今年もエージェンティックAIやそれに付随するデータベース、モダナイゼーション・その継続的改善などのトピックがメイン。
総合的な感想としては、要件定義から運用まですべての場面でエージェントAIを使用すべきだなという点と、セキュリティや権限回りのサービス紹介が多かった印象。
基調講演
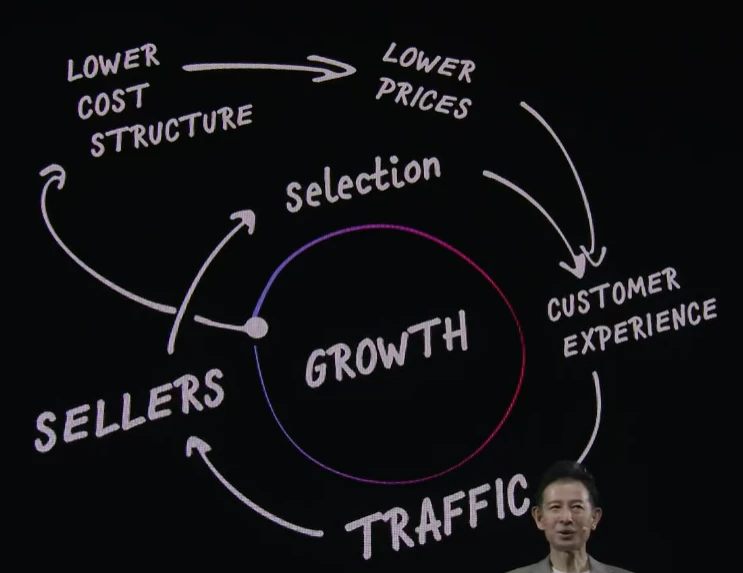
AWS Japanの白幡晶彦氏は、Amazon/AWSの成長思想である 紙ナプキンに書かれた「フライホイール」 を紹介し、今後その回転を加速するのがAIエージェントだと説明しています。例として、Blue Originでは2,700以上のAIエージェントが本番稼働し、ソニーグループでは生成AI基盤「Enterprise LLM」を6万5,000人以上が利用している事例が紹介されました。
OpenAI Japanの長﨑忠雄氏も登壇し、OpenAIとAWSのパートナーシップ拡大が紹介されました。 GPT-5.5などのOpenAIモデルをAmazon Bedrockで使えること、CodexをAWS環境に導入できること、OpenAIモデルとハーネスを使ったBedrockマネージドエージェントをデプロイできること が説明されています。
デイブ・ブラウン氏は、AWSのAIエージェント戦略を大きく4領域で説明しています。
業務のためのエージェントでは、社内のメール、チャット、ドキュメント、データレイクなどに散らばる情報をつなぐAIアシスタント 「Amazon Quick」 が紹介されました。情報の関係性を理解し、資料作成やメール送信まで支援する構想です。
開発のためのエージェントでは、 Kiro、AWS DevOps Agent、AWS Transform が中心です。Kiroは要件・設計・実装タスク・テストまで構造化してコード生成する開発支援ツール。AWS DevOps Agentはリリースや運用の問題をAIが検知・検証し、AWS Transformは既存コードのモダナイズや技術的負債解消を継続的に支援するものです。
セキュリティのためのエージェントでは、 AWS Continuum が紹介されています。これは脆弱性検出、コードレビュー、ペネトレーションテスト、脅威モデリング、脆弱性対応の優先順位付けなどをAIで自動化していく方向性です。最初は人間が確認する学習モードから始まり、信頼度が上がると自動適用に移る考え方です。
エージェント構築基盤としては、Amazon Bedrock AgentCore が重要です。AgentCore harness により、エージェントの実行環境、メモリ、データ、ツール、サンドボックスなどをまとめて扱えるようにし、モデルに依存せず安全にエージェントを動かす基盤として説明されています。さらに、Web Search on AgentCore、Amazon Bedrock Managed Knowledge Base、AWS Context などで、最新のWeb情報、社内非構造化データ、構造化データをエージェントに取り込む流れも紹介されています。
事例では、東京海上日動がAI駆動開発ライフサイクル、AI-DLCを紹介。Kiroを使った検証で開発速度が10倍になり、プロトタイプ作成が半年から1日に短縮されたという話が出ています。ポイントは「AIを入れる」ではなく、仕事のやり方・意思決定・内製化まで変えることです。
freeeは、AIエージェントによって中小企業のバックオフィス業務を「Done by you」から「Done for you」へ変える構想を紹介しています。Amazon Bedrock、EKS、SageMaker HyperPodなどを使い、本番稼働のAIエージェント、独自小型言語モデル、開発組織のAI活用を進めているとのことです。
| 領域 | 注目サービス/概念 | 意味 |
|---|---|---|
| 開発 | Kiro / AI-DLC | 要件定義〜設計〜実装〜テストをAI中心に回す |
| 運用 | AWS DevOps Agent | 障害対応だけでなく、リリース前検証までAI化 |
| モダナイズ | AWS Transform | 技術的負債の継続的解消 |
| セキュリティ | AWS Continuum | 脆弱性対応・脅威モデリングのAI化 |
| エージェント基盤 | Bedrock AgentCore | エージェントの実行・運用・スケール基盤 |
| ナレッジ活用 | Managed Knowledge Base / AWS Context | 社内データをエージェントが使える形にする |
Day1 6/25
AI エージェント精度改善のポイント - Architecture・Context・Tools の設計方針
AI Agentアーキテクチャの種類
- Single Agent
- Graph (条件分岐)
- Multi Agent
- Agent as tools (オーケストレーターが分析手順を決めて、各Agentを呼び出す)
- Swarm (オーケストレーターなしで各Agentが相互議論する)
Multi Agentにより似たドメイン知識が混ざることを避けることができる
分析フローを事前定義可能な場合は、graphで実装するのがよい
分析内容や手順がわからない場合は、Agent as tools
上記の全アーキテクチャは、Stands Agentsで簡単に実装できる。
| Single Agent | Graph | Agent as tools | Swarm | |
|---|---|---|---|---|
| 特徴 | 単一で完結 | 事前定義可能 | オーケストレーターが処理手順を判断 | Agent動詞が協調して判断。分散型 |
| 向くケース | 少数ドメイン | 処理手順固定 | フローが不安定 | Agent間で議論が必要 |
| 考慮事項 | ドメイン増加で肥大化 | 事前定義できない要件に不対応 |
課題:Lost in the middle
解決策:情報を要約して圧縮する。
課題:Tool呼び出しのリトライによるコスト・時間増加
解決策:Tool設計と呼び出し条件の整備
- Architecture
ユースケースを整理し、要件を満たすシンプルなアーキを選択すること - Context
タスクを解くのに必要最低限の情報を設計すること - Tools
AI Agentが理解しやすい完結な定義にし、Tool数を最小限に抑えること
AWS DevOps Agent による自律的インシデント対応 -その能力を引き出す設計のベストプラクティス
障害対応におけるAI利用。
-
AIに任せつつ危険な実行はさせない仕組みが大事
-
多様なデータソースと連携している仕組み
-
全メンバーで同じ品質のコンテキストやAI利用能力を有する必要がある
-
調査スコープを決めて精度を引き出す -> Agent spaceで範囲制限できる
-
テレメトリを充実させて正確性を上げる -> メトリクス・ログを有効化、OpenTelemetryと紐づけ
-
ナレッジ共有が大事 -> Skillsに登録、.mdに記載
Dev Ops Agentで、AWS内の障害の原因調査ができる。
ラヴィットの大規模配信の裏側とサーバレス設計
- Amazon IVSを使用した大規模映像配信。
- Amazon APIgateway + Lambda + ElastiCacheで多段キャッシュの実装による速度改善
- 一部の処理を非道化することで、APIパフォーマンスの向上
- Amazon Novaで、高速なコンテンツも出レーションを提供
AWS Analytics MCP サーバーで実現するエージェント型データエンジニアリング
課題:ビジネスのスピードに意思決定が追い付いていない
AWS Analysis MCPサーバー
- Data Processing MCPサーバー:Athena, Glue用
- Redshift MCPサーバー:Redshift用
- MSK MCPサーバー
- OpenSearch MCPサーバー
kiroのUIでデータパイプライン構築をAIエージェントにさせる
- データ探索
MCPサーバーが探索を提示とフィールドの確認 - データカタログ化
- ジョブ実行
- ETLジョブの実行
- データ検証
- Jupyter NBに使い方のコードが出力
- Readmeも出力
自然言語で、データパイプラインの構築・実行・検証ができる時代
AWS Analytics MCPサーバーは主要サービスに対応し、べスプラに沿ったコード生成ができる
AWS Infrastructure as Code : 2025 年主要アップデートの振り返り
AWS CloudFormation IDEエクスペリエンス:AWS Toolkit
=> 自走補完やホバーが可能
IaCの早期エラー検証:変更セットの作成
=> 早期エラーの発見が可能
AIはある程度の正確さとスピードが必要だが、インフラは確実な正確性が必要
サーバーレス API のセキュリティ -API 認可の基本を押さえ、AI エージェント時代に備える-
サーバレス設計の際は、認証・認可・検証が必要だとねという話。
Inspector, Gurdduty, Cognito, WAF, APIGatewayの認証認可、IAM設定で解決
サーバレスアプリは呼び出し元のアプリでの認証トークンの管理も大事
-
OAuth2・・・アクセストークン、リフレッシュトークン
-
OpenID Connect(OIDC)・・・IDトークン
-
AIエージェントでのOAuth2適用
-
Agentcore Identityで認証・認可
Day1 6/26
基調講演
- ハードウェア(半導体)からAWSやってきたよ
Nitro Systemの仮想化・・・ネットワーク、ストレージI/Oをハードにオフロード、ベアメタルに近いセキュリティ
Graviton CPU
フィジカルAI・・・ファナックとの協業
AI-DLCによるAI中心の開発サイクル・・・サーバーエージェントとの協業
-
チャールズ・ダーウィン
「変化を恐れず、変化に対応したものが生き残れる」 -
KIROによる仕様駆動開発
20倍以上の開発効率化
NTT tsuzumi2
トークナイザー・・・同じ文章でも少ないトークンで理解
AWSに多大な支援をもらって学習している
学習には280kステップ中に何度も異常終了する
クラウドおにぎり
シンプルなAPIGateway+Lambdaのサーバレス構成
裏でEventBridgeやdurable functionがいる
サーバレス原則
- 単一責任
- 適切なサイジング
- パッケージ最適化(起動の速さ)
課題:ユーザーや決済の待ち時間と15分制限
解決策:疎結合、非同期処理、レジリエンスの向上
「最強の剣は振らなくて済む剣である」
カスタマイズはしない方がよい
コールドスタート対策
- Lambda provisioned concurrency
- Lambda snapshot
コストパフォーマンスでどちらにするか選択
Durablefunctionとマネージドインスタンスも紹介
AIエージェントベスプラ
9つのルール
- 課題から始めて小さく構成する
- ツールとAPI連携を設計する
- ロギングを始めから設計に加える
- 評価の自動化をする
- マルチエージェントの検討
- セキュア化する
- コードを使用する
- 何度も繰り返しテストする
- 組織体制を整える
AgenrCore
- Code interpreter
- Identity
- Gateway
- Observavility
- Evaluations
Amazon Bedrock AgentCore Identity が解決する3つの課題
- セキュリティ・・・安全な権限委任
- UX・・・毎回同意する面倒さ
- 開発速度・・・各ユースケースごとのエージェントの実装
Amazon Bedrock AgentCore Identityを使用することで解決する
インバウンドAuth・・・UI側の認証・認可
アウトバウンドAuth・・・MCP以降の認証・認可
WATでユーザーを識別し、外部サービスの認証をボールドに保持して再利用できる。
AI エージェントで実現するデータベース運用:検知・推奨・最適化
データベースのパフォーマンス・セキュリティの等の問題をプロアクティブにAIで検知・最適化
各データベースの3つの課題
- Amazon RDS
- Amazon Aurora
- Amazon Redshift
AI エージェントの推論から大規模学習まで" コスト効率と性能が両立する AI インフラ — AWS Trainium の全貌
AWSシリコン
- Nitro System・・・仮想化基盤
- Graviton・・・ARM CPU
- Trainium / Inferentia・・・機械学習向けアクセラレータ
Neuron・・・AWS の AI チップである AWS Trainium と AWS Inferentia を使って、機械学習モデルの学習・推論を高速に動かすためのSDK
NKI (Neuron Kernel Interface)・・・NeuronCore上で動く独自の計算カーネルを書くためのプログラミングインターフェース
AI エージェント時代における責任あるAIのベストプラクティスと実践例
不適切なコンテンツ、機密情報、ハルシネーションの対応
Responsible AIの根幹
- ガードレールの実装
- オブザーバリティの確保
なぜこの回答がされたのかをユーザーへ同時に提示する
アーキテクチャ道場
今回のテーマは下記の二つ
- コスト・回答品質・レイテンシーの最適化手法
- 設計・レビューのAI利用における問題
2026 Japan All AWS Certifications Engineers の発表
今年ようやくAll Certification Engineerに選定されました!

感想
AIエージェントを一人の同僚として、生産性を上げていくことが本当に大事だなと感じました。
kiro・CodeX・Claude Codeどれでもまずは使って、何かプロダクトを作ることが大事だなと思います。