企業内で、AI開発を目指す方に役立つ情報を発信する為に、自らが気付いたテクニカルなポイントに対して、備忘ログとして残すとともに、活用いただく為に公開します。
1.本投稿の概要
企業内のマスターデータの保管先であるリレーショナルデーターベースを有効活用し、AI開発を活性化させる。
2.従来のAI開発イメージ
・課題に応じて、マスターデータの保管先であるリレーショナルデータベースからデータ抽出し、CSVファイル化
・作成したCSVファイルを、AI開発用環境上へ配置
・Pythonのノウハウを使ってAI開発
3.従来の課題
・企業内で複数人がAI開発を行う場合、効率を考えDockerを利用するが、データ管理が複雑
・データ抽出や、CSVファイルの配置などが手間
・Pythonの勉強をして、データの前処理をプログラミングする必要
4.従来課題の解決策
リレーショナルデータベース上のデータを、Python上のプログラムから直接IOし、課題を解決
・DockerコンテナのPythonプログラムから直接IOでき簡単
・ネットワーク経由でIOする事で、Dockerコンテナーに関する複雑性を排除
・従来のSQL文の知識を使って、レコード抽出、項目選択、欠損データ保管処理等が実施可能
5.前提条件
・リレーショナルデータベースとしては、OSSであり、私の周りでAI開発における利用実績が多い、Postgresqlを
使い紹介
・各ソフトウエアのバージョンは、普段利用しているAIソフトウエアGRID社の"ReNom"を参考に決定
・ドライバーに関しては、Webを検索した際の利用動向から独断で決定
6.環境
・kaggleのタイタニック号の生存者に関する情報をサンプルとして利用します。
下のデータ入手先のdataタグから”train.csv”をダウンロード
データ入手先
・コンテナ環境外のネットワーク経由でIO可能なPostgresqlサーバーへ"titanic_train"
という名前でテーブルを作成
・ダウンロードしたデータを事前にインポートしておく
・コンテナ上のOS:ubunts 16.04 LTS
・Python:3.6
・pandas:0.20.3
・psycopg2:2.7.3.2
(Pythonの)Postgresql用ドライバー
インストール方法
7.サンプル・ソース
#!/usr/bin/env python
# encoding:utf-8
# Postgresql 用のライブラリー"psycopg2"を用意
import psycopg2
# Pandasのリレーショナルデータベース用ライブラリを用意
import pandas.io.sql as psql
# Postgresqlサーバーへネットワークを経由して接続
# コンテナ利用時にソースデータのフォルダーを意識する必要がない)
con = psycopg2.connect("host=IPアドレス port=ポート番号 dbname=DB名 user=ユーザーID password=パスワード")
con.get_backend_pid()
cur = con.cursor()
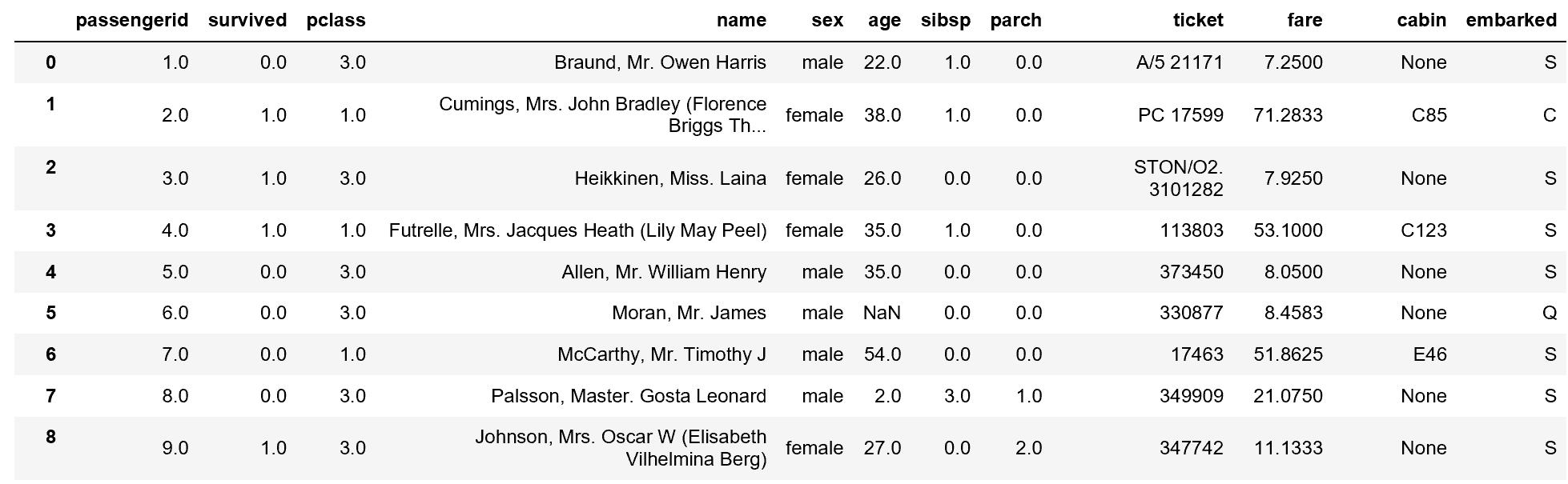
# 無処理の状態で、Pandasのデータフレームに読み込む。
sql = """select * from titanic_train;"""
df_train_org = psql.read_sql(sql, con)
# 内容表示
df_train_org
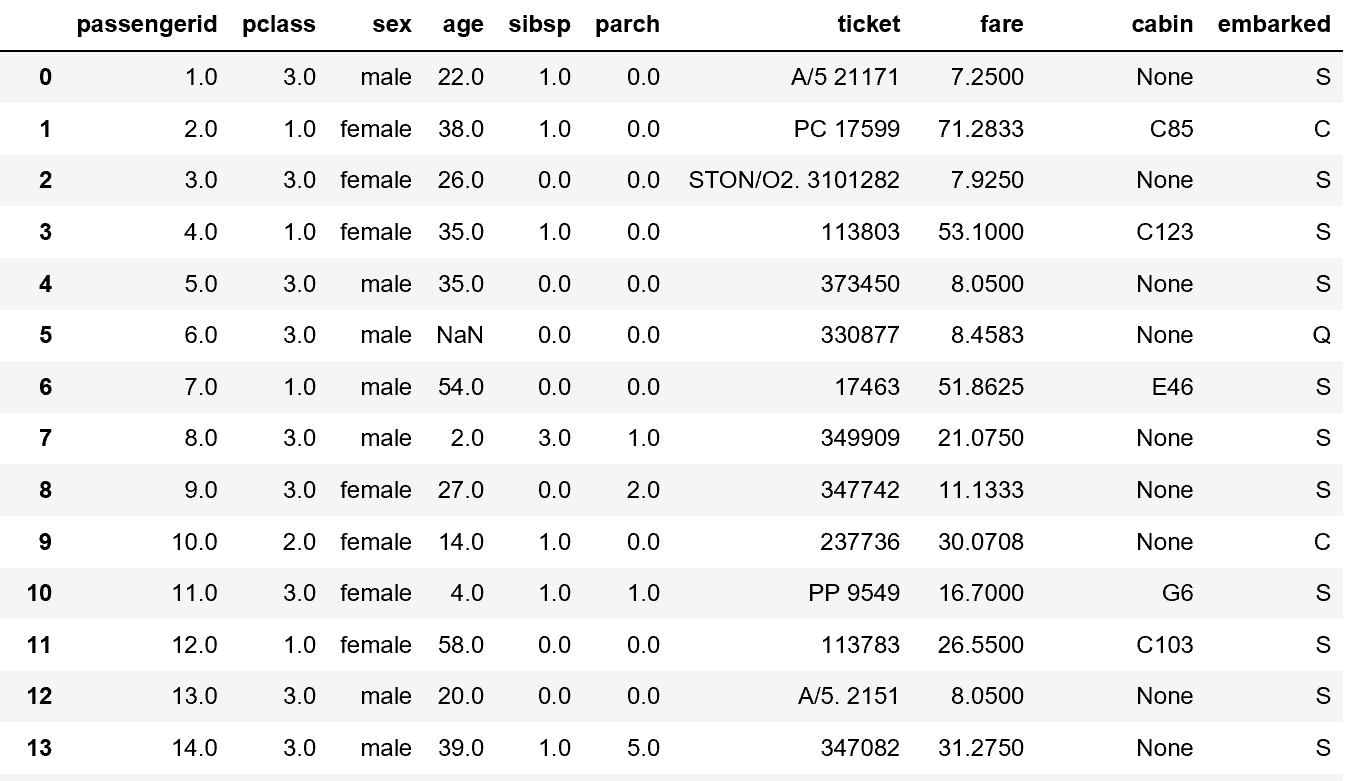
# 分析に必要な項目のみSQL文を修正して、読み込む
sql = """select passengerid, pclass, sex, age, sibsp, parch, ticket, fare, cabin, embarked from titanic_train;"""
df_train_01 = psql.read_sql(sql, con)
# 内容表示
df_train_01
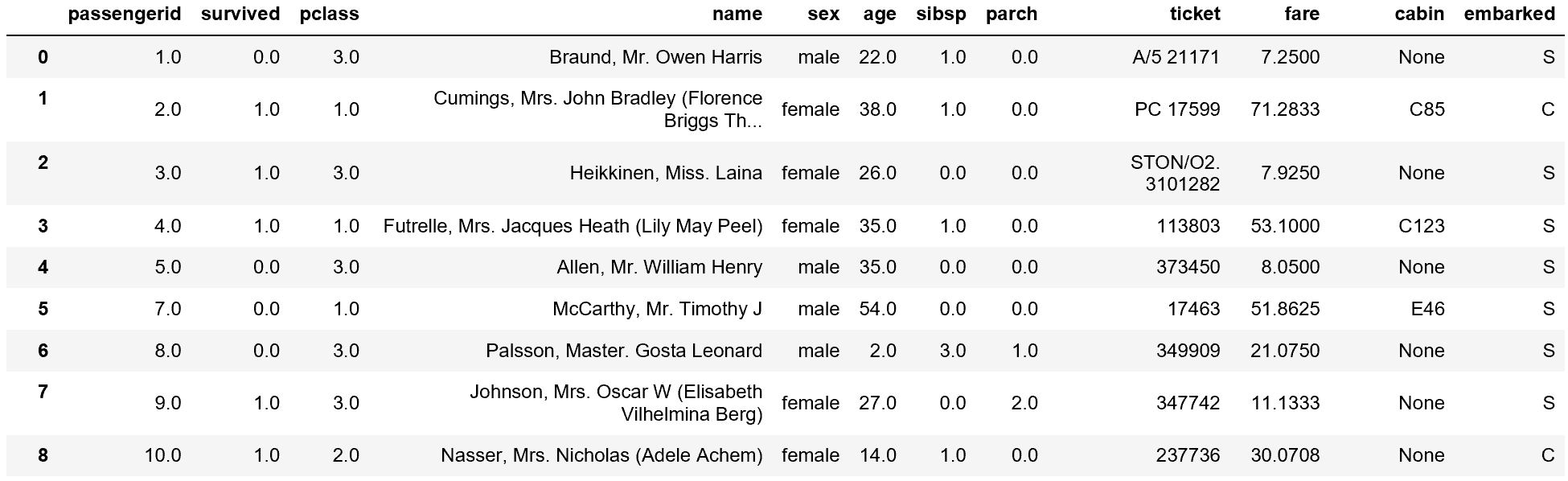
# 重要な項目等に欠落があり、レコードを読み飛ばす場合、SQL文を修正して、読み飛ばす
sql = """select * from titanic_train where age <> 'NaN';"""
df_train_02 = psql.read_sql(sql, con)
df_train_02
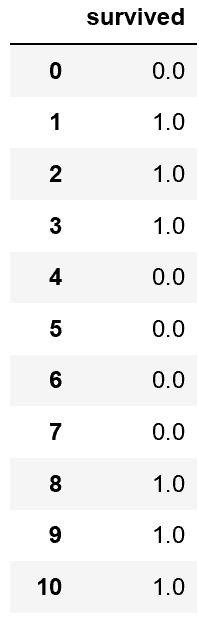
# 教師データ等を単独に、別のデータフレームへ読込事は簡単
sql = """select survived from titanic_train order by passengerid;"""
df_train_03_y = psql.read_sql(sql, con)
df_train_03_y
作者:
AIエバンジェリスト 前田 正重
(伊藤忠テクノソリューションズ株式会社 エキスパートエンジニア)