楽天商品検索API
事前準備
- Rakuten Developersに楽天会員アカウントでログインする
https://webservice.rakuten.co.jp/ - 画面右上の+New Appを押す
- 登録事項を入力して同意ボタンを押す
- Rakuten APIキーが発行される
APIを使用するために必要なので、3つのAPI キーを控えておくApplication ID/developer ID application_secret Affiliate ID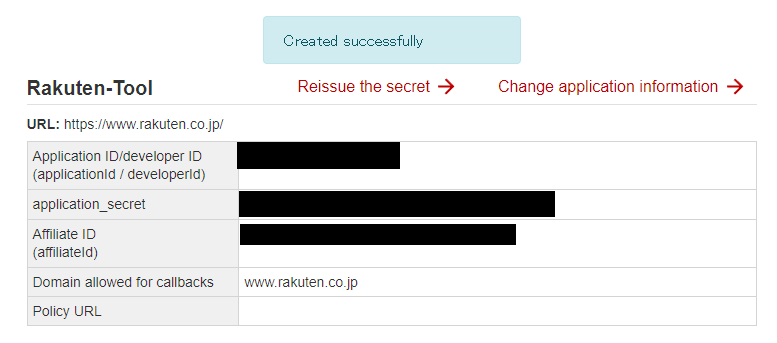
APIの使い方
下記に利用可能なAPI一覧とその詳細について記載されている。
取得可能なパラメーターは以下のサイトに記載されている。
1. 商品検索
from ast import keyword
import pandas as pd
import requests,json,datetime,os,re
from time import sleep
MAX_PAGE = 5
HITS_PER_PAGE = 30
REQ_URL = 'https://app.rakuten.co.jp/services/api/IchibaItem/Search/20220601'
WANT_ITEMS = [
'genreId','itemCode',
'itemName','itemPrice','catchcopy',
'itemCaption','reviewAverage','reviewCount',
'shopCode','shopName','itemUrl','shopUrl','postageFlag'
]
CLIENT_ME = {
'APPLICATION_ID':'1003809139331141391',
'APPLICATION_SECRET':'fc3268cf5c1eef7272b9bc689a1faa9d61470946',
'AFF_ID':'30f5260f.a1327a3c.30f52610.2012e42b'
}
req_params = {
'applicationId':CLIENT_ME['APPLICATION_ID'],
'format':'json',
'formatVersion':'2',
'keyword':'',
'hits':HITS_PER_PAGE,
'sort':'+itemPrice',
'page':0,
'minPrice':100
}
sta_time = datetime.datetime.today()
this_date = format(sta_time,'%Y%m%d')
path_output_dir = f'./{this_date}'
if not os.path.isdir(path_output_dir):
os.mkdir(path_output_dir)
def create_output_data(arg_keywords):
for keyword in arg_keywords:
#初期設定
cnt = 1
keyword = keyword.replace('\u3000',' ')
req_params['keyword'] = keyword
path_file = f'{path_output_dir}/{keyword}.csv'
df = pd.DataFrame(columns=WANT_ITEMS)
print(f"{'-'*30}\nNowKeyword --> {keyword}")
#ページループ
while True:
req_params['page'] = cnt
res = requests.get(REQ_URL,req_params)
res_code = res.status_code
res = json.loads(res.text)
if res_code != 200:
print(f"ErrorCode --> {res_code}\nError --> {res['error']}\nPage --> {cnt}")
else:
#返ってきた商品数の数が0の場合はループ終了
if res['hits'] == 0:
break
#Serch版
#tmp_df = pd.DataFrame(res['Items'])[WANT_ITEMS]
tmp_df = pd.DataFrame(res['Products'])[WANT_ITEMS]
df = pd.concat([df,tmp_df],ignore_index=True)
if cnt == MAX_PAGE:
break
cnt += 1
sleep(1)
df.to_csv(path_file,index=False,encoding="utf_8_sig",sep=",")
print(f"Finished!!")
keyword = '米'
create_output_data([keyword])
2. 商品価格検索
from ast import keyword
import pandas as pd
import requests,json,datetime,os,re
from time import sleep
MAX_PAGE = 5
HITS_PER_PAGE = 30
REQ_URL = 'https://app.rakuten.co.jp/services/api/IchibaItem/Search/20220601'
REQ_URL = 'https://app.rakuten.co.jp/services/api/Product/Search/20170426'
WANT_ITEMS = [
'JAN','productName','productCaption','productId','smallImageUrl','mediumImageUrl','itemCount','salesItemCount',
'averagePrice','salesMinPrice','usedExcludeCount','usedExcludeMinPrice','usedExcludeSalesItemCount','usedExcludeSalesMinPrice',
'reviewAverage','reviewCount',
'genreId','genreName','affiliateUrl'
]
#['ProductDetails', 'affiliateUrl', 'averagePrice', 'brandName', 'genreId', 'genreName',
#'itemCount', 'makerCode', 'makerName', 'makerNameFormal', 'makerNameKana', 'makerPageUrlMobile',
#'makerPageUrlPC', 'maxPrice', 'mediumImageUrl', 'minPrice', 'productCaption', 'productId', 'productName',
#'productNo', 'productUrlMobile', 'productUrlPC', 'rank', 'rankTargetGenreId', 'rankTargetProductCount',
#'releaseDate', 'reviewAverage', 'reviewCount', 'reviewUrlMobile', 'reviewUrlPC', 'salesItemCount', 'salesMaxPrice',
#'salesMinPrice', 'smallImageUrl', 'usedExcludeCount', 'usedExcludeMaxPrice', 'usedExcludeMinPrice',
#'usedExcludeSalesItemCount', 'usedExcludeSalesMaxPrice', 'usedExcludeSalesMinPrice']
CLIENT_ME = {
'APPLICATION_ID':'1003809139331141391',
'APPLICATION_SECRET':'fc3268cf5c1eef7272b9bc689a1faa9d61470946',
'AFF_ID':'30f5260f.a1327a3c.30f52610.2012e42b'
}
req_params = {
'applicationId':CLIENT_ME['APPLICATION_ID'],
'format':'json',
'formatVersion':'2',
'keyword':'',
'hits':HITS_PER_PAGE,
# 'sort':'+itemPrice',
'page':0,
'minPrice':100
}
sta_time = datetime.datetime.today()
this_date = format(sta_time,'%Y%m%d')
path_output_dir = f'./{this_date}'
if not os.path.isdir(path_output_dir):
os.mkdir(path_output_dir)
def create_output_data(arg_keywords):
for keyword in arg_keywords:
#初期設定
cnt = 1
keyword = keyword.replace('\u3000',' ')
req_params['keyword'] = keyword
path_file = f'{path_output_dir}/{keyword}.csv'
df = pd.DataFrame(columns=WANT_ITEMS)
print(f"{'-'*30}\nNowKeyword --> {keyword}")
#ページループ
while True:
req_params['page'] = cnt
res = requests.get(REQ_URL,req_params)
res_code = res.status_code
res = json.loads(res.text)
if res_code != 200:
print(f"ErrorCode --> {res_code}\nError --> {res['error']}\nPage --> {cnt}")
else:
#返ってきた商品数の数が0の場合はループ終了
if res['hits'] == 0:
break
#Product版
res['Products'][0]['JAN'] = keyword
tmp_df = pd.DataFrame(res['Products'])[WANT_ITEMS]
df = pd.concat([df,tmp_df],ignore_index=True)
if cnt == MAX_PAGE:
break
cnt += 1
sleep(1)
df.to_csv(path_file,index=False,encoding="utf_8_sig",sep=",")
print(f"Finished!!")
JANCode = '4902370536058'
create_output_data([JANCode])
楽天RMS APIの始め方
下記記事参照