はじめに
こちらは Zscaler Advent Calendar 2024 の14日目の記事になります。
ZDX を利用したことがない方や、ZDX Standard Edition で Microsoft365 を監視したいユーザー向けに設定例をご紹介します。
以下の免責事項をご理解の上、記事を読んで頂けると幸いです。
免責事項
本記事のコンテンツや情報において、可能な限り正確な情報を掲載するよう努めておりますが、 誤情報が入り込んだり、情報が古くなったりすることもあり、必ずしもその内容の正確性および完全性を保証するものではございません。そのため、本記事をエビデンスとしたゼットスケーラーへの問い合わせなどはご対応致しかねることをご理解頂けると幸いです。掲載内容はあくまで個人の意見であり、ゼットスケーラーの立場、戦略、意見を代表するものではありません。当該情報に基づいて被ったいかなる損害について、一切責任を負うものではございませんのであらかじめご了承ください。
ZDX でMicrosoft 365 アプリの監視を設定する
本手順では、Microsoft 365アプリの監視設定例として Teams Web アプリ を設定します。
ZDX Standard エディションを使用して、Teams の一般的なパフォーマンスを監視することができます。
この設定は簡単な3つのステップで行われ、設定を完了するとZDX管理ポータル上でアプリケーションとプローブに監視内容が表示されます。
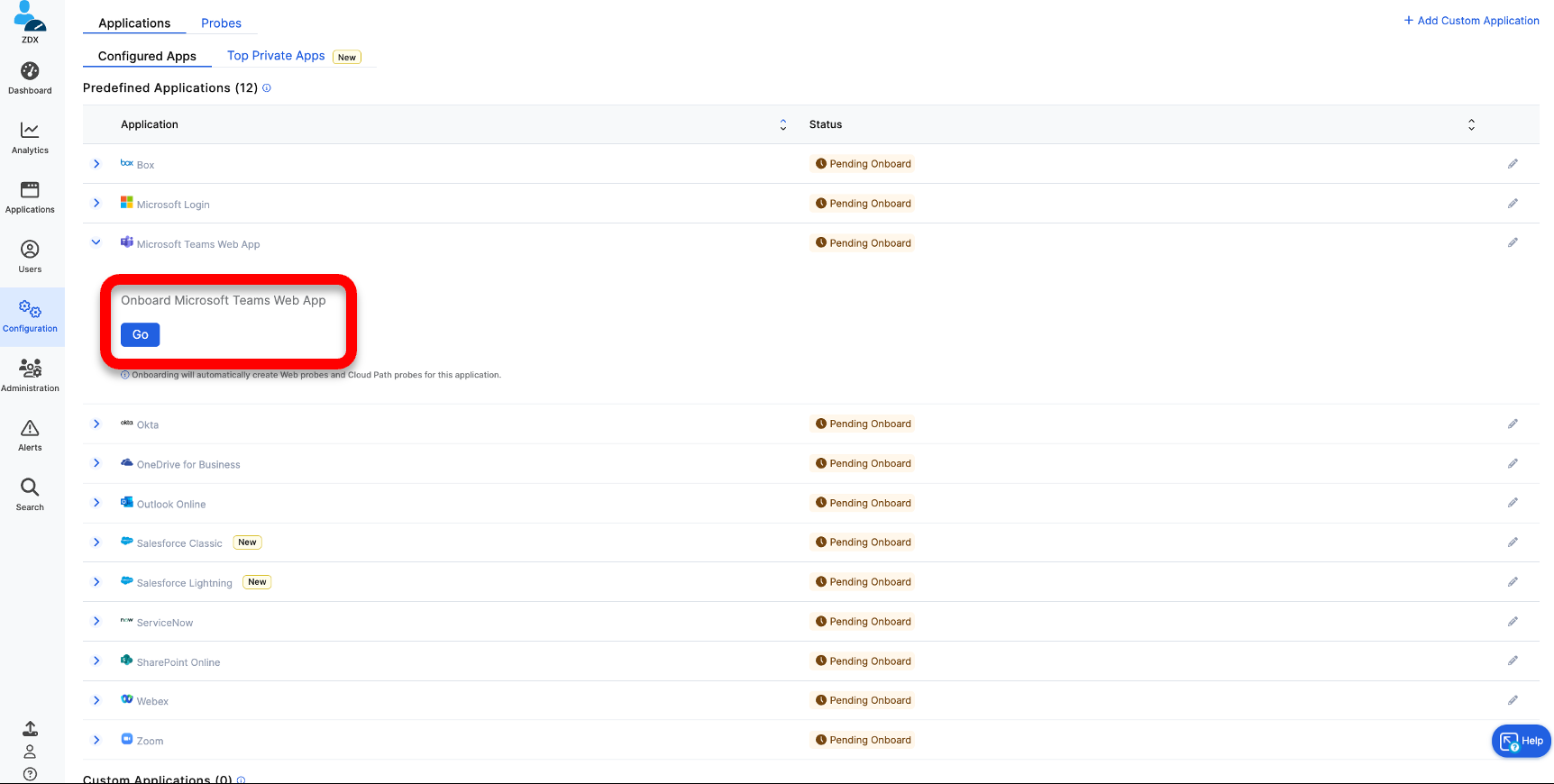
1 - アプリケーションを追加
- [Configuration] メニューをクリックします。
- [Applications]タブを選択し、 [Microsoft Teams Web App]をクリックして、[Go]をクリックします。
Microsoft Teamsを含む、Microsoft 365スイートを利用する組織に最適なエディションとして、ZDX Standardの上位エディションとなるZDX M365があります。
UCaaS 監視を含む ZDX の各種エディションの紹介はこちら
https://www.zscaler.com/jp/resources/data-sheets/zscaler-digital-experience.pdf
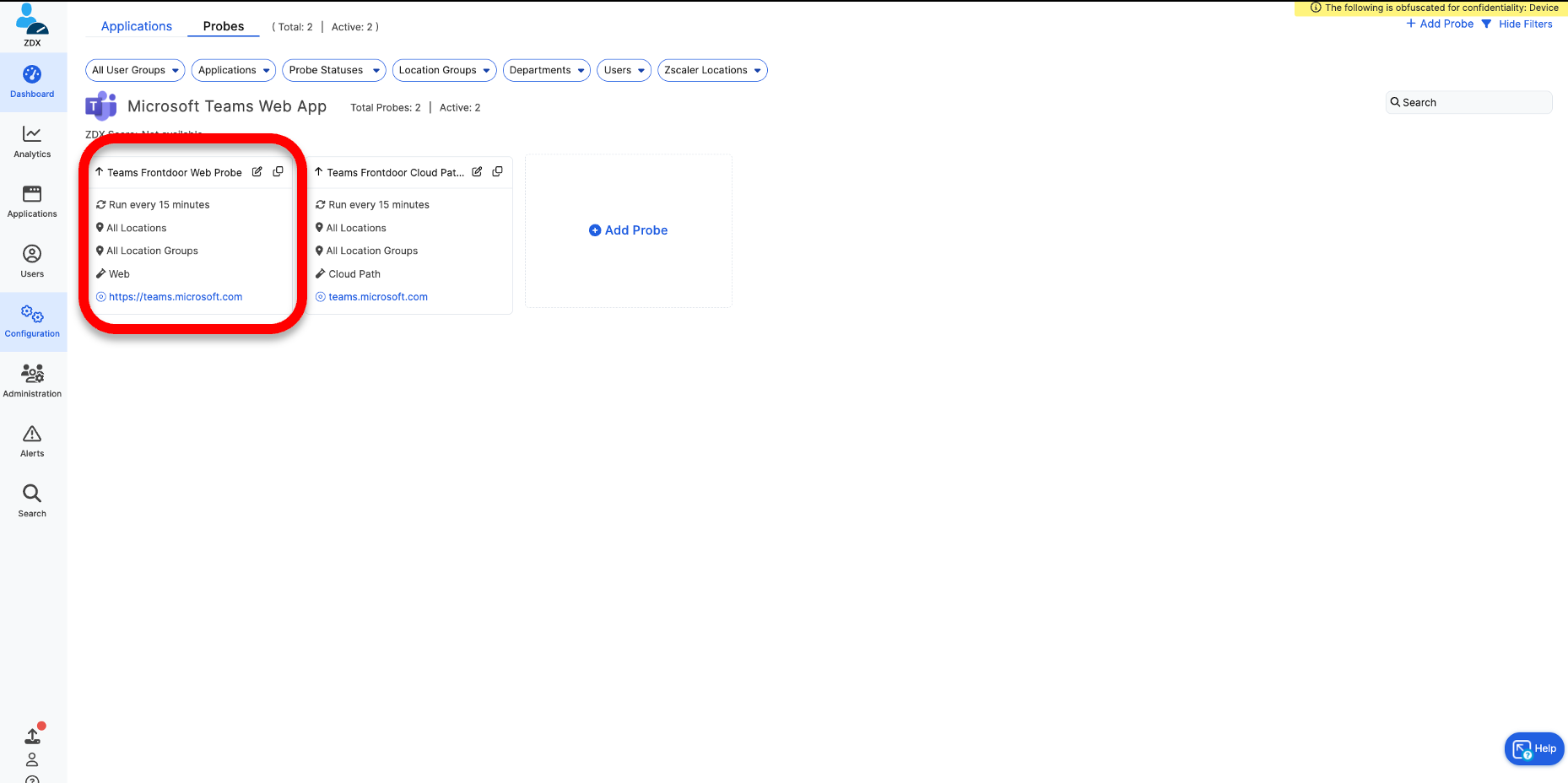
2 - プローブを設定
Web Probeの設定
[Probes]タブを選択します。
Microsoft Teams Web Appの [Destination URL] が次のように設定されていることを確認します。
https://teams.microsoft.com
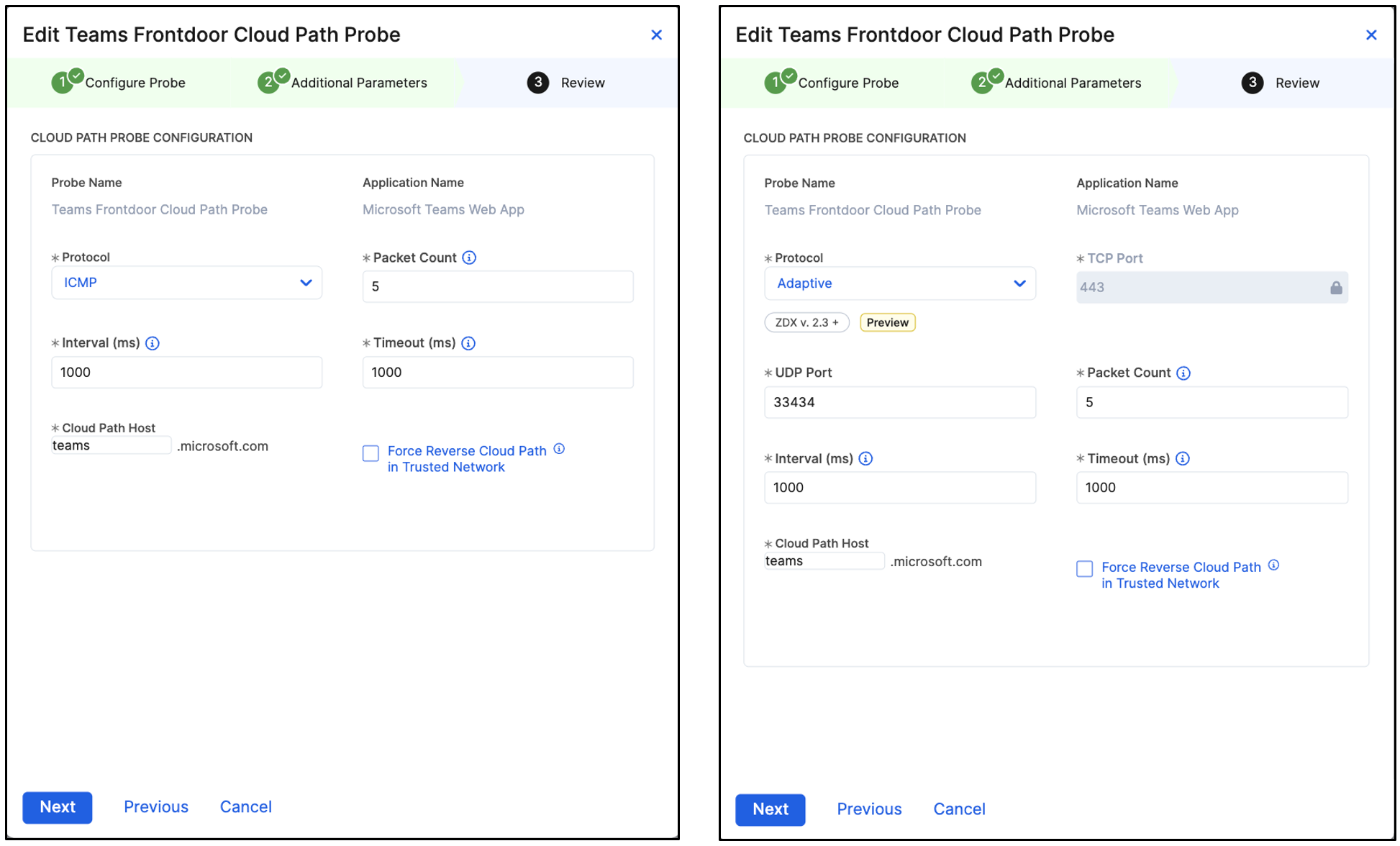
Web Probe編集画面から、[②Additional Parameters]に遷移して、[HTTP Response Status Codes]にて200-299、301、302、304、307が含まれていることを確認します。

Cloud Path probesの設定
Cloud Path Probe編集画面から、[②Additional Parameters]に遷移して、プロトコルを[ICMP]から[Adaptive]に変更します。
これにより、アプリがプローブプロトコルを変更した際にも、プローブプロトコルが動的に変更されます(プローブを手動で編集する必要はありません)。
[Packet Count] が 5 に設定されていることを確認します。SaaSアプリでは5がおすすめです。

3 - アラートを作成
ZDXのアラートを設定します。
適切な条件でアラートを設定することは、エンドユーザーに影響を与える前に問題を特定するために重要です。
[Alerts] メニューから[Rules]タブ をクリックし、[+ Add Alert Rule] でTeams用に以下のアラートルールを設定します。

作成する3つのアラートルール
| Name | Rule Type | Filter | Criteria | Action |
|---|---|---|---|---|
| Alert 1 | Application | “Web Probe” : Teams Frontdoor Web Prob |
“Page Fetch Time” > 平均値の2倍 (平均値が不明な場合には4000ms) OR “Web Request Availability” < 10%
|
“Minimum Devices Impacted” : 10% ”Alert Only if Repeated” : 3
|
| Alert 2 | Network | “Cloud Path Probe” :Teams Frontdoor Cloud Path Probe |
“Latency” > 平均値 の1.5倍 (平均値が不明な場合には100ms) AND “Packet Loss” >= 20%
|
“Minimum Devices Impacted” : 50% ”Alert Only if Repeated” : 3
|
| Alert 3 | Device | None |
“CPU Usage” >=70% AND “Memory Usage” >= 70% AND “Bandwidth” >= 50Mbps
|
“Minimum Devices Impacted” : 10% “In Group“ : Departments
|
Alert 1 Application の監視

アプリケーションの遅延を検出するために最も推奨される設定が "PageFetchTime" (PFT) です。
PFTには、読み込み時間、DNS解決時間、サーバー応答、合計時間が含まれます。
これらのメトリクスは、アプリケーションとネットワークの両方のパフォーマンスをカバーしています。
一方、“Web Request Availability” 監視は、アプリが応答しない場合に通知を受け取るのに役立ちます。
Alert 2 Network の監視

複数のデバイスで発生しているネットワーク遅延を測定します。
ルーティングとネットワークの問題を検出するのに役立ちます。
Alert 3 Deviceの監視
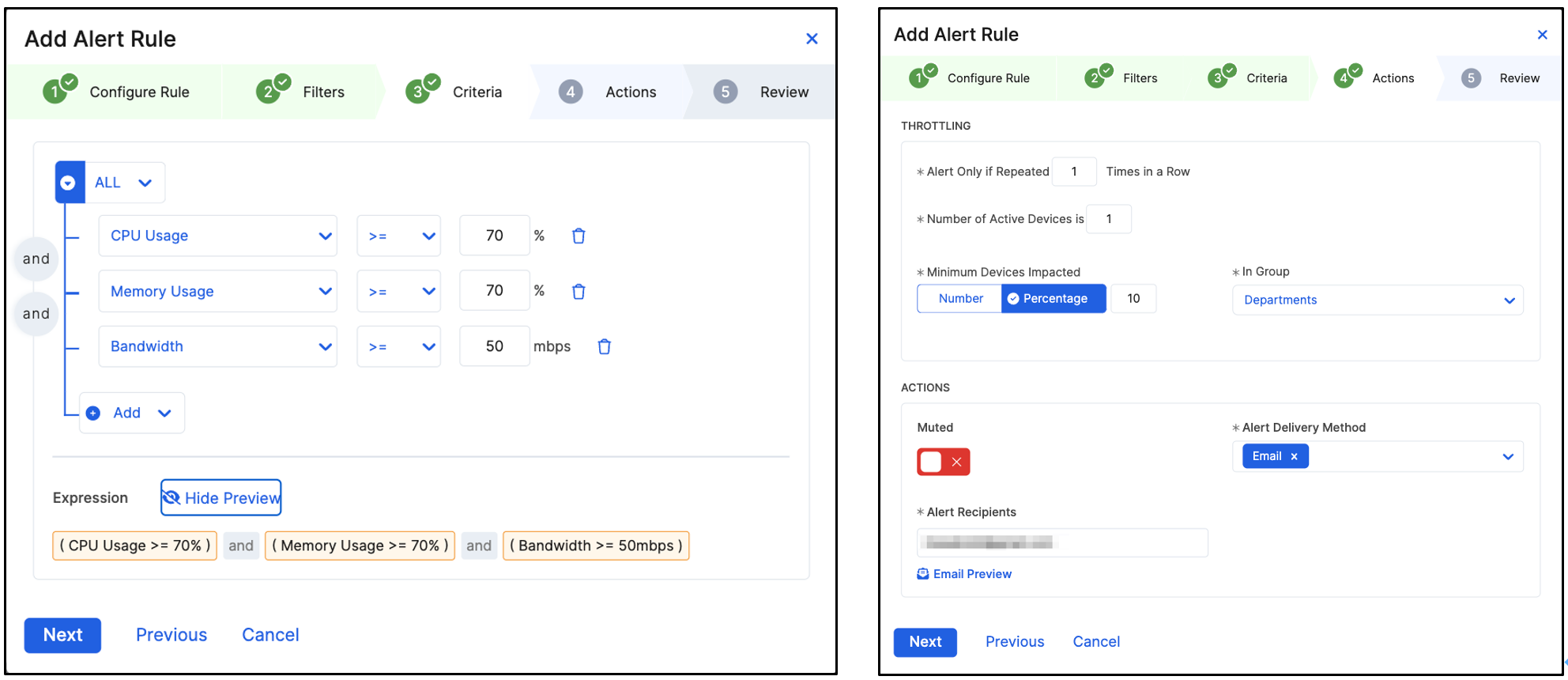
同じ部門のデバイスの全体のうち10%でCPU 使用率が高い状態になるとアラートがトリガーされます。
これにより、デバイスのリソース状況の傾向を把握することができます。
アラート設定後の画面

ZDX を活用して Office 365 のパフォーマンスの問題を特定する
シナリオ 1: 個別のユーザーが Office アプリケーションのパフォーマンスについて不満を漏らしている
[Users]をクリックし、[Applications]ドロップダウンメニューからアプリ(この場合はTeams)を選択し、苦情を申し立てたユーザーをフィルタリングします。
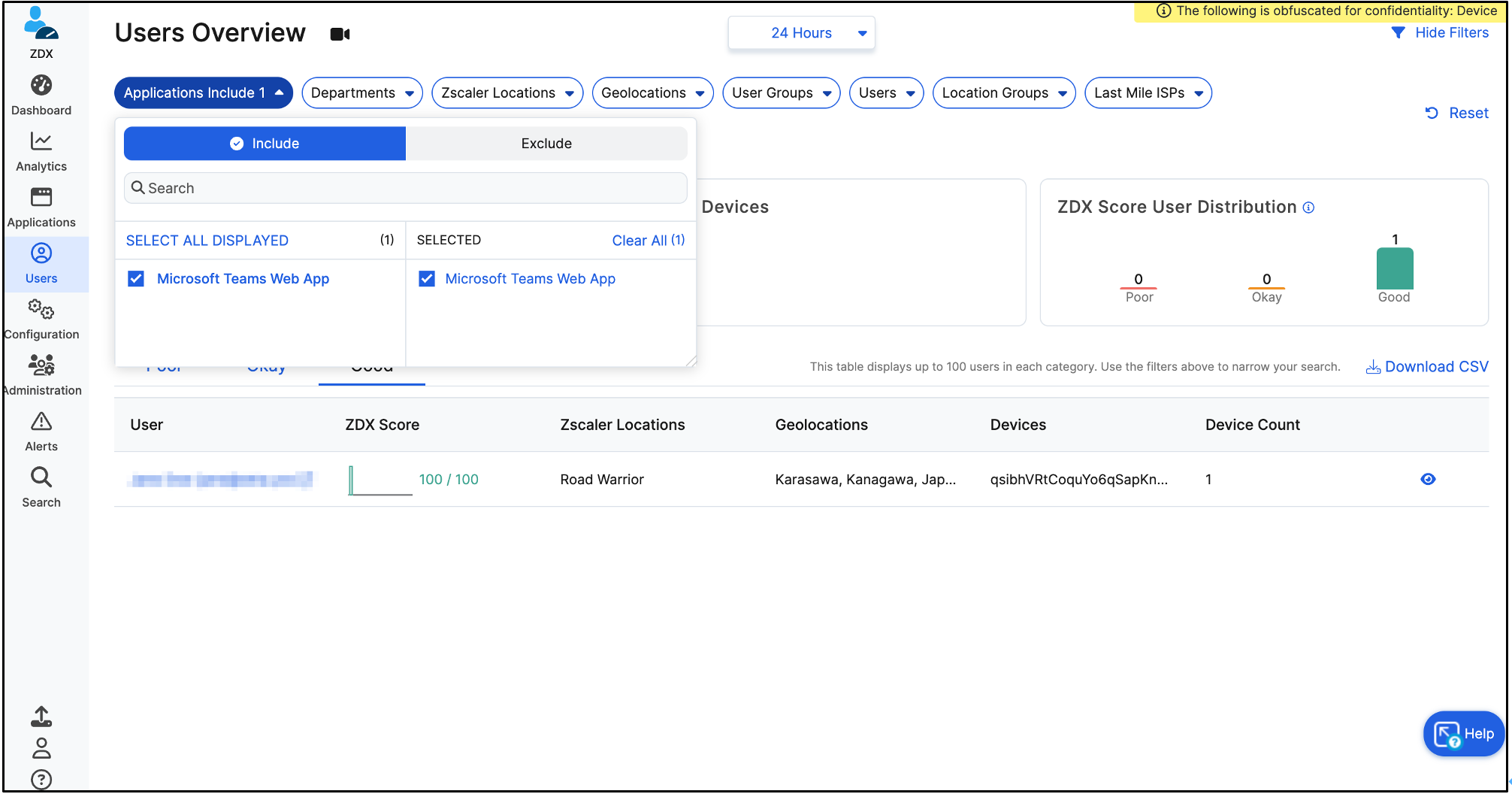
[Cloud Path]までスクロールして、問題の原因について詳しく知ることができます。
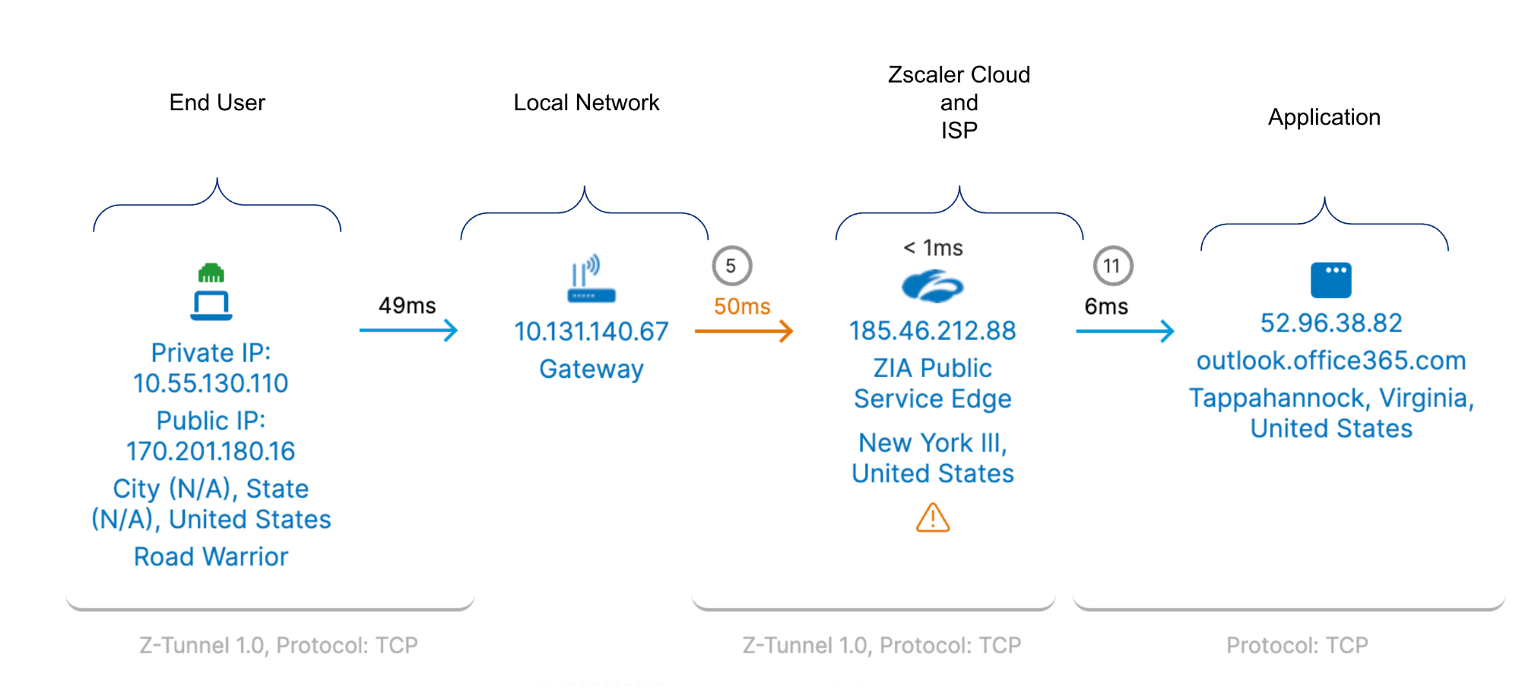
Application で問題が検出されると、感嘆符  が下に表示されます。
が下に表示されます。
例えば、Sharepoint を利用する際のDNS時間、サーバー時間などが原因と考えられます。
Zscaler Cloud(Zscalerのクラウドインフラストラクチャ) で問題が検出されると、感嘆符  が下に表示されます。
が下に表示されます。
例えば、Zscaler でリクエストの処理に問題が発生していることが原因と考えられます
ネットワーク で問題が検出されると、矢印 がオレンジ色に変わります。
例えば、ユーザーのローカルネットワークで遅延やパケット損失が原因、またはISPが原因と考えられます。
End User (エンドユーザーデバイス) で問題が検出される場合には、CPU 使用率が高い  、Wi-Fi の問題
、Wi-Fi の問題  などが原因と考えられます。
などが原因と考えられます。
シナリオ 2: 多くのユーザーからM365 アプリケーションのパフォーマンスが悪いと報告がある
ZDX管理ポータルからユーザー全体のトレンドを確認します。
[Applications]に移動し、影響を受けるアプリ(この場合はTeams)を選択します。
時系列でのZDXスコア(パフォーマンス)、ページフェッチ時間(可用性を含む)、および地域ごとのZDXスコア(パフォーマンス)が表示されます。

ZDX Advanced エディションでは、ML/AIを利用して問題の根本原因を自動的に特定できます。
参考情報: Best Practices in Operationalizing ZDX | Zscaler
https://www.zscaler.com/resources/white-papers/best-practices-operationalizing-zdx.pdf
以上となります。