はじめに
言語処理100本ノックは、東北大学の乾・岡崎研究室で公開されている、実践的な課題に取り組みながら,プログラミング,データ分析,研究のスキルを楽しく習得することを目指した問題集です。
これまでに、「第4章 形態素解析」、「第5章 係り受け解析」、「第8章 機械学習」、「第9章 ベクトル空間法 (I)」を解いてきました。引き続き「第10章 ベクトル空間法 (II)」を進めていきます。
9章では、なんちゃってword2vecを実装しましたが、10章では一般に公開されているword2vecライブラリを使って色々やっていきます。これが最終章です。
8章、9章は、NLP初心者の私には、問題文の理解すらおぼつかない状態だったため、タイトルを「問題文の意味がわからない人のための〜」と題して、問題文の解釈と併せて説明してきました。
この章はそこまで難しくないと思いますので、タイトルから「問題文の意味がわからない人のための〜」を外し、4章、5章の淡々とコードを載せていくスタイルに戻しています。
調べないと分からなかった/思い出せなかった用語は下記の3つです。
- k-meansクラスタリング
- Ward法によるクラスタリング
- t-SNEによる可視化
一応、簡単にまとめておきます。
k-meansクラスタリング / Ward法によるクラスタリング
クラスタリングとは、人間があれこれ教えることなしに、機械に勝手にデータを分類させる手法。
非階層型のクラスタリングと階層型のクラスタリングがあって、それぞれの代表格がk-means(非階層型)とWard法(階層型)。この辺の記事(最も重要で、最もよく使われ、最も難しい分析手法の一つ「クラスター分析」)に短く要点がまとまっていると思います。
t-SNE
9章に出てきた主成分分析や特異値分解と同じような次元圧縮の手法の一つではあるが、人間が解釈しやすい様に次元圧縮してくれるので、2〜3次元程度に圧縮して可視化するという用途に向いている。
「t-SNE を用いた次元圧縮方法のご紹介」が分かりやすかったです。
では、以降で淡々と90〜99を解いて行きます。最後に総括的なことを書いています。
90. word2vecによる学習
81で作成したコーパスに対してword2vecを適用し,単語ベクトルを学習せよ.
さらに,学習した単語ベクトルの形式を変換し,86-89のプログラムを動かせ.
spark.mllibのword2vecを使います。
package nlp100_10
import java.io.{File, PrintWriter}
import scala.io.Source
import org.apache.spark.rdd.RDD
import org.apache.spark.mllib.linalg.{Vector, Vectors}
import org.apache.spark.mllib.clustering.{KMeans, KMeansModel}
import nlp100_10.Model._
object Main {
def main(args: Array[String]) {
println("86. 単語ベクトルの表示")
println(model.transform("United_States").toArray.mkString(" "))
println("87. 単語の類似度")
println(multiplyVec(model.transform("United_States"), model.transform("U.S")))
println("88. 類似度の高い単語10件")
wordSynonyms("England", 10).foreach(println)
println("89. 加法構成性によるアナロジー")
println(vectorSynonyms(analogyWord("Spain", "Madrid", "Athens")).head._1)
}
package nlp100_10
import java.io.{File, PrintWriter}
import scala.io.Source
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import org.apache.spark.mllib.feature.{Normalizer, Word2Vec, Word2VecModel}
import org.apache.spark.mllib.linalg.{Vector, Vectors}
import org.apache.spark.mllib.clustering.{KMeans, KMeansModel}
import nlp100_9.WikiRDD._
object Model {
val RAW_FILE = "/Users/inaba/Dropbox/NLP100-Spark/src/main/resources/enwiki-20150112-400-r10-105752.txt"
val COMBINED_WORDS = "/Users/inaba/Dropbox/NLP100-Spark/src/main/resources/combined_words.txt"
val CORPUS = "/Users/inaba/Dropbox/NLP100-Spark/src/main/resources/corpus"
val MODEL_PATH = "/Users/inaba/Dropbox/NLP100-Spark/src/main/resources/model"
val WORD_SIMILARITY_SET1 = "/Users/inaba/Dropbox/NLP100-Spark/src/main/resources/set1.tab"
val WORD_SIMILARITY_SET2 = "/Users/inaba/Dropbox/NLP100-Spark/src/main/resources/set2.tab"
val WORD_SIMILARITY_COMBINED = "/Users/inaba/Dropbox/NLP100-Spark/src/main/resources/combined.tab"
val COUNTRY_CLUSTERS = "/Users/inaba/Dropbox/NLP100-Spark/src/main/resources/clusters"
val COUNTRY_VECTORS = "/Users/inaba/Dropbox/NLP100-Spark/src/main/resources/country_vectors.txt"
val sc = new SparkContext(new SparkConf().setAppName("NLP100").setMaster("local[*]"))
val model: Word2VecModel = {
if (!new File(CORPUS).exists) {
// コーパスがなければ作成する
sc.textFile(RAW_FILE).cleansData.replaceCombinedWord(COMBINED_WORDS).saveAsTextFile(CORPUS)
}
val model: Word2VecModel = if (new File(MODEL_PATH).exists) {
Word2VecModel.load(sc, MODEL_PATH)
} else {
val input = sc.textFile(CORPUS).map(_.split(" ").toVector)
// モデルの生成と学習
val m = new Word2Vec()
.setVectorSize(300)
.setNumPartitions(20)
.setMinCount(1000)
.fit(input)
m.save(sc, MODEL_PATH)
m
}
// 正規化
val normalizer = new Normalizer
new Word2VecModel(
model.getVectors.map { case (key, array) =>
key -> normalizer.transform(toVector(array)).toArray.map(_.toFloat)
})
}
/* 各種計算メソッド */
def plusVec(vec1: Vector, vec2: Vector): Vector = Vectors.dense(vec1.toArray.zip(vec2.toArray).map { case (v1, v2) => v1 + v2 })
def minusVec(vec1: Vector, vec2: Vector): Vector = Vectors.dense(vec1.toArray.zip(vec2.toArray).map { case (v1, v2) => v1 - v2 })
def multiplyVec(vec1: Vector, vec2: Vector): Double = vec1.toArray.zip(vec2.toArray).map { case (v1, v2) => v1 * v2 }.sum
def analogyVec(vec1: Vector, vec2: Vector, vec3: Vector) = plusVec(minusVec(vec1, vec2), vec3)
def analogyWord(word1: String, word2: String, word3: String) = plusVec(minusVec(model.transform(word1), model.transform(word2)), model.transform(word3))
def toVector(a: Array[Float]): Vector = Vectors.dense(a.map(_.toDouble))
def vectorSynonyms(vector: Vector, num: Int = 10): List[(String, Double)] = {
model.getVectors.map { case (k, array) => k -> multiplyVec(vector, toVector(array)) }.toList.sortBy(_._2).reverse.slice(0, num)
}
def wordSynonyms(word: String, num: Int = 10): List[(String, Double)] = {
vectorSynonyms(model.transform(word), num)
}
86. 単語ベクトルの表示
-0.05195711553096771 -0.02188839577138424 -0.02766110934317112 ...
87. 単語の類似度
0.7993002007168585
88. 類似度の高い単語10件
(England,0.999999995906603)
(Scotland,0.8266511212525927)
(Wales,0.8146345041068417)
(London,0.7710435879598873)
(Australia,0.7684126888668479)
(Ireland,0.7508965993753893)
(Hampshire,0.7350064189984341)
(Lancashire,0.7295800707042573)
(Yorkshire,0.7289047527357796)
(Sydney,0.7255715511987988)
89. 加法構成性によるアナロジー
Greece
完璧!
91. アナロジーデータの準備
単語アナロジーの評価データをダウンロードせよ.このデータ中で": "で始まる行はセクション名を表す.
例えば,": capital-common-countries"という行は,"capital-common-countries"というセクションの開始を表している.
ダウンロードした評価データの中で,"family"というセクションに含まれる評価事例を抜き出してファイルに保存せよ.
問題文の単語アナロジーの評価データはリンクが切れているようなので、ここから落としてきました。
def analogies: List[List[String]] = {
val URL = "https://raw.githubusercontent.com/arfon/word2vec/master/questions-words.txt"
val ANALOGY_DATA = "/Users/inaba/Dropbox/NLP100-Spark/src/main/resources/analogy.txt"
if (new File(ANALOGY_DATA).exists) {
Source.fromFile(ANALOGY_DATA).getLines().toList.map(_.split(" ").toList)
} else {
// familyセクションのみ切り出し
var families = Source.fromURL(URL).getLines.toList
families = families.slice(families.indexOf(": family") + 1, families.length)
families = families.slice(0, families.indexWhere(_.startsWith(": ")))
// ファイル出力
val file = new PrintWriter(ANALOGY_DATA)
file.write(families.mkString("\n"))
file.close()
families.map(_.split(" ").toList)
}
}
92. アナロジーデータへの適用
91で作成した評価データの各事例に対して,vec(2列目の単語) - vec(1列目の単語) + vec(3列目の単語)を計算し,そのベクトルと類似度が最も高い単語と,その類似度を求めよ.
求めた単語と類似度は,各事例の末尾に追記せよ.
このプログラムを85で作成した単語ベクトル,90で作成した単語ベクトルに対して適用せよ.
resultの中に正解(true)/不正解(false)を入れていきます。
var result = List[Boolean]()
analogies.foreach { words =>
try {
val actualAnswer = vectorSynonyms(analogyWord(words.head, words(1), words(2)), 1).head._1
println("%s\t-\t%s\t+\t%s\t=\t%s\t%s".format(words.head, words(1), words(2), words(3), actualAnswer))
result :+= (words(3) == actualAnswer)
} catch {
case e: IllegalStateException => Unit
}
}
93. アナロジータスクの正解率の計算
92で作ったデータを用い,各モデルのアナロジータスクの正解率を求めよ.
println(result.count(x => x) / result.length.toDouble)
0.020512820512820513
上手く学習できてないですね。。。
boy/girl、father/mother、brother/sister等の性別の違いを学習できてないため、boy - girl + brother = brotherになっちゃってるようです。
94. WordSimilarity-353での類似度計算
The WordSimilarity-353 Test Collectionの評価データを入力とし,1列目と2列目の単語の類似度を計算し,各行の末尾に類似度の値を追加するプログラムを作成せよ.
このプログラムを85で作成した単語ベクトル,90で作成した単語ベクトルに対して適用せよ.
val (human: List[Double], machine: List[Double]) = wordSimilarity(WORD_SIMILARITY_COMBINED).unzip
def wordSimilarity(fileName: String): List[(Double, Double)] = {
Source.fromFile(fileName).getLines.map { line =>
try {
val words = line.toString.split("\t")
List(words(2).toDouble, multiplyVec(model.transform(words(0)), model.transform(words(1))))
} catch {
case e: IllegalStateException => Nil
case e: NumberFormatException => Nil
}
}.filter(_.nonEmpty).toList.map(x => (x.head, x.last))
}
95. WordSimilarity-353での評価
94で作ったデータを用い,各モデルが出力する類似度のランキングと,人間の類似度判定のランキングの間のスピアマン相関係数を計算せよ.
val diff = rank(human).zip(rank(machine)) // 2つの類似度のリストを順位のリストに変換に変換してペアにする
.map(x => math.pow(x._1 - x._2, 2)) // 対となる順位の差をそれぞれ求めて2乗する
println(spearman(diff))
// 類似度のリストを順位のリストに変換に変換
def rank(words: List[Double]): List[Int] = {
val ranking = words.sorted.zipWithIndex.map(x => (x._1, x._2 + 1)).toMap
words.map(ranking)
}
//スピアマンの順位相関係数。同じ順位の場合は昇順にしているため若干本来と違う。a:4.5,b:4.5 => a:4,b:5 にしてる。
def spearman(diff: List[Double]) = 1 - (6 * diff.sum) / (math.pow(diff.length, 3) - diff.length)
combined: 0.39186961031541434 (低い相関あり)
set1: 0.2655867166143566 (低い相関あり)
set2: 0.4190924041068492 (相関あり)
96. 国名に関するベクトルの抽出
word2vecの学習結果から,国名に関するベクトルのみを抜き出せ.
// 複合語の処理 (例えば、"United States" => "United_States")
val countryNames = Source.fromFile(COMBINED_WORDS).getLines.map(line => line.replace(" ", "_")).toList
val countryVectors: Map[String, Vector] = model.getVectors
.filter(x => countryNames.indexOf(x._1) >= 0) // 国名だけを抽出
.map { case (key, array) => key -> Vectors.dense(array.map(y => y.toDouble)) } // String->Array[Float]をString->Vectorに変換
97. k-meansクラスタリング
96の単語ベクトルに対して,k-meansクラスタリングをクラスタ数k=5として実行せよ.
val countryRdd: RDD[Vector] = sc.parallelize(countryVectors.values.toList) // MapをRDDに変換
val clusters = if (new File(COUNTRY_CLUSTERS).exists) {
// k-meansクラスタリングモデルがファイルに保存されている場合
KMeansModel.load(sc, COUNTRY_CLUSTERS)
} else {
// k-meansクラスタリングモデルがファイルに保存されていない場合
val clusters: KMeansModel = KMeans.train(countryRdd, 5, 100)
clusters.save(sc, COUNTRY_CLUSTERS)
clusters
}
// クラスタの中心点が5つできていることを確認
clusters.clusterCenters.foreach(println)
// 各データがどのクラスタに属しているかを確認
countryVectors.keys.zip(clusters.predict(countryRdd).collect)
.toList.sortBy(_._2).foreach(println)
[0.04466799285174126,0.04456286245424832,-0.01976845185050652, ...
[0.03334749694396224,0.015676170529332012,-0.03916260437108576, ...
[-0.014139431890928082,-0.0038628893671557307,-0.04137489525601268, ...
[0.03492516125058473,0.024117531810506163,-0.029571880074923465, ...
[0.043189115822315216,0.02963972231373191,-0.03933139890432358, ...
(Morocco,0)
(Macedonia,0)
中略
(Sudan,0)
(Chile,1)
(Indonesia,1)
中略
(Czech_Republic,1)
(Jordan,2)
(Jersey,2)
中略
(Bermuda,2)
(Lebanon,3)
(France,3)
中略
(Denmark,3)
(India,4)
(Pakistan,4)
中略
(China,4)
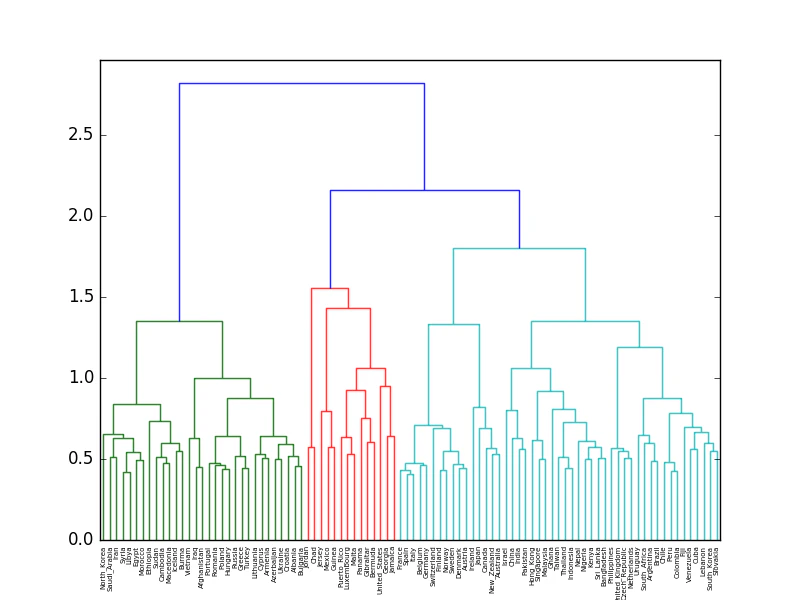
98.Ward法によるクラスタリング、99.t-SNEによる可視化
98.Ward法によるクラスタリング
96の単語ベクトルに対して,Ward法による階層型クラスタリングを実行せよ.
さらに,クラスタリング結果をデンドログラムとして可視化せよ.
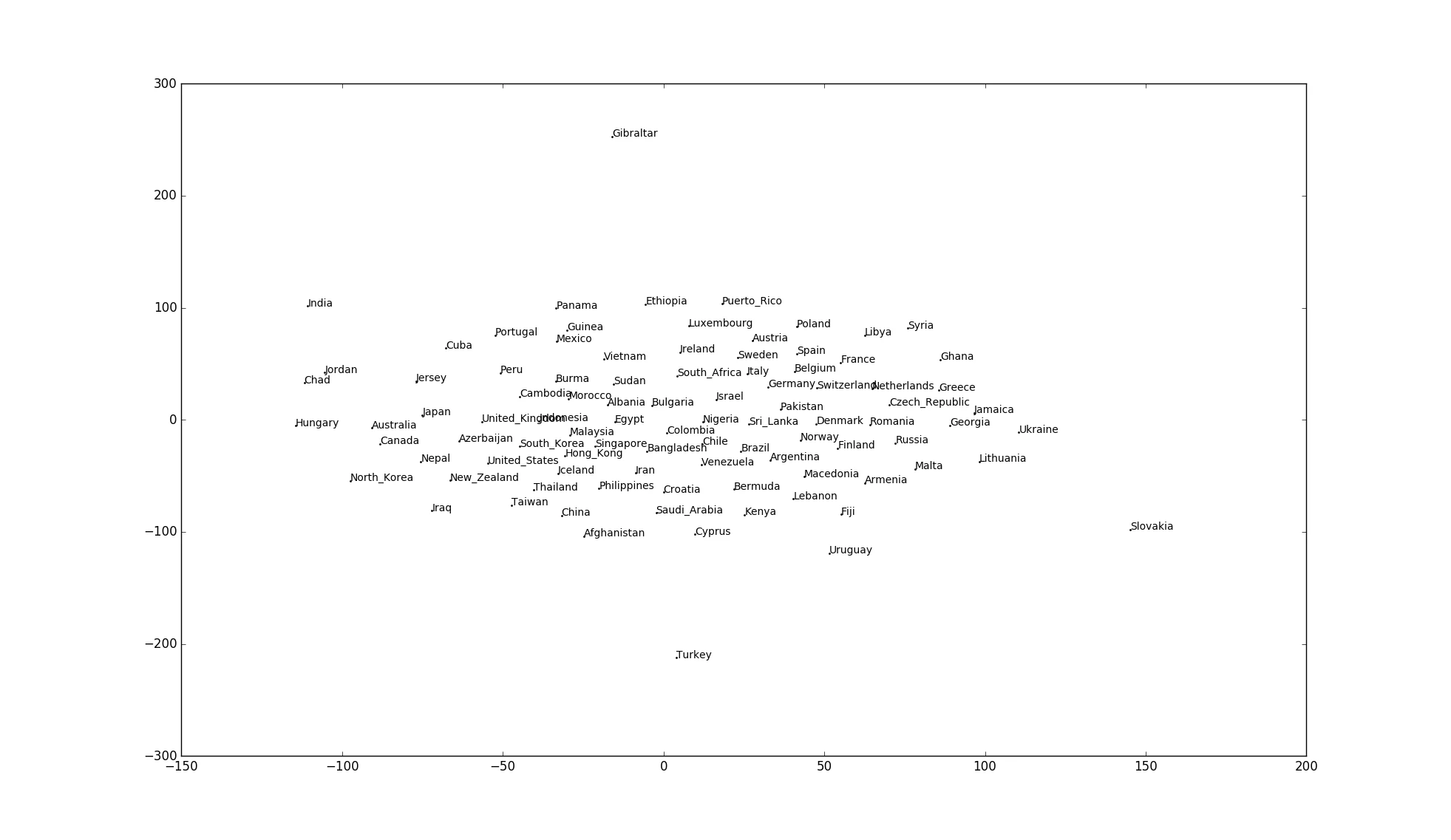
99.t-SNEによる可視化
96の単語ベクトルに対して,ベクトル空間をt-SNEで可視化せよ.
なんとSparkのspark.mllibがWard法をサポートしてないっぽい(Clustering - spark.mllib)。
あと二問なのにまた別のライブラリを探すの面倒くさいなぁ。
JVMで動くものとしては、Wekaというのがあるらしいが"the last decade"感が半端ないからパス。
ということで、いつもお世話になっている北野坂備忘録に倣ってscipyでやります。
from scipy.cluster.hierarchy import ward, dendrogram
from sklearn.manifold import TSNE
from matplotlib import pyplot as plt
# 単語ベクトルをファイルから復元 (スペース区切りで1列目が国名、2列目から301列目までが国名の特徴を表すベクトル)
COUNTRY_VECTORS = '/Users/inaba/Dropbox/NLP100-Spark/src/main/resources/country_vectors.txt'
with open(COUNTRY_VECTORS) as input_handler:
lines = [line.split() for line in input_handler]
country_names = [line[0] for line in lines]
country_vectors = [line[1:] for line in lines]
# Ward法でクラスタリング
ward_result = ward(country_vectors)
# デンドログラムで表示
dendrogram(ward_result, labels=country_names)
plt.show()
# t-SNE
t_sne_result = TSNE().fit_transform(country_vectors)
# 表示
fig, ax = plt.subplots()
ax.scatter(t_sne_result[:, 0], t_sne_result[:, 1])
for index, label in enumerate(country_names):
ax.annotate(label, xy=(t_sne_result[index, 0], t_sne_result[index, 1]))
plt.show()
カンタン。でも、殆ど国名は読めない。。。かろうじて読めるところも、あまり納得感はない。
ここでは、scipy.cluster.hierarchyやsklearn.manifoldを使えばward法でのクラスタリング、dendrogramでの可視化、t-SNEによる可視化が簡単にできることを確認するだけで良しとしよう。
言語処理100本ノック全体を通しての総括(感想)
最後に、全体を通して学んだことを簡単にまとめておきます。
あくまで初心者が少し言語処理をかじってみた限りでの感想なので、正しいことを説明しているとは思わないで下さい。
(コメント欄でのツッコミ大歓迎です。)
- 一見難解な機械学習用語や統計用語であっても、目的とインプット・アウトプットに着目してブラックボックス的ツールとして扱えば怖くない。
- ビッグデータのETL処理にSparkは不可欠だが、機械学習アルゴリズムはPython系ライブラリのほうが充実している。
- 機械学習・自然言語処理系のライブラリを使うのは難しくない。
- だけど「ライブラリを使ってみる」のと「精度の高い学習・分析をする」ことの距離は果てしなく遠い。。。(距離を埋めるために必要なことは何なんだろう?)
- 機械学習の結果出てきた分析結果が、正しいのか正しくないのかテストするのは難しい。普通(?)のアプリケーションの様に、Expected resultとActual resultが完全一致することを確認することはできないから。結局、学習結果の妥当性は、役に立つかどうかで判断するしかなく、役に立つかどうかを判断するには、分析の目的が明確でなくてはならない。この章は練習だから良いのだが、目的なしに漫然とクラスタリングしただけだと、"So what?"な結果になる。