DBエンジニア必見 => 名著「失敗から学ぶRDBの正しい歩き方」のまとめ
現職でDB設計やSQLを書く機会も多いのですが、RDBのアンチパターンを深く理解することでより良い設計やSQLを書けるのではないかと思い名著「失敗から学ぶrdbの正しい歩き」を読みました。
各項目がわかりやすく説明されており、非常に勉強になりました。
内容を忘れない為にも学んだ内容をまとめます。(めちゃくちゃ長いですw)
対象読者
1. DB設計をする人
2. サーバーサイドエンジニア
3. SQL職人
4. インフラエンジニア
第1章「データベースの迷宮」
プログラミングでは度々話題になる名前付けやクラス設計ですが、データベースでも同じくとても大切です。
例)悪い命名規則
1.memo1、memo2、memo3……と無限に続く、何が入っているのかわからないカラム
2.「hoge_data」のタイピングミスで「hoge_date」になり、意味が変わってしまっているカラム
3.中に入っている値の意味がわからないカラム
4.外部キー制約がなく、リレーションシップがまったくわからないテーブル
このような状態のままDB設計を進めてしまうと以下のような問題が起こってしまう。
1、2、3の問題-> 不適切な名前では、データベースのテーブルの関連性や意図が理解できない。
保存されたデータが正しいかどうかが判断できない。
4の問題-> リレーショナルモデルに基づいた設計をしていないと、既存の便利なツールを利用できない。
どのようなデータを保存し、どのようなデータを取り出せば良いかわからない
こうなってしまうと、後々にDB保守するフェーズで多大な労力が必要になる。
ブラックボックス化したデータベースに対する改修は影響範囲が読めないため安易に変更できないからです。
このような状態にならないために大事なポイント
1. 命名ミスは初期段階で対処にする
2. 今後を想定した命名にする
わかりずらい設計や名前はデータベースの破綻の始まりです。
第2章「失われた真実」
RDBでは履歴テーブルが必要になるケースが多いです。
履歴テーブルの保存を怠ると以下のようなケースに遭遇してしまいます。
1.このデータがどのようにして今の値になったかわからない
2.ある日を境に売上データと商品マスタの単価データが合わない
3.払い戻しの処理が特別対応となる
一方、履歴テーブルを作ることによって以下のようなデメリットもあります。
1.レコードの保存量が増えるためテーブルサイズが増える
2.集計が単純な主キー検索ではなくなるため、テーブルサイズが肥大化した際に検索速度が劣化する
履歴テーブルの作成はパフォーマンスとトレードオフの関係になっています。
ちなみに履歴テーブルの名称は語尾にhistoryとつけるのが標準になっているようです。
第3章「やりすぎたJOIN」
JOINは非常に便利ですが、以下のような知識もない状態でJOINを利用してしまうとパフォーマンスが著しく落ちます。
1.JOINに対する不理解
2.多段JOINと不要なJOIN
3.JOINの内部表にINDEXがない
ステージング環境などのデータが小さい場合は問題がなくても、本番環境の大きなデータではサービスに影響を与えるほど大きな負荷になるケースが多いので気をつけましょう。
ちなみに僕がよく利用しているRailsはORM機能が優秀でSQLを意識せずにかけるのですが、実は多段JOINを利用しているケースが多々あるのでアプリケーションFWを利用している場合でもJOINは意識すべきと個人的には思います。
Railsでto_sqlというメソッドを利用すれば、実際のSQLを確認できますよ!
JOINについて
JOINには以下の3パターンがあります。
それぞれの特徴は必ず理解しましょう。
1. INNNER JOIN
2. LEFT OUTER JOIN
3. RIGHT OUTER JOIN
4. FULL OUTER JOIN
JOINするテーブルが2つ程度なら問題ありませんが、JOINの回数が増えると急激に重くなるのがJOINの特徴です。
JOINは掛け算と言われます。テーブルスキャンの場合、100行と100行のJOINの場合は10,000行のテーブルスキャン相当ですが、10,000行と10,000行ではなんと100,000,000行です。
このようなケースは必ずINDEXを貼ることが重要です。
たとえば、100行と「一意なINDEXが貼られた100行」の場合は、100行+(100×1)行となり200行相当です。INDEX1つでこのように大きく計算コストが変わるのです。
JOINのアンチパターンの対策ポイント
1.JOINは必要最低限
2.INDEXを適切に活用する
3.JOINするテーブルは小さくしてからJOINする
4.複雑なクエリになった場合はViewを活用する
第4章「効かないINDEX」
INDEX(索引)とはテーブルからデータを高速に取り出すためのRDBMSのしくみです。INDEXを適切に作成し、さらにそれを検索時に利用することでクエリの高速化が実現されます。
※ちなみにINDEXはRDBMSによって実装方法が異なるので注意です。(MySQLとPostgreSQLでは実装が違う)
一般的にRDBMSで利用されているINDEXはBTreeINDEXになります。
INDEXの仕組みを理解せずに闇雲にINDEXを貼ると、データの変化によってINDEXが利用されないなどのアンチパターンを生むケースが多いです。
アンチパターンを防ぐには以下のポイントが重要になります。
1.INDEX(とくにBTreeINDEX)の特性をしっかりと把握して適切なINDEXを設定する
2.INDEXを利用できるクエリを実行する
3.INDEXを活用できるテーブル設計をする
4.スロークエリログやデータの状態などをしっかりとモニタリングする
また、INDEXが効かない(使われない)ケースもあるので、どんな時にINDEXが使われないかを知ることも大事です。
1.検索結果が多い、全体の件数が少ない
2.条件にその列を使っていない・カーディナリティの低い列に対する検索
3.あいまいな検索
第5章「フラグの闇」
実務を経験すると、以下のようなケースに削除フラグを利用したくなるケースが多いです。
・エンドユーザから見えなくしたいが、データは消したくない
・削除したデータを検索したい
・データを消さずにログに残したい
・操作を誤ってもなかったことにしたい
・削除してもすぐに元に戻したい
論理削除は簡単に実装できるので容易に「じゃあ論理削除するか」となるのですが、容易に削除フラグを付けてしまうと、以下のようなRDBの問題が発生します。(耳が痛い話です...)
1.クエリの複雑化
2.UNIQUE制約が使えない
3.カーディナリティが低くなる
■ 削除フラグを利用すると、関連するテーブルすべてに影響を与える形になり、アプリケーション開発時のコストが増大します。
■ 削除フラグを利用するとUNIQUE制約が使えなくなります。
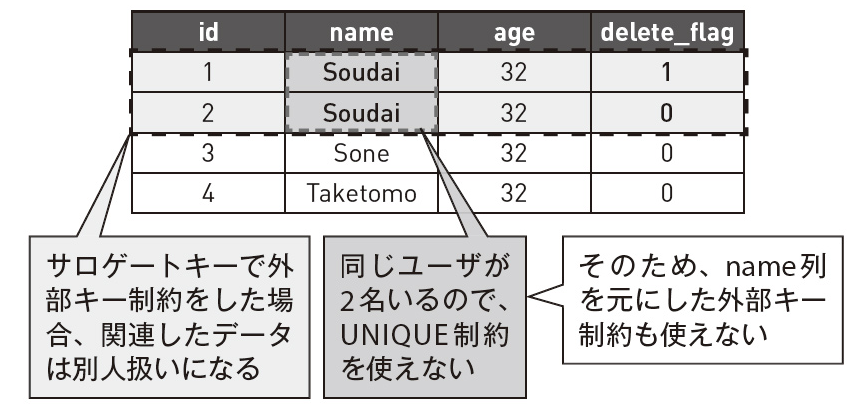
UNIQUE制約が利用できなくなると以下のような不都合が生まれます。
・データの重複を防げない
・該当列に対して外部キー制約を利用できない
・外部キー制約を利用できないことでデータの関連性を担保できない
■ 削除フラグの多くは、未削除(delete_flag=0)の状態であり、削除フラグの列ではデータが重複し、カーディナリティが低くなります
このようなアンチパターンを防ぐために重要なのポイントが以下になります。
事実のみを保存する
事実のみを保存しましょう。例えば削除ユーザーはフラグで状態管理するのではなく、別モデルに移すことが有効です。
個人的には論理削除するより、別モデルに移動させる方法が論理削除よりベターだと思います。
理由はクエリもシンプルを保てる、なおかつ実装もシンプルを保てるからです。
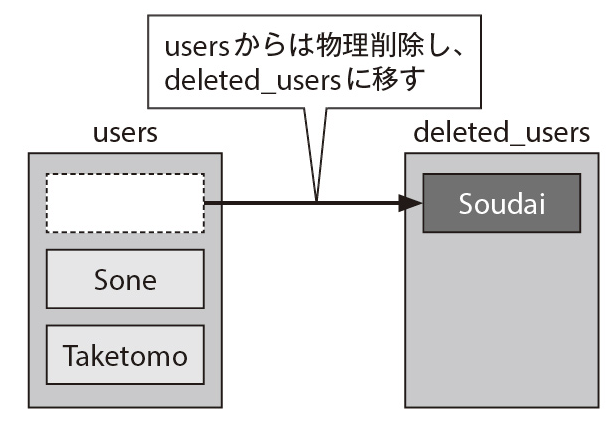
もし削除フラグで状態管理する場合は以下のケースに注意して利用しましょう。
・対象のテーブルが小さく、INDEXが不要
・そのテーブルが関連するテーブルの親になることがなく、データを取得する際に頻繁にJOINの対象になることがない
・UNIQUE制約が不要で、外部キーでデータの整合性を担保する必要がない
第6章「ソートの依存」
ソートはとても便利なRDBMSの機能ですが、パフォーマンス面で考えるとRDBが苦手とする分野です。
RDBMSでorderbyで並び替える時は以下のような挙動で動きます。
全てのデータを取り出してから、order byで並び替え、最後にlimtで必要なデータを切り分けるような仕組みになっています。
例えば以下のようなSQLの場合はデータを取り出してからバラバラのデータを並び替えるため、ソートは高コストな処理になり、データ数が大きくなればなるほど、重い処理になるという特徴があります。
SELECT <--- 3番目に処理
*
FROM <--- 1番目に処理
users
WHERE <--- 2番目に処理
id < 1000
ORDER BY name <--- 4番目に処理
LIMIT 100 <--- 5番目に処理
では、どのようにしてSQLを改善すれば良いのでしょうか? order byを早くする方法
1. データを小さくする
2. INDEXを活用する
データを小さくする方法としてidを指定してソートを高速化する方法があります。
SELECT
*
FROM
"発注履歴"
WHERE
"発注日時">(now()+'1year');
ANDid>:前の表示ページの最後の行のid <-- ※1
ORDERBY
"発注日時"DESC;
LIMIT
100
※1 アプリケーション側で「次のページ」として渡すのはOFFSETの値ではなく、最後に表示された行のidにすることですばやく絞り込めます。(発注日時が順にINSERTされるのであれば、idも発注日時も同時に並んでいるという法則を利用)
ORDERBYは、データが大きくなればなるほど重い処理になります。ですが事前にWHERE句を使えば、対象を絞り込むことができます。
たとえば、1億件のレコードを並び替えるのと、それを1,000件に絞り込んでから並び替えるのとでは、同じORDERBY後に100件を取り出すとしても、処理時間が雲泥の差です。
ですので、WHERE句のINDEXを活用し、データを十分に小さくした後にorderbyするとパフォーマンスは劇的に向上します。
例) SELECT*FROMusersWHERE性別=‘男性’ORDERBY出身県idLIMIT5
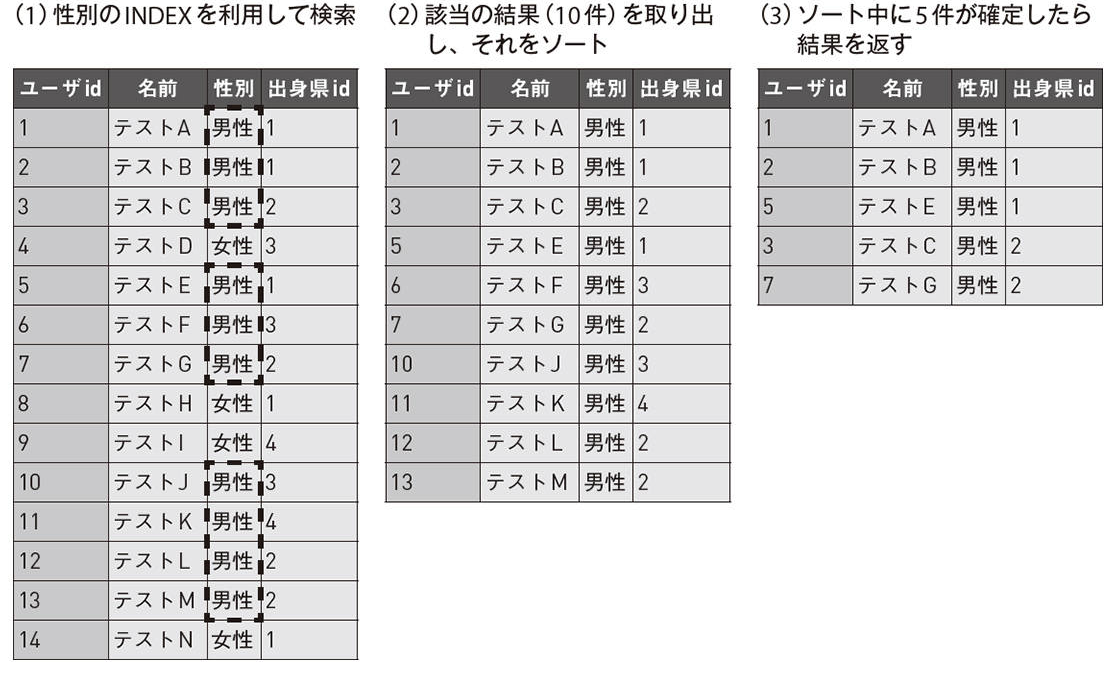
該当の結果の10件に対してsortしているので、全件に対してsortするよりパフォーマンスは大幅に向上する。
■ 大きなデータをどうしてもsortしたい場合
どうしても大きなデータをsortする場合は以下の方法でもOK
1. アプリ側でソート
2. ソート済みの結果をキャッシュ
3. NoSQLなどを利用してソート
第7章「隠された状態」
RDBに状態を持たせるのはたいへん危険です。
データにビジネスロジックを持たせたり、複数の意味を持たせたりすると、一見しただけでは本来の状態を読み取れないデータになってしまいます。(これが隠された状態です)
隠された状態になるとどうなるのか?
1. 運用コストが跳ね上がる
2. 仕様変更コストが跳ね上がる
3. バグ発生時の対応が難しい
4. 不正データが入っても気付きにくい
アンチパターンを生まないためのポイント
1.データに複数の意味を持たせない
2.1つのデータの責務を小さくする
3.常に状態が見えるようにするために事実のみを保存する
特に3の事実のみを保存するのはRDSでは重要な項目です。
事実以外(複雑なビジネスロジック)をデータに持たせてしまうと、データの中身がブラックボックスになってしまい所謂隠された状態になってしまいます。
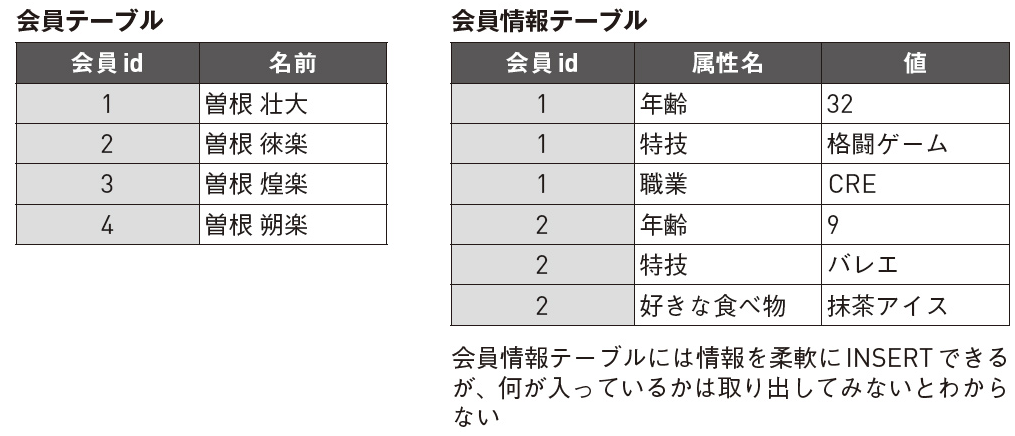
RDBの設計の際、、汎用性を高める設計を目指した場合にたびたび陥る罠として、**「EAV」「PolymorphicAssociations」**もアンチパターンの例として本書で挙げられています。
■ EAV
-> 複数の目的に使われるカラムを用意する設計。
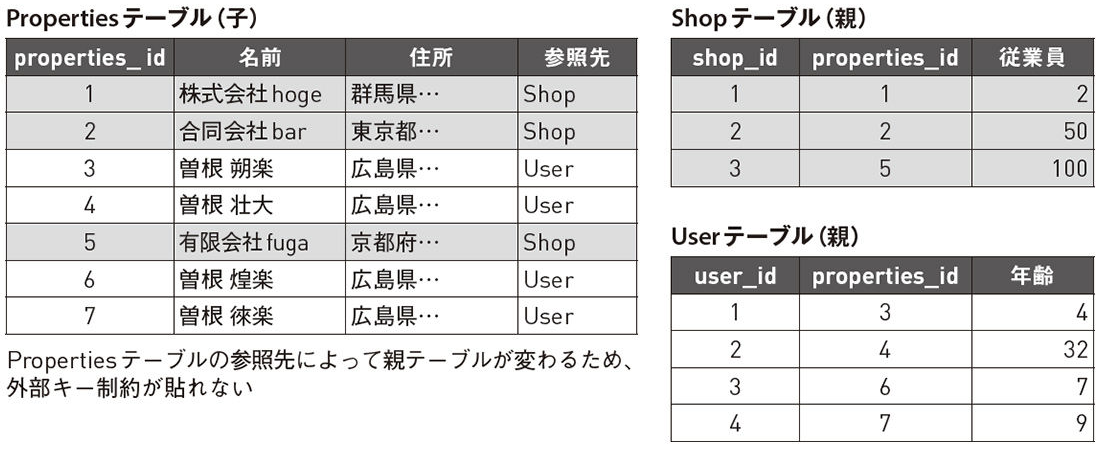
■ PolymorphicAssociations
-> 子テーブルが複数の親テーブルを持つような設計
第8章「JSONの甘い罠」
最近のMySQLやPostgreSQLなどのRDBMSではデータタイプにJSONで保存することが出来ます。
JSONで保存することで、簡単にスキーマレスな設計を実現することができます。
しかし、JSONを利用することで以下のようなデメリットもあります。
1. SQL検索が難しくなる
2. ORMが使えない
僕が好きなRailsを含め多くのORM(Objectrelationalmapping)はJSONデータ型をサポートしていません。
またそもそも、JSONを取り出すためのSQLを表現することがたいへん難しいです。
そのためJSONデータ型に頼ったDB設計をしてしまうと、一時的に開発工数を下げることができたとしても、将来的には開発工数が激増することが多々あります。
ですからJSONデータ型を取り出す方法、保存する方法との相性についても検討することが必要です。
JSONデータ型は汎用性が高く便利ですが、RDB本来の責務であるデータを守ることが難しくなってしまうというデメリットもあります。
では、どんな時にJSONデータ型を利用すべきなのでしょうか?
1.JSONそのものに対応している
2.スキーマレスに値を保存できる
「WebAPIの戻り値」「PHPのComposer(設定ファイルがJSON)」といった値は、JSONそのものに対応しているのでJSONで保存すべきです。
逆に以下のような条件に当てはまる場合はJSONデータ型を採用すべきではありません。
1.正規化することはできないか
2.JSONに対して頻繁に更新を行いたいか
3.検索条件としてJSON内の属性が固定できない場合
第9章「強すぎる制約」
RDBMSを使う理由はACID※1を担保すること、つまり規約が大きなメリットと言えます。
しかし強すぎる規約は時にして毒になるケースもあります。(強すぎる制約はパフォーマンスや仕様変更のボトルネックになるケースがあります。)
※1 Atomicity, Consistency, Isolation, Durabilityの頭文字をとった、DB規約の一種
では、規約は必ずも悪なのかというとそういうわけでもありません。
適切なCHECK制約や正規化などは不正データの保存を防いでくれます。
しかし、データは“成長する生き物”ですので、変化に対応しなければいけません。そこで制約が足かせになることは、本末転倒です。

制約をつけるときは上記の図の強すぎる制約になっていないか?と考えるときは、事実に基づいて範囲内に収まっているかを問うことが大事です。
もし、範囲を超えている場合はもう少し弱い規約に変更することも検討してみましょう。
多くのシステムは適切な正規化と弱い制約で十分に設計できます。
絶対に守る必要があるデータに対してのみ強い制約を指定することで、より良いDB設計を作ることができるのです。
この匙加減を間違えると、制約を極端に避けたり、逆に制約に依存して強過ぎる制約を作ったりしてしまいます。
第10章「転んだ後のバックアップ」
バックアップの必要性は言うまでもありません。
ただ、間違ったバックアップ運用を行っている企業も多いです。
バックアップ種類には大きく分けて以下の3つのパターンがあります。
1. 論理バックアップ
-> 論理バックアップは、SQLやCSVとして、DBそのものを再構成できるようにバックアップを取ることです。論理バックアップの実地はテキストなので、中身の確認や編集が可能。ただ、ファイルサイズがでかい
2. 物理バックアップ
-> 物理バックアップは、データベースの物理ファイルをまるごとバックアップする手法。最小限のサイズで取得できて、リストアの時間が短い。ただ、バージョン違いで互換性がないことが多い。
3. PITR
-> PITRは、特定の日時の状態にデータをリストアできる手法のことを指します。たとえば「2017/11/2603:43」に障害が発生した場合に、直前の「2017/11/2603:42」の状態にリストアすることができます。ただ、バックアップのサイズがでかい
まとめるとこんな感じ
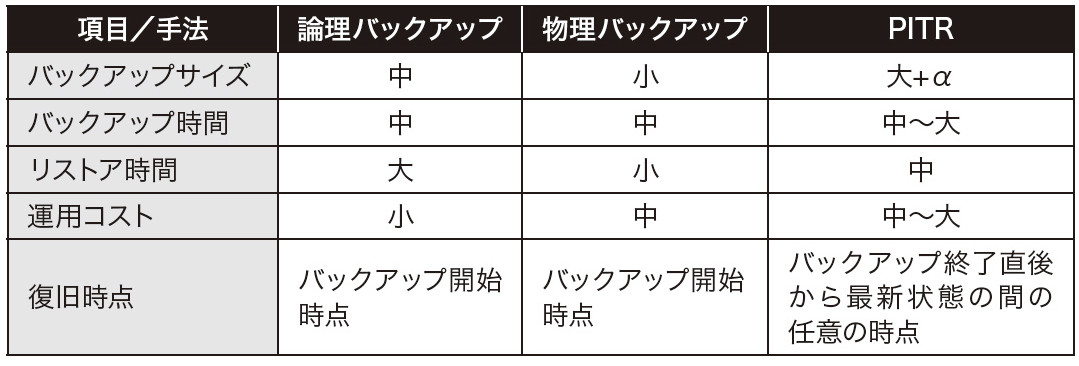
バックアップ運用を決める際に重要な3つの指針があります。
1. RPO:復旧できるデータ
2. RTO:復旧までにかかる時間
3. RLO:復旧したいデータ

RTOとRLOによって、バックアップ設計が決まります。その際の判断基準が稼働率です。

でも、AWSとかにはレプリケーション機能とかあるし、そもそもバックアップは必要ないのでは?
結論から言うと、レプリケーションでは以下のような対応できないケースもあるのでバックアップは必要です。
1.アプリケーションのバグによるデータ破壊からの復旧
2.不正なデータ投入からの復旧
3.ヒューマンエラーからの復旧
4.レプリケーション破壊といったシステム破壊からの復旧
間違ったバックアップ運用をしないために重要なこと。
1.バックアップが正しく行われていることを毎回確認し、失敗したときに必ず気付けるようにする
2.リストアを定期的に行う
3.手順書をまとめる。ベーシックな手順だけではなく、実際のユースケースに則したパターンをいくつか用意すると良い
ちなみにバックアップ運用が面倒な場合はAWSがオススメです。
たとえばAmazonRDSを使えば、バックアップとしては1日1回のフルバックアップと5分おきの更新情報が含まれたログのバックアップが行われています。
そのためPITRを非常に簡単に運用することができ、リストアもWebUIから簡単に実行できます。
AWSは神です。
第11章「見られないエラーログ」
ログはシステムの振る舞いを教えてくれる大切な存在です。
しかし、エラーログが出ててもシステムが稼働している場合は「まあ。動いてるから大丈夫か!」とエラーログを見て見ぬ振りをするケースが散見されます。(自分にも身に覚えがあるので、耳が痛い話です....)
エラーログはRDBMSに限らず、ミドルウェアやアプリケーション全般において、重要な警告です。これを無視することは、大きな問題を未然に防ぐチャンスを自ら潰していると言えるので、エラーログ対応は必須です。
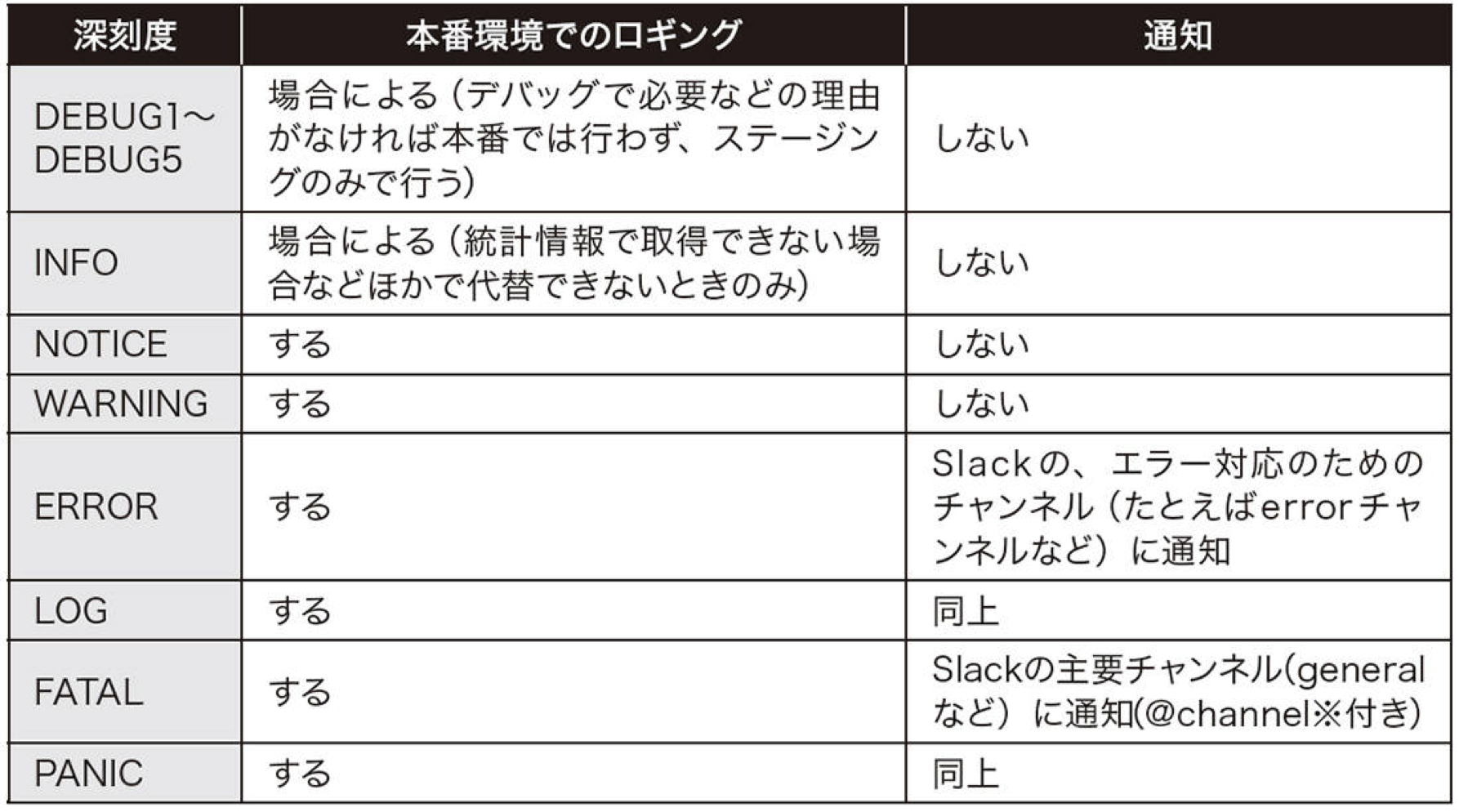
例えば、僕がよく利用しているPostgreSQLのエラーログは下記のようになっています。(メッセージ深刻度レベル)
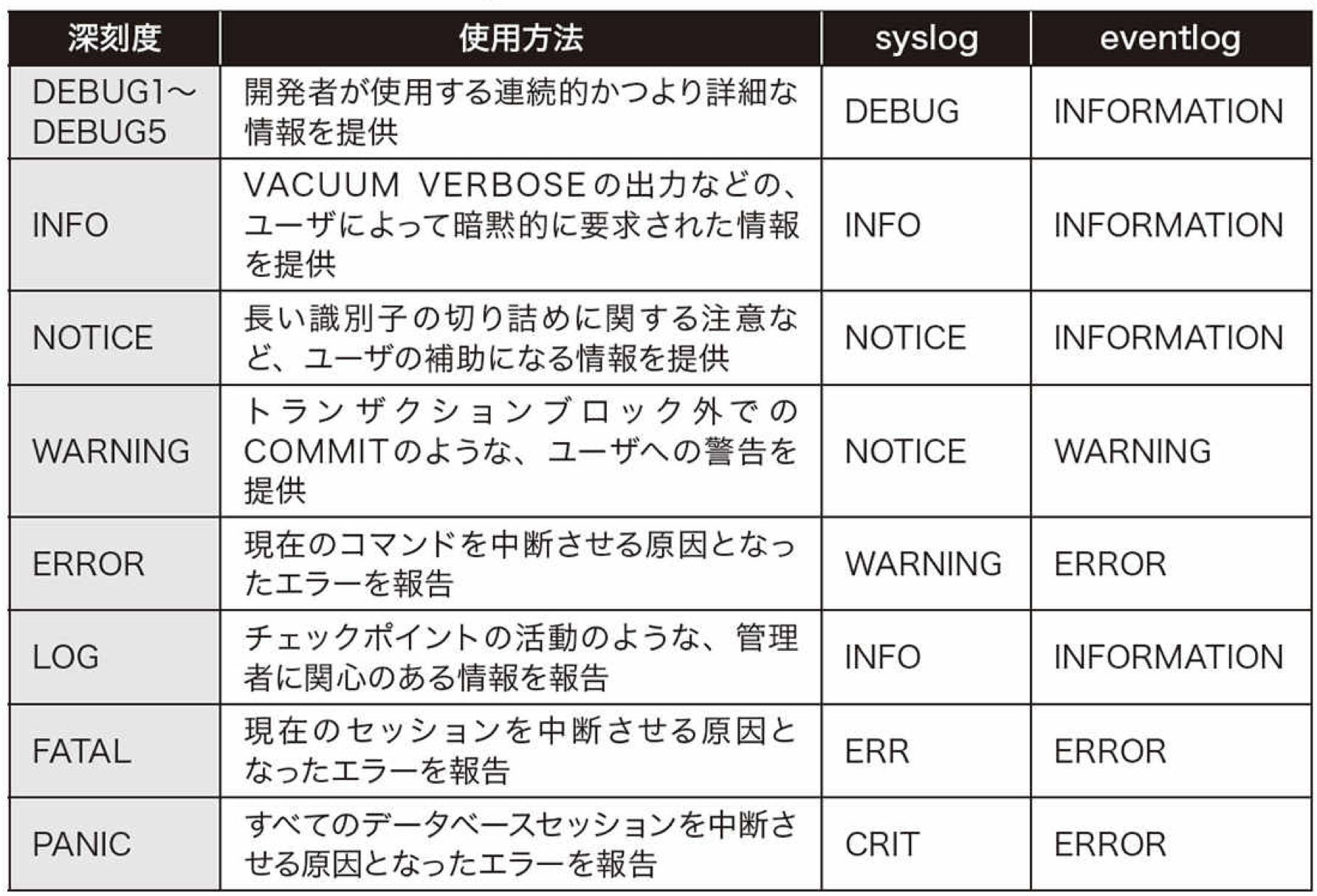
■ PostgreSQLのエラーログ設定
logging_collector=on#logの有効化
log_line_prefix='[%t]%u%d%p[%l]%h[%i]'#logの出力時のフォーマットの指定
log_min_duration_statement=<許容できないレスポンス時間(ミリ秒)>
log_min_error_statement=error#出力したい深刻度レベル#指定された深刻度レベルよりも重要なレベルが出力される#この場合、ERRORLOGFATALPANIC
参考:https://www.postgresql.jp/document/9.4/html/runtime-config-logging.html
このような設定をしておくことで、エラーログで重要な事故を事前に気づくことが出来ます。
また、ログレベルによって、通知設定をしておくことで重要なエラーログの時はすぐに現象に気づくような環境設定をすることが大事です。
第12章「監視されないデータベース」
第11章のエラーログの監視と同様に、RDBMS自体もモニタリングをする必要があります。
日常的なモニタリングをしていないと、障害を予想できなかったり、対応することが出来ません。
モニタリング方法は大きく分けて3つあります。
1.サービス(プロセス)の死活監視
-> サービスやプロセスの死活監視は「いち早く障害発生を確認できるようにするため」に必要な監視
2.特定条件のチェック監視
-> チェック監視は「特定の条件を設けて、障害を未然に防いだり、復旧にいち早く取り掛かれたりするようにするため」に必要な監視
3.時系列データをもとにしたメトリックス監視
-> 状況の変化を時系列で管理することで、キャパシティプランニングや障害の予兆の把握に役立てるために必要な監視
監視ステップとしては1->2->3というような順序になっています。
モニタリング監視対象
【OS側】
・ディスクI/O
・ネットワークトラフィック
・CPU利用率
・メモリ利用率
【RDBMS側】
・SELECT/INSERT/UPDATE/DELETEなどのSQLの実行量
・実際に読み込まれているレコードの量
・インデックスヒット率・デッドロックの有無
・テンポラリファイルの作成の有無
・ロックの量と時間
モニタリング文化がない企業は、まずはモニタリングする文化作りから始めることが大事です。
第13章「知らないロック」
RDBMSのロックはトランザクション中のデータを守るための大切なしくみです。しかし、意図しないロックはパフォーマンスに大きな影響を与え、時にはデッドロックを起こします。
楽観的ロック、悲観的ロックとは?
https://qiita.com/merrill/items/d9d41d64df292bd6432a
デットロックとは?
https://wa3.i-3-i.info/word11317.html
■ デットロックが起きる経緯

①自分が1巻を確保する
②友人が2巻を確保する
③自分が2巻を確保しようとするが、友人が2巻を確保しているため、自分は2巻が返されるのを待つ
④友人が1巻を確保しようとするが、自分が1巻を確保しているため、友人は1巻が返されるのを待つ
⑤お互いがお互いの本の返却を待ち、どちらも読み始められない
このデットロックを起きないようにするには?
-> 自分も友人も必ず1巻から確保する
こんなように、意図しない箇所でデットロックがかからるケースがあるので注意が必要です。
デットロックが起きなようにするにはRDBMSの仕組みを理解することが大事です。
また、RDBMSによってロックに違いがあるので注意が必要です。
PostgreSQLのロック
https://qiita.com/kiyodori/items/7da3e34ca2ff9f5668c4
第14章「ロックの功罪」
トランザクションにはACID特性があります。

Isolationを完全に担保しようとすると、直列処理で1件ずつ処理する必要があります。
しかし、実際にRDBMSは並列に処理できます。※1
※1(直列処理にしたい場合は第13章で述べたとおり、ロックをかける必要があります。)
なぜか?
それは、全ての処理を並列処理にしてしまうと、パフォーマンスが落ちるからです。
RDMBMSはIsolation制限を緩めて利用しています。
制限レベルとトランザクション分離レベル
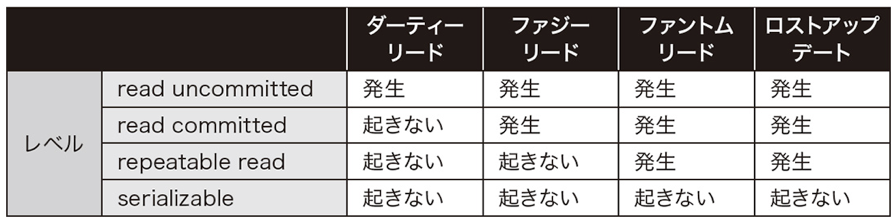
(1)readuncommitted
(2)readcommitted
(3)repeatableread
(4)serializable
下に行くほど、並列度が低くなります。
serializableは完全な直列処理になるためIsolationを担保していると言えますが、その分並列処理はできなくなります。(つまり処理速度が遅くなる可能性がある)
■ ダーティーリード
ダーティリードはほかのトランザクションから自分のコミットしていない変更内容が見えてしまう現象
■ ファジーリード
ファジーリードはノンリピータブルリードとも言います。ダーティリードと違い、ほかのトランザクションのコミットしていないデータは見えない
■ ファントムリード
ファントムリードはほかのトランザクションがコミットした追加・削除が見えてしまう現象
■ ロストアップリード
ロストアップデートは、複数のトランザクションで更新が並列に行われた場合、あとに実行されたトランザクションで結果が上書きされる現象
参考:https://qiita.com/momotaro98/items/ad859ec2934ee98540fb
ロックによるパフォーマンス問題に対して、RDBMSの肝とも言えるトランザクション分離レベルを理解せずにロックをかけてしまうとデットロックになったりします。
第15章「簡単すぎる不整合」
DB設計をするとに大事なのは正しい正規化をすることです。
正しい正規化をすることで、仕様変更に強くデータ不整合が起きにくなります。
正規化は第5正規化?まであった気がしますが。
個人的には第3正規化まで完了していれば問題ないと思います。
この正規化をすることを面倒に思い、実装の都合を優先して非正規化した状態でテーブル設計をしてしまうと仕様変更に弱くデータ不整合が起きやすい状態に陥ってしまいます。(非正規化したテーブルのデータの整合性は、アプリケーションで担保するしかないので、アプリケーションがバグったらデータがすぐ壊れてしまいます。)
ちなみに正規化するのが面倒なパターンはこんな時かなと思います。
・テーブルを作って正規化をするのが面倒なとき
・外部キー制約によってデッドロックなどが発生しているとき
・正規化によってJOINのコストが高くなり、パフォーマンスに問題が出ているとき
正規化せずにアンチパターンを防ぐには以下の2点でアンチパターンを防げるケースもあります。
こちらを利用すれば、テーブルを分けずにデータの整合を保ちやすくなります。(正規化がどうしてもできない場合とかに利用)
1.CHECK制約
2.ENUM型
本書ではRDBは正規化に始まり正規化に終わるといっても過言ではないと言及しています。
それぐらい正規化は大事ということです。
DBの正規化はデータの不整合を起こさないために必要です。
第16章「キャッシュ中毒」
キャッシュは一度利用したデータを保存しておき、再度同様のリクエストがあった際に保存しておいたデータを再利用することで計算処理を省略するしくみです。
キャッシュは手軽に表示速度を爆上げする事が出来ますが、デバックしづらくなるという特徴もあります。
- キャッシュがおかしいのか
- 元データがおかしいのか
- 一時的におかしなデータがキャッシュされたのか
キャッシュ利用すると、この辺の問題の切り分けが難しくなります。
RDBMSでキャッシュを利用するデメリットはキャッシュしたデータの状態を意識することが難しく、参照時にどの状態なのかコード側からは直感的に把握し辛いことです。
それを避けることに大事なのが以下です。
キャッシュと元データの整合性を合わせる
キャッシュの生存期間を決める
キャッシュを正しく読み取る必
もう少し具体的にデメリットを述べると以下です。
参照されたタイミングのキャッシュがどのデータか把握が難しい
どのデータがキャッシュされたか把握が難しい
どこまでキャッシュされているのかの把握が難しい
意図しない結果となった場合、原因がキャッシュなのか元データの破損なのか判断が難しい
ちなみによく利用されるキャッシュの種類は以下
クエリキャッシュ
前回と同じSQLなら、RDBMS側で前回の実行を返すキャシュ
クエリキャシュのデメリットは以下の通り
・実行されたクエリの結果が、キャッシュなのか最新情報なのかわからない
・テーブルが更新されるとキャッシュとして不適切なため、クエリキャッシュはクリアされる
・まったく同じクエリでなければキャッシュされない
アプリケーションキャッシュ
一度RDBMSから取得したデータや作成したデータをアプリケーションのキャッシュとして利用できる。
保存先としては、アプリケーションのプロセス内、ファイル、memcached、Redisなどがあります。
アプリケーションキャッシュのデメリットは以下の通り
・汎用的で自由度の高いゆえに、状態の管理が難しい
・容易に作成・呼び出しが行えることから意図しないキャッシュを呼び出しがちになる。
・個人情報などの「見えてはいけないデータ」が見えてしまうケースがある
キャッシュのデメリットを理解した上でキャッシュを利用する事が大事です。
キャッシュを利用するときはキャッシュ戦略を決めてから利用する事が大事です。
・キャッシュヒット率や更新頻度を推測、計測する
・キャッシュの対象と範囲を見極める
・キャッシュのキーを決める
・キャッシュの生存期間と更新方法を決める
この辺をしっかりと事前に検討してからキャッシュをは利用しましょう。
第17章「複雑なクエリ」
複雑なコードをスパゲティコードと言いますが、複雑なクエリをスパゲティクエリと呼んだりします。
複雑なクエリが生まれる主な理由は以下になります。
1.スキル不足に起因した、力技による解決としての複雑なクエリ
2.テーブル設計に問題を抱えており、目的を達成するため結果的に複雑になったクエリ
スパゲティクエリを解決するには、クエリを読み解き、リファクタリングすることが必要です。
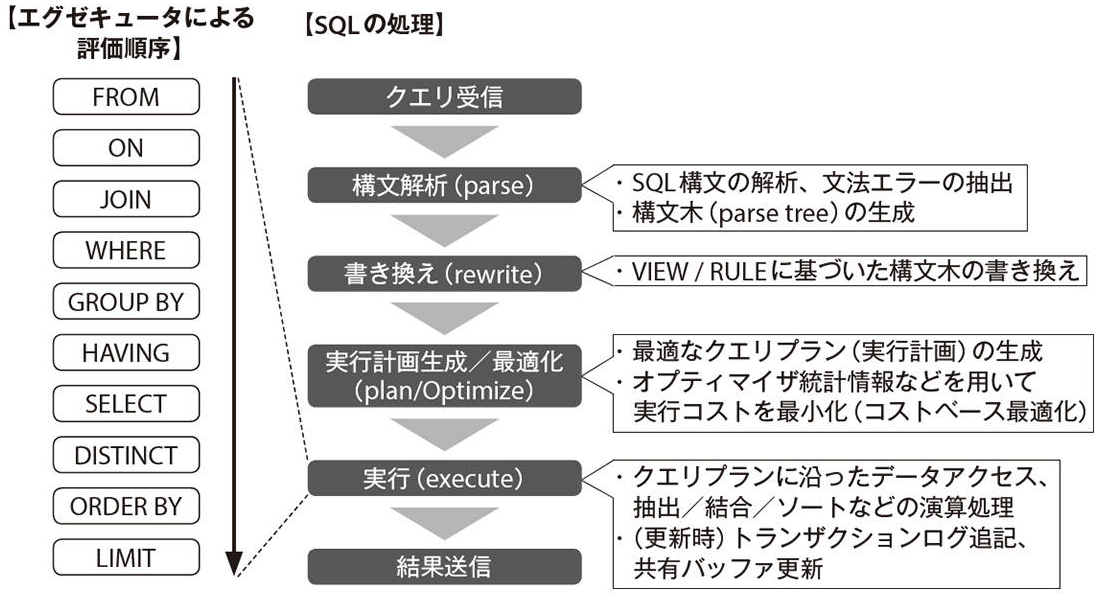
以下のSQL構文評価順にスパゲティクエリを解析して、必要であればパーツを分解することでスパゲティクエリをリファクタリングすることができます。
この順序でSQL実行されるということは覚えておくことが大事です。
①FROM句
②ON句
③JOIN句
④WHERE句
⑤GROUPBY句
⑥HAVING句
⑦SELECT句
⑧DISTINCT句
⑨ORDERBY句
⑩LIMIT句
第18章「ノーチャンジ・コンフィグ」
PostgreSQLに限らず、デフォルトのコンフィグ設定はminimumに寄せて作られています。
そのため、デフォルトのままではハイスペックなサーバを用意したとしてもその効果が得られません。
コンフィグで設定できる内容を理解して、適切なコンフィグ設定を心がけることが大事です。
■ コンフィグの役割
1. パフォーマンス
2. セキュリティ
3. RDDMSの役割
■ コンフィグのチェックツール
1.PostgreSQL => PgTune
https://pgtune.leopard.in.ua/#/
2.MySQL => MySQLTuner
https://github.com/major/MySQLTuner-perl
第19章「塩漬けのバージョン」
RDBMSは一度利用すると、5年~10年利用することはザラです。(まあ、バージョンアップ面倒ですからね...)
しかし、多くの現場では利用年数が増えてもバージョンを最新化することなく利用し続けるケースが多いです。(バージョンアップにはデータベースの停止を伴い、サービスのメンテナンス時間が必要となるので)
バージョンアップをサボると、セキュリティリスクや安定稼働しないといったデメリットがあるのでバージョンアップは必須になります。
バージョンアップには2種類あります。
1. マイナーバージョンアップ
-> バグ対応やセキュリティアップデートが中心。アプリケーションへの影響が小さい。
2. メジャーバージョンアップ
-> 機能追加や機能改善が中心。アプリケーションへの影響が大きい。
バージョンアップする場合は以下のSTEPで進めていけばOK
①バージョンアップ方法の決定
②コンフィグの確認
③リハーサル
④バージョンアップ作業
第20章「フレームワーク依存症」
フレームワーク側の都合がRDBMS側の設計に影響を与えるケースが多くあります。
例えば、RailsのORマッパーは優秀ですが、それに依存するようなDB設計にすると不都合が起きやすくなります。