VTuberのためのフェイストラッキング
現在手軽に利用できるフェイストラッキングの技術の中で主要なものとして、ARKitとMediapipeが挙げられます。
ARKitはiOS向けのフェイストラッキングであり、高い品質のトラッキングが期待できます。
一方でMediapipeはGoogle社から展開されており、一般的な動画や画像を入力として処理することができます。アーキテクチャや個別のモデルなども公開されており、透明性が高いことに特徴があります。しかしながら、利用条件によってARKitと比べると精度面で不利に見える場面があります。
もちろん他にもさまざまな手法がありますが、今回は取り扱いのしやすいこれらのフェイストラッキング技法の傾向を観察したいと思います。
それぞれが出力する最終的なBlendshapeの値に着目してみていきます。
※ 図ではすべてのBlendshapeを表示しています。そのため文字が非常に小さく読みづらいものとなっています。詳細が気になる場合は拡大表示してご覧ください。
事前準備
比較のため、同じシーケンスにおける出力結果を得る必要があります。
そのためまずは、ARKitとMediapipeの処理を同期させて結果を出力するコードを準備します。
詳細は割愛しますが、ARKitの認識〜出力に対応したスマートフォンのアプリからデータを送信し、Mediapipeを走らせているコード内で受信する形をとります。この際、厳密にはARKitで取得したカメラ画像も合わせて送信してそれに対して処理をかけることでより正確な比較になるかと思いますが、iPhoneのカメラとWebカメラを横並びにした形で取得する流れで今回は実施します。それぞれのアラインメントや正規化処理でこの程度の誤差は吸収してくれるものだと判断します。
各Blendshapeが一通り反応するようなシーケンスを収録します。データは1372フレームとなりました。
以降の結果は今回収録したシーケンスに依存する結果となる点はご容赦ください。シーケンス内での演技の傾向などに応じて一部結果は大きく異なることが想定されます。特にシーケンス全体での強度を含む発火傾向をみようとする場合には、同一手法内でのBlendshape比較は不適切かもしれません。
一方、今回の主目的としては特に違いが出やすいBlendshapeを特定することなので、その点は問題ないかと思われます。
傾向の観察
さて、下記ではそれぞれの手法において、まずはBlendshapeがそれぞれどのように影響しあっているのか観察してみます。
その後、手法間の傾向や違いを観察し、考察していきます。
Mediapipe内での相関傾向
まずはMediapipeにおけるBlendshape相関を観察してみます。顔の動きの中で、どのBlendshapeがどのBlendshapeと同時に発火しやすいかみえてきます。
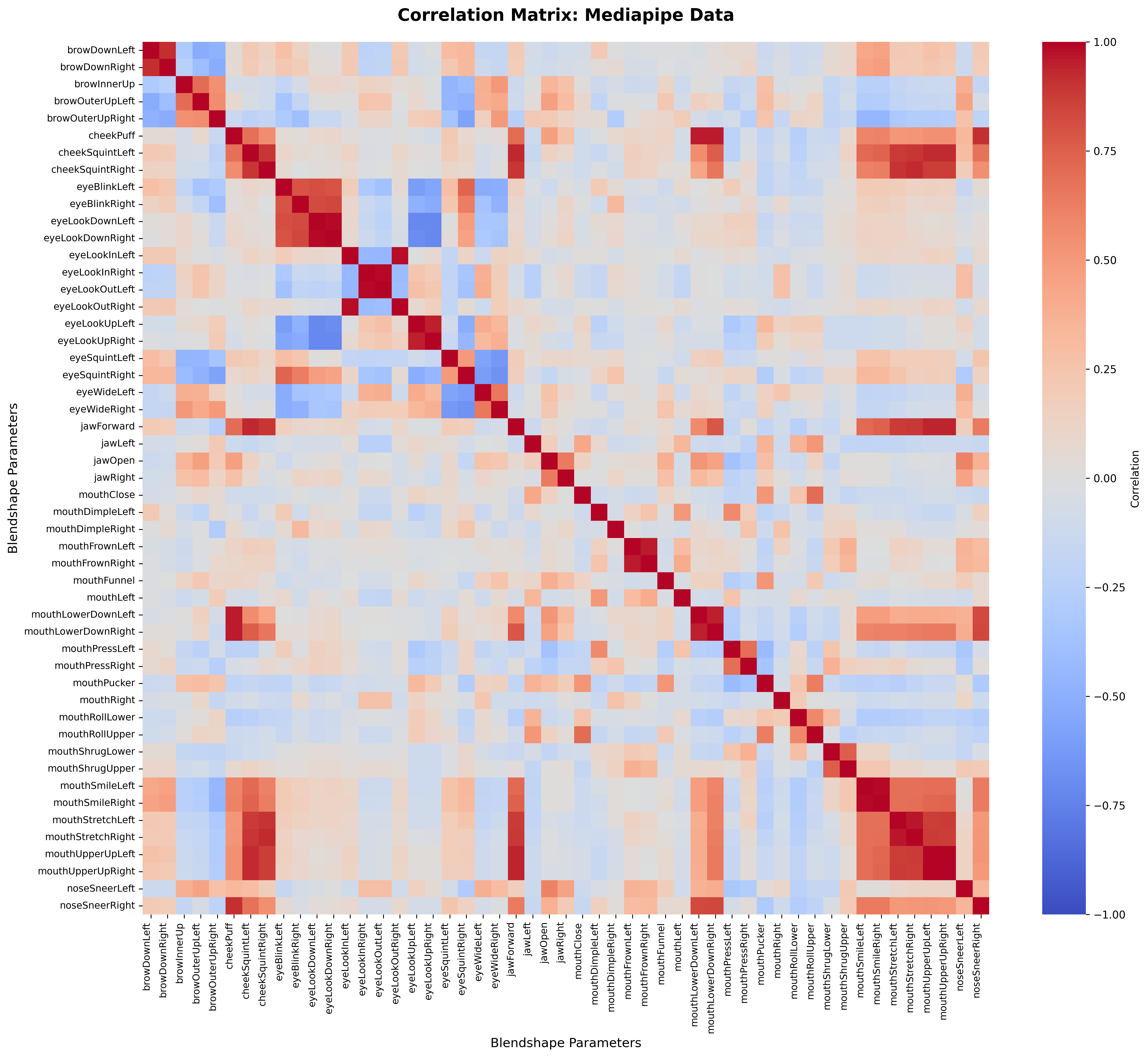
左右間の関連は当然でありますが、jawやmouthがcheek系と連動していたり、eyeLookDownはeyeBlinkと連動しやすいといったことがわかります。
さらに詳しく解析してみます。

左上:標準偏差
左下:平均
右上:レンジ
右下:変動係数(CV)
を表示しています。
まずわかりやすい特徴として、
cheekSquintLeft
cheekSquintRight
noseSneerLeft
noseSneerRight
cheekPuff
の5つは、今回収録したシーケンスでは値の変動がほとんど見られず、実質的には使えていないような挙動でした。
その他にもjawForwardやjawRightといったBlendshapeは反応が悪いです。jaw系についてはデータに依存する点はあるかと思いますが、それでも相対的に反応がしづらいようです。
eyeSquintLeftが極端に平均値が高いですが、これもまた収録時のカメラと被写体の画角の影響はあるかもしれません。
変動係数については、イベント(特定の表情)に準拠して反応するBlendshapeを特定するのに役立ちます。自然な表情遷移ではなく、明確に通常顔から変化があったときにだけ反応するような場合です。しかしながら、後述するARKitと比較するとMediapipeは全体的に安定傾向(値の変動が小さい)で、顕著な振る舞いは限定的のようです。
ARKit内での相関傾向
続いて同様にARKitの結果です。

Mediapipeで観測できていた傾向が薄まったりしていることがわかるかと思います。
一方で、cheekSquintがbrowDownに連動しやすかったり、tongueOutはjawとの関連が観測できます(tongueOutはMediapipeの方には実装されていません)。

ARKitについても先ほどの4項目を図示してみます。
どの図においても傾向がMediapipeと大きく異なりそうです。
まず、ほとんど反応しないようなBlendshapeはありません。
そして、各Blendshapeの可動域が明確に大きいです。
平均値も安定していて、常に一定の値をとってしまうような挙動も少なそうです。
変動係数の傾向も顕著で、目の動きやtongueOutのようなBlendshapeが明確にイベントによって発火されることが確認できます。
ARKitとMediapipeの相関
では改めて二つの手法のデータを比較していきましょう。
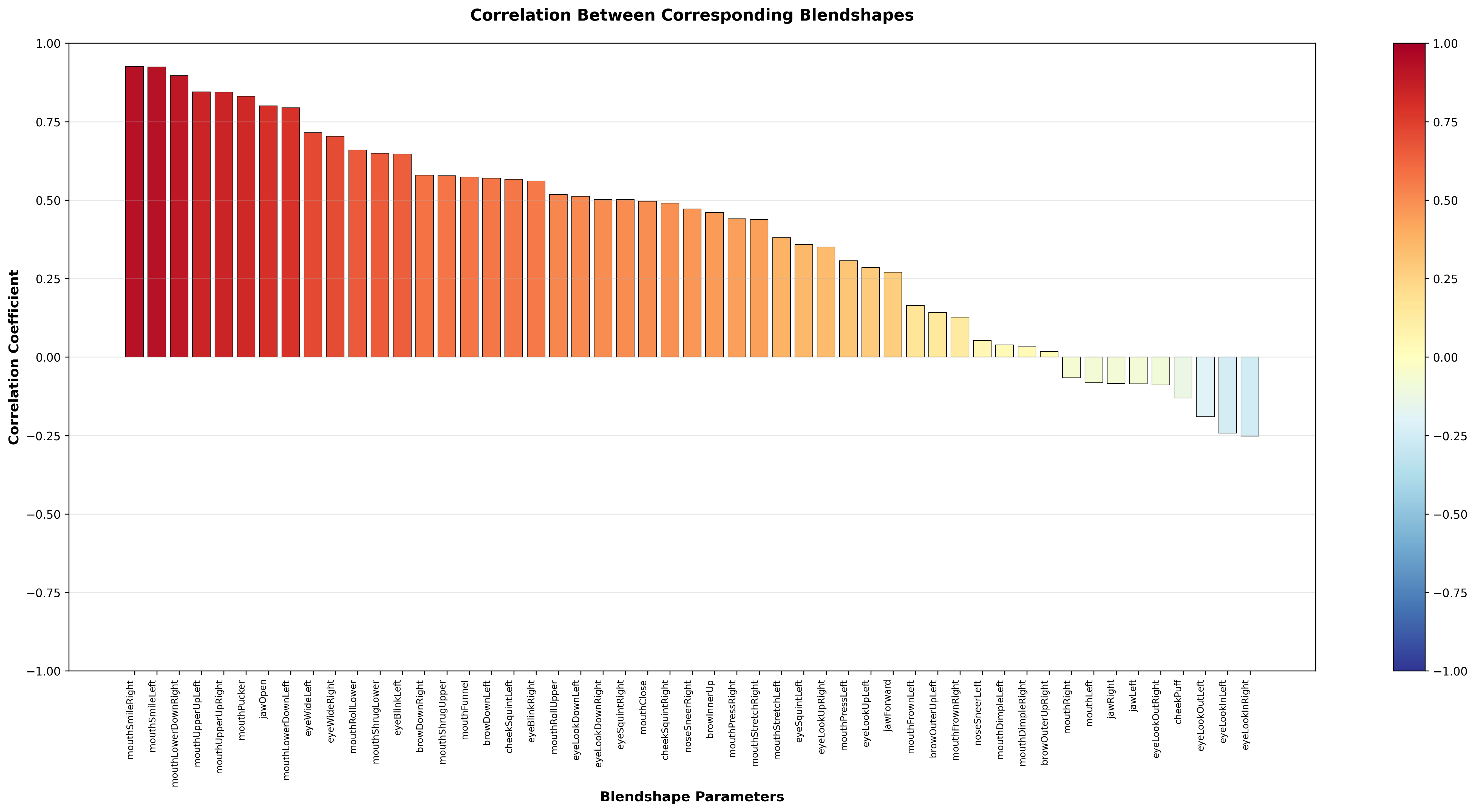
全体的にmouth系は相関が強そうです。MediapipeもARKitのように口パクや笑顔検知をする目的で利用することは問題なさそうにみえます。
しかしながら、反応が悪いBlendshapeもあり、口の細かな表現などには不十分かもしれません。
eyeLook系は負の相関を示していて、今回の条件においてはそのまま利用することが難しい挙動となりました。
考察
(ほぼ)同じシーケンスで、(ほぼ)同様なBlendshape定義を持つ手法であっても検知できる値に大きな違いが観測されました。
Mediapipeの方での結果をみていると、eyeSquintLeftのように平均的な発火傾向が強いBlendshapeがあり、ここから設営条件や個人差の影響を受けやすいことが考えられるのではないかと思います。Mediapipeの実装を調べてみると一応センタリングやスケーリング処理は含まれているようですが、それでも今回は顔の位置・個人差の影響を受けやすい印象でした。セットアップや個人に応じて、基準顔をベースにキャリブレーションしてあげるのがよさそうに思えます。
ARKitは相対的に全体のBlendshapeがバランスよく反応し、安定して動いているように感じられます。とはいえ、Blendshapeによってはレンジが大きく異なるものもありますし、各パラメータの反応傾向を観察・理解しておくとデザインに応用する際に有益かもしれません。
おわりに
二つのフェイシャルキャプチャ手法について、その傾向を観察してみました。
今回は単一のシーケンスに基づく大雑把なデータなので、データによっては異なる結果が得られる可能性についてご留意ください。
全体的にMediapipeのパフォーマンスについて批判的な内容になってしまったかもしれませんが、Mediapipeはやはりカメラの種類に依存せずに気軽に利用できる点において優れています。またそれゆえに、いまだに多くの場面で活用されています。性質を理解すれば、より表現力を向上させながら活用できる可能性もありますので、今後もさまざまな応用が期待されます。