
こんにちは、まゆみです。
Pandasについてシリーズで記事を書いています。
今回は第27回目になります。
前々回の記事と前回の記事でPandasのGroupByオブジェクトについて記事を書いて来ました。
今回の記事では
- グループ化されたGroupByオブジェクトにfor loop処理をするにはどうすればいいのか
- どうしてそのようなコードになるかの理由
を書いていこうと思います。
ではさっそく始めていきますね。
今回使うデータ
今回も前回に引き続き、世界各地域別のゲームの売上高に関するデータを使っていきます
Genre(ジャンル)のコラムをグループ化しました。
下記がその結果になります。
グループ化されたオブジェクトを、genresという変数に代入しましたが、genreを表示させても、GroupByオブジェクトというオブジェクト名と、そのオブジェクトが保存されているロケーションしか表示されません。(下記参考)
ですが、コンピューターの裏側では、同じ値の物がまとめられています。(下記参考)
では、このGroupByオブジェクトを使って、
各ジャンルごとの日本での売り上げがトップの物を取り出してみましょう
.max()メソッドでは、最大値は取り出せるがDataFrame全体が表示されない
最大値を取り出すと言って、真っ先に思いつくのは.max()メソッドと思います
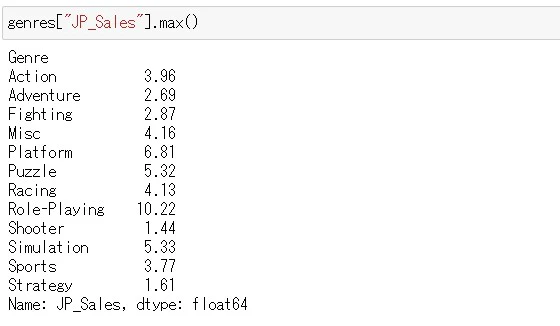
ただ、.max()メソッドだと、最大値自体は表示させることができますが、DataFrameとしては表示する事ができません。
そこで、
GroupByオブジェクトに対してfor loop を使う
ことで、その問題を解決する事ができます
GroupByオブジェクトをループ処理する

こんな疑問がわいてきますよね。
先ほど、言及したようにコンピューターの裏側ではグループ化されたオブジェクトが作られどこかに保存されています。(この記事の後半に、参考になる英語文献を翻訳して載せています)
イメージで言えばこんな感じです。
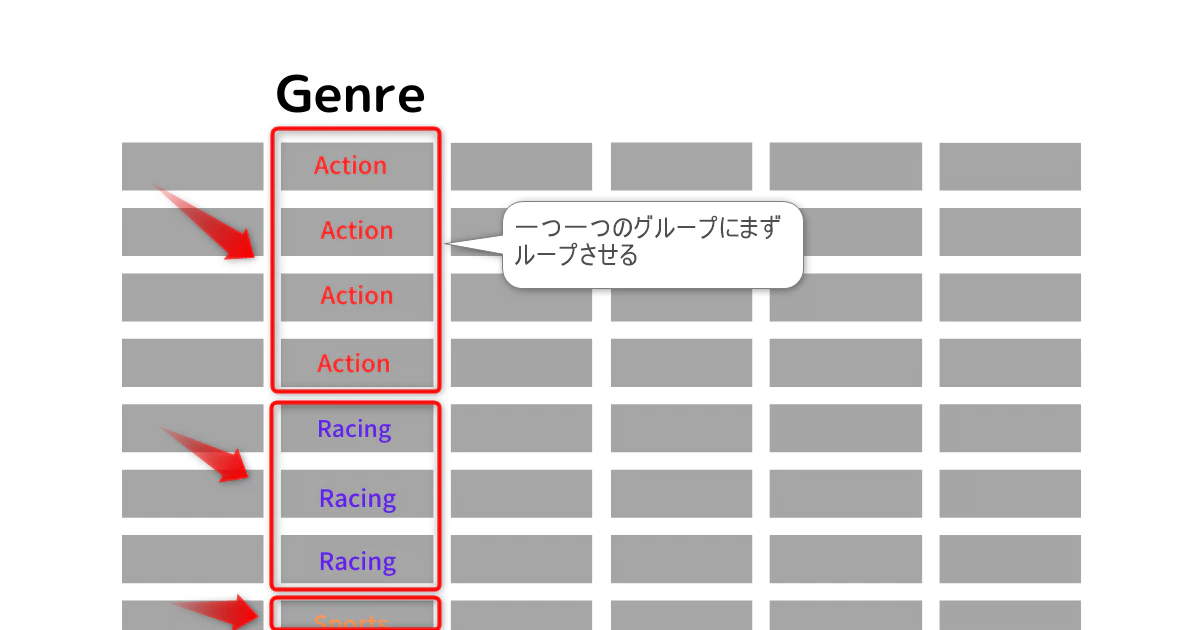
今回はジャンル (genresという変数に代入している) ごとにグループ化しているので、そのグループ一つ一つを (genre) として、一つ一つのグループに対してループ処理をしましょう。
これをfor loop の一つ目の変数にします(下記のコードの変数genre)
for genre in genres
ただ、各々のグループのなかで、さらに最高値を探す必要があるので、DataFrameの値そのものにもループさせます。
なので、for loop の2つ目の変数としてdataを付け加えます。
for genre data in genres
GroupByオブジェクトのループ処理になぜ2つの変数が要るのかについての理由が書かれている情報の引用をしておきますね。

引用元:kite
そもそもGroupByオブジェクトってどうなってるの?
では、一歩下がって、GroupByオブジェクト自体一体何なの?を考えることが、なぜfor loop に2つの変数が必要なのかを考える助けになると思うので、参考文献を下記に記します。
大事な部分だけ翻訳して載せておきますね。(引用元:Real Python)
split ステージ

翻訳:
GroupByオブジェクトとは一体何か?
GroupByオブジェクトの理解を難しくしている理由の一つに、GroupByオブジェクトは元来、怠惰であることがあげられる。
あなたが指示を出すまで、有益な結果を返すような処理を施さないのである。
GroupByオブジェクトについてたびたび使われる用語のひとつに、『split-apply-combine』(分割して-適応して-くっつける)というものがある。これは、連なった3つのステップについてのことである。
そのステップとは
①テーブルデータ(csvやexcelのようにテーブルの形式になったデータ)をグループに分ける
②その小さく分割されたテーブルデータそれぞれに処理を行う
③結果を結合させる
GroupByオブジェクト自体を可視化する事は難しい。
なぜならば、あなたがGroupByオブジェクト に対して何かをするまでは、実質的にGroupByオブジェクトは何もしないからである。
あなたがGroupByオブジェクトに対して何かのメソッドを呼び出すまでは、split-apply-combine のプロセスはされずに先送りされることになる。
では、その各々のステージが起こっているのを目にすることができないのに、split-apply-combineの各ステージに対してどのようにして心理的な区切りをつけていけばいいのか?
GroupByオブジェクトのsplitが実際に起こっているのを調べる1つの方法としては、反復処理をさせることである。
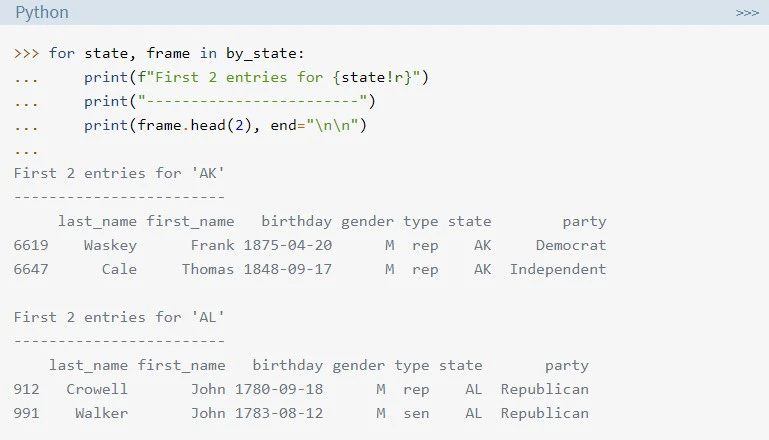
注意
iterate through は『反復処理する』と翻訳されますが、for loop と同義後です。
apply ステージ
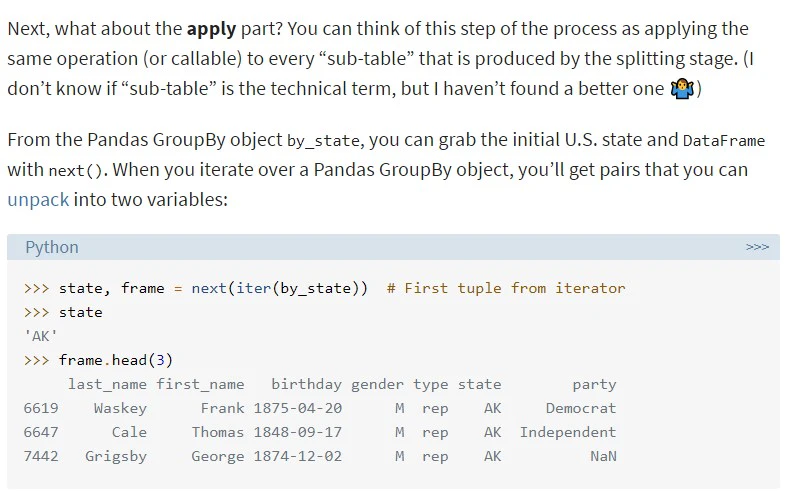
翻訳:
では、次にapplyについてはどうか?
このステップは、splitステージで作り出された 各々の"sub-table" (筆者は、sub-tableとは小さくグループ分けされたテーブルデータのことを指しています。専門用語でsub-tableと呼ぶのかについては疑問だがとも言っています)に対して、同じ処理を施すことだと考えてみましょう
GroupByオブジェクトに反復処理をすると、2つの変数に展開することのできる値を取り出すことができます
combine ステージ

翻訳:
最後のステップ、すなわちcombineは、これまでのステップのなかで一番明白であろう。
このステップでは、シンプルにsub-table別に処理がなされた結果を取り出し、それらを一緒に結合させます。
では、いよいよGroupByオブジェクトを使って、各ジャンルごとの日本での売り上げがトップの物を取り出してみましょう(前置きが長くなってすみません<(_ _)>)
GroupByオブジェクトにfor loop を使う
先ほど説明したように、2つの変数を使ってfor loopを書きます
for genre , data in genres:
dataにループ処理をする中で、一番値の大きい物を取り出したいので、.nlargesta()メソッドを使います
for genre , data in genres:
highest_sale = data.nlargest(1, "JP_Sales")
この取り出した、各ジャンルの最高値をどこかに入れなくてはいけないですね。
なので、インデックスのみで、値が何も入っていない『空のDataFrame』を作っておきます
df = pd.DataFrame( columns= video_sale.columns )
df
実行結果は下記のようになります

オリジナルのDataFrameのコラムのみを引数として渡し、コラム名だけのDataFrameを作りました。
このDataFrame に先ほどのループ処理で取り出した最大値を付け加えていきましょう。
付け加えるのには『append』を使います。
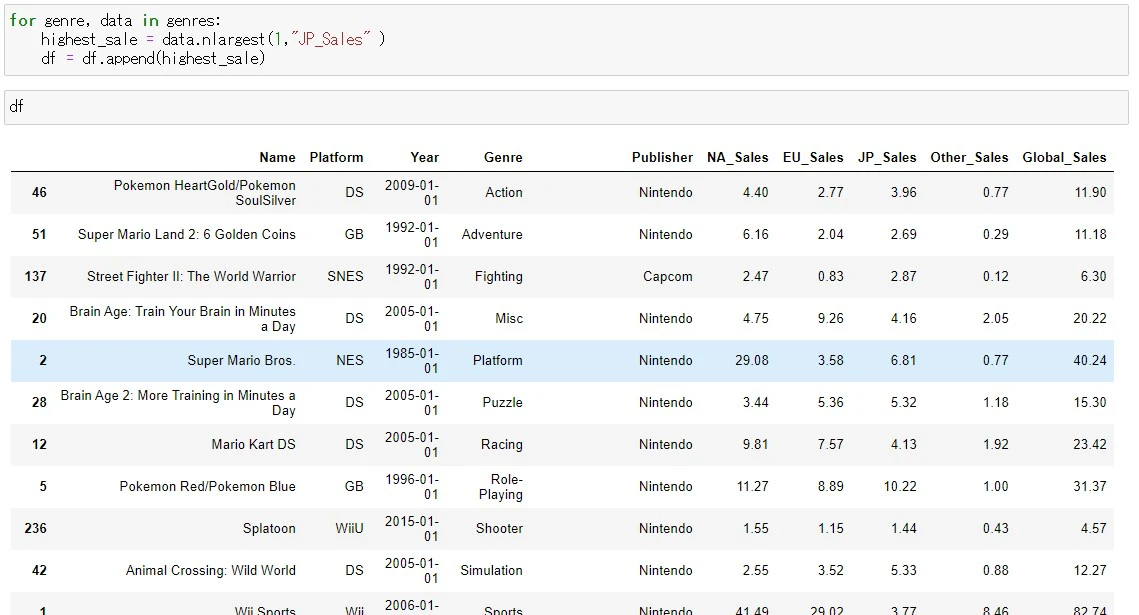
上記のように、各ジャンルの中で、日本の売り上げがトップの物のDataFrameが出来上がりました。
まとめ
今回の記事はこれくらいで終わりにします。
今回の記事はいつもより少し長めになってしまいました。<(_ _)>
これに懲りずに、次回以降もどうぞよろしくお願いしますっ!