100本ノックの「第5章 係り受け解析 (40〜49)」を解いてみました。第4章 形態素解析 (30〜39)の続きです。
環境
- OS X El Capitan Version 10.11.4
- Python 3.5.1
参考にしたページ
CaboCha、pydot、Graphvizの導入や、「49. 名詞間の係り受けパスの抽出」で結構ハマりましたが、下記のサイトを参考にさせて頂きなんとか解決しました。
- 自然言語処理100本ノック 第5章 係り受け解析(前半)
- 自然言語処理100本ノック 第5章 係り受け解析(後半)
- 言語処理100本ノック 2015年版 (46~49)
- CaboCha公式サイト
- CaboChaで始める係り受け解析
- Graphvizとdot言語でグラフを描く方法のまとめ
- graphvizを使ってPython3で木構造を描く
- [AttributeError: module 'pydot' has no attribute 'graph_from_dot_data' in spyder]
(http://stackoverflow.com/questions/35285142/attributeerror-module-pydot-has-no-attribute-graph-from-dot-data-in-spyder)
準備
使用するライブラリ
import CaboCha
import pydotplus
import subprocess
係り受け解析済み文章の保存
夏目漱石の小説『吾輩は猫である』の文章(neko.txt)をCaboChaを使って係り受け解析し,その結果をneko.txt.cabochaというファイルに保存せよ.
このファイルを用いて,以下の問に対応するプログラムを実装せよ.
def make_analyzed_file(input_file_name: str, output_file_name: str) -> None:
"""
プレーンな日本語の文章ファイルを係り受け解析してファイルに保存する.
(空白は削除します.)
:param input_file_name プレーンな日本語の文章ファイル名
:param output_file_name 係り受け解析済みの文章ファイル名
"""
c = CaboCha.Parser()
with open(input_file_name, encoding='utf-8') as input_file:
with open(output_file_name, mode='w', encoding='utf-8') as output_file:
for line in input_file:
tree = c.parse(line.lstrip())
output_file.write(tree.toString(CaboCha.FORMAT_LATTICE))
make_analyzed_file('neko.txt', 'neko.txt.cabocha')
40. 係り受け解析結果の読み込み(形態素)
形態素を表すクラスMorphを実装せよ.このクラスは表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をメンバ変数に持つこととする.
さらに,CaboChaの解析結果(neko.txt.cabocha)を読み込み,各文をMorphオブジェクトのリストとして表現し,3文目の形態素列を表示せよ.
class Morph:
"""
1つの形態素を表すクラス
"""
def __init__(self, surface, base, pos, pos1):
"""
メンバ変数として表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)を持つ.
"""
self.surface = surface
self.base = base
self.pos = pos
self.pos1 = pos1
def is_end_of_sentence(self) -> bool: return self.pos1 == '句点'
def __str__(self) -> str: return 'surface: {}, base: {}, pos: {}, pos1: {}'.format(self.surface, self.base, self.pos, self.pos1)
def make_morph_list(analyzed_file_name: str) -> list:
"""
係り受け解析済みの文章ファイルを読み込んで、各文をMorphオブジェクトのリストとして表現する
:param analyzed_file_name 係り受け解析済みの文章ファイル名
:return list 一つの文章をMorphオブジェクトのリストとして表現したもののリスト
"""
sentences = []
sentence = []
with open(analyzed_file_name, encoding='utf-8') as input_file:
for line in input_file:
line_list = line.split()
if (line_list[0] == '*') | (line_list[0] == 'EOS'):
pass
else:
line_list = line_list[0].split(',') + line_list[1].split(',')
# この時点でline_listはこんな感じ
# ['始め', '名詞', '副詞可能', '*', '*', '*', '*', '始め', 'ハジメ', 'ハジメ']
_morph = Morph(surface=line_list[0], base=line_list[7], pos=line_list[1], pos1=line_list[2])
sentence.append(_morph)
if _morph.is_end_of_sentence():
sentences.append(sentence)
sentence = []
return sentences
morphed_sentences = make_morph_list('neko.txt.cabocha')
# 3文目の形態素列を表示
for morph in morphed_sentences[2]:
print(str(morph))
41. 係り受け解析結果の読み込み(文節・係り受け)
40に加えて,文節を表すクラスChunkを実装せよ.
このクラスは形態素(Morphオブジェクト)のリスト(morphs),係り先文節インデックス番号(dst),係り元文節インデックス番号のリスト(srcs)をメンバ変数に持つこととする.
さらに,入力テキストのCaboChaの解析結果を読み込み,1文をChunkオブジェクトのリストとして表現し,8文目の文節の文字列と係り先を表示せよ.
第5章の残りの問題では,ここで作ったプログラムを活用せよ.
Chunkクラスにたくさんメソッドがありますが、ここで必要なのは__init__と__str__のみです。その他のメソッドは、後続の問を解いていくにあたって都度追加していったものです。
class Chunk:
def __init__(self, morphs: list, dst: str, srcs: str) -> None:
"""
形態素(Morphオブジェクト)のリスト(morphs),係り先文節インデックス番号(dst),係り元文節インデックス番号のリスト(srcs)をメンバ変数に持つ
"""
self.morphs = morphs
self.dst = int(dst.strip("D"))
self.srcs = int(srcs)
# 以下は後々使うメソッドです.
def join_morphs(self) -> str:
return ''.join([_morph.surface for _morph in self.morphs if _morph.pos != '記号'])
def has_noun(self) -> bool:
return any([_morph.pos == '名詞' for _morph in self.morphs])
def has_verb(self) -> bool:
return any([_morph.pos == '動詞' for _morph in self.morphs])
def has_particle(self) -> bool:
return any([_morph.pos == '助詞' for _morph in self.morphs])
def has_sahen_connection_noun_plus_wo(self) -> bool:
"""
「サ変接続名詞+を(助詞)」を含むかどうかを返す.
"""
for idx, _morph in enumerate(self.morphs):
if _morph.pos == '名詞' and _morph.pos1 == 'サ変接続' and len(self.morphs[idx:]) > 1 and \
self.morphs[idx + 1].pos == '助詞' and self.morphs[idx + 1].base == 'を':
return True
return False
def first_verb(self) -> Morph:
return [_morph for _morph in self.morphs if _morph.pos == '動詞'][0]
def last_particle(self) -> list:
return [_morph for _morph in self.morphs if _morph.pos == '助詞'][-1]
def pair(self, sentence: list) -> str:
return self.join_morphs() + '\t' + sentence[self.dst].join_morphs()
def replace_noun(self, alt: str) -> None:
"""
名詞の表象を置換する.
"""
for _morph in self.morphs:
if _morph.pos == '名詞':
_morph.surface = alt
def __str__(self) -> str:
return 'srcs: {}, dst: {}, morphs: ({})'.format(self.srcs, self.dst, ' / '.join([str(_morph) for _morph in self.morphs]))
def make_chunk_list(analyzed_file_name: str) -> list:
"""
係り受け解析済みの文章ファイルを読み込んで、各文をChunkオブジェクトのリストとして表現する
:param analyzed_file_name 係り受け解析済みの文章ファイル名
:return list 一つの文章をChunkオブジェクトのリストとして表現したもののリスト
"""
sentences = []
sentence = []
_chunk = None
with open(analyzed_file_name, encoding='utf-8') as input_file:
for line in input_file:
line_list = line.split()
if line_list[0] == '*':
if _chunk is not None:
sentence.append(_chunk)
_chunk = Chunk(morphs=[], dst=line_list[2], srcs=line_list[1])
elif line_list[0] == 'EOS': # End of sentence
if _chunk is not None:
sentence.append(_chunk)
if len(sentence) > 0:
sentences.append(sentence)
_chunk = None
sentence = []
else:
line_list = line_list[0].split(',') + line_list[1].split(',')
# この時点でline_listはこんな感じ
# ['始め', '名詞', '副詞可能', '*', '*', '*', '*', '始め', 'ハジメ', 'ハジメ']
_morph = Morph(surface=line_list[0], base=line_list[7], pos=line_list[1], pos1=line_list[2])
_chunk.morphs.append(_morph)
return sentences
chunked_sentences = make_chunk_list('neko.txt.cabocha')
# 3文目の形態素列を表示
for chunk in chunked_sentences[2]:
print(str(chunk))
42. 係り元と係り先の文節の表示
係り元の文節と係り先の文節のテキストをタブ区切り形式ですべて抽出せよ.ただし,句読点などの記号は出力しないようにせよ.
44で使いやすいように文章ごとにまとめておきます。
def is_valid_chunk(_chunk, sentence):
return _chunk.join_morphs() != '' and _chunk.dst > -1 and sentence[_chunk.dst].join_morphs() != ''
paired_sentences = [[chunk.pair(sentence) for chunk in sentence if is_valid_chunk(chunk, sentence)] for sentence in chunked_sentences if len(sentence) > 1]
print(paired_sentences[0:100])
43. 名詞を含む文節が動詞を含む文節に係るものを抽出
名詞を含む文節が,動詞を含む文節に係るとき,これらをタブ区切り形式で抽出せよ.ただし,句読点などの記号は出力しないようにせよ.
Chunkクラスに色々便利メソッドを実装しているので楽ですね。
for sentence in chunked_sentences:
for chunk in sentence:
if chunk.has_noun() and chunk.dst > -1 and sentence[chunk.dst].has_verb():
print(chunk.pair(sentence))
44. 係り受け木の可視化
与えられた文の係り受け木を有向グラフとして可視化せよ.
可視化には,係り受け木をDOT言語に変換し,Graphvizを用いるとよい.また,Pythonから有向グラフを直接的に可視化するには,pydotを使うとよい.
def sentence_to_dot(idx: int, sentence: list) -> str:
head = "digraph sentence{} ".format(idx)
body_head = "{ graph [rankdir = LR]; "
body_list = ['"{}"->"{}"; '.format(*chunk_pair.split()) for chunk_pair in sentence]
return head + body_head + ''.join(body_list) + '}'
def sentences_to_dots(sentences: list) -> list:
_dots = []
for idx, sentence in enumerate(sentences):
_dots.append(sentence_to_dot(idx, sentence))
return _dots
def save_graph(dot: str, file_name: str) -> None:
g = pydotplus.graph_from_dot_data(dot)
g.write_jpeg(file_name, prog='dot')
dots = sentences_to_dots(paired_sentences)
for idx in range(101, 104):
save_graph(dots[idx], 'graph{}.jpg'.format(idx))
【サンプル】101番目の文章の係り受け木
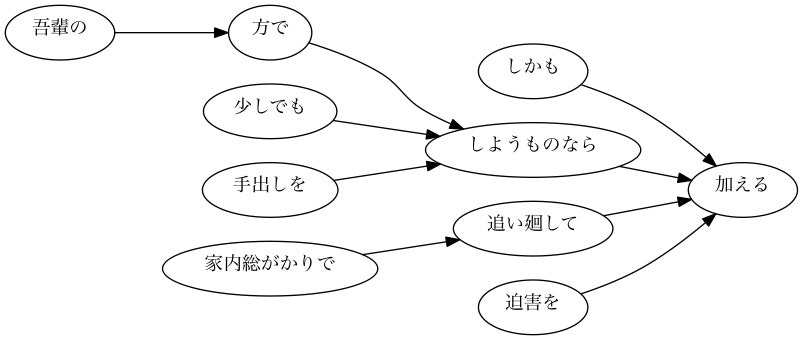
【サンプル】102番目の文章の係り受け木
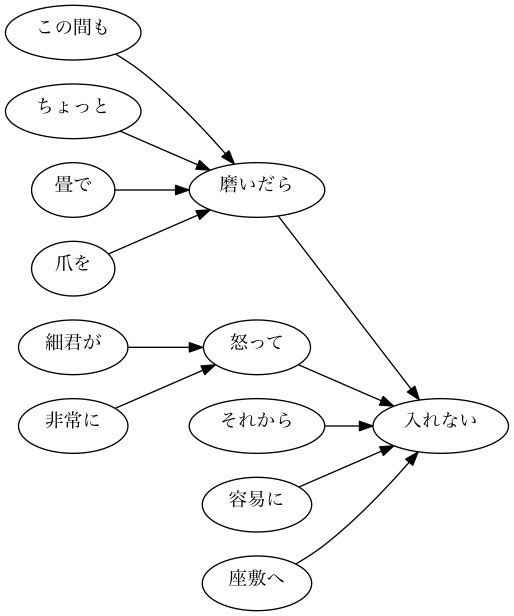
【サンプル】103番目の文章の係り受け木
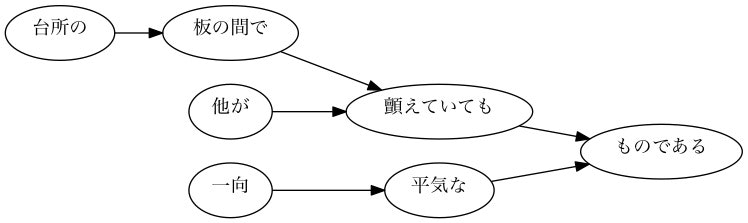
※ちなみに「顫える」は「ふるえる」と読むそうです。
45. 動詞の格パターンの抽出
今回用いている文章をコーパスと見なし,日本語の述語が取りうる格を調査したい.
動詞を述語,動詞に係っている文節の助詞を格と考え,述語と格をタブ区切り形式で出力せよ.
ただし,出力は以下の仕様を満たすようにせよ.
- 動詞を含む文節において,最左の動詞の基本形を述語とする
- 述語に係る助詞を格とする
- 述語に係る助詞(文節)が複数あるときは,すべての助詞をスペース区切りで辞書順に並べる
「吾輩はここで始めて人間というものを見た」という例文(neko.txt.cabochaの8文目)を考える.
この文は「始める」と「見る」の2つの動詞を含み,「始める」に係る文節は「ここで」,「見る」に係る文節は「吾輩は」と「ものを」と解析された場合は,次のような出力になるはずである.
始める で 見る は を
このプログラムの出力をファイルに保存し,以下の事項をUNIXコマンドを用いて確認せよ.
- コーパス中で頻出する述語と格パターンの組み合わせ
- 「する」「見る」「与える」という動詞の格パターン(コーパス中で出現頻度の高い順に並べよ)
def case_patterns(_chunked_sentences: list) -> list:
"""
動詞の格のパターン(動詞と助詞の組み合わせ)のリストを返します.(「格」は英語で"Case"というらしい.)
:param _chunked_sentences チャンク化された形態素を文章ごとにリスト化したもののリスト
:return 格のパターン(例えば['与える', ['に', 'を']])のリスト
"""
_case_pattern = []
for sentence in _chunked_sentences:
for _chunk in sentence:
if not _chunk.has_verb():
continue
particles = [c.last_particle().base for c in sentence if c.dst == _chunk.srcs and c.has_particle()]
if len(particles) > 0:
_case_pattern.append([_chunk.first_verb().base, sorted(particles)])
return _case_pattern
def save_case_patterns(_case_patterns: list, file_name: str) -> None:
"""
動詞の格のパターン(動詞と助詞の組み合わせ)のリストをファイルに保存します.
:param _case_patterns 格のパターン(例えば['与える', ['に', 'を']])のリスト
:param file_name 保存先のファイル名
"""
with open(file_name, mode='w', encoding='utf-8') as output_file:
for _case in _case_patterns:
output_file.write('{}\t{}\n'.format(_case[0], ' '.join(_case[1])))
save_case_patterns(case_patterns(chunked_sentences), 'case_patterns.txt')
def print_case_pattern_ranking(_grep_str: str) -> None:
"""
コーパス(case_pattern.txt)中で出現頻度の高い順に上位20件をUNIXコマンドを用いてを表示する.
`cat case_patterns.txt | grep '^する\t' | sort | uniq -c | sort -r | head -20`のようなUnixコマンドを実行してprintしている.
grepの部分は引数`_grep_str`に応じて付加される.
:param _grep_str 検索条件となる動詞
"""
_grep_str = '' if _grep_str == '' else '| grep \'^{}\t\''.format(_grep_str)
print(subprocess.run('cat case_patterns.txt {} | sort | uniq -c | sort -r | head -10'.format(_grep_str), shell=True))
# コーパス中で頻出する述語と格パターンの組み合わせ(上位10件)
# 「する」「見る」「与える」という動詞の格パターン(コーパス中で出現頻度の高い順に上位10件)
for grep_str in ['', 'する', '見る', '与える']:
print_case_pattern_ranking(grep_str)
46. 動詞の格フレーム情報の抽出
45のプログラムを改変し,述語と格パターンに続けて項(述語に係っている文節そのもの)をタブ区切り形式で出力せよ.
45の仕様に加えて,以下の仕様を満たすようにせよ.
- 項は述語に係っている文節の単語列とする(末尾の助詞を取り除く必要はない)
- 述語に係る文節が複数あるときは,助詞と同一の基準・順序でスペース区切りで並べる
「吾輩はここで始めて人間というものを見た」という例文(neko.txt.cabochaの8文目)を考える.
この文は「始める」と「見る」の2つの動詞を含み,「始める」に係る文節は「ここで」,「見る」に係る文節は「吾輩は」と「ものを」と解析された場合は,次のような出力になるはずである.
始める で ここで 見る は を 吾輩は ものを
def sorted_double_list(key_list: list, value_list: list) -> tuple:
"""
2つのリストを引数に取り、一方のリストをキー、もう一方のリストを値としてdict化しキーでソートしてから、元通りに2つのリストに分解してタプルとして返す.
:param key_list ソートするときのキーとなるリスト
:param value_list keyに従ってソートされるリスト
:return key_listでソート済みの2つのリストのタプル
"""
double_list = list(zip(key_list, value_list))
double_list = dict(double_list)
double_list = sorted(double_list.items())
return [pair[0] for pair in double_list], [pair[1] for pair in double_list]
def case_frame_patterns(_chunked_sentences: list) -> list:
"""
動詞の格フレームのパターン(動詞と助詞の組み合わせ)のリストを返します.
:param _chunked_sentences チャンク化された形態素を文章ごとにリスト化したもののリスト
:return 格のパターン(例えば['する', ['て', 'は'], ['泣いて', 'いた事だけは']])のリスト
"""
_case_frame_patterns = []
for sentence in _chunked_sentences:
for _chunk in sentence:
if not _chunk.has_verb():
continue
clauses = [c.join_morphs() for c in sentence if c.dst == _chunk.srcs and c.has_particle()]
particles = [c.last_particle().base for c in sentence if c.dst == _chunk.srcs and c.has_particle()]
if len(particles) > 0:
_case_frame_patterns.append([_chunk.first_verb().base, *sorted_double_list(particles, clauses)])
return _case_frame_patterns
def save_case_frame_patterns(_case_frame_patterns: list, file_name: str) -> None:
"""
動詞の格のパターン(動詞と助詞の組み合わせ)のリストをファイルに保存します.
:param _case_frame_patterns 格フレーム(例えば['する', ['て', 'は'], ['泣いて', 'いた事だけは']])のリスト
:param file_name 保存先のファイル名
"""
with open(file_name, mode='w', encoding='utf-8') as output_file:
for case in _case_frame_patterns:
output_file.write('{}\t{}\t{}\n'.format(case[0], ' '.join(case[1]), ' '.join(case[2])))
save_case_frame_patterns(case_frame_patterns(chunked_sentences), 'case_frame_patterns.txt')
47. 機能動詞構文のマイニング
動詞のヲ格にサ変接続名詞が入っている場合のみに着目したい.46のプログラムを以下の仕様を満たすように改変せよ.
- 「サ変接続名詞+を(助詞)」で構成される文節が動詞に係る場合のみを対象とする
- 述語は「サ変接続名詞+を+動詞の基本形」とし,文節中に複数の動詞があるときは,最左の動詞を用いる
- 述語に係る助詞(文節)が複数あるときは,すべての助詞をスペース区切りで辞書順に並べる
- 述語に係る文節が複数ある場合は,すべての項をスペース区切りで並べる(助詞の並び順と揃えよ)
例えば「別段くるにも及ばんさと、主人は手紙に返事をする。」という文から,以下の出力が得られるはずである.
返事をする と に は 及ばんさと 手紙に 主人は
このプログラムの出力をファイルに保存し,以下の事項をUNIXコマンドを用いて確認せよ.
- コーパス中で頻出する述語(サ変接続名詞+を+動詞)
- コーパス中で頻出する述語と助詞パターン
def sahen_case_frame_patterns(_chunked_sentences: list) -> list:
"""
動詞の格フレームのパターン(動詞と助詞の組み合わせ)のリストを返します.
:param _chunked_sentences チャンク化された形態素を文章ごとにリスト化したもののリスト
:return 格のパターン(例えば['する', ['て', 'は'], ['泣いて', 'いた事だけは']])のリスト
"""
_sahen_case_frame_patterns = []
for sentence in _chunked_sentences:
for _chunk in sentence:
if not _chunk.has_verb():
continue
sahen_connection_noun = [c.join_morphs() for c in sentence if c.dst == _chunk.srcs and c.has_sahen_connection_noun_plus_wo()]
clauses = [c.join_morphs() for c in sentence if c.dst == _chunk.srcs and not c.has_sahen_connection_noun_plus_wo() and c.has_particle()]
particles = [c.last_particle().base for c in sentence if c.dst == _chunk.srcs and not c.has_sahen_connection_noun_plus_wo() and c.has_particle()]
if len(sahen_connection_noun) > 0 and len(particles) > 0:
_sahen_case_frame_patterns.append([sahen_connection_noun[0] + _chunk.first_verb().base, *sorted_double_list(particles, clauses)])
return _sahen_case_frame_patterns
def save_sahen_case_frame_patterns(_sahen_case_frame_patterns: list, file_name: str) -> None:
"""
動詞の格のパターン(動詞と助詞の組み合わせ)のリストをファイルに保存します.
:param _sahen_case_frame_patterns 格フレーム(例えば['する', ['て', 'は'], ['泣いて', 'いた事だけは']])のリスト
:param file_name 保存先のファイル名
"""
with open(file_name, mode='w', encoding='utf-8') as output_file:
for case in _sahen_case_frame_patterns:
output_file.write('{}\t{}\t{}\n'.format(case[0], ' '.join(case[1]), ' '.join(case[2])))
save_sahen_case_frame_patterns(sahen_case_frame_patterns(chunked_sentences), 'sahen_case_frame_patterns.txt')
# コーパス中で頻出する述語(サ変接続名詞+を+動詞)をUNIXコマンドを用いて確認
print(subprocess.run('cat sahen_case_frame_patterns.txt | cut -f 1 | sort | uniq -c | sort -r | head -10', shell=True))
# コーパス中で頻出する述語と助詞パターンをUNIXコマンドを用いて確認
print(subprocess.run('cat sahen_case_frame_patterns.txt | cut -f 1,2 | sort | uniq -c | sort -r | head -10', shell=True))
48. 名詞から根へのパスの抽出
文中のすべての名詞を含む文節に対し,その文節から構文木の根に至るパスを抽出せよ. ただし,構文木上のパスは以下の仕様を満たすものとする.
- 各文節は(表層形の)形態素列で表現する
- パスの開始文節から終了文節に至るまで,各文節の表現を"->"で連結する
「吾輩はここで始めて人間というものを見た」という文(neko.txt.cabochaの8文目)から,次のような出力が得られるはずである.
吾輩は -> 見た ここで -> 始めて -> 人間という -> ものを -> 見た 人間という -> ものを -> 見た ものを -> 見た
再帰的に関数を呼び出すとスッキリ書けますね。
def path_to_root(_chunk: Chunk, _sentence: list) -> list:
"""
引数として与えられた文節(`_chunk`)がrootの場合は、その文節を返します.
引数として与えられた文節(`_chunk`)がrootでない場合は、その文節とその文節が係っている文節からrootまでのパスをlistとして返します.
:param _chunk rootへの起点となる文節
:param _sentence 分析対象の文章
:return list _chunkからrootまでのパス
"""
if _chunk.dst == -1:
return [_chunk]
else:
return [_chunk] + path_to_root(_sentence[_chunk.dst], _sentence)
def join_chunks_by_arrow(_chunks: list) -> str:
return ' -> '.join([c.join_morphs() for c in _chunks])
# 最初10文だけ出力して動作確認
for sentence in chunked_sentences[0:10]:
for chunk in sentence:
if chunk.has_noun():
print(join_chunks_by_arrow(path_to_root(chunk, sentence)))
49. 名詞間の係り受けパスの抽出
文中のすべての名詞句のペアを結ぶ最短係り受けパスを抽出せよ.ただし,名詞句ペアの文節番号がiとj(i<j)のとき,係り受けパスは以下の仕様を満たすものとする.
- 問題48と同様に,パスは開始文節から終了文節に至るまでの各文節の表現(表層形の形態素列)を"->"で連結して表現する
- 文節iとjに含まれる名詞句はそれぞれ,XとYに置換する
また,係り受けパスの形状は,以下の2通りが考えられる.
- 文節iから構文木の根に至る経路上に文節jが存在する場合: 文節iから文節jのパスを表示
- 上記以外で,文節iと文節jから構文木の根に至る経路上で共通の文節kで交わる場合: 文節iから文節kに至る直前のパスと文節jから文節kに至る直前までのパス,文節kの内容を"|"で連結して表示
例えば,「吾輩はここで始めて人間というものを見た。」という文(neko.txt.cabochaの8文目)から,次のような出力が得られるはずである.
Xは | Yで -> 始めて -> 人間という -> ものを | 見た Xは | Yという -> ものを | 見た Xは | Yを | 見た Xで -> 始めて -> Y Xで -> 始めて -> 人間という -> Y Xという -> Y
問題文を読んでも何がやりたいのか全く分からなかったけど、自然言語処理100本ノック 第5章 係り受け解析(後半)や言語処理100本ノック 2015年版 (46~49)を読んで理解したところによると、こういうことらしい.
分からないなりに、問題を分解しながらとりあえずコードを書き始めてみると徐々に分かってくるもんですね. どのように問題を分解したかについては、下記コードに少しコメントを多めに書いて説明しているので参考になればと思います。
def noun_pairs(_sentence: list):
"""
引数として渡された文章が持つ全ての名詞節から作ることができる全てのペアのリストを返す.
"""
from itertools import combinations
_noun_chunks = [_chunk for _chunk in _sentence if _chunk.has_noun()]
return list(combinations(_noun_chunks, 2))
def common_chunk(path_i: list, path_j: list) -> Chunk:
"""
文節iと文節jから構文木の根に至る経路上で共通の文節kで交わる場合、文節kを返す.
"""
_chunk_k = None
path_i = list(reversed(path_i))
path_j = list(reversed(path_j))
for idx, (c_i, c_j) in enumerate(zip(path_i, path_j)):
if c_i.srcs != c_j.srcs:
_chunk_k = path_i[idx - 1]
break
return _chunk_k
for sentence in chunked_sentences:
# 名詞句ペアのリスト
n_pairs = noun_pairs(sentence)
if len(n_pairs) == 0:
continue
for n_pair in n_pairs:
chunk_i, chunk_j = n_pair
# 文節iとjに含まれる名詞句はそれぞれ,XとYに置換する
chunk_i.replace_noun('X')
chunk_j.replace_noun('Y')
# 文節iとjからrootへのパス(Chunk型のlist)
path_chunk_i_to_root = path_to_root(chunk_i, sentence)
path_chunk_j_to_root = path_to_root(chunk_j, sentence)
if chunk_j in path_chunk_i_to_root:
# 文節iから構文木の根に至る経路上に文節jが存在する場合
# 文節jの文節iから構文木の根に至る経路上におけるインデックス
idx_j = path_chunk_i_to_root.index(chunk_j)
# 文節iから文節jのパスを表示
print(join_chunks_by_arrow(path_chunk_i_to_root[0: idx_j + 1]))
else:
# 上記以外で,文節iと文節jから構文木の根に至る経路上で共通の文節kで交わる場合
# 文節kを取得
chunk_k = common_chunk(path_chunk_i_to_root, path_chunk_j_to_root)
if chunk_k is None:
continue
# 文節kの文節iから構文木の根に至る経路上におけるインデックス
idx_k_i = path_chunk_i_to_root.index(chunk_k)
# 文節kの文節jから構文木の根に至る経路上におけるインデックス
idx_k_j = path_chunk_j_to_root.index(chunk_k)
# 文節iから文節kに至る直前のパスと文節jから文節kに至る直前までのパス,文節kの内容を"|"で連結して表示
print(' | '.join([join_chunks_by_arrow(path_chunk_i_to_root[0: idx_k_i]),
join_chunks_by_arrow(path_chunk_j_to_root[0: idx_k_j]),
chunk_k.join_morphs()]))