスへ全て委譲します。
- ビジネスロジック:Domain層へ委譲します。
- 永続化ロジック:Infra層のRepositoryへ委譲します。
リファクタリング手順
以下で説明するのは、上記設計へ移行するためのリファクタリング手順です。
コマンド側
手順1:CommandServiceを作り、演算処理とDB更新処理を委譲

- Domain層にCommandServiceを新規追加します。
- Controllerの
createやupdateなど更新系メソッド内、演算ロジックやDB更新ロジックを、CommandServiceへ委譲します。- Controller側の
flashやredirect_toなど、演算や更新に無関係なロジックはController側に残しておきます。
- Controller側の
手順2:DomainObjectを作り、演算処理を委譲

- CommandService内のロジックや、CommandServiceからコールされているAcitveRecordのメソッドを分析し、金額計算等の演算処理を見つけます。
- Domain層にDomainObject(ValueObjectなど)を新規追加し、見つけた演算処理を各々DomainObjectへ委譲する( つまりCommandServiceやActiveRecordから委譲する )。
- ActiveRecordから委譲する際は、そのロジック(メソッド)が他からコールされていないか注意します。コールされている場合別途設計検討します。
手順3:Aggregateを作り、更新データを集約

- CommandService内のロジックや、CommandServiceからコールされているAcitveRecordのメソッドを分析し、更新しているActiveRecordのカラムを見つけます。
- Domain層にAggregateを新規追加します。
- 更新する最小限のデータセットを持つようAggregateを設計します。
- 必要に応じてAggregateに集約全体の整合性維持用ロジックも持たせます。
- Aggregateに更新データを渡すようリファクタします。
手順4:WriteRepositoryを作り、DB更新処理を委譲

- Domain層にDBテーブル更新用 WriteRepositable interfaceを新規追加します。
- WriteRepositable interfaceの実装クラスをInfra層に用意します。
- CommandServiceやActiveRecordのメソッドを分析し、トランザクションやカラムへの代入、
ActiveRecord.saveなど、DB更新ロジックを見つけます。 - 見つけたDB更新ロジックをWriteRepositoryへ委譲します。
クエリ側
手順1:QueryServiceを作り、参照周りの処理を委譲

- QueryServiceをDomain層に新規追加します。
-
Controller.showなどに書かれてるActiveRecord.find系の参照処理やその周辺の処理をQueryServiceに移動します。 - Controllerは
QueryService.findを介してActiveRecordを取得するようリファクタします。
手順2:ReadRepositoryを作り、参照処理を委譲

- 参照用リポジトリReadRepositable interface、及び実装クラスReadRepositoryを追加します。
- QueryServiceにあるActiveRecordの処理を、 ReadRepositoryに移動します。
- ※ものによってはQueryServiceが不要になり、ReadRepositoryだけで済む場合もありそうです。
手順3:QueryObjectを作り、ViewとControllerからActiveRecord依存を引き剥がす

- Domain層にQueryObject interfaceを用意します。
- QueryObject interface にはActiveRecordと同名のメソッドや、カラムと同名のアクセサを定義します。但し、 Controller側やView側でアクセスする必要最小限のもののみ用意します 。不必要なアクセスを防止し、影響範囲を低減するためです。
- Infra層にQueryObject interfaceの実装クラスQueryObjectImplを用意します。
- ActiveRecordをラップするようにQueryObjectImplを実装します。
- QueryServiceやReadRepositoryはQueryObject interfaceのオブジェクトを返すように修正します。
実際上手くいっているか
上記設計に基づくリファクタリングは先月2019年11月にスタートしたばかり。一部ユースケースについてリファクタリングを進めています。QueryObjectは未着手ですが、それ以外のリファクタリングに成功しております。
妥協との戦い
とは言っても途中様々な罠があり、設計通りになるかどうか難儀する局面も多々あります。本記事の設計はあくまで理想像であり、どこまで近づけるか、課題とコストとのバランス取りを繰り返す毎日です。ただ、設計通りにいかないからといって既存実装への安易な妥協は避けます。課題解決にならないですし、ここを上手く設計してこそエンジニアとしての腕の見せ所です。
設計的に困難だった箇所は、その実践ノウハウを資料化し、チームに水平展開し、リファクタリング生産性の更なる向上に努めています。
DDDの浸透
この設計は所謂「レールから外れた」ものです。
リファクタリングチーム以外の他のエンジニアさんが困惑しないよう社内でDDDの勉強会を開催したり、レクチャー等を通じて開発運用に支障をきたさぬよう努めています。
今後の技術課題
QueryObject interfaceによる抽象化はViewとModelの引き剥がしに重要ですが、View側のみで利用するメソッドをActiveRecordに生やすActiveDecorator gemなど、引き剥がす上でいくつか課題があります。その他ActiveDecorator以外にActiveRecordに作用するgemがある場合も相当な罠となるため、実験的にリファクタするなど早め早めのリスク対策の必要性を肌身で感じております。
苦労していること ー 強大なActiveRecord ー
ActiveRecordの密結合さにほとほと苦労している毎日です。あらゆるコードがActiveRecordありきで、引き剥がしは一筋縄にはいきません。
スライド Ruby on Railsの正体と向き合い方 にあるように、Railsは歴史的背景からModelとの密結合でスタートアップ加速力を得た犠牲的アーキテクチャです。そもそも大規模開発が想定されていないのです。
「Railsじゃなくていいんじゃね?」への回答
スタートアップを主眼とするRailsと、長期開発力を主眼とするドメイン駆動設計とではスタンスが大きく異なり、親和性がない組み合わせでしょう。「RailsではDDDは困難」が多くの識者の見解で、その通りだと思います。
「これもうRailsじゃなくていいんじゃね?」
「いつまでもRailsにしがみついてないで、さっさと非Railsに移行しなよ」
との声が聞こえてきそうです。
しかし冒頭で述べた通り、既に動いているサービスであり、内部が30万行オーバーの密結合構造であるために、 マイクロサービスへの移行もリプレイスも困難な制約が、無視できぬ現実として存在します 。
従って、今後しばらくはRailsに付き合いつつ、開発生産性向上のためにリファクタリングしていく必要性があるのです。このリファクタリング活動により密結合が解消され、構造が整理されて初めて、マイクロサービス化やリプレイスの道筋も見えてくることでしょう。
終わりに
新規開発でRails+DDDは無理でしょう。私も避けます。しかし Railsレガシーコードの解消においては DDDの考え方は参考にすべき点が多く、我々のリファクタリング活動に取り入れております。かなり挑戦的な取り組みですが、実を結ぶようこれからもリファクタリング設計を試行錯誤していきます。