以前に投稿した記事:【スケジューラ】自分の投稿したQiita記事の情報をAPIから取得してみるの続きです。
以前の記事にも書いたように、Qiitaへの投稿記事の情報をスケジューラを利用して定期的に取得し、その情報をデータベースに記録することができました。
しかしながら、その時その時のスナップデータだけでは、どのようにView数が伸びてきたかなどは不明です。
なので、Histroryテーブルを作成して、Histroryデータを残していくことにしました。そうすることで、View数の遷移等をグラフにすることができますね。今回はその過程を記事にします。
新規テーブルの作成
History用のテーブルを新たに追加します。
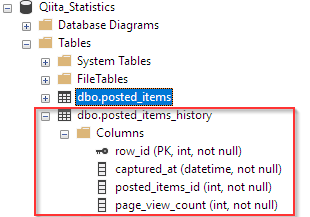
データベーススキーマの変更をデータモデルに反映
対象データベースの構造の変更をデータモデルに反映させます。Sharperlightアプリケーションメニューよりスタジオを起動し、Qiita用のデータモデルを開きます。
SchemaメニューのImport Tableアイテムを利用して、スキーマ情報の差分を取り込みます。
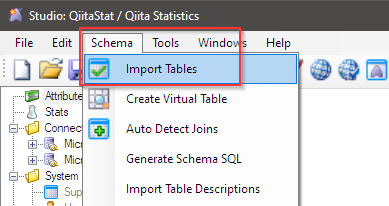
専用ダイアログが表示されるので、Get Tablesボタンで変更が加わったテーブル情報を取得し、データモデルに取り込みます。
差分が取り込まれました。
これでSharperlightと対象データベースの会話は上手く運びます。
Hisitoryテーブルへのデータに移動
以前の記事で作成したスケジューラのタスクで定期的にスナップショットデータがテーブルに保存されるので、その直後にそのデータセットをひとつのグループとしてHsitoryテーブルへ転送記録します。グループを表すコードには、転送開始日時を使用します。
この転送処理を新しいスケジュールタスクとして追加します。
スケジュールタスクの追加
新規タスクの追加を行い、コード、グループ及び説明をそれぞれ記入します。
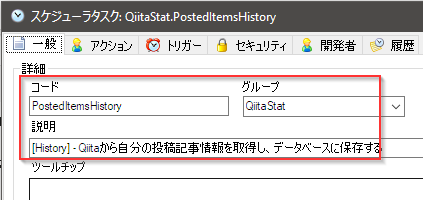
先ず、このタスク開始時の日時を取得し、タスクパラメータとします。これがグループコードとなります。
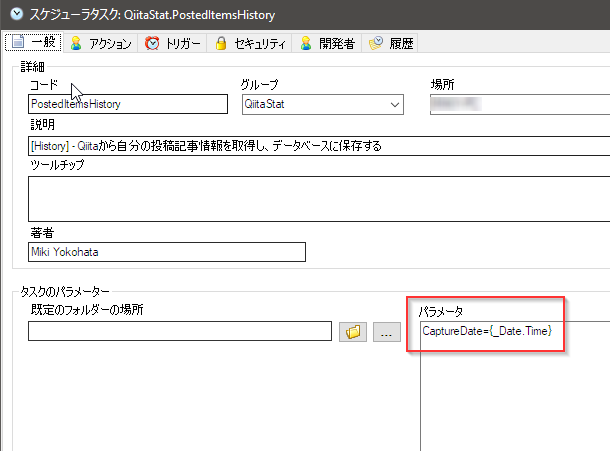
次にアクションタブに移動し、アクションを追加していきます。
クエリを作成し、キャプチャされたデータが保存されているposted_itemsテーブルから転送に必要なデータを読み込みます。
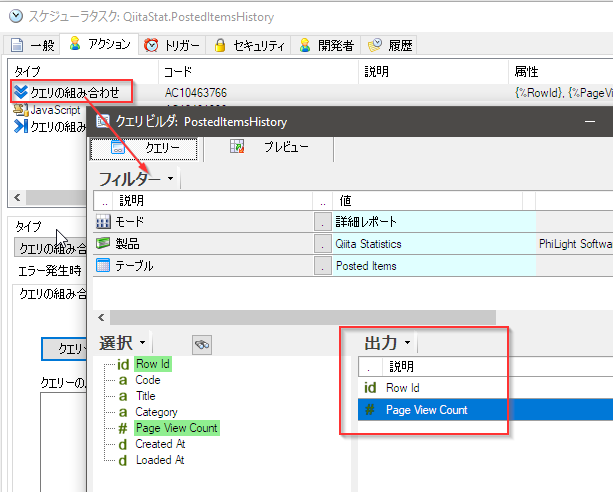
これで転送に必要なデータは、タスクパラメータとこのクエリで供給されることとなります。
次にJavaScriptアクションを追加して、下記のコードを書きます。
最初の3行に注目、クエリからのデータとタスクパラメータからのデータを参照しています。
これらをHistoryテーブルにSharperlightエンジンの機能を利用して書き込んでいきます。
var RowId = lib_task.QueryCombinationValueGet('RowId');
var PageViewCount = lib_task.QueryCombinationValueGet('PageViewCount');
var CaptureDate = lib_task.ParamGet('CaptureDate');
try{
// Call Writeback Function
db_Writeback(RowId, PageViewCount,CaptureDate);
}catch (err){
lib_task.LogMessage('ERROR','main',err);
}
function db_Writeback(xRowId, xPageViewCount, xCaptureDate){
try{
console.log(xRowId + '/' + xPageViewCount + '/' + xCaptureDate);
//タスクログに情報を記録する
lib_task.LogMessage('INFO','db_Writeback()','db_Writeback start');
//データモデルのテーブル情報を取得する
let wb = JSON.parse(lib_app.writeback.MetaDataJsonGet('QiitaStat', 'PostedItemsHistory'));
if (wb.errorMessage.length > 0) {
lib_task.LogMessage('ERROR','db_Writeback()',wb.errorMessage);
}else{
wb.rows = [];
let cells = [];
cells.push({
"code": 'CapturedAt',
"value": xCaptureDate
});
cells.push({
"code": 'PostedItemsId',
"value": xRowId
});
cells.push({
"code": 'PageViewCount',
"value": xPageViewCount
});
wb.rows.push({
"cells": cells
});
//レコード数が処理指定数に到達したら書き込み処理を実行
wb.mode = 'Update'; //Update,Validate,Delete,Delete-IdentityOnly,Delete-UniqueKeysOnly
wb.breakOnFirstRowError = true;
let wbStatus = JSON.parse(lib_app.writeback.Execute(wb));
if( wbStatus.errorMessage.length > 0 ) {
//タスクログにエラーを記録する
lib_task.LogMessage('ERROR','db_Writeback()',wbStatus.errorMessage);
for( var i=0;i<wbStatus.status.length;i++ ) {
var si=wbStatus.status[i];
//タスクログにエラーを記録する
lib_task.LogMessage('ERROR','db_Writeback()',si.fieldCode + ' - ' + si.message);
}
}
wb.rows = []; //行データの入れ物を空にする
}
}catch(err){
//タスクログにエラーを記録する
lib_task.LogMessage('ERROR','db_Writeback()',err);
}
}
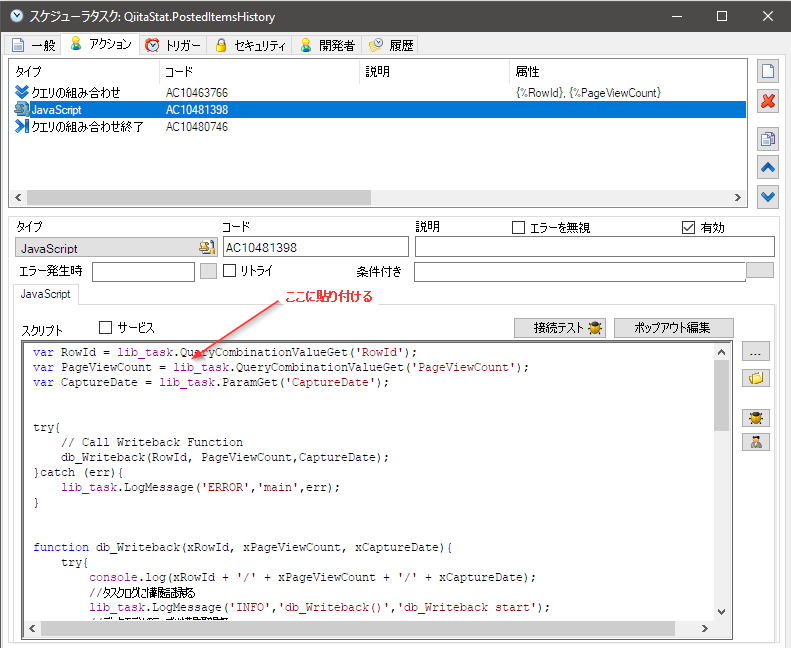
最後にクエリのループを閉じで終わり。
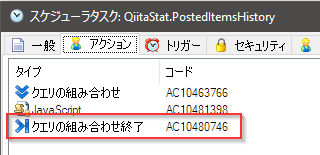
OKでタスクを保存しましょう。
親スケジュールタスクの作成
さて、以前の記事で作成したデータをキャプチャするタスクと今回作成したHistory転送タスクがありますが、これらが別々に動作するとHisioryテーブルにデータを転送する前に、次の最新データがキャプチャされてしまうなんてことが発生しかねません。
そういった事を防ぐため、親タスクを作成し、これら二つのタスクを順次、セットで定期的に動作させます。
では、新規タスクを追加し、コード、グループ等を記入しアクションタブに移動します。
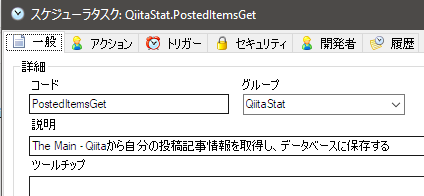
アクションタブでは、指定タスクを実行アクションを二つ追加します。
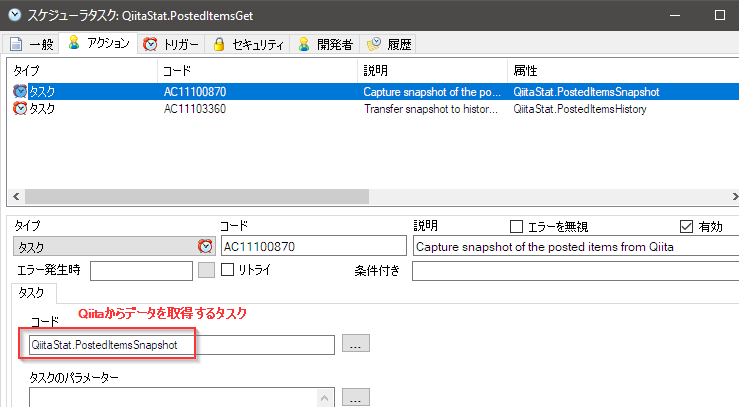
最初は、Qiitaからデータを取得するタスクの実行。
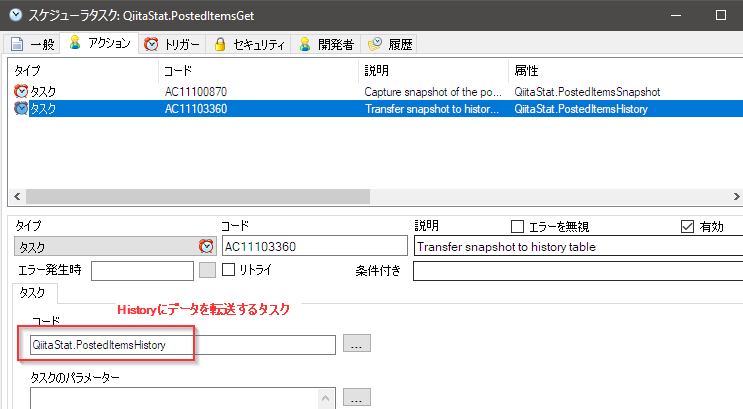
次にHistoryにデータを転送するタスクの実行です。
トリガータブに移動し、このタスクを実行させるスケジュールを作成します。
この例では、毎日、午前6時から午後9時までの間、1時間おきにこのタスクが実行されます。
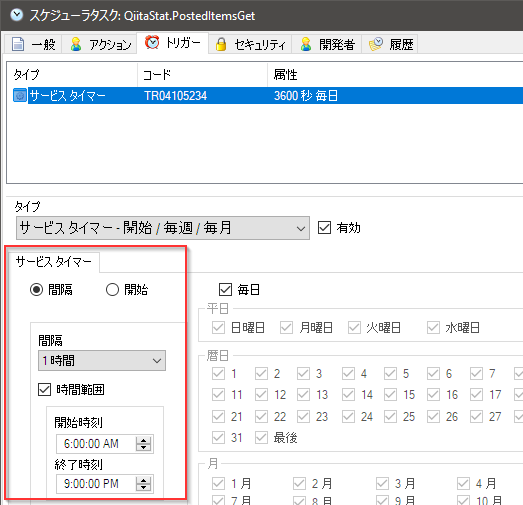
OKでタスクを保存。
お忘れなく、データをキャプチャするタスクのトリガー(スケジュール)は削除しておきます。
以上で、データのキャプチャ及びHistoryへのデータの集積メカニズムが完成です。あとはSharperlightのレポーティング機能を使用し、お好みのレポートを作成できます。
サンプル
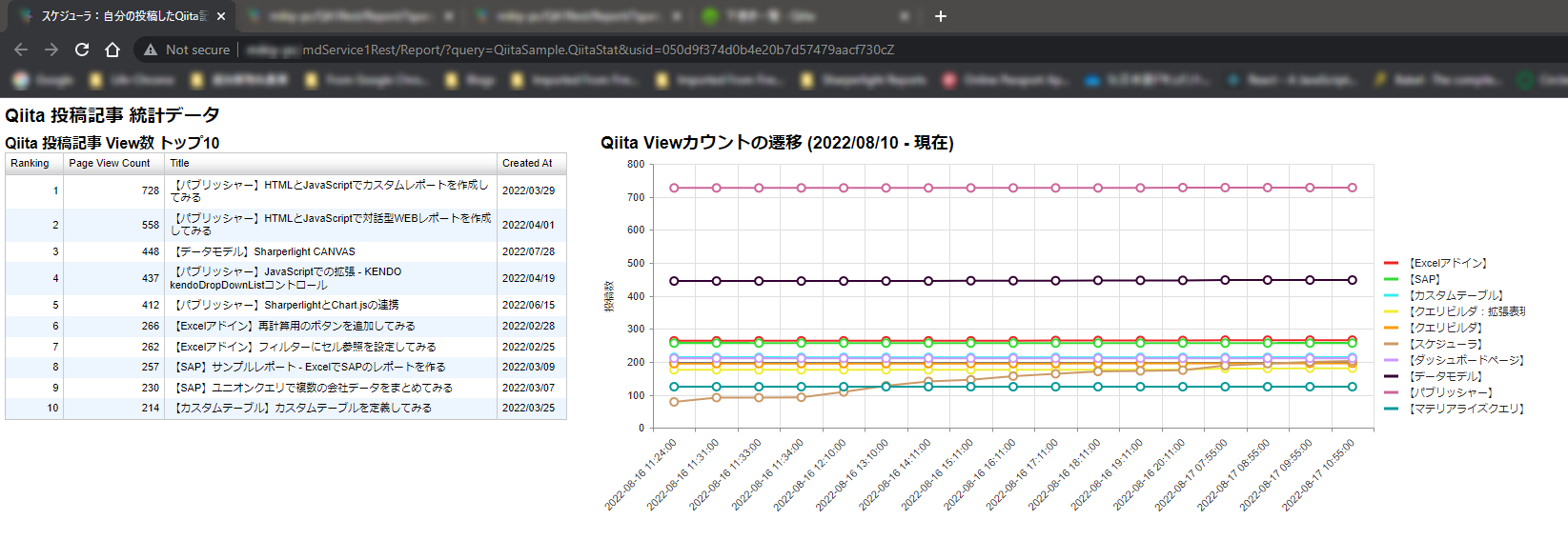
ドリル機能もあるよ。
クリックすると...
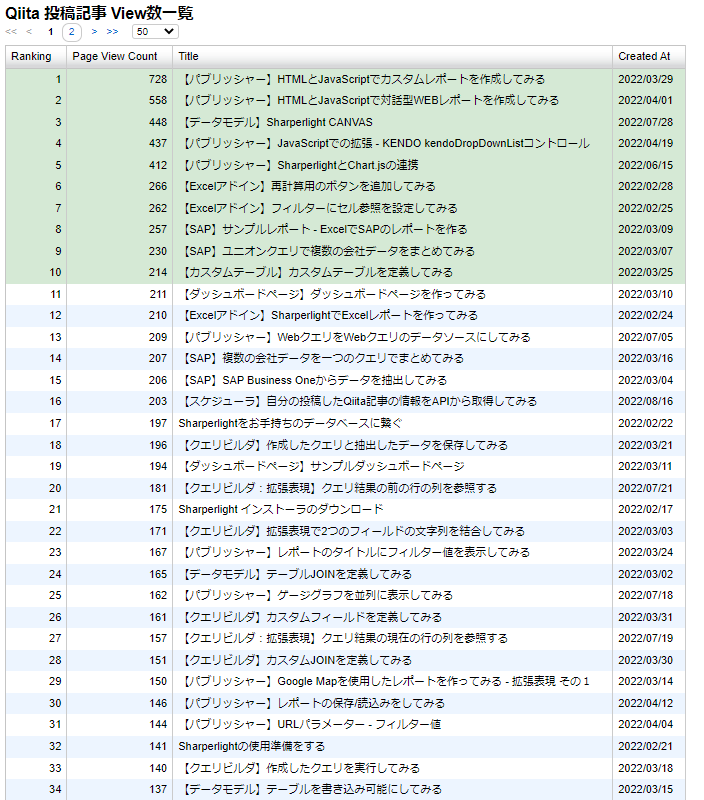
グラフにも...
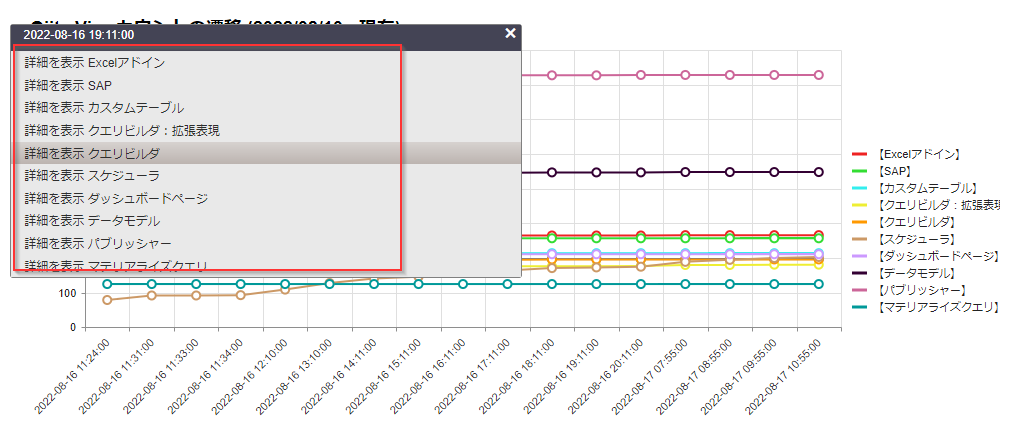
選択すると...
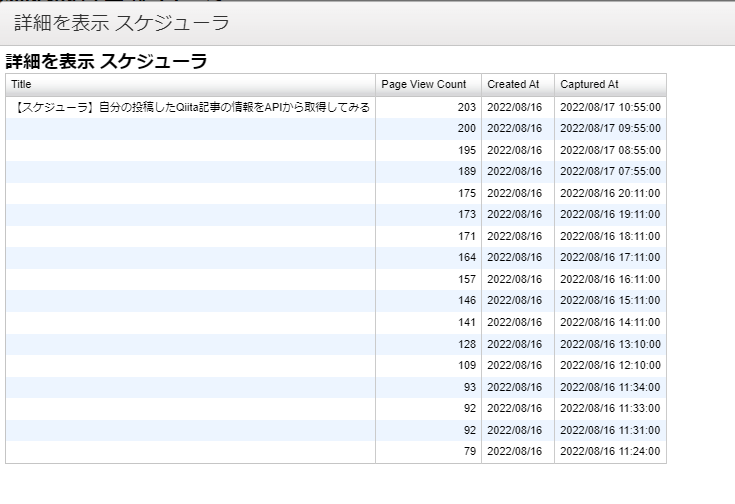
といった感じです。
では失礼いたします。