3次元ガウシアンスプラッティング アルゴリズム解説
バキューン!株式会社センシンロボティクス、ハチャメチャ元気系OL部第一ヒヤシンス組(組織名は仮称)、Mas-Sensynです。
動画からきれいな3次元復元結果ができることで2年ほど前から非常に流行っている3D Gaussian Splatting(3DGS)ですが、その理論をさくっと短時間で読めるように解説した記事があまりないので、解説することにしました。
短時間で3DGSの理論を学べることをこの記事の目的とします。
下図はオフィスにあるフェイクツリーを3DGSしたものです。きれいですね(「きれいだ」、「きれいじゃない」、みたいなネタが数年前に流行りましたね)。

背景: 先行研究NeRF
Neural Radiance Fields (NeRF) [7]は高品質でフォトリアリスティックなレンダリングを実現しましたが、大きな性能上の制約があり、品質と速度のトレードオフが生じていました。
下図はNeRFのアルゴリズムを表す原論文の図です。
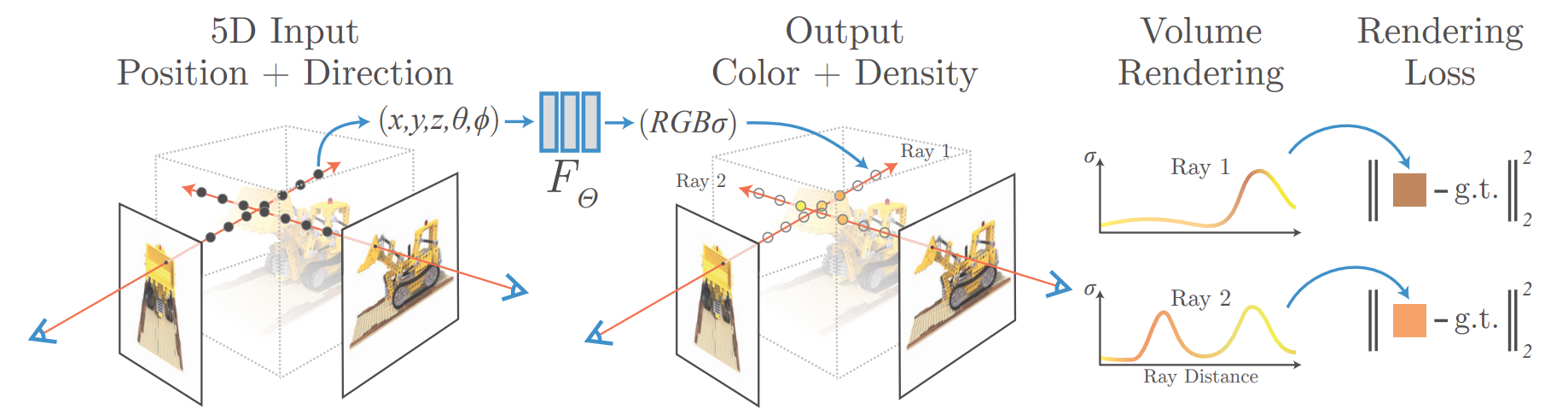
NeRFのボトルネック:
- 暗黙的表現: シーンデータがニューラルネットワークに符号化されており、低速で繰り返しのクエリが必要。
※注: NeRFも、各3D点の体積密度σをMLPで学習することで密度場として形状を暗黙的に表現するため、3次元復元は可能です。ただしメッシュ等の明示的形状を得るにはMarching Cubes等の事後処理が必要です。
- レイマーチング: カメラレイに沿った点の逐次サンプリングは計算コストが高く、空の空間で無駄な計算が発生しがち。
目的
3DGSアルゴリズムの目標は、リアルタイム性能を確保しながら高い視覚品質を達成することです。
-
リアルタイム描画性能: インタラクティブな体験のために30 FPS以上の速度を達成。
-
高品質: 最新のNeRF派生手法が達成したフォトリアリスティックな視覚的忠実度を維持または超越。
-
高解像度: 現代のディスプレイに適したレンダリング解像度を目標。
キーアイデア
明示的に3次元の世界を3Dガウス分布の集合として表し、それを2次元に描画した結果と取得した画像を比較して差が少なくなるようにパラメータを学習し、GPU並列処理で高速化します。
全体アーキテクチャ
3DGSは、学習と描画のステップがあります:
-
学習: 画像から明示的な3Dガウシアンプリミティブを初期化し、精緻化。パラメータ ($\mu, \Sigma, \alpha, SH$) はバックプロパゲーションで最適化。
-
描画: 高速なGPUパイプラインがガウシアンを2Dに投影してブレンド。プロセス全体で勾配がジオメトリに逆伝播可能。
下図は原論文に記載されている学習の全体フロー図で、描画はその一部として、左から右に流れる矢印で表されるものです。

学習:初期化
学習プロセスは、疎なStructure-from-Motion (SfM) 点群を、完全に学習可能な以下のパラメータを持つ3Dガウシアンに変換することから始まります:
※注: SfMは必須ではなくランダム初期化でも動作しますが、SfMを用いることで収束が速く精度も向上するため採用されています。(参考文献[1] Fig. 7にSfMあり/なしの比較があります。)
-
位置 ($\mu$): プリミティブの中心。
-
共分散 ($\Sigma$): 異方性の形状(分散行列は伸縮/回転で代替される)。
-
色 (SH): 視点依存の外観(球面調和関数係数とすることで、視点依存の外観を表現する)。
-
不透明度 ($\alpha$): 透明度。
学習:適応的密度制御
最適化中に位置勾配に基づいてジオメトリを動的に調整し、細部を捉えます。その際にGaussianの数に対して以下の操作を実行します:
-
クローン(緻密化): 再構成が不十分な領域(位置勾配が大きい)でガウシアンを複製。
-
分割(精緻化): 大きくぼやけたガウシアンを2つの小さなものに分割し、細部にフィット。
-
プルーニング: 不可視または過大なガウシアンを削除し、ノイズと計算コストを削減。
描画(ラスタライゼーション)
レンダリングプロセスは、GPU上で速度に最適化されたカスタムのタイルベースラスタライザです。画面を16×16ピクセルのタイルに分割し、各タイルを独立したGPUスレッドブロックで並列処理することで高速化を実現しています。原論文では1080p(1920×1080)解像度で100 FPS以上を達成しています。
※注: 16×16ピクセルの根拠:原論文[1] Section 5では「16×16 tiles」と記載。公式実装[6]の
cuda_rasterizer/config.hにて#define BLOCK_X 16、#define BLOCK_Y 16と定義されており、1スレッド=1ピクセルのため16×16ピクセルとなる。
-
カリング: カメラの視錐台(view frustum)外のガウシアンを除去。99%信頼区間が視錐台と交差するガウシアンのみを保持。
-
投影: 残った3Dガウシアンを2Dスプラットに投影し、各スプラットがどのタイルと交差するかを計算。
-
ソート: 可視スプラットを深度で効率的にソート(GPU基数ソート)。タイルIDと深度をキーとしてソート。
-
アルファブレンディング: 各タイル内で、色 ($c_i$) と不透明度 ($\alpha_i$) を前から後ろへ合成:
$$
C = \sum_{i \in N} c_i \alpha_i \prod_{j=1}^{i-1} (1 - \alpha_j)
$$
評価と結果
3DGSは高品質なNeRF手法より桁違いに高速なリアルタイム性能を達成しながら、視覚的忠実度も同等です。
| 手法 | 速度 (FPS @ 1080p) |
|---|---|
| Mip-NeRF 360 | 0.06 FPS |
| Instant-NGP | 12 FPS |
| 3DGS | 130+ FPS |
※注: 出典は[1] Table 1.
主要な貢献
3DGSアプローチの3つの主要な革新点:
-
新しいプリミティブ: シーン表現として明示的で異方性の3Dガウシアン。
-
適応的ジオメトリ: 学習中にパラメータ最適化と緻密化・プルーニングを交互に実行し、ガウシアン数を動的に調整。
-
高速パイプライン: リアルタイムの学習とレンダリングのための、可視性を考慮した微分可能GPUラスタライゼーション。
最近の発展
この分野は新しい応用と効率改善で急速に進化しています:
-
動的シーン (4D): 非剛体運動する被写体のモデリング。4DTAM: Non-Rigid Tracking and Mapping via Dynamic Surface Gaussians, H.Matsuki et.al., CVPR 2025.
-
セマンティック編集: テキストプロンプトや拡散モデルによるシーン編集。GaussianEditor: Editing 3D Gaussians Delicately with Text Instructions, J.Wang et al., CVPR 2024.
-
効率化: メモリフットプリント(モデルがメモリ上に残す恒常的な占有サイズ)の削減。Compact 3D Gaussian Splatting for Static and Dynamic Radiance Fields, Lee et al., CVPR 2024.
-
3D生成: ガウシアン事前分布を用いたText-to-3D生成。DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation, Tang et al., CVPR 2024.
結論
3DGSは、暗黙的なニューラルフィールドを、明示的でラスタライズ可能なプリミティブに置き換えることで、新視点生成の重要な課題を解決しました。これにより、リアルタイムでフォトリアリスティックな3Dシーン再構成とレンダリングが可能となり、ロボティクスや没入型技術の新たな道を開きました。
参考文献
さらに詳細を知りたい方は以下のリンクを見ることをお勧めします。
[1] 原論文
[2] 論文アルゴリズム解説動画
[3] 講義動画
[4] gsplat実装解説動画
[5] OpenCV解説
[6] 公式実装 diff-gaussian-rasterization
[7] NeRF原論文