
こんにちは、まゆみです。
Pandasについての記事をシリーズで書いています。
今回は第35回目になります。
今までの記事では、
CSVデータを読み込みPandasでデータを集計したりする方法を述べてきました。

今回は、Pandasで計算した結果を CSVに書き込むという、今までのプロセスとは逆のプロセスになります
ではさっそく始めていきます。
今回使うデータ
前回の記事に引き続き、『NYC Open Data』のサイトから、アメリカの学校ごとにおけるSATテストの平均点に関するデータを用いていきます。(SATとは日本のセンター試験のようなものみたいです。)
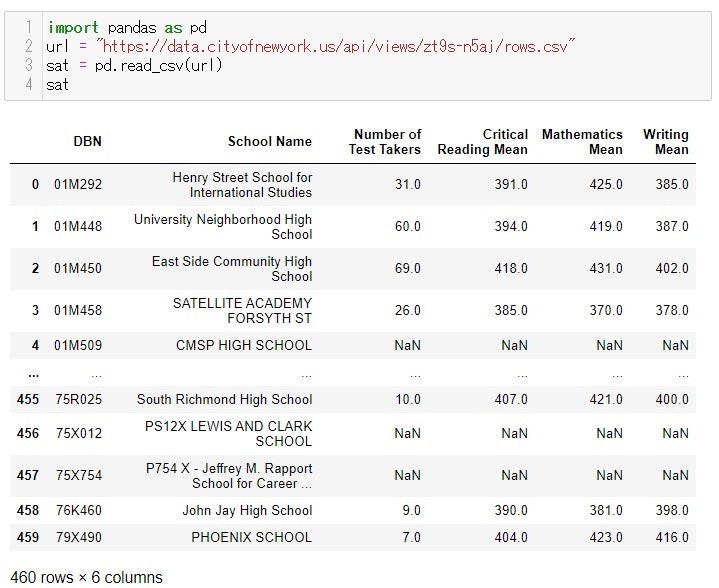
このコラムの中の
『Mathematics Mean』(数学の平均点)
を使って、数学の平均点が
~ 650 Very Good
650 ~ 550 Good
550 ~ 450 Fairly Good
450 ~ 350 Poor
350 ~ Very Poor
とグレード分けした結果をCSVに書き出してみたいと思います。
では、Pandasのメソッド.to_csv()メソッドの使い方を紹介します
.to_csv()メソッド

引用元:Pandasドキュメント
.to_csv()は、SeriesにもDataFrameにも使えます。
まず、一番忘れてはならないのが、Pandasの結果を書き出すための『CSVファイルを作ること』です。
CSVファイルを作ると言っても、引数にあなたの作りたいCSVファイル名を書くだけで大丈夫です。
下記のようにコードを書きます。
.to_csv("好きなファイル名.csv")
また、Pandasのドキュメントを見ていただければ『パラメーターindex = True』となっているのが分かると思います。
このままデフォルト値を使いますと、下記のような結果になります

index= False にすると、インデックスが入らないです。

.to_csv("ファイル名.csv", index= False)
また、扱うデータによって、『encoding error』が出る場合もあります
その時は、パラメーターencoding= "utf-8" を試してみてください。
Mathematics Meanのコラムにある値をグレード分けする
では、数学の平均点をそれぞれのグレードに分けていきましょう。
例として、550点以上、650点未満の得点を『good』というグレードに分ける方法のみを書いておきます。
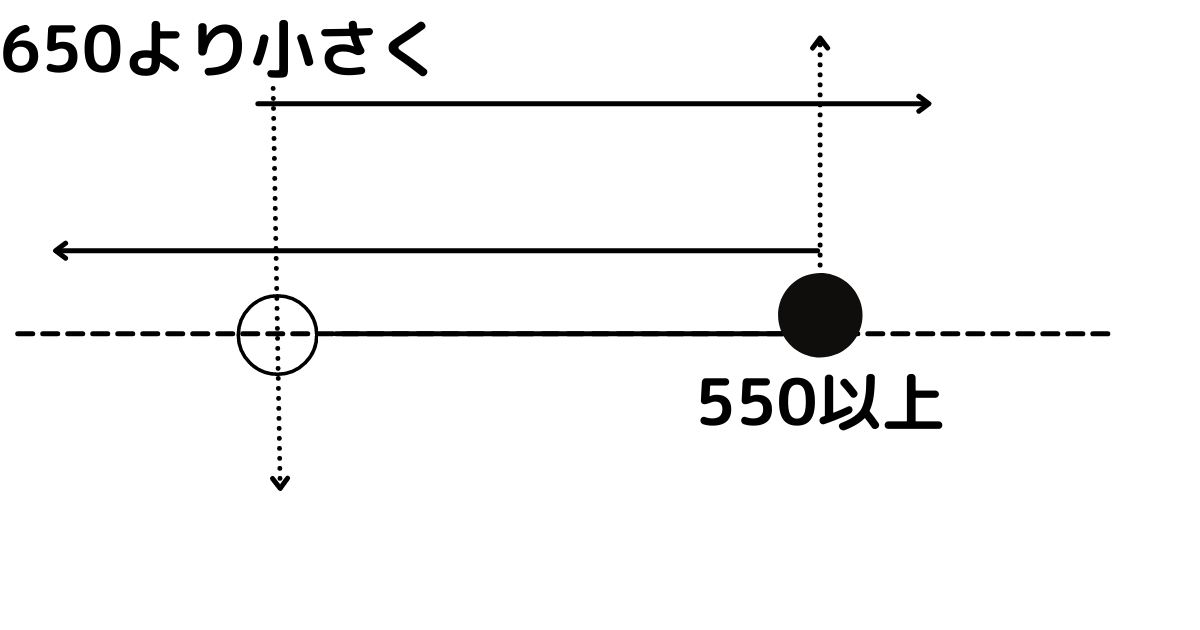
650未満
550以上
の両方を満たす部分なので『&』でつなぎます。

dateframe["コラム名"] >= 550
条件となるものを『mask』という変数に代入するのは業界の慣習のようです。
2つの条件が同時に満たされる部分が欲しいので、条件2つを&でつなぎます。
それらの条件を満たすアイテムの個数を知りたいので、len関数を使います。
その結果をgoodという変数に代入しました。
他のグレード(very_good, fairly_good , poor, very_poor)も同じ感じで、それぞれのグレードに評価される生徒の数を調べてみてくださいね。
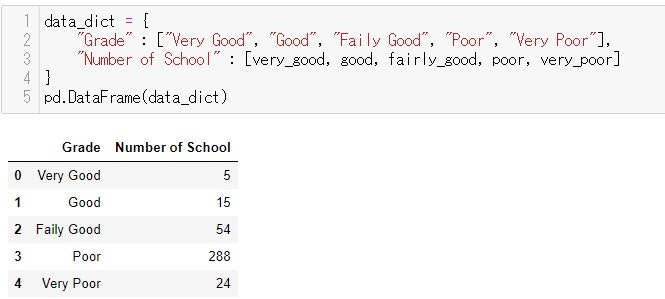
DataFrameを作る
PandasのDataFrameを作る時、引数に、辞書型データを渡すことができます
辞書型データを渡すと下記のようなDataFrameになります。


カレントフォルダー内を調べてみましょう
『math_grade.csv』ができています。
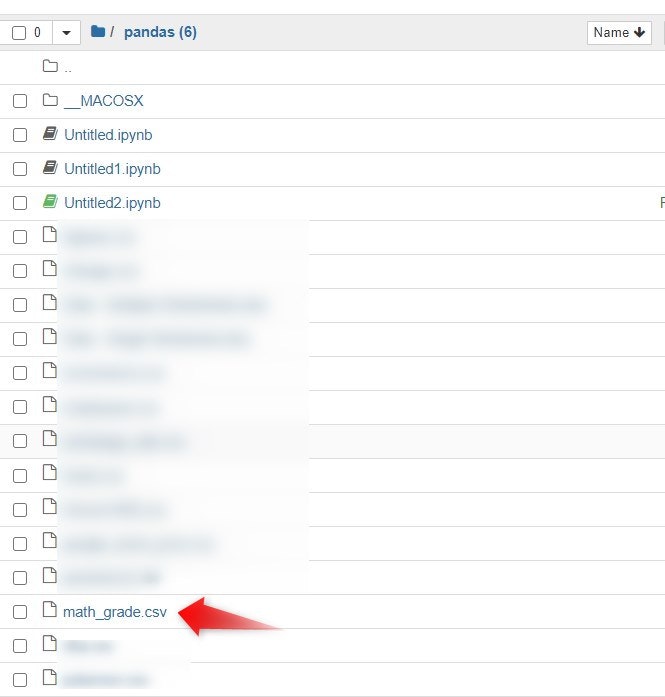
『math_grade.csv』を開くとこんな感じです。

同様にして、セントラルパークのリスはどんな色のものが多いかも調べてみます。
Central Parkにいるリスはどんな色が多いのかも調べてみた

こちらはセントラルパークのリスについて調べたデータになります。
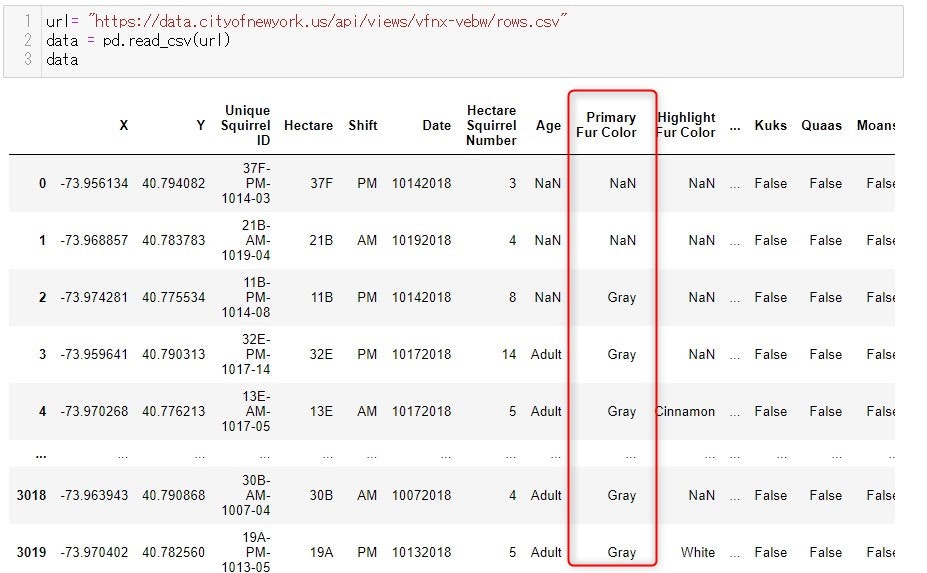
『Primary Fur Color』の各値がいくつあるか調べます。
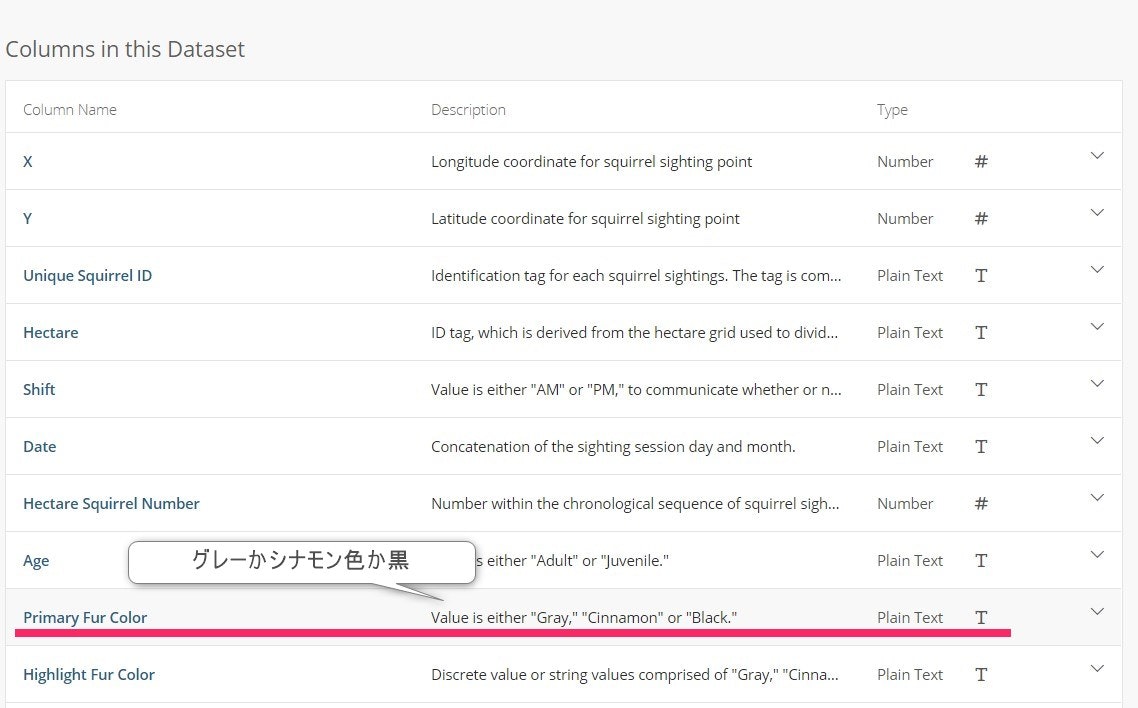
Primary Fur Colorの値は、Gray, Cinnamon, Black のみの3種類になります。
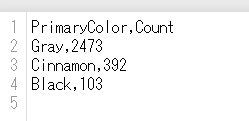
Gray のリスの数を数えます。

同様にして、black, cinnamon の数も抜き出しました。
先ほどとおなじく、
①DataFrame を作って
②CSVファイルに書き出しました。
まとめ
今回は、今まではCSVから読み込んでいたものを、反対に『CSVに書き込む』というのをやってみました。
お役に立てれば嬉しいです。