はじめに
この記事では、書籍「実践XAI[説明可能なAI] 機械学習の予測を説明するためのPythonコーディング」を参考にして、SHAPによる機械学習モデルの局所的・大域的説明の方法および簡単な理論を解説します。
「局所的な説明」と「大域的な説明」
機械学習モデルの説明の種類には大きく分けて
- 局所的な説明(Local Surrogate)
- 大域的な説明(Global Surrogate)
の2つがあります。
これらを一言で説明すると、次のようになります(記事[1]から引用)。
大域的な説明では、深層学習モデルやランダムフォレストのような決定木のアンサンブルなどの複雑なモデルを可読性の高いモデル、例えば単一の決定木やルールモデルで近似的に表現することでモデルの説明とする。
局所的な説明では、ある入力xをモデルがyと予測したときに、その予測の根拠を説明として提示する。
つまり、こういうことです。
- モデルの全体的・平均的なふるまいを見たいときには「大域的説明」を見る。
- なぜこの予測値になったのか?を知りたいときには「局所的説明」を見る。
より具体的な例を挙げると、
- 大域的説明:回帰係数、特徴量重要度など
- 局所的説明:SHAP、LIMEなど
ということになります。
※SHAP、LIMEは局所的説明のところに入れましたが、大域的説明を与えることもできます。
SHAP(SHapley Additive exPlanations)
SHAPでは、各特徴量が予測値に対してどれだけ貢献しているかを計算することで、予測を説明します。
Shapley値とは
以下は書籍「実践XAI」p.42~43からの引用です。
シャープレイ値(Shapley value)は協力ゲーム理論(cooperative game theory)で広く用いられているアプローチであり、望ましい特性をいくつか有している。
[中略]
シャープレイ値がモデルの説明をどのように確立するかというと、協力ゲーム理論による結果の偏りのない分布に基づき、モデルの出力($x$)に対する貢献度をその入力特徴量に分配する。ゲーム理論と機械学習モデルを結びつけるには、モデルの入力特徴量をゲームのプレイヤーに一致させることと、モデル関数をゲームのルールに一致させることの両方が必要である。ゲーム理論では、プレイヤーはゲームに参加するかしないかを選択できるが、それと同じように特徴量にもモデルに「参加するかしないか」の選択肢がある。
※「モデルの出力($x$)」とありますが、ふつう$x$は入力を表すのでおそらく誤記でしょう。
上記のとおり、SHAPは協力ゲーム理論にもとづいた説明方法です。
本では協力ゲーム理論についてほとんど触れられていないので、少しだけ説明しておきます(参考[2])。
協力ゲーム理論は、プレイヤー間で協力して得られた利益をどのように各プレイヤーへ分配すれば最も合理的か?を分析する学問です。
シャープレイ値は「特性関数型ゲーム」による定式化によって導かれるそうなので、特性関数型ゲームについて紹介します。
特性関数型ゲーム
$n$人のプレイヤー$1,2,\cdots,n$がいるとします。この$n$人のプレイヤーからなる集合を
$$F \equiv \{1,2,\cdots,n\}$$
と定義します。つまり$F$は全員があつまった集合です。
この全体集合$F$から取ってきた、空でない部分集合$S(\subseteq F)$のことを提携といいます。つまり「全員の中から何人かが集まって、集合$S$として協力する」というイメージですね。$S$の例としては、
\begin{align*}
S_1 &= \{1,5,6\}\\
S_2 &= \{1\}\\
S_3 &= \{1,2,\cdots,n\} (=F)
\end{align*}
などが挙げられます。$S$の取り方は全部で$2^n-1$通りあります。
また、提携$S$のメンバーで協力した時に得られる利益を、$v(S)$という実数値関数で表します。
この関数を特性関数と呼びます。
ここで定義した$F,v$の組$(F,v)$のことを特性関数型ゲームといいます。
特性関数型ゲームを機械学習にあてはめる
上で定義した特性関数型ゲームを、機械学習の場合に当てはめましょう。
全特徴量を$x_1, \cdots, x_n$とすると、この集合が全体集合
$$F=\{x_1, \cdots, x_n\}$$
となります。
これらのうちいくつかの特徴量を使って機械学習モデルを構築することを考えます。
この「いくつかの特徴量」が提携$S$に対応し、この特徴量たち$S$を使って学習したモデルを$f_{S}(x_S)$と書きます。
※例えば$S=\{x_1,x_3\}$なら$x_S$は$(x_1,x_3)$のことを表す。
Shapley値の定義
以下は書籍「XAI」p.43~44からの引用です。
SHAP値とはどのようなもので、どのように計算するのかがわかれば、SHAP値を正しく解釈し、その意味を正しく理解することができる。各特徴量値のシャープレイ値は次の式によって計算される。
$$\phi_i = \sum_{S\subseteq F\backslash \{i\}} \frac{|S|!(|F|-|S|-1)!}{|F|!}[f_{S\cup\{i\}}(x_{S\cup\{i\}}) - f_S(x_S)]$$
※「SHAP値」と「シャープレイ値」は同じものと考えてOKだと思います。表記ゆれがすごいですね…。ちゃんと校正しているんでしょうか。
上の式は、特徴量$x_i$に対するShapley値の定義を与えています。
この式の解釈としては以下のようになります。
- $\displaystyle\sum_{S\subseteq F\backslash \{i\}}$:特徴量のすべての組み合わせを考えるよ。ただし$S$には特徴量$x_i$は不在だよ。
- $f_{S\cup\{i\}}(x_{S\cup\{i\}}) - f_S(x_S)$:特徴量$S$たちだけで学習した場合と、特徴量$x_i$を加えて学習した場合の予測値の差分。
- $\displaystyle\frac{|S|!(|F|-|S|-1)!}{|F|!}$:確率(下記参照)。
\frac{|S|!(|F|-|S|-1)!}{|F|!}=\frac{1}{\frac{|F|!}{|S|!(|F|-|S|-1)!1!}}
に注意する。これを高校数学でよくある例題で表現すると、
$|S|$個の黒玉、$|F|-|S|-1$個の白玉、$1$個の赤玉、の合計$|F|$個の玉の並べ方の総数の逆数といえる。
\overbrace{\overbrace{●●●●}^{\text{提携}S}\text{○○○}\cdots\text{○}\overbrace{🔴}^{\text{特徴量}i}}^{\text{全特徴量}F}
よって特徴量$i$のShapley値は、特徴量$i$が参加した場合の予測値と不参加の場合の予測値の差分の期待値、と解釈できます。
Shapley値は特徴量が予測値にたいしてどれだけプラスの作用をするかマイナスの作用をするかを表す指標、と捉えるといいのではないでしょうか。
※お気づきのように、部分集合$S$の取り方は指数オーダーで増えていってしまうため厳密な値を求めようとすると莫大な計算時間がかかります。実際にはShapley値を近似するアルゴリズムで計算されているようです。
※こちらの方の記事(↓)ではもう少し丁寧にShapley値について解説されています。詳しく知りたい方はぜひご覧ください。
SHAPによる描画
ここからは、SHAPライブラリを使っていろいろな図を描いてみましょう。
サンプルコードはSHAP公式ドキュメント[3]からの引用です。
プロットを行う前には、SHAP値の算出が必要です。サンプルコードは以下です。
【補足】adultデータセットとは
以下の12個の特徴量から、世帯年収が高収入かそうではないかを予測するためのデータセットです。
- Age
- Workclass
- Education-Num
- Marital Status
- Occupation
- Relationship
- Race
- Sex
- Capital Gain
- Capital Loss
- Hours per week
- Country
import xgboost
import shap
# train XGBoost model
X,y = shap.datasets.adult()
model = xgboost.XGBClassifier().fit(X, y)
# compute SHAP values
explainer = shap.Explainer(model, X)
shap_values = explainer(X)
ただしデータ数が多い場合、計算に時間がかかることがあります。
そのようなときは、書籍に記載があるように「バックグラウンドサンプル」なるものを作成してからExplainerに投げます。
max_samplesを小さくするほど計算時間は短縮されますが、SHAP値の計算精度は当然落ちます。
import xgboost
import shap
# train XGBoost model
X,y = shap.datasets.adult()
model = xgboost.XGBClassifier().fit(X, y)
# compute SHAP values
background = shap.maskers.Independent(X, max_samples=10)
explainer = shap.Explainer(model, background)
shap_values = explainer(X)
waterfallプロット
局所的な説明を見るためのプロットです。
例えば、index=0の局所的な説明を見たい場合は次のようなコードを書きます。
shap.plots.waterfall(shap_values[0], max_display=30)
# max_display: shap値上位何個までを表示するか
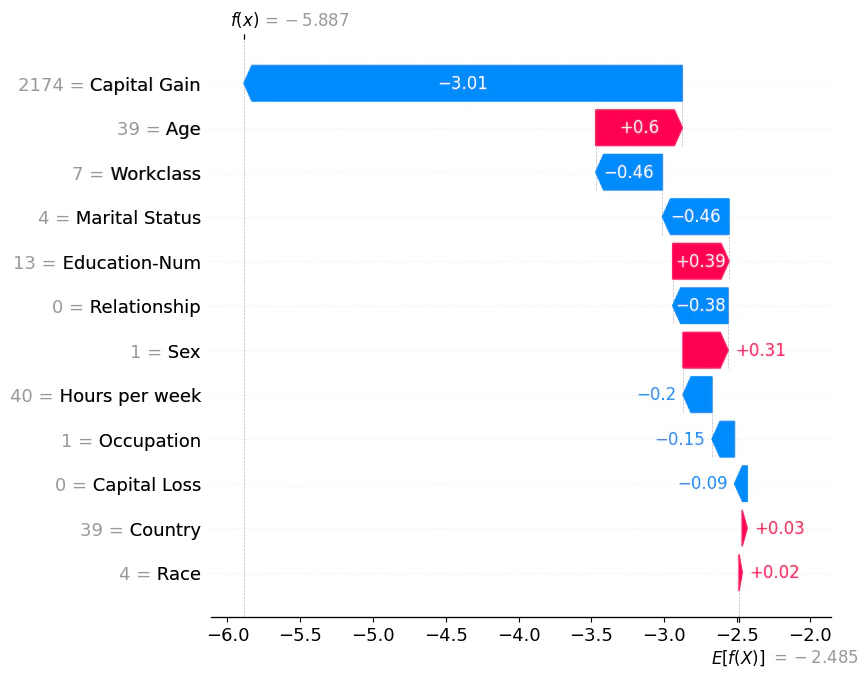
waterfallプロットでは、出力平均値$E[f(X)]$からスタートして、各特徴量がどのように影響しながら最終的な予測値$f(X)$に至るかを表しています。
出力平均値は、一番下に書いてある
$$E[f(X)]=-2.485$$
です。分類モデルでは対数オッズが表示されるようです。
指定したインスタンス(ここではindex=0のデータ)に対する予測値は、一番上に書いてある
$$f(X)=-5.887$$
です。こちらも、分類モデルでは対数オッズです。
上図では、Capital Gainという特徴量が大きな影響をもたらしていると読み取れます。
さらに「-3.01」となっていることから「負」の影響をもたらしていることも分かります。
forceプロット
局所的な説明を見るためのプロット。
正の影響を持つ特徴量と負の影響を持つ特徴量を分けて数直線上にプロットしてくれます。
shap.initjs()
shap.force_plot(shap_values[0])

「base value」と書いてあるのがモデル出力の平均値(対数オッズ)です。
確率値表示にしたい場合はlink='logit'と引数で指定しましょう。
太字で -5.89 と書いてあるのがモデルの出力値です。
棒の長さはもちろん、SHAP値の大きさを表しています。
例えばCapital Gainの部分の長さは、waterfallプロットでも見たように「3.01」ぶんの長さがあります。
※書籍p.131では
横軸の上にグレーで表示されている数値は、すべてのサンプルの予測値である。
とか書いてありますが、これは……。嘘ですよね?単に2.0間隔で数字を振っているだけですね。
ちなみに、shap.force_plotに複数インスタンスのSHAP値を渡すと…
shap.initjs()
shap.force_plot(shap_values[:100]) # index=0~99のSHAP値
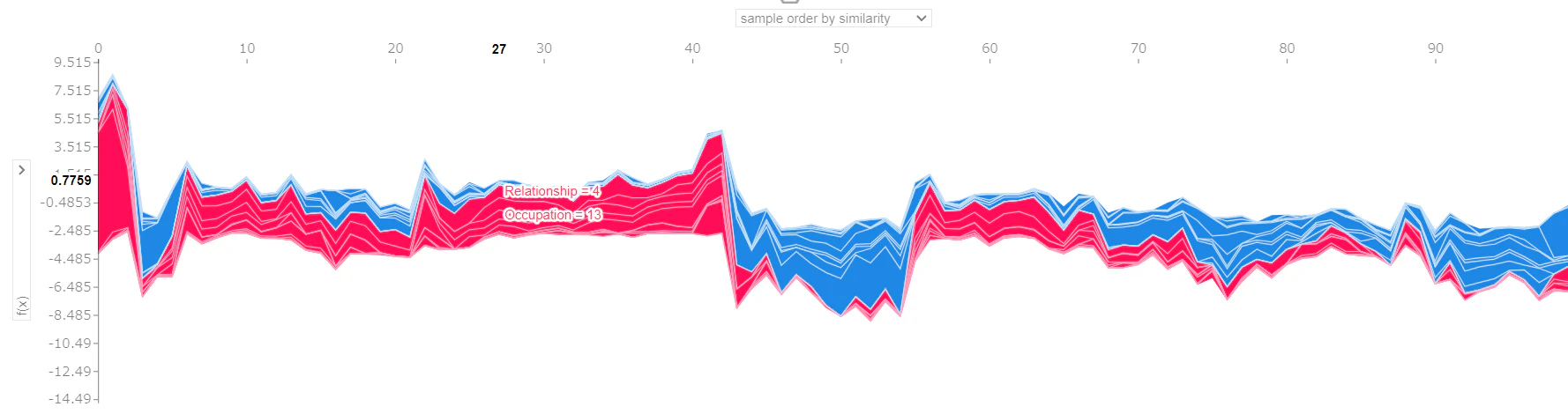
先ほどは1つのインスタンスについてしか見れなかったプロットが、複数を一気に俯瞰できるようになりました。
ここでの縦軸は、先ほどの横軸に対応していて、
ここでの横軸は、インスタンスを表します。
カーソルを合わせると、各インスタンスの情報がポップアップされるようになっています。
beeswarmプロット
大域的な説明を見るためのプロットです。
shap.plots.beeswarm(shap_values)

各点が青色~赤色で着色されていますが、これは各インスタンスの値自体の大きさを表します。
青ければ値は小さく、赤ければ値は大きいです(右端にカラーバーがあります)。
横軸はSHAP値の大きさを表します。
例えばAgeの部分を見ると、赤い点が右側へ、青い点が左側へ寄っています。
このことから、年齢が高い(低い)ほど年収が高い(低い)傾向にあることがわかりますね。
barプロット
大域的な説明を見るためのプロットです。
shap.plots.bar(shap_values)
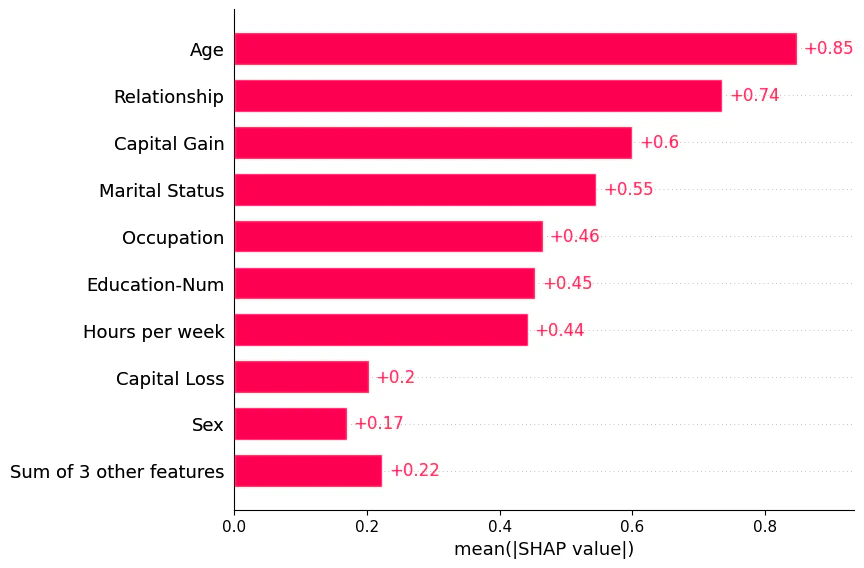
横軸は、SHAP値の絶対値平均を表します。
よくある特徴量重要度と同じようなもの、と考えてよいでしょう。
heatmapプロット
SHAP値がデカいインスタンスがどう分布しているかを確認したり、大域的説明(bar)を確認したりすることができます。
shap.plots.heatmap(shap_values)
※データ量によってはメモリかなり消費するので注意してください。
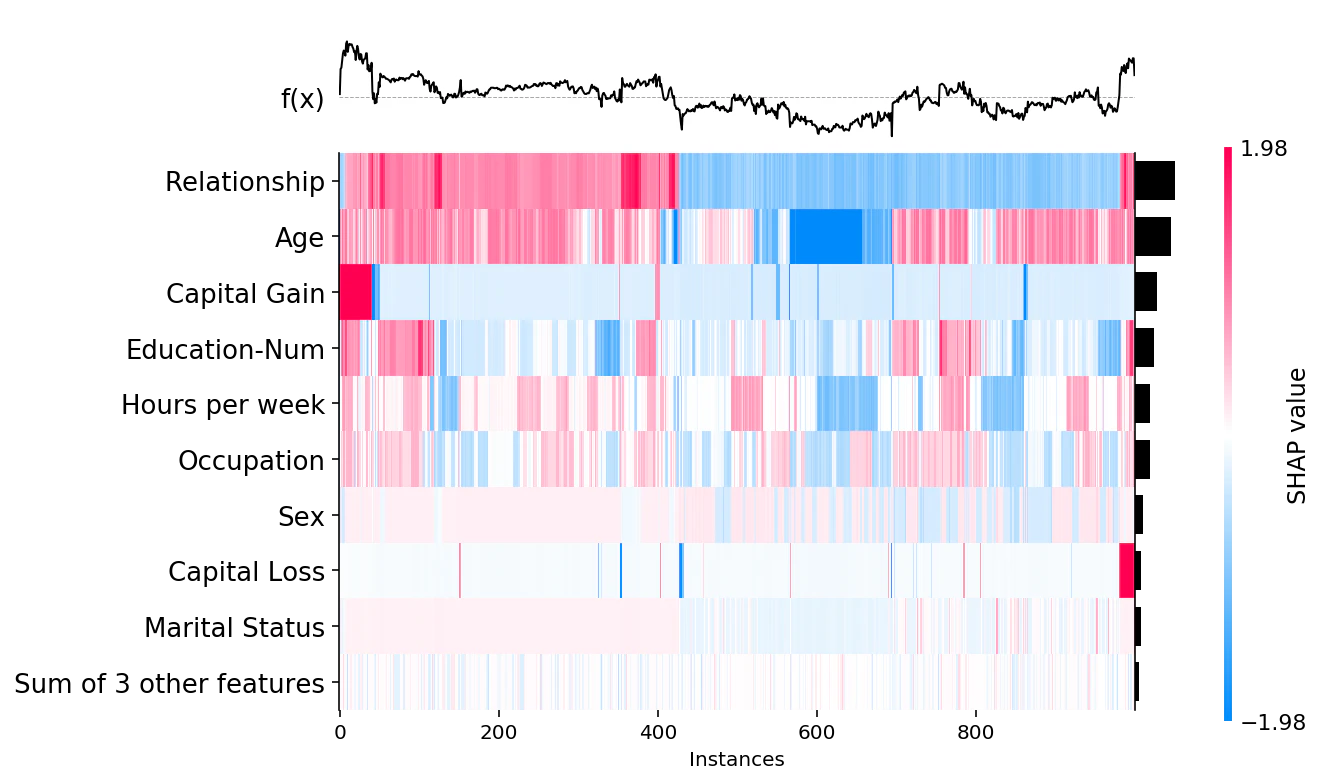
heatmapの青~赤はSHAP値の大小を表します。
上部の折れ線グラフは各インスタンスに対する、モデルの出力値を表します。
右にある棒グラフは、(barプロットで説明した)SHAP値の絶対値平均を表します。
付録
ここでは、書籍「実践XAI」における説明やコードの不備、および私からのツッコミを付録として載せておきます。43ページまでのツッコミは前回記事で紹介しています。
実はこれら以外にもツッコミどころ(文章構成がおかしい、図が意味をなしていない、など)があるのですが、挙げていくとキリがないほど多いので割愛しています。
A:【誤植】赤色の縦線は何を表すか
以下は書籍p.45からの引用です。
特徴量$i$のSHAP値は、単に、モデルの目的変数の値(正解値) と、特徴量の値$x_i$でのPDPとの差分である。このことは、シャープレイ値の加法的な性質を示している。
[中略]
機械学習モデルでは、すべての入力特徴量のSHAP値は常に、モデルの出力のベースライン(正解値) と、予測値を説明しようとしている現在のモデルの出力の差分を足したものになる。
[中略]
なお、図3-8において、使用年数10年のAge特徴量上に示されている斜線と正解値の横点線との差分(赤の縦線の高さ)が、その特徴量のSHAP値である。
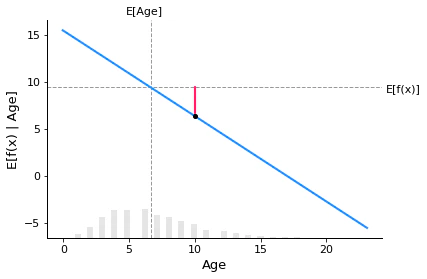
まず太線で示した箇所は、誤りだと考えられます。「正解値」な訳がないです。
もしここに書いてあることが本当だとしたら、SHAP値とPDPがわかれば真の値(ground truth)が分かるということになってしまいますよね。
正しくは、モデル出力値の平均($E[f(X)]$)だと思います。図から見ても明らかです。
※あと、書籍の図3-8には「←実際は赤の縦線」ってありますけど、「実際は」ってどういう意味で言っているんでしょうか…。
B:タイトル詐欺
- 該当箇所:5.3 アンサンブルモデルでSHAPを使う(p.111~116)
この5.3節は「アンサンブルモデルでSHAPを使う」と書いてあるのですが、この節ではアンサンブルモデルは1つも使っていませんでした。
実際に使っているのは線形回帰モデルです。
なので第3章を(違うデータセットを使って)もう1度やっているという内容になっております…。
さらに(!)、この節には誤植もあります。該当箇所はp.113で
図5-5の水平な点線(E[f(x)])は予測された住宅価格平均の中央値である。
正しくは住宅価格の中央値の平均値です。
※ここでの目的変数は「住宅価格の中央値」であり、それの平均値なので「住宅価格の中央値の平均値」という表現が適切です。
C:それって、スタッキング?
- 該当箇所:p.110
書籍ではアンサンブルの手法として
- バギング
- ブ―スティング
- スタッキング
が紹介されています。
バギング、ブ―スティングの説明はまあいいのですが、スタッキングの説明でちょっと「?」となりました。
スタッキングとして紹介されていたのは、いわゆる
- Averaging法(平均法)
- Vote法(投票法、多数決法)
でした。
こちらの記事にもあるとおり、スタッキングとAveraging/Vote法は区別されています。
単に平均する・多数決をとることをスタッキングと呼ぶのはちょっと無理があるのではないかと思いました。
次回
次は、LIMEについて解説します。
参考記事
[1] 人工知能学会「【記事更新】私のブックマーク『機械学習における解釈性(Interpretability in Machine Learning)』」
https://www.ai-gakkai.or.jp/resource/my-bookmark/my-bookmark_vol33-no3/
[2] 岸本信「協力ゲーム理論入門」オペレーションズ・リサーチ
https://orsj.org/wp-content/corsj/or60-6/or60_6_343.pdf
[3] SHAP公式ドキュメント
https://shap-lrjball.readthedocs.io/en/latest/example_notebooks/plots/decision_plot.html