導入
今まで徒然なるままに論文を読むなりしてきたわけだが、ついに自分がどこに居るのかわからなくなり、最後に自分がいた場所である対話システムの分野に一旦立ち戻ろう、となった5月の半ば。全体を俯瞰できるものを探した所、ちょうどよいものが見つかったので読んでみる。
今回読む論文+スライドは、Deep learning for Dialogue Systems というもので、2017年から毎年更新されている「(深層学習を用いた)対話システムってなんだよ」という聴者を対象にした「対話システムの今昔」を紹介するものです。これを書いているのは、National Taiwan Universityのコンピュータサイエンス・情報工学の助教の方、Microsoft Researchの深層学習研究チームの方、元Google Researchの研究者でAmazonの研究科学者の方の3名となっています。つまるところ ほぼほぼ無敵な布陣 というわけです。(あとOpenAIの自然言語処理の人も加わったら多分何も文句言えないですね…)
但しこの論文の趣旨は、「 Task-oriented Spoken Dialogue System (タスク指向な、音声を介した対話システム)」があり、つまり 雑談対話とかは趣旨ではないです 。
また以下の記事は Deep learning for Dialogue Systems の Univesity Tutorials である、KAUST 2019 で使われたスライド と 2018年度の論文を元に作成しています。
Dialogue Systems の種類と歴史
対話システムのはじまりへ目を向けると、1990年代の Keyword Spotting (ex. AT&T) というものから始まります。こいつは要するに、「AかBかCか言って、そしたらシステムがAかBかCかを判断します」、というようなものです。そこから マルチモーダル対話システム という風に進んでいき、最終的に皆さんご存知、 Virtual Personal Assisttants という風に進んできています。
Virtual Personal Assistants とは Apple Siri だとか、 Microsoft Cortana だとか Amazon Alexa だとか、 Apple Home Pod 、Google Assistant といったものを指します。これらの需要は、 専ら生活や仕事の補助 、という風になっており、例えばスケジュールを組んだりとか、ものを探したりだとか、といったものとみなされています。
またこいつらが良いとされる基準は、「ユーザが求める情報に簡単にアクセスできること」、「ユーザの抱えるタスクを効率的に消化できるように助けられること」と言われています。(Amazon Alexa Prize や NTT の対話コンペティションなんかは対話時間やユーザの満足度、が評価基準になっていたので少し違っていますね。)
さて、対話システム全体の変遷がなんとなくわかってきたところで、対話システムの二柱となる、雑談対話、タスク指向対話の2つの変遷を眺めると、以下のようになります。
雑談対話
- Seq2Seq
機械翻訳のように1入力to1出力の対話を行う - Seq2Seq with conversation contexts
文脈情報をもって複数(過去の情報を含む、という意味)入力to1出力の対話を行う[1] - Knowledge-groundes Seq2Seq
環境情報(Knowledge) をもって対話を行う。[2]
タスク指向会話
-
Single-domain, System-initiative
対話システム主導で、特定のドメインに特化した対話を行う。 -
Multi-domain, contextual, mixed initiative
複数のドメインに対応でき、文脈が考慮できる他、ユーザが多少対話の主導権を握ることも出来る。 -
End-to-End learning, massively multi-domain
End-to-Endな学習を行い、より多くのドメインに対応出来る。[3]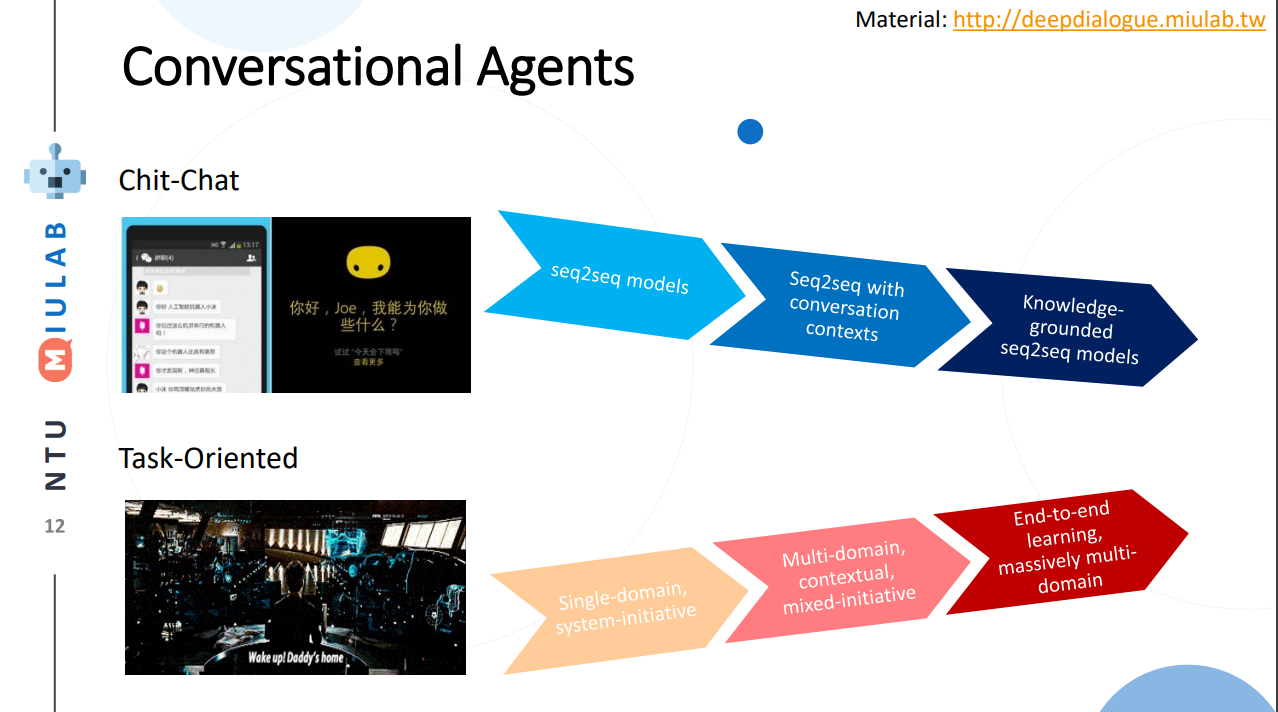専らこの論文では後者のタスク指向型の研究の紹介がメインになっており、実際見る限り研究分野としても後者のほうが(需要が高いので)沢山論文が出ているようです。
Dialogue Systems の基本形態
Dialogue Systems は特に最近では 実質なんでもあり なところがありますが、一応ベースとなる概要図というものがあります。それが以下です。これは 2011年に出された Spoken Language Understanding: Systems for Extracting Semantic Information from Speech という書籍に出てくる図です。これは標準的なパイプラインフレームワークということで、対話システムという一つのシステムの中にいくつかの小さなシステムがあり、それがデータを介して繋がっているという話になります。言い換えれば End-to-Endに何かでっかいモデルを使って処理しているわけではない 、というわけです(最近ではEnd-to-Endにしたいとかなんとか)。
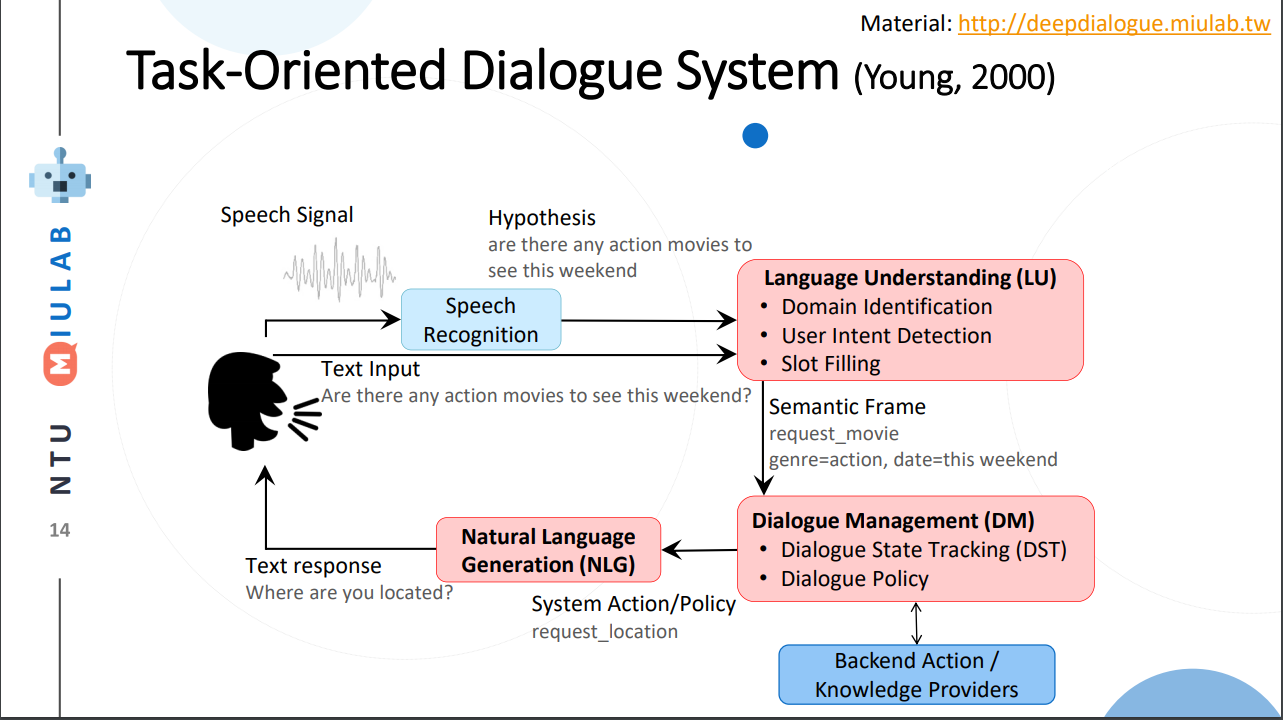
さて図を眺めてみると、 Speach Recognition 、 Launguage Understanding 、 Dialogue Management 、 Natural Language Generation 、そして Backend Action / Knowledge Providers 、最後に User の5つが登場していることがわかります。
そして研究者はこの5分野から任意の一つ、ないし複数の組み合わせ、ないし 任意の一つの中の一要素 について研究を行います。User ってなんだよ?と疑問に思う方が居るかもしれませんが、ユーザシミュレーションの観点から、人間から機械への発話のみを学習する、という面白い研究が存在しています[4]。
ここでやや駆け足にですが、上から4つの、それぞれで必要になっている技術をざっと一覧します。尚これはスライドや論文で述べられているものなどに留めており、 実際は問題設定によって目を背けたくなるくらいに増えます 。
Speech Recognition
音声をテキストに変換する部分です。ここが上手く行かないと、どんなに頑張っても全てうまく行きません。音声波形からテキストに変換するだけ、と一見すると思えますが、例えばどこが句点・読点であるのか検出することが難しいことや、同音異義語を区別するために過去の発話から文脈推定する場合があるなど、様々な問題・解決手法があります。 (この部分はスライドや論文ではあんまり触れられていないので、Gunrockを元に書いています。)
Language Understanding
言語理解、ということになっていますが、今回主に議論されているのは Natural Language Understanding (NLU) でしょう。雑に言うと、「お前の言っている文を読んだけど、つまるところ何を言っているんだ?」というものを解釈するための部分です。主に必要な要素は Domain Identification、User Intent Detection、Slot Fillingです。これはわかりやすさのために例を引用します。
状況はスマートフォンに搭載された対話システムに、レストランの予約を頼もうとするユーザの図です。まず音声入力はSpeech Recognition によって、「ここらへんに美味しい和食の店ある?」というテキストになります。これをNLUでは、
-
まずレストランについての話をしている、という風に クラス(ドメイン)分類 します (Domain Identification)。
こうすることで知識ベースなりデータベースなりのどの辺りを見ればよいのかという検討がつき、検索がしやすくなります。 -
次に「レストランを探している」という大まかな意味を 分類タスク をもって判定します(User Intent Detection)。
タスク指向型の対話システムで考えるならば"タスク推定"とも言えるプロセスでしょうか。一般的にはこの大まかな意味は先に与えられた複数の選択肢の中から選択する、という手法が取られています(Slot Fillingのためと思われる)。 -
最後に Slot Filling というプロセスでが行われます。
ここでは与えられている、「どんなレストランを探しているのか→"和食"」「どこのレストランを探しているのか→"ここ(位置情報なりより補完)"」「どんな感じのレストランを探しているのか→"美味しい”」といった タスクを達成するために必要な情報をテキストから抽出します 。欲しい情報を予め定義している場合が多いことから、Slot に情報を入れていく、という意味合いが感じ取れると思います。(尚実際にはテキスト中の単語に対してタグ付けをしていくという手法が一般的です。)以上のことから「
ここらへんに美味しい和食の店ある?」は{domain: "レストラン", query: "レストランを探す", slots [where: "...", kind, "和食", taste: "美味しい"] }みたいな情報に変換されます。
Dialogue Management
名前の通り対話全体の管理です。ここが上手く行かないと、お前は何を考えているんだ?となる部分だと思って下さい。主に必要な要素は、 Dialogue State Tracking、Dialogue Policy の2つです。ここではそれぞれが何をしたいのかをざっくり紹介します。
また論文やスライドではかなり曖昧にされていますが、 Dialogue State Tracking と Dialogue Policy の間で BackEnd Acton / Knowledge Providers との通信が行われており、具体的には Dialogue State Tracking 以前から得られた情報を元に、 Policyの選択肢を得るプロセスになっていると考えられます。
-
Dialogue State Tracking
ここはかなり複雑な部分で、恐らく元の論文やスライドを見ても簡単には理解が出来ないかもしれません。これは対話のプロセス全体を想像して見ることから始めて下さい。結局の所我々は一つの発話で全ての情報を伝えることは非常に少なく、 複数の発話によって 言いたい全ての情報を相手に与えることがほとんどです。すると対話が進んでいくと状態が進んでいき、あるところで終点(或いはExit(打ち切り))になると考えられます。これらをStateと考えると、これはマルコフモデルのような図を想像することが出来ます。これを管理するのが Dialogue State Tracking というわけです。
![]()
-
Dialogue Policy
ここは BackEnd Action / Knowledge Providers から得られた選択肢からどれを選ぶと最も高い報酬を得られるか考え、最も適当なそれを選択する部分です。この文脈における Policy というのは日本語でいうと"方策" というのが最もふさわしいでしょう。というのもこの部分に関しては、最近部分観測マルコフ過程の強化学習(Reinforest Learning)という枠組みで研究されることが多いからです(強化学習の文脈でPolicyはほとんどの場合で"方策"と訳されます)。
わかりやすくするため、NLUの例を持ち出すならば、方策リストとして「予算を尋ねる」「レストランAを紹介する」などが考えられ、報酬を考えた結果「予算を尋ねる」が選択される、ということです。
Natural Language Generation
ここではDialogue Management から出てきた方策の意味を示す文を生成する部分です。ここではテンプレートや、RNNベースのモデルを用いた文生成が行われます。問題となるのは例えば同じシチュエーションではほぼ毎回同じ出力しか得られないこと(タスクの達成だけを考えるなら無視して良いけど対話としては…)や、文中で同じ言葉を繰り返してしまうこと(頭痛が痛い、とか、子供の児戯とか)などで、ルールベースに解消したり、Attentionメカニズムを使ったり色々な手法で対処しようと研究が行われています。
求められていること
少なくともこのスライド上では、対話システムの課題点としては以下の点が挙げられるとしています。詳しい話は書いていなかったので、解釈を補足して紹介します。
-
Variability in Natural Language (自然言語の多様性)
これは文面通り受け取っても問題ないと思います。つまりテンプレート時代などから続く回答文の種類の少なさを解消したい、対処できるドメインの数をもっと増やしたいという意味だと推測しています。 -
Robustness (堅牢性)
雑に言えば、 わけのわからない出力文を生成しないようにしよう、ということでしょう。これは特に深層学習ベースで対話システムを組む際には避けては通れない道だと思われます。恐らく出力文を文脈なり文法なりで一度チェックする機構を整備することや、万が一問題があったときの対処を検討する必要がありそうです。 -
Recall / Precision Trade-off
これは機械学習全般で言われていることです。詳しい話は このブログ が参考になると思います。対話システムでこの例を挙げるのは難しいので、別の例を挙げて説明すると、砂場で砂金を集めようとする際に、全部の砂金を集めようとすると余計なものである砂も沢山集めてしまうことがある、砂を絶対に集めないようにしようとすると砂金を見逃してしまうことがある、というようなものです。 -
Meaning Representation (意味表現)
自然言語処理で避けては通れないこの お気持ち というフレーズですが、大体の雰囲気で言うと、文章の意味構造を分析する、ということです。これは例えば指示語が何を言っているとか、その文脈でその単語はどんな意味を表しているのか、とかそういったものを指しています(多分)。この辺りは沢山論文や研究を読んで気持ちになるしかないですねぇ… -
Common Sence, World Knowledge (常識)
これもまた自然言語処理ならではの課題で、そしてこいつは極端に論文になりづらい分野です。このスライドや論文でもほとんど言及がありませんでした。どういったものかというと、「世間一般の常識をコンピュータに教えられるか」という問題を指します。これは現段階ではTwitterなどから泥臭くデータを集めてKnowledge Base(Amazon Naptuneとか)を用いる手法が一般的で、それ以外ではConcept Netというクソデカオープンソースプロジェクトに泣きつくことなどがあり、日本だと昔中原先生が「日本人検定」というアプリを開発してデータ収集をしていました[5] し、京都大学とYahooも同様のアプリを作りデータを収集していました[6]。 -
Ability to Learn (学習能力)
この場合の学習能力、というのは集まるデータを学習させることを指しているか、或いはそもそものモデルの性能について言及していると思います。前者については定期的な再学習することやオンライン学習、後者は最近研究が盛んな言語モデル辺りを積極的に活用できると良いんじゃないですかね?(遠い目) -
Transparency (透明性)
これも機械学習ならではの問題でしょう。特に深層学習なんかは学習の中身がブラックボックス、と揶揄されていますね…
今の研究のトレンド
2019年度のスライドで紹介された最新のトレンドと、特に現在持ち上がっている課題を紹介します。
End-to-Endな対話システム
End-to-Endというのは一種類のモデル(とはいえ複雑だったりします)でうまいこと対話システムの全体、ないし一部をまとめて学習するモデルを指します(例[7])。
これによって得られる恩恵としては、他のシステムのせいで精度の上限が決まってしまうという問題の解消が挙げられますが、その恩恵を得られるだけの十分なデータを集めるのはエグそうですね。
Multimodality
日本では大人気(?)なマルチモーダルです。例えば画像とか映画とか、そういった情報も処理できるようにしよう、ということです。
これを用いる利点としては、言外の文脈を理解することが出来る、というものがあります。例えばテレビの前に座っていることがわかればなんとなくテレビ番組の話をするのかな?と予測することが出来ることなんかが考えられます。
Dialogue Breadth
これは簡単に言ってしまえば ドメインを広げる ということです。Dialogue Systems の種類と歴史 の、タスク指向型対話システムの歴史にあるように、現在までに Single domain → Multi-domain へと成長してきたわけですが、ここから次に目指すのは、Open domain 、というわけです。そのためには外部知識をもっと増やすことや、ドメインの切り替えを上手く行うことなんかをやらなければならないと考えられます。
Dialogue Depth
こちらは簡単に言うことは難しいので、図を引用します。下から上の方が難易度が高い、ということになっています。Empathetic systems というのは、 共感が出来る システムを指します。
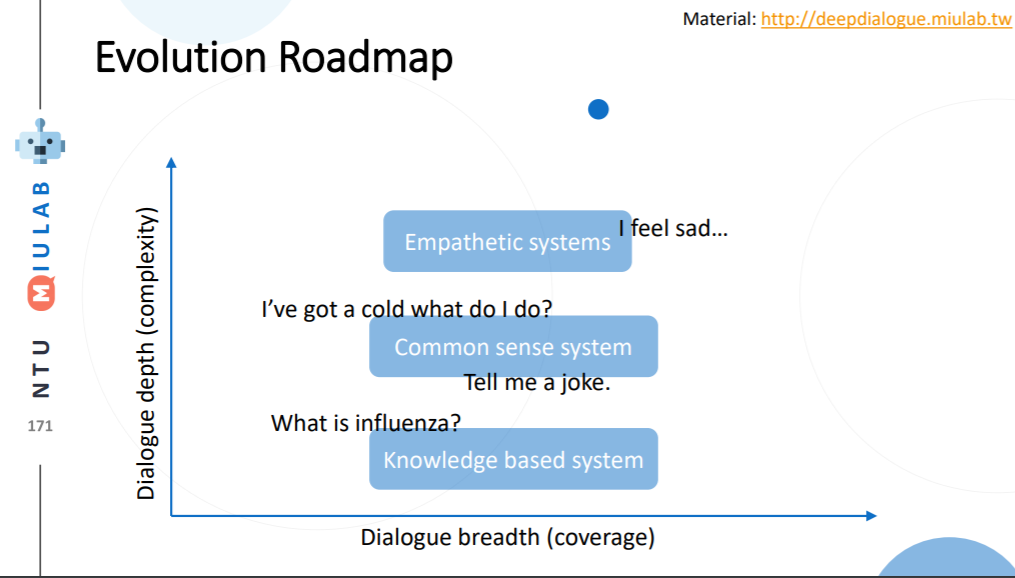
これを解決するにはより文脈を理解する必要がある他、常識について学習させる必要があると考えられます。
[1]: A Hierarchical Latent Variable Encoder-Decoder Model for Generating Dialogues. Iulian V. Serban et al.
[2]: Knowledge-grounded Neural Conversation Model. Marjan Gazvininejad et al.
[3]: End-to-End Task-Completion Neural Dialogue Systems, Xiujun Li et al. (abstract)
[4]: A Sequence to Sequence Model for User Simulation in Spoken Dialogue Systems Layla El Asri et al.
[5]: コモンセンス知識獲得を目的としたソーシャルゲーム"日本人検定" 中原 和洋
[6]: 連想ゲームによるコモンセンス知識の獲得 大谷直樹 et al.
[7]: Dialogue Learning with Human Teaching and Feedback in End-to-End
Trainable Task-Oriented Dialogue Systems Bing Liu et al.