
こんにちは、まゆみです。
Pandasについての記事をシリーズで書いています。
今回は第34回目になります。
今回は、前回使ったデータと同じものを使い
PandasのオブジェクトをPythonの辞書やリストに変える方法を書いていこうと思います。
Pythonの辞書やリストの扱いは慣れている方が多いと思うので、変換後、色々なメソッドを使ったりしてみてくださいね。
ではさっそく始めていきます。
今回使うデータ
前回の記事と同じデータを使います
アメリカの学校ごとの、SATの平均得点を調べたデータです。
SATとは日本のセンター試験のようなものみたいですね。
(Web上で更新されているサイトから最新のCSVデータの読み込み方が分からない方は前回の記事を参考にしてください。)
PandasのオブジェクトをPythonのオブジェクトに変換する方法

Pythonのリストに変換する
.tolist()メソッド(toとlistの間にアンダーバーがない事に注意)を使うとPythonのリスト型データに変換する事ができます
『SchoolName』とラベルの付いたコラムをリスト型データにします。

Pythonの辞書に変換する
では次に、.to_dict()メソッドを使って辞書型データに変換してみましょう

ここで、注意なのは、辞書型データにしたときにもしkey が重複した場合、最後のkey のみが使われた辞書型データになるということです。
今回はデフォルトのインデックス(0から始まるインデックス)をそのまま使ったので、重複する事はありませんが、もしインデックスをカスタマイズする時には注意が必要です。
データのフォーマットを揃えてみる
ただ、今回読み込んだデータのSchoolNameはフォーマットが統一されていません。

そしてあなたは、美人だけど仕事には厳しい上司に下記のような仕事を言い渡されました。

.join()メソッド
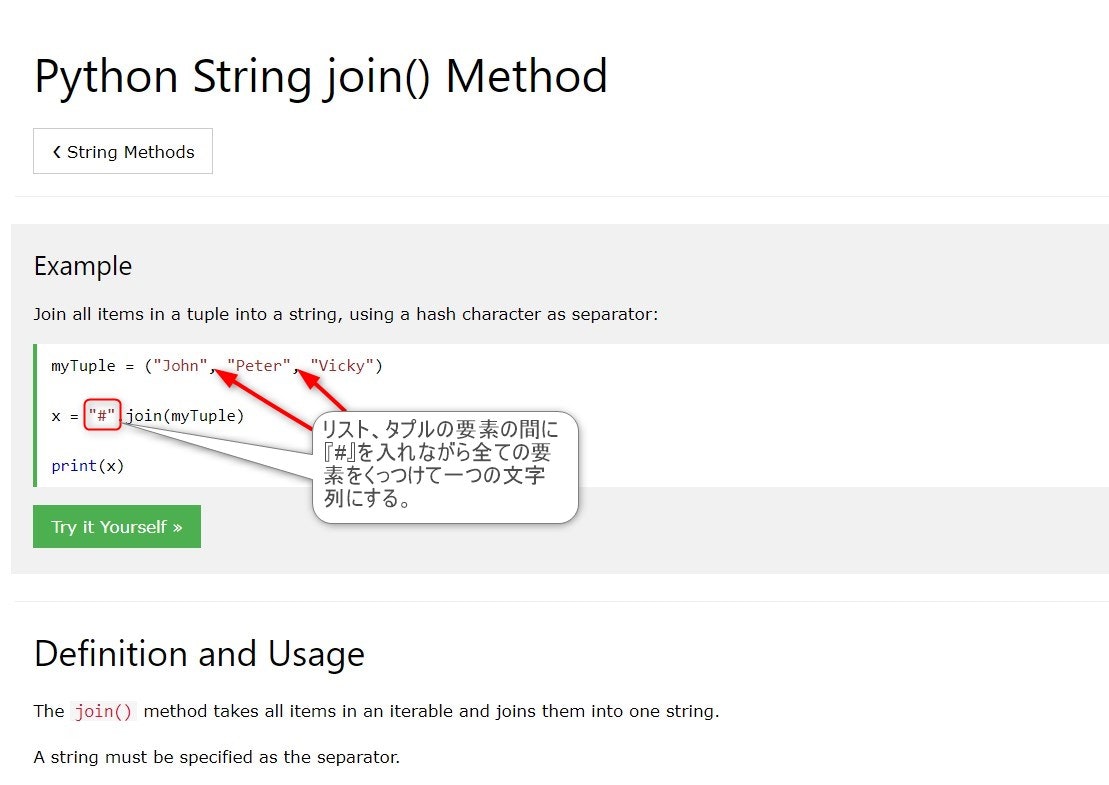
引用元:w3schools
.join()はPythonのメソッドですが、引数にPandasのSeriesを渡すこともできます
それぞれの学校名を『, 』(カンマとスペース)で区切り一つの文字列として渡したいのなら
", ".join(df["コラム名"])
実行結果は下記のようになります


title()メソッドで、それぞれの単語の頭文字を大文字にすることができます。(.title()メソッドは単語と単語の間のスペースによってそれぞれを別の単語だと認識し、頭文字を大文字に直してくれます。)
ただ、PandasのオブジェクトにPythonの文字列に関するメソッドを使う時は、間に『.str』が必要です。
(.strについてはこちらの記事で詳しく説明しています。)
",".join(df["コラム名"].str.title())

全ての学校名の頭文字が大文字になりました。

.sort_values()
.drop_duplicates()
はどちらもPandasのメソッドであるので、先ほど.title() (Pythonのメソッド) とSeriesをつなぐ時に必要だった『.str()』は上記のメソッドを使う時は必要ありません。

学校名が同じフォーマットで統一され、重複するものははじかれ、アルファベット順に並べることができました。
まとめ
今回の記事はこれくらいで終わりにしますね。
次回の記事では、jupyter notebookであれこれ触ったデータをCSVファイルに書き込む方法を書いていきますね。