はじめに
こんにちは。まっちゃ![]() です。
です。
今回は、主に画像生成で用いられている拡散モデルについてまとめていきます。実装部分については、Kerasの公式ページに記載されているコードを抜粋して解説を行っていきます。
なぜ重要か
拡散モデルは、元画像にノイズを付与していく順方向の拡散プロセスを基に、ノイズから画像を生成する逆方向の拡散プロセスを構築しています。
また、訓練されるネットワークは付与するノイズと時間情報を入力として、任意の時刻におけるノイズ画像に付与されたノイズを予測します。
目次
- 拡散モデルの概要
- 拡散モデルの構成要素
- 順方向の拡散過程
- 再パラメータ化トリック
- 逆方向の拡散過程
- 拡散スケジューリング
- 正弦波埋め込み
- サンプリング(画像の生成)
- DDIMの実装
- 拡散スケジューリング
- 正弦波埋め込み
- 残差接続
- ダウンサンプリング
- アップサンプリング
- 逆拡散過程(サンプリング)
- まとめ
- 参考
拡散モデルの概要
以下の図に、拡散モデルの概要を示します。拡散モデルは、推論したノイズをランダムノイズ$x_T$から少しずつ取り除いていくことで、元の画像$x_0$を生成するモデルです。拡散モデルは、左向きに表される順方向の拡散過程と右向きに表される逆方向の拡散過程から成ります。

拡散モデルの構成要素
ここから拡散モデルの構成要素の説明をしていきます。
順方向の拡散過程
元の画像$x_0$にノイズを付与していく過程です("拡散モデルの概要"で示した図の左方向の過程)。ノイズを付与していく際、$t$秒後の画像$x_t$は$t-1$秒後の画像$x_{t-1}$を用いて、以下の式で表されます。ここで、$\varepsilon_{t-1}$は付与するノイズを表します。このとき、分散$\beta_t$のガウスノイズを付与していく過程をとることで、$T$秒後に純粋なガウスノイズ$x_T$を取得することが出来ます。
$$x_t = \sqrt{1-\beta_t}x_{t-1} + \sqrt{\beta_t}\varepsilon_{t-1}$$
再パラメータ化トリック
再パラメータ化トリックを適用することで、順方向の拡散過程を$t$回繰り返すことなく、元の画像$x_0$から任意の時刻$t$に置ける画像$x_t$を表すことができます。$x_t$は再パラメータ化トリックを適用することで、以下の式で表されます。ここで、$\alpha_t$と$\bar{\alpha_t}$はそれぞれ、$\alpha_t=1-\beta_t$, $\bar{\alpha_t}=\Pi_{i=1}^t\alpha_i$となります。
$$x_t = \sqrt{\bar{\alpha_t}}x_0 + \sqrt{1-\bar{\alpha_t}}\varepsilon$$
逆方向の拡散過程
ノイズを取り除いていき、元の画像$x_0$を生成する過程です("拡散モデルの概要"で示した図の右方向の過程)。この時、ノイズ画像$x_t$とノイズの割合$\bar{\alpha_t}$を入力とし、時間$t$において$x_0$に付与されたノイズ$\varepsilon$を予測するようにネットワークを訓練します。
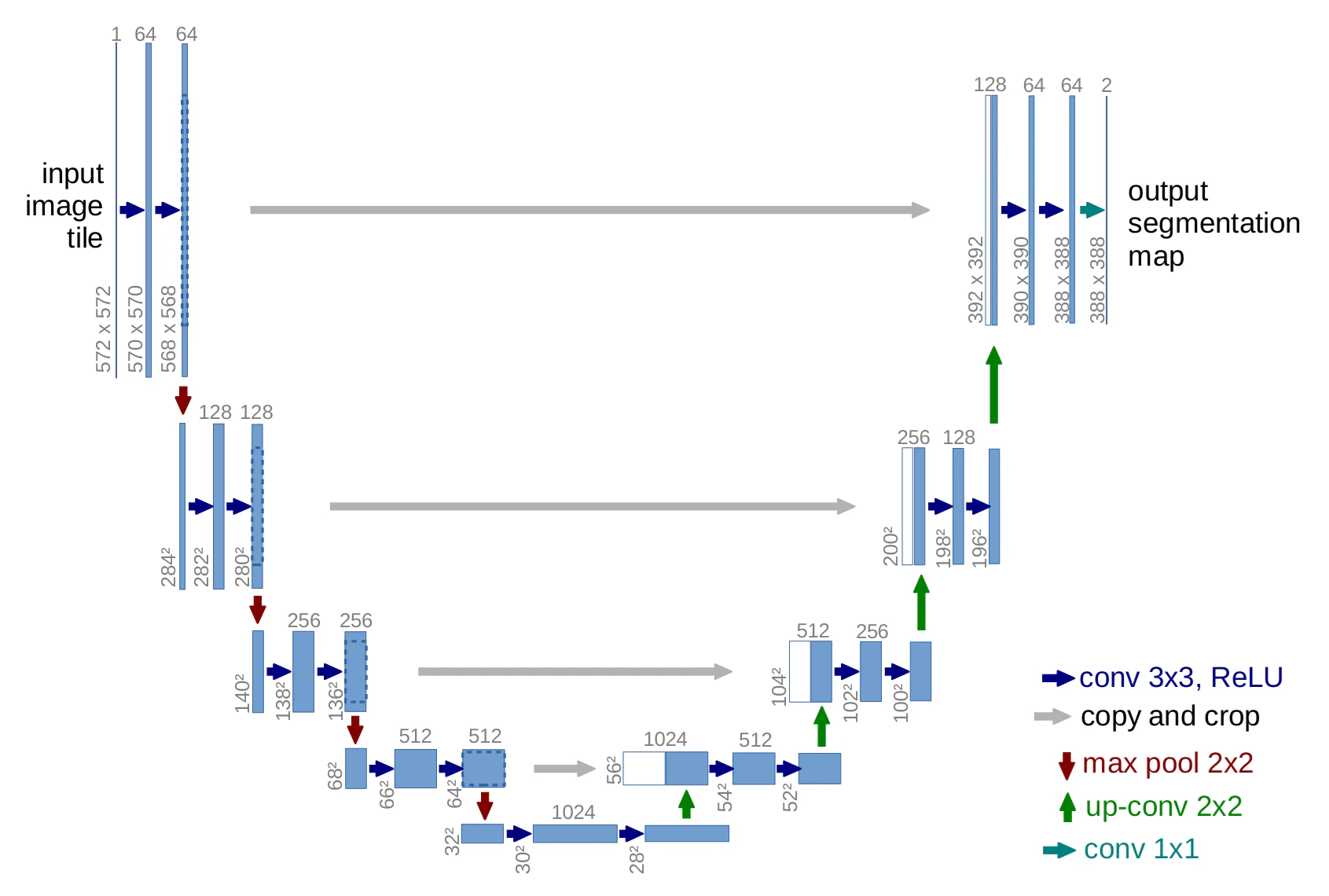
予測されるノイズのサイズは元画像と同じであるため、ネットワークとしてU-Netが主に用いられています。
- U-Net
ダウンサンプリング部とアップサンプリング部で構成され、入力と同じ形状の出力を得たい場合に用いられるモデルです。ダウンサンプリング部では、CNNと同様に層が深くなるにつれて、特徴マップを小さくしてチャネル数を増加させます。一方、アップサンプリング部では、特徴マップを大きくしてチャネル数を減少させます。
また、U-Netでは、ダウンサンプリング部とアップサンプリング部において、特徴マップのサイズが同一の箇所にスキップ接続を持たせています。スキップ接続を持たせることで後ろに情報を流すことができ、深いネットワーク構造の学習時に問題となる勾配消失を削減しています。
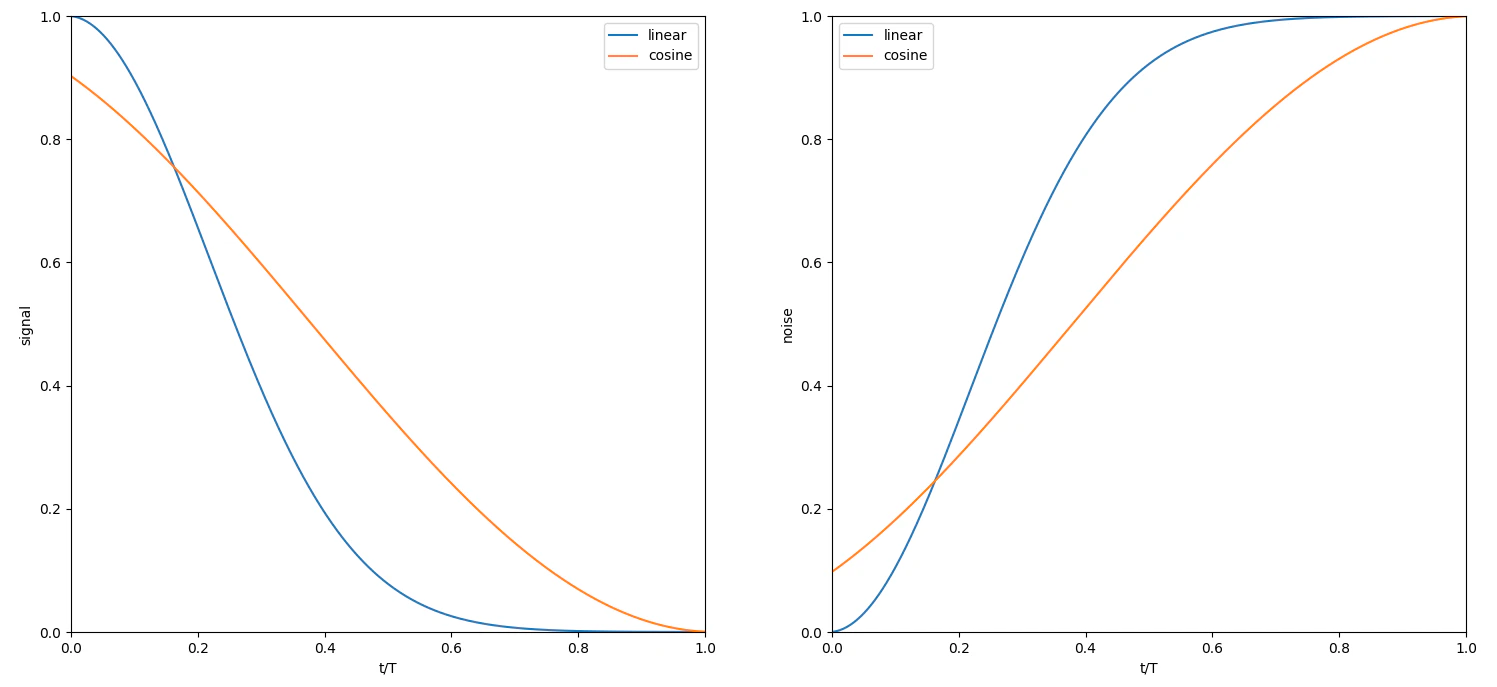
拡散スケジューリング
ノイズを付与する割合を時間で変化させています。拡散スケジューリングによりノイズを徐々に付与していくことで、学習の効率と画像生成の質を向上させています。原論発表後の研究で様々なスケジューリング手法が提案されています。本記事ではコサイン拡散スケジューリングを扱っていきます。以下の図に、線形およびコサイン拡散スケジューリングそれぞれにおける元画像の割合(左図)とノイズの割合(右図)の変化を示します。横軸は時刻を、縦軸はそれぞれ元画像とノイズを表します。オレンジ色で示されるコサイン拡散スケジューリングは、青色で示される線形拡散スケジューリングと比較して緩やかに、元画像の割合が減少し、ノイズの割合が増加していることが分かります。
正弦波埋め込み
時間によって変化するノイズの量を表すため、ノイズを付与していく際の時間情報を埋め込んでいます。この埋め込み方法により入力データを連続的かつ周期的な特徴を持つ表現に変換することで、モデルが時間情報を学習できるようになります。この埋め込み方法は、Transformerモデル(例:GPTやBERT)で位置情報を符号化する際にも使われています。
サンプリング(画像の生成)
ランダムノイズから元の画像を出力します。以下の図に、サンプリングのプロセスを示します。サンプリングは以下のプロセスから成り、順方向の拡散過程と同様に複数のステップを経ることで、高品質な画像を生成しています。
- 入力したランダムノイズ$x_t$から付与されたノイズ$\varepsilon_t$を予測し、元の画像$x_0$を生成
- $\varepsilon_t$を$t-1$回適用して$t-1$秒後のノイズ画像$x_{t-1}$を生成
- 1.と2.を繰り返し、徐々にノイズを除去した元画像$x_0$を生成

以下の式は、上記のプロセスを表したものです。ここで、右辺第一項のカッコ内は元画像$x_0$となり、$\varepsilon_\theta^{(t)}(x_t)$はモデルが推定した$t$秒後のノイズとなります。また、$\sigma_t$は、生成プロセスにおけるランダムさを表す係数です。
$$x_{t-1} = \sqrt{\bar\alpha_{t-1}}\Bigl(\frac{x_t-\sqrt{1-\bar\alpha_t}\varepsilon_\theta^{(t)}(x_t)}{\sqrt{\bar\alpha_t}}\Bigr)+\sqrt{1-\bar\alpha_{t-1}-\sigma_t^2}・\varepsilon_\theta^{(t)}(x_t)+ \sigma_t\varepsilon_t$$
以上が拡散モデルの概要になります。
DDIMの実装
前項の"サンプリング(画像の生成)"で示した式において、$\sigma_t = 0$の場合はランダムさが無くなります。結果として、逆拡散過程プロセスが決定的になるため、同じランダムノイズを入力することで常に同じ画像が生成されます。これは、ノイズ除去拡散暗黙モデル(DDIM: denoising diffusion implicit model)というモデルに該当します。
以下でDDIMの構成要素に関して、kerasを用いた実装を解説します。下記のコードは、Kerasのサンプルコードから抜粋しています。モデルの全容把握は、上記のページを参照してください。
拡散スケジューリング
ノイズを付与する割合を時間で変化させています。コサイン関数を導入することで、拡散過程の初期段階では元のデータを比較的多く保持し、時間経過により徐々にノイズを増やします。
- diffusion_times
拡散過程の進行度合いを表し、0から1までの範囲を指定します。 - noise_rates
拡散過程において、ノイズをどの程度付与するかを計算します。 - signal_rates
拡散過程において、ノイズ付与前の画像をどの程度保持するかを計算します。
def diffusion_schedule(diffusion_times):
min_signal_rate = 0.02
max_signal_rate = 0.95
start_angle = ops.cast(ops.arccos(max_signal_rate), "float32")
end_angle = ops.cast(ops.arccos(min_signal_rate), "float32")
diffusion_angles = start_angle + diffusion_times * (end_angle - start_angle)
noise_rates = ops.sin(diffusion_angles)
signal_rates = ops.cos(diffusion_angles)
return noise_rates, signal_rates
正弦波埋め込み
モデルに埋め込む時間ステップ情報を作成します。
- embedding_*_frequency
埋め込み周波数のスケールを指定します。 - frequencies
対数スケールで均等な周波数の配列を作成します。 - embeddings
周波数から算出した角速度を用いて正弦波と余弦波を計算し、埋め込みを作成します。
def sinusoidal_embedding(x):
embedding_min_frequency = 1.0
embedding_max_frequency = 1000.0
frequencies = ops.exp(
ops.linspace(
ops.log(embedding_min_frequency),
ops.log(embedding_max_frequency),
embedding_dims // 2,
)
)
angular_speeds = ops.cast(2.0 * math.pi * frequencies, "float32")
embeddings = ops.concatenate(
[ops.sin(angular_speeds * x), ops.cos(angular_speeds * x)], axis=3
)
return embeddings
残差接続
残差接続は深層学習の学習における勾配消失問題を軽減し、より深いネットワークの学習を安定させるために用いられています。
- width
出力する特徴マップのチャネルを指定します。 - residual
入力チャネル数と出力チャネル数を比較して、同じ場合はそのまま残差として使用し、異なる場合は畳み込み層を用いて調整します。 - activation="swish"
バッチ正規化層後の畳み込み層における活性化関数のSwish関数は、以下の特徴を持ちます。- x=0で微分可能
- 負の入力に対して微小な値を出力
- layers.Add()
取得した残差との接続を行い、情報を保持します。
def ResidualBlock(width):
def apply(x):
input_width = x.shape[3]
if input_width == width:
residual = x
else:
residual = layers.Conv2D(width, kernel_size=1)(x)
x = layers.BatchNormalization(center=False, scale=False)(x)
x = layers.Conv2D(width, kernel_size=3, padding="same", activation="swish")(x)
x = layers.Conv2D(width, kernel_size=3, padding="same")(x)
x = layers.Add()([x, residual])
return x
return apply
ダウンサンプリング
ネットワークが入力画像の全体的な構造やより抽象的な特徴を捉えるために、特徴マップのサイズを下げながら特徴を抽出していきます。また、後でデコーダー側で使用するためのスキップコネクションを保存します。
- block_depth
ダウンサンプリングの層の数を指定します。 - skips
出力を追加していき、スキップコネクションを準備します。 - layers.AveragePooling2D(pool_size=2)
出力された特徴マップのサイズを半分にして、特徴を抽出します。
def DownBlock(width, block_depth):
def apply(x):
x, skips = x
for _ in range(block_depth):
x = ResidualBlock(width)(x)
skips.append(x)
x = layers.AveragePooling2D(pool_size=2)(x)
return x
return apply
アップサンプリング
ダウンサンプリングにより取得した特徴マップを元のサイズに戻していきます。その過程で、エンコーダー側から渡されたスキップコネクションを利用して、より詳細な情報を復元します。
- block_depth
アップサンプリングの層の数を指定します。 - layers.UpSampling2D(size=2, interpolation="bilinear")
入力された特徴マップのサイズを拡大します。 - layers.Concatenate()
skipsに保存されていたスキップコネクションを一つずつ取り出し、チャネル方向に結合します。
def UpBlock(width, block_depth):
def apply(x):
x, skips = x
x = layers.UpSampling2D(size=2, interpolation="bilinear")(x)
for _ in range(block_depth):
x = layers.Concatenate()([x, skips.pop()])
x = ResidualBlock(width)(x)
return x
return apply
逆拡散過程(サンプリング)
初期ノイズと生成ステップ数を入力とし、初期ノイズからノイズを徐々に除去することで画像を生成します。
- initial_noise
入力する初期ノイズを指定します。 - diffusion_steps
画像生成に要するステップ数を指定します。ステップ数が多い程、高品質の画像が生成されやすい傾向にありますが、計算コストが増加します。 - num_images
初期ノイズのバッチサイズを取得し、生成する画像枚数を取得します。 - denoise(noisy_images, noise_rates, signal_rates, training=False)
学習したモデルにノイズ画像と時間情報を入力して、付与されたノイズと元画像を推論します。 - next_noisy_images
次の拡散時間におけるノイズ画像を準備します。時系列で示すと、現在の時刻からステップ時間前の時間になります。
def reverse_diffusion(self, initial_noise, diffusion_steps):
num_images = initial_noise.shape[0]
step_size = 1.0 / diffusion_steps
next_noisy_images = initial_noise
for step in range(diffusion_steps):
noisy_images = next_noisy_images
diffusion_times = ops.ones((num_images, 1, 1, 1)) - step * step_size
noise_rates, signal_rates = self.diffusion_schedule(diffusion_times)
pred_noises, pred_images = self.denoise(
noisy_images, noise_rates, signal_rates, training=False
)
next_diffusion_times = diffusion_times - step_size
next_noise_rates, next_signal_rates = self.diffusion_schedule(
next_diffusion_times
)
next_noisy_images = (
next_signal_rates * pred_images + next_noise_rates * pred_noises
)
return pred_images
まとめ
ここまで閲覧いただき、ありがとうございます。今回は拡散モデルについてまとめてきました。ノイズから画像を出力する際に元の画像にノイズを付与していく過程をもとにして、逆プロセスを構築する方法はコードを読みながら大変勉強になりました。サンプルコードの中身を理解しながら写経していくことで、プロセスの中身を深く知ることができました。コードを追う中で「なるほど」となる箇所を多々あったので、他のモデルの実装コードを読んで、理解を深めていきたいです。
参考