
こんにちは、まゆみです。
Pandasについての記事をシリーズで書いています。
今回は22回目になります。
今回の記事からしばらくの間、DataFrameの中のテキストの処理の仕方について書いていきます
DataFrameの値の中には、
- 望まないところにスペースが入っていたり
- 全て大文字で書かれていたり
- 一つのセルに複数の値が入っていたり
- 他もろもろ。。。
で、あなたが望む処理ができない時があります。
そのような時の解決策を、今回の記事から少しずつ紹介していこうと思います。
今回の記事では
- Pythonのテキストに関するメソッドをPandasで使う時に必要なこととは?
- 給料の前に『$』がついていて計算のメソッドが使えないとき、どうしたら良いのか?
を書いていきます
ではさっそく始めていきますね。
Pythonの文字列に関するメソッドを使う時に必要な『.str』
Pandasでデータを処理したい時に、合わせてPythonの文字列に関するメソッドも使いたい時があると思います。
例えば
.lower() 全てを小文字にするメソッド
.upper() 全てを大文字にするメソッド
.title() スペースで区切られたそれぞれの単語の最初の文字だけを大文字にするメソッド
.len() 文字数を数えてくれるメソッド
など、上記に示した以外のPythonメソッドも使いたい時があると思います。
その時に、必要となるのが『.str』になります

上記の様に、Series(もしくは、DataFrame["コラム名"])とPythonのメソッドの間に.strを入れます。
具体例を出していきますね。
今回使うデータ
卒業学部とサラリーの関係のデータを使っていきます。
ある大学学部を卒業した時の初任給や経験を積んだ後の、サラリー額上位10%の値や、下位10%の値などのデータになっています。
興味のある方は是非、見てみてくださいね。
今回使うデータの中の、『Undergraduate Major』というコラムのなかの値が全て文字列になっているので、このコラムを使ってPythonのメソッドが使えるか試してみます。

全て、期待通りに実行されました。
1つ注意点は.len()メソッドを使う時、スペースも1文字としてカウントされるということです。
Salaryを文字列から数列にする
例えば、給料のデータに
¥マークや$ マークがついていたり、カンマ(,)が3桁ごとに打たれているデータをよく見かけると思います。
$ 100,000は数列ではなく、文字列になるので計算に関するメソッドなどが使えないですよね。
そこで
①$マークや、カンマをPythonの、.replace()メソッドで、取り除く
②Pandasのastype()でデータのタイプを変更する
で、計算のメソッドが使える数列に変更します
Pythonの.replace()メソッド

要らない文字を削除するというよりは、$とカンマを空白に置き換える(=replace)と考えてください。
また、今回のように2か所変更したい文字がある($を取り除くことと、カンマを取り除くという2か所)がある場合は、
.replace("A","").replace("B","")
と.replace()を2つ繋げます。(""が文字列の無い事を表しています)
PandasのSeriesオブジェクトに対してPythonのメソッドを使う時は、先ほど説明したように、.strをオブジェクトとPythonのメソッドの間に入れます。
Series.str.replace("A","").str.replace("B","")
で大丈夫です。
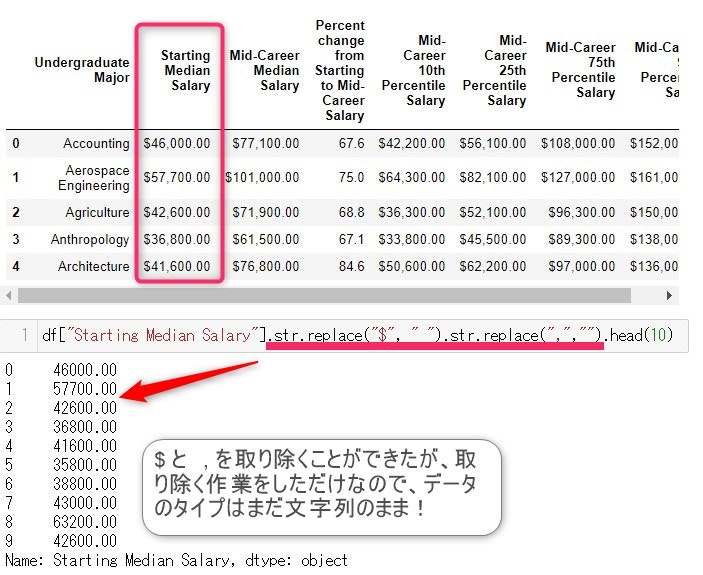
期待通りの結果になりました。
次はデータ型を変更します
.astype()メソッド
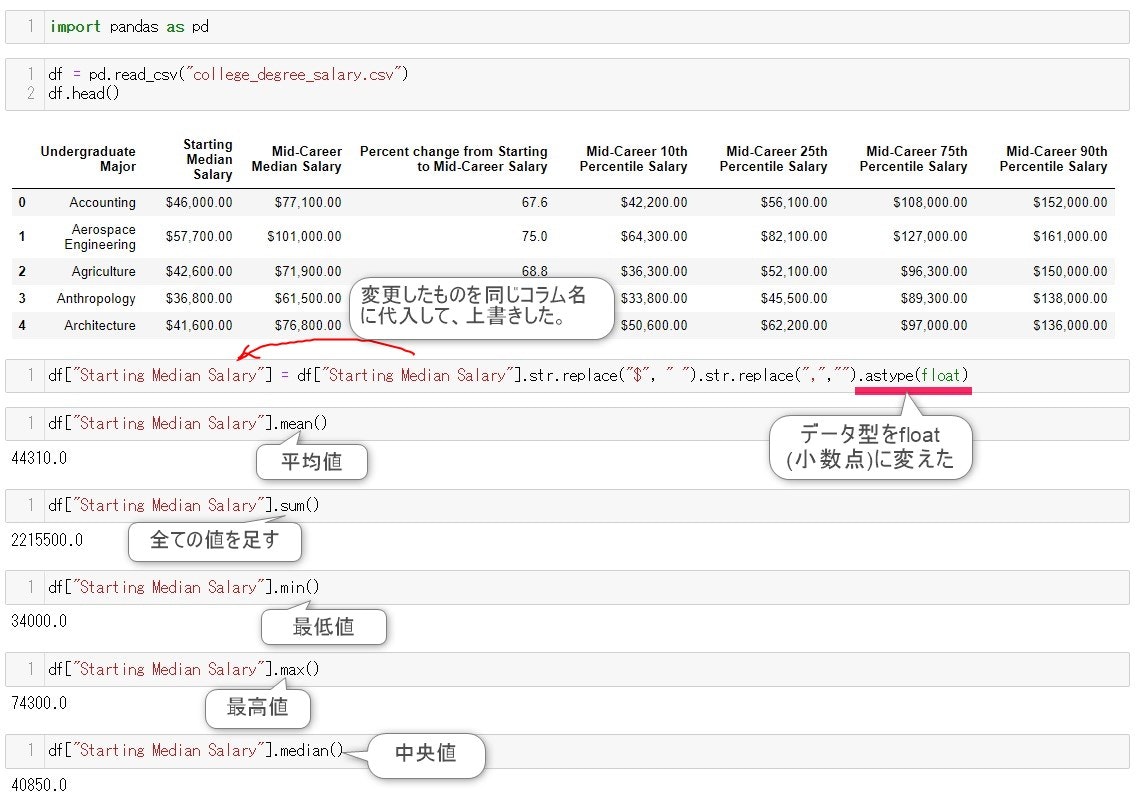
今回、Starting Median Salary(初任給)と名前の付いたコラムのデータを文字列から数列に変更するのに
.astype()メソッド
を使います
.astype()は万能なメソッドで、引数に変更したいデータ型を書くと、そのデータ型に変更する事ができます
今回は、小数点(floating number) に変更したいので
.astype(float)
と先ほど、$ とカンマを取り除いた後のコードに書き足します
(.astype()と.to_numeric()の違いについては、また別の記事で書いていきたいと思います。)
では、文字列だったサラリーのコラムを数列に変更して、いろんなメソッドを使って、サラリーのデータから、
初任給が最高のサラリー額や
全学部の平均サラリー額
などを出してみましょう。
(※計算に便利なメソッドはこちらの記事にまとめていますので、良かったら参考にどうぞ)
まとめ
今回の記事はこれくらいで終わりにします。
お役に立てれば幸いです。