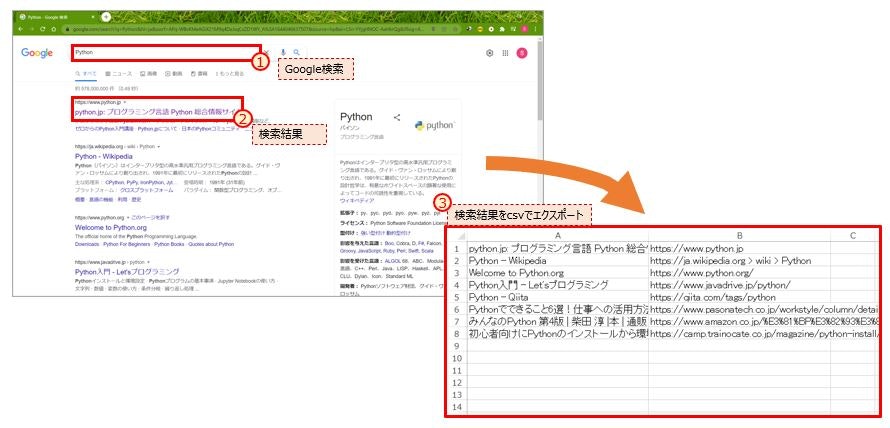
Seleniumを使ったWebスクレイビングのサンプルコード(Google検索結果をcsvにエクスポート)です。
作業イメージ図
ライブラリのインポート
import os
import csv
from selenium import webdriver
from selenium.webdriver.common.by import By #要素を選択
from selenium.webdriver.common.keys import Keys #Keyを返す
from selenium.webdriver.support.ui import WebDriverWait #明示的待機
from selenium.webdriver.support.expected_conditions import presence_of_element_located #指定した要素がDOM上に現れるまで待機
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities #環境(OS, Browser)を設定
Gridサーバーへ接続
if __name__ == ‘__main__’: #定型句(import時に実行されないようにするため)
filename = './google_search_result.csv'
titles = []
urls = []
# Selenium Gridサーバー(Hub)へ接続する。(※Browser, OSなどの環境を指定)
driver = webdriver.Remote(
command_executor=os.environ[“SELENIUM_URL”],
desired_capabilities=DesiredCapabilities.CHROME.copy()
)
Google検索結果を返す
#前章からの続き(main関数内)なのでインデント付けてね。
# 検索キーワード入力
keyword = input("Search Keyword:")
# Googleにアクセス+入力キーワードで検索
#name要素でq(=query)を探索
driver.get("https://google.com")
driver.find_element(By.NAME, “q”).send_keys(keyword + Keys.RETURN)
# 検索結果描画待機(条件にマッチするまで最大10秒待つ)
wait = WebDriverWait(driver, 10)
wait.until(
presence_of_element_located((By.XPATH, ‘//a/h3’))) #h3タグ
# タイトルとURLを抽出
for elem_h3 in driver.find_elements_by_xpath('//a/h3'):
title = elem_h3.text
url = elem_h3.find_element_by_xpath('..').get_attribute('href')
print("Title:"+title+" | "+"URL:"+url)
titles.append(title)
urls.append(url)
# csv出力
result = [list(row) for row in zip(titles, urls)]
with open(filename, mode="w", encoding="utf-8") as f:
writer = csv.writer(f, lineterminator="\n")
writer.writerows(result)
driver.quit()
参照元
Selenium公式(英語)
https://www.selenium.dev/
10分で理解する Selenium
https://qiita.com/Chanmoro/items/9a3c86bb465c1cce738a
参考
YouTubeで「Pythonを使った事務処理の効率化」というタイトルでSeleniumを使ったWebスクレイピングを紹介。