DynamoDB Streamとは
DynamoDB Streamは、DynamoDBに対する書込みをイベントトリガーとして利用できる機能です。つまりは特定のDynamoDBテーブルに書き込み(追加、変更、削除)があった場合にイベントが飛んでくるので、それをトリガーとしてLambdaを起動したりできます。使い方の概要このあたりが参考になると思います。
DynamoDB StreamをトリガーにしてLambdaを実行する
やりたかったこと
AWS IoT Core経由でRaspberry Piから飛んでくるセンサーデータを、DynamoDBテーブル(A)に格納しているのですが、このままでは比較的粒度が大きいので、Kibanaとかで可視化しやすいように、Lambdaで細かくバラして別テーブル(B)に格納したかったのです。
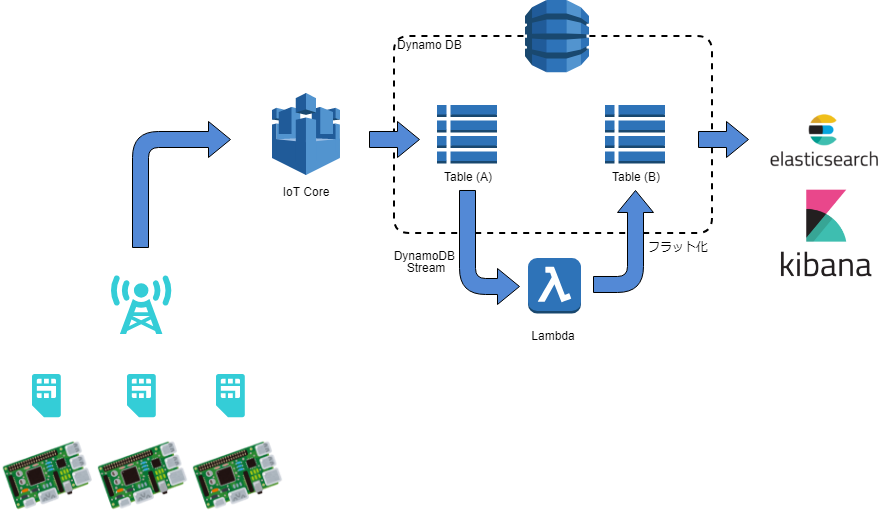
定期バッチ処理なども検討しましたが、取りこぼしなく処理することを考えるのが面倒なので、DynamoDB Streamがうってつけでした。
とんでもないキャパシティが要求された
テーブル(A)のストリームイベントをトリガーにLambdaを起動し、加工したデータをテーブル(B)に投入したところ、事件が起こりました。Auto Scalingを利用していたのですが、みるみるうちに容量がうなぎ登りとなり、**キャパシティが5,000を超えてしまいました!**見積額が月額$2,000越え!(涙)
原因は「水平トリム」の利用だった
どう考えても机上の計算をかるく5倍は上回りそうなので悩みましたが、原因はこれでした。
LambdaのトリガーにDynamoDB Streamを設定する際に「開始位置」というのを指定しますが、「水平トリム」と「最新」が選択できて、デフォルトは「最新」です。
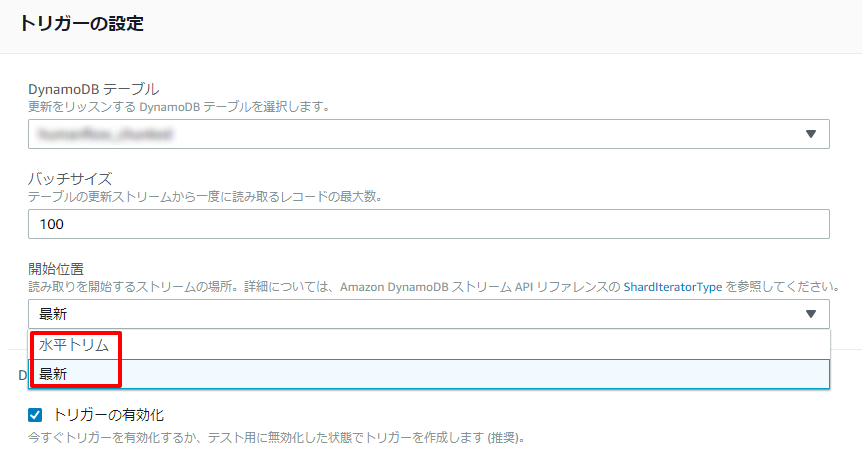
本家のドキュメントが非常に分かりにくいのですが、「最新」はストリームの新しい方を優先して処理、「水平トリム」は古い方から時系列順に処理するということのようです(この辺はもっと詳しい方がいたら教えてください)。
センサーデータは24時間常時飛んでくるので、時系列順に処理した方が良いだろうと「何となく」思ってしまった自分は「水平トリム」を選択しました。
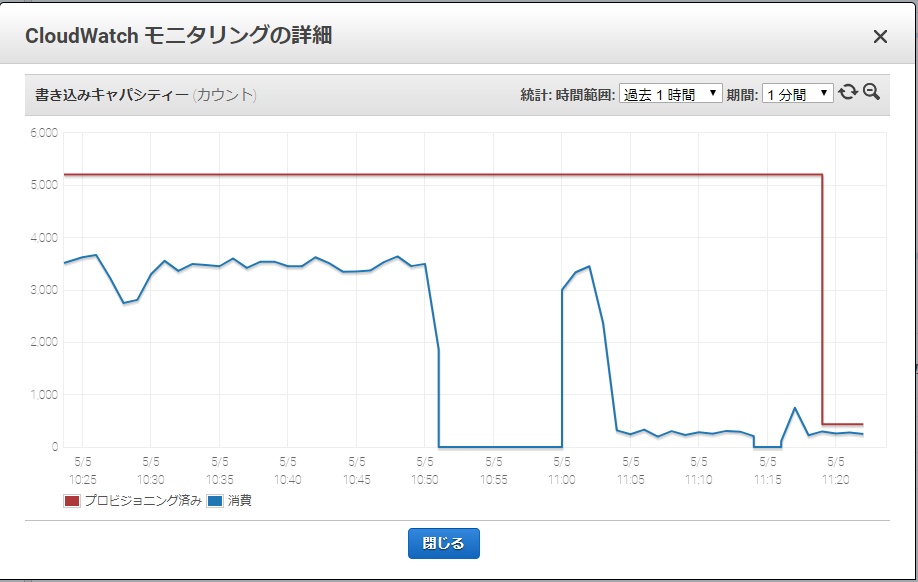
問題の原因を探るべく、書き込み側のテーブルBを確認したところ、なんと1日前のデータが投入されているではないですか!
自分はてっきりトリガーを購読した時点からのデータがストリームで飛んでくるのかと思ったら、なんと24時間も前のデータから飛んできているようでした。そこから最新のデータに追いつくべく、超高速でストリームイベントが飛んでくるので、それを書き込む側のテーブルのキャパシティがすごいことになってしまったと言うことでしょうか。
その後、開始位置を「最新」にしたトリガーを作り直して設定したところ、キャパシティは一気に400程度まで落ちてくれました。(途中ゼロになったりしたところは、トリガーを一時的に無効にしたり試行錯誤をした形跡)
まぁ、「水平トリム」のままでも、そのまましばらく放置すれば、いずれは最新データに追いついて、その時にはキャパシティは落ち着くとは思うのですが、こういう問題もあるみたいなので、一時的にでも不必要にキャパシティを上げるのは望ましくはないとは思います。
いろいろ調べると、DynamoDB Streamは内部的に24時間分のデータを保持しているようなのですね。開始位置を「最新」のままで使った場合には、恐らく過去のデータは捨てられると思いますが、今回は今現在から以降のデータが取れれば良かったので、めでたく解決です。いや、焦りました!
よほど過去の更新データ(といっても最大24時間ですが)が重要な場合以外は「水平トリム」は使わないのが無難かもしれませんね。