
こんにちは、まゆみです。
Pandasについての記事をシリーズで書いています。
今回は第25回目になります
今回の記事では、Pandasの『Groupby』について書いていこうと思います
Groupbyとは、Groupという文字通り、ある特定のコラムをグループ化します。
そしてオリジナルのDataFrameとは別のGroupbyオブジェクトが作られます。(詳しくは後述します)
言葉で説明するよりも、コードの実行結果を示しながら説明する方がクリアになると思うので、さっそく始めていきますね
今回使うデータ
今回は、日経225企業についてのデータを使っていきます
CSVデータを読み込むと下記のようになりました。

社名が書かれた『名称』というコラムをグループ分けするのは、全く意味がありませんよね。
なぜならば、社名は個々で違うのでグループ分けしようがないからです。
今回のデータで言うと『日経業種』とラベルが書かれたコラムなど、1つのグループのなかにいくつかの会社名がカテゴリー分けされるコラムを選んで、Groupby していきます
.groupby()メソッド
では、『日経業種』コラムに、.groupby()メソッドを使います
実行結果は上記のようになります
Pandasの.groupby()メソッドを使っても、
グループ分けされたDataFrameが表示されるわけでもなく、オブジェクト名と保存されているロケーションのみが表示されるだけ(GroupByオブジェクトと呼ばれます)
です。
GroupByオブジェクトは、変数に代入して、オブジェクトに対してメソッドやアトリビュートを使ったりするまでは、グループ分けしたことで得られるメリットは得られないでしょう。
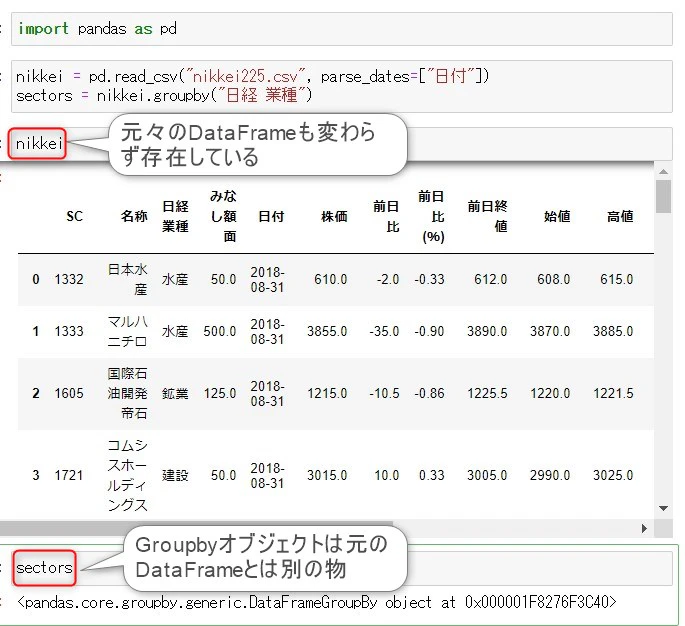
nikkei というDataFrame から作ったGroupByオブジェクトをsectorsという変数に代入します
また、.groupby()メソッドを使ったからと、元のDataFrameが変更されるわけではなく
元のDataFrameとは別の
もう一つ別のGroupbyオブジェクトが作られます。
groupbyオブジェクトにメソッドを使う
.size()
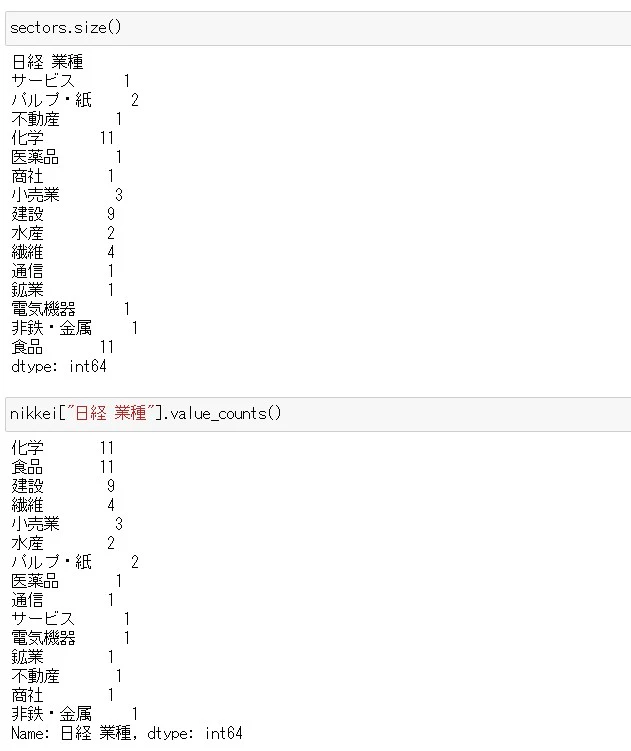
.size()を使うと、それぞれにグループ分けされた要素のアイテム数(row(列)の数)を返してくれます
groupby_object.size()
と
dataframe["コラム名"].value_counts()
はやってくれること自体は似ていますが、value_counts()では、数字が大きいもの順に並べられています
.groups アトリビュート
PandasのGroupby オブジェクトに使える便利なアトリビュート.goups を紹介します

引用元:Pandasドキュメント
Pandasドキュメントにあるように、.groupメソッドはPythonの辞書型データを返してくれます
その辞書がどのような構造になっているかというと
![{group1_ [ row, row], group2_[row, row]}.png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F1011305%2F31691282-1254-3686-1068-12b9174313fb.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=24f8ccfaee7f1b343f82283de8ec7ebe)

パルプ・紙に分類された値が、37、38列目にあることが分かるので、
.iloc[]で、列全体を指定すると

2つのrowを指定した時は、上記の実行結果のスクショのうち上のような形で、1つだけrow を指定した時は、下のような形で表示されます。
もしくは、先にどのグループのデータを取り出したいか分かっている時は、下記のメソッドが使えます
.get_group()

.groupby()メソッドはパワフルなメソッド
結局、.groupby()メソッドがやってくれることはこの記事に書かせてもらったことと同じです。
条件に合致するものを抜き出して、それをまた同じコラム名に代入して。。。
ただ、.groupby()を使えばもっと早く、もっと少ないコードで同じことをすることができます
まとめ
今回の記事はこれくらいで終わりにします。
まだまだ、GroupByオブジェクトに対して使えるメソッドやオブジェクトは他にもたくさんありますが、記事がめちゃくちゃ長くなってしまいそうなので。
次回もまた、GroupByオブジェクトをどのように活用するかの記事を書いていきますね。