こんにちは!Martimです!
今回は、2026年7月1日に提供を再開した Claude Fable 5 の「性能は本当に落ちたのか?」という疑問に、2つのベンチマークデータを使って迫っていきます!
本記事の情報は 2026年7月3日時点 のものです。Fable 5は再開直後で状況が日々変わっています。料金体系・安全分類器の挙動・ベンチマークスコアは今後更新される可能性があります。
皆さん、こんな声を目にしていませんか?
「Fable 5、帰ってきたけど弱体化(nerf)されてない?」
「コーディングで使うと勝手にOpus 4.8に切り替わるんだけど......」
「ベンチマークのスコアが激減してるらしい」
SNSや開発者コミュニティで飛び交っているこの話題、調べてみたらベンチマークの種類によって 真逆の結果 が出ていて、その差の原因がかなり面白かったので共有します!
目次
- Claude Fable 5とは
- 提供停止から再開までの時系列
- 安全分類器(Safety Classifier)とフォールバックの仕組み
- ベンチマーク比較(1) BridgeBench -- コーディング性能が激減?
- ベンチマーク比較(2) Arena.ai -- 汎用性能はほぼ維持
- なぜ2つのベンチマークで結果が真逆なのか
- Fable 5 と Opus 4.8、結局どちらを使うべきか?
- AWSエンジニアとしての注目ポイント
- おわりに
Claude Fable 5とは
まずFable 5がどういうモデルなのか、ざっくり押さえておきます。
Claude Fable 5は、Anthropicが一般公開しているモデルの中で最も高性能なAIモデルです。
もともと「Mythosクラス」として一部の承認組織にだけ提供されていた超高性能モデルに、安全機構(セーフガード)を搭載して一般向けに公開したのがFable 5です。中身はClaude Mythos 5と同一で、違いは安全分類器(safety classifier)の有無だけ。危険と判断されたリクエストは自動的にClaude Opus 4.8に引き継がれる仕組みが入っています。
スペックをOpus 4.8と並べると、こうなります。
| 項目 | Claude Fable 5 | Claude Opus 4.8(参考) |
|---|---|---|
| モデルID | claude-fable-5 | claude-opus-4-8 |
| コンテキストウィンドウ | 100万トークン以上 | 100万トークン |
| 最大出力トークン | 128Kトークン | 128Kトークン |
| 料金(入力/出力 100万トークンあたり) | $10 / $50 | $5 / $25 |
| SWE-bench Pro | 80.3% | 69.2% |
| FrontierCode Diamond | 29.3% | 13.4% |
→ つまり、Fable 5はOpus 4.8の約2倍の料金で、特に難易度の高いコーディングタスクで大きな差をつけるモデルです。
提供停止から再開までの時系列
Fable 5はリリースからわずか3日で提供停止という、AI業界でも前例のない事態を経験しています。かなり激動の3週間だったので、時系列で振り返ります。
| 日付 | 出来事 |
|---|---|
| 6月9日 | Claude Fable 5・Mythos 5を一般公開 |
| 6月12日 | 米商務省が輸出管理指令を発出。Amazonの研究者がFable 5の安全機構を迂回する手法(ジェイルブレイク)を報告したことがきっかけ。全ユーザー向けにアクセス停止 |
| 6月26日 | 米国の一部組織に対し、Mythos 5のアクセスを先行復帰 |
| 6月30日 | 商務長官が輸出管理を撤回する書簡を送付。規制解除 |
| 7月1日 | Fable 5が全世界で提供再開。ただし強化された安全分類器を搭載 |
ポイントは、7月1日に帰ってきたFable 5は「まったく同じ状態」ではないということです。Anthropicは再公開にあたり、報告されたジェイルブレイク手法を99%以上ブロックする 改良版の安全分類器 を搭載しました。
この安全分類器の強化こそが、今回の「弱体化した?」騒動の核心です。
安全分類器(Safety Classifier)とフォールバックの仕組み
ここが今回の記事で一番大事なパートです。再開後のFable 5を理解するには、この安全分類器の仕組みを知っておく必要があります。
安全分類器とは、Fable 5に送られるリクエストをリアルタイムで監視し、危険なカテゴリに該当すると判断した場合に自動でブロックする仕組みです。
ブロック対象のカテゴリは主に以下の3つです。
- 攻撃的サイバーセキュリティ -- 脆弱性の悪用方法、攻撃コードの生成など
- 生物学・化学 -- 危険な物質の合成手順など
- モデル蒸留 -- AIモデルの知識を不正に抽出する行為
リクエストが分類器に引っかかると、以下の流れで処理されます。
- Fable 5ではなく Claude Opus 4.8が代わりに回答する(フォールバック)
- ユーザーにはフォールバックが発生した旨の 通知が表示される
- 課金はFable 5の料金ではなく Opus 4.8の料金が適用される
6月の初回リリース時もこの仕組みは存在しており、Anthropicの説明では全セッションの5%未満でしか発動しないとされていました。しかし、7月1日の再開版では分類器が大幅に強化されたため、日常的なコーディングやデバッグでも誤検知が増えた とAnthropicが認めています。
開発者から報告されている誤検知の例
再開後、開発者コミュニティでは具体的なフォールバック事例が多数報告されています(2026年7月3日時点での報告)。
- デッドコードの検索だけでOpus 4.8に切り替わった
- C、C++、Rust、Win32 API関連のコードを扱うとフォールバックが発動した
- メモリ管理に関する作業で切り替わった
- ソースコード内に「security」「vulnerable」「unsafe」「hook」といった単語が含まれるだけでフォールバックがトリガーされた
一方で、「自分は一度もリルートされていない」「Fable 5で1日に60件のPRを出せた」という声もあり、ワークロードの内容によって体感差がかなり大きいようです。セキュリティ周りのコードをほとんど触らない開発者にとっては、以前と変わらない使い心地かもしれません。
Anthropicは「今後数週間で誤検知の頻度を改善していく」と説明しています(2026年7月1日時点の公式発表)。実際にどこまで改善されるか、注目しておきたいところです。
ベンチマーク比較(1) BridgeBench -- コーディング性能が激減?
ここからが本題です。まずはコーディング特化のベンチマーク「BridgeBench」の結果を見ていきます。
BridgeBenchとは
BridgeBenchは、AIエージェントサービスを開発する米BridgeMind AIが公開しているオープンソースのコーディング向けベンチマークです。以下の3つの観点でAIモデルを評価しています。
| ベンチマーク名 | 評価内容 |
|---|---|
| Hallucination(ハルシネーション) | コード分析時にAIがどれだけ虚偽の主張をするか。30タスク・6クラスタ・175問で検証 |
| Debugging(デバッグ) | 壊れたTypeScriptを診断・修復できるか。再現テスト・隠れたバグの発見・根本原因の特定を評価 |
| Refactoring(リファクタリング) | 構造を変えつつ動作を保てるか。隠れた回帰の検出・構造的な意図への準拠を評価 |
Before / After 比較
BridgeMind AIは2026年7月2日、再開されたFable 5(7月1日版)でBridgeBenchを再実行し、結果を公式Xアカウントで公開しました。

(https://claude.ai/api/5fdf4930-f5c5-460c-b30d-85bcaeb2db18/files/38cd68fb-1b60-405a-9c86-86e690959fd2/preview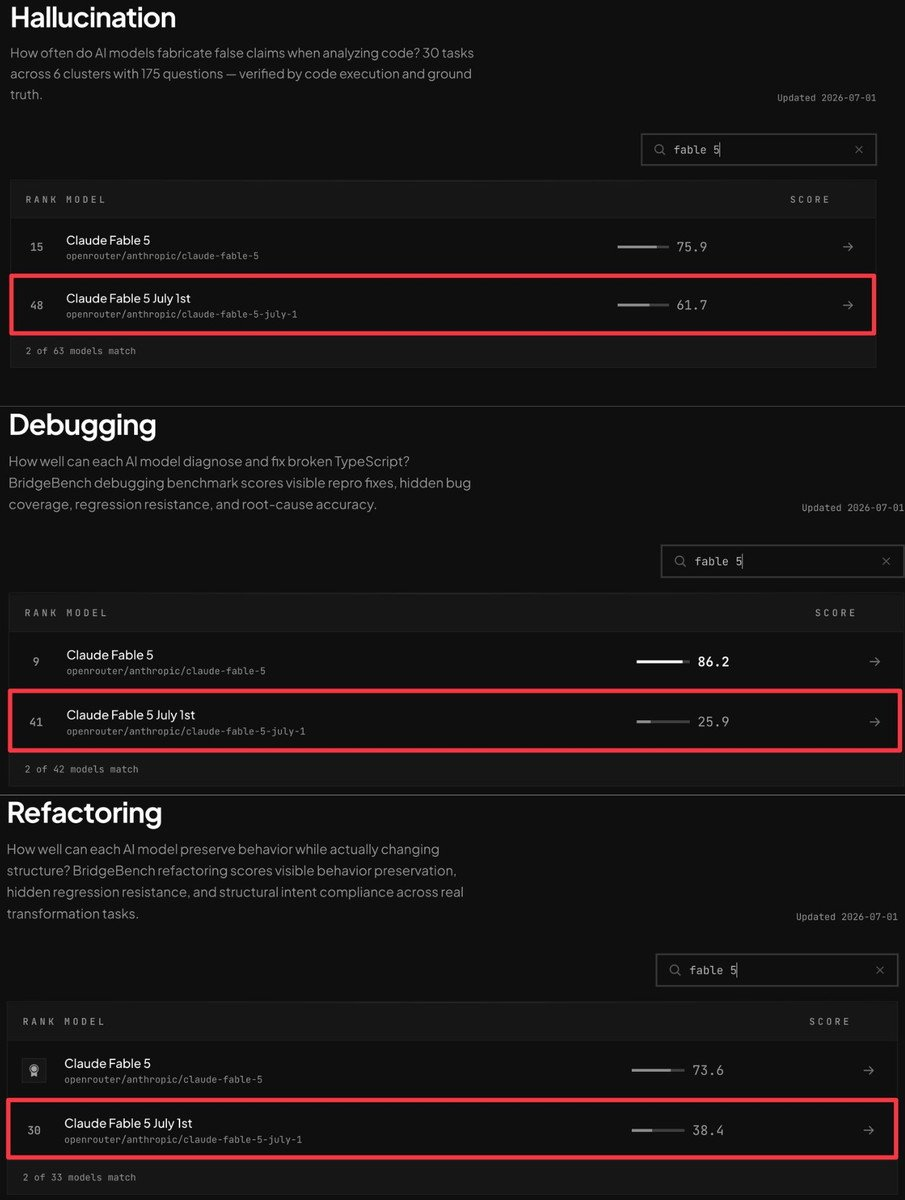
)
BridgeBenchでのClaude Fable 5スコア比較。赤枠が7月1日版(再開後)のスコア。デバッグは86.2から25.9に、リファクタリングは73.6から38.4に低下している。(出典:BridgeMind AI 公式Xアカウント、2026年7月2日)
以下はスコアの日本語整理です(2026年7月2日時点のBridgeBenchデータ)。
| ベンチマーク | 提供停止前(6月版) | 再開後(7月1日版) | 変化 | ランク変動 |
|---|---|---|---|---|
| Hallucination | 75.9 | 61.7 | -14.2 | 15位 → 48位 |
| Debugging | 86.2 | 25.9 | -60.3 | 9位 → 41位 |
| Refactoring | 73.6 | 38.4 | -35.2 | 上位 → 30位 |
→ つまり、デバッグのスコアは約70%の下落です。リファクタリングも約半減、ハルシネーション耐性も2割近く低下しています。
なぜここまでスコアが落ちたのか
この数字だけ見ると「モデルが壊れた」ように見えますが、実態は違います。
BridgeMind AIの詳細な分析によると、TypeScriptデバッグの12タスク中9タスクがOpus 4.8にリルートされ、リルートされたタスクはすべてゼロ点として集計された ことがスコア崩壊の主因です。Fable 5が実際にタスクを完了した3タスクでは、6月版と同等の性能を発揮していたとされています。
BridgeMind AI自身がこの状況を端的に表現しています。
「モデルが弱くなったのではない。檻に入れられた(caged)のだ」
この表現はなかなか的確です。BridgeBenchのスコア低下は「Fable 5自体の知能が落ちた」のではなく、「安全分類器が過剰反応してFable 5に仕事をさせず、代わりにOpus 4.8が回答した」結果ということになります。
ベンチマーク比較(2) Arena.ai -- 汎用性能はほぼ維持
もう一つのベンチマーク、Arena.ai(旧LMArena / Chatbot Arena)の結果は、BridgeBenchとは大きく異なります。
Arena.aiとは
Arena.aiは、ユーザーがAIモデルの出力を ブラインド形式で比較・投票する プラットフォームです。ユーザーはどちらのモデルが回答しているかを知らない状態で「どちらが良いか」を選び、その投票結果がEloレーティングとして集計されます。2026年7月時点で累計680万票以上・366以上のモデルがランキングされています。
Before / After 比較
Arena.aiは2026年7月2日、Fable 5の提供停止前後のスコア比較を 暫定値(Preview) として公開しました。

(images/arena-ai-comparison.png)
Arena.aiによるClaude Fable 5のBefore(6月版・灰色)/ After(7月版・オレンジ)比較。Code Arena: Frontendでは微減しているが、Document(+34)やText: Expert(+25)ではむしろスコアが上昇している。(出典:Arena.ai、2026年7月2日、暫定値)
以下はスコアの日本語整理です(2026年7月2日時点のArena.ai暫定データ)。
| 評価カテゴリ | 日本語訳 | 提供停止前(6月版) | 再開後(7月版) | 変化 |
|---|---|---|---|---|
| Code Arena: Frontend | コーディング(フロントエンド) | 1650 | 1623 | -27 |
| Vision | 画像認識 | 1312 | 1315 | +3 |
| Document | ドキュメント処理 | 1499 | 1533 | +34 |
| Text: Overall | テキスト総合 | 1509 | 1504 | -5 |
| Text: Expert | テキスト(専門家向け) | 1537 | 1562 | +25 |
| Text: Creative Writing | テキスト(創作) | 1500 | 1509 | +9 |
| Text: Coding | テキスト(コーディング) | 1563 | 1545 | -18 |
| Text: Hard Prompts | テキスト(難問) | 1533 | 1530 | -3 |
| Text: Longer Query | テキスト(長文) | 1523 | 1527 | +4 |
→ つまり、Arena.aiの結果では9項目中5項目でスコアが微増しており、全体としてほぼ横ばい、一部はむしろ改善しています。
唯一の明確な低下はCode Arena: Frontend(-27)とText: Coding(-18)で、やはりコーディング系で安全分類器の影響が出ていますが、BridgeBenchほどの崩壊は見られません。
Arena.aiのスコアは2026年7月2日時点の暫定値です。今後より多くの投票データが集まることでスコアが変動する可能性があります。
なぜ2つのベンチマークで結果が真逆なのか
ここまでの結果を整理すると、以下のようにまとめられます。
| 観点 | BridgeBench | Arena.ai |
|---|---|---|
| 対象タスク | TypeScriptのデバッグ・リファクタリング(コーディング特化) | テキスト・画像・ドキュメント・コーディングなど多ジャンル |
| 安全分類器の影響 | 直撃(12タスク中9タスクがリルート) | 限定的(汎用タスクはほぼ影響なし) |
| フォールバック時のスコア | ゼロ点として集計 | 回答品質で投票されるため、Opus 4.8の実力が反映される |
| 結論 | スコア大幅低下 | ほぼ横ばい~微増 |
ポイントは2つあります。
1つ目は、安全分類器の誤検知がコーディングタスクに集中していること。 BridgeBenchのタスクはTypeScriptの修復やリファクタリングが中心で、ソースコード内にセキュリティ関連の語句が含まれやすく、分類器のトリガーに引っかかりやすい構造です。一方、Arena.aiの汎用タスク(テキスト生成・ドキュメント処理・クリエイティブライティングなど)では分類器がほとんど反応しません。
2つ目は、ベンチマークのスコア計算方法の違い。 BridgeBenchではフォールバック(Opus 4.8が回答した場合)をゼロ点として扱うため、リルート率がそのままスコア崩壊に直結します。対してArena.aiは人間のブラインド投票なので、Opus 4.8が回答した場合でもOpus 4.8なりの品質が評価に反映されます。
→ つまり、「Fable 5の性能が落ちた」のではなく、「Fable 5が仕事をする機会が安全分類器によって制限されている」 というのが実態です。モデルの頭脳は変わっていません。
Fable 5 と Opus 4.8、結局どちらを使うべきか?
ここまで読むと、「じゃあ今、Fable 5とOpus 4.8のどちらを使えばいいの?」という疑問が出てくると思います。
個人的に調べた範囲での結論は、「基本はOpus 4.8をデフォルトにし、長く複雑な高難度タスクだけFable 5に振る」のが現時点で最も合理的な使い分け です(2026年7月3日時点での判断)。
Fable 5が向いているケース
- 大規模なコードベースの移行・リファクタリング -- 数万行~数百万行規模の作業。実例として、決済サービスのStripeは5000万行規模のRubyコードベース移行をFable 5で1日に圧縮したと報告しています
- マルチステップの長時間エージェント実行 -- 数時間~数日にわたるタスク。計画立案からサブエージェントへの委任、自己チェックまで自律的に進行できる
- 複雑なアーキテクチャ設計 -- 正解が自明でない意思決定タスクや、複数の要件を同時にバランスする設計判断
- 高精度が必要な深い分析・リサーチ -- 論文レベルの調査や、ドキュメントを横断した深い分析
Opus 4.8が向いているケース
- 日常的なコーディング -- 1関数のリファクタ、テスト生成、PRレビューなど、スコープが明確な短い作業
- レイテンシやコストを重視する場面 -- 料金はFable 5の半額。シンプルなタスクではOpus 4.8で十分な品質が出る
- サイバーセキュリティ関連のコードを扱う場面 -- Fable 5だと安全分類器に引っかかるリスクがあるため、Opus 4.8を直接使う方が安定する
料金の考え方(2026年7月3日時点)
| 項目 | Claude Fable 5 | Claude Opus 4.8 |
|---|---|---|
| 入力(100万トークンあたり) | $10 | $5 |
| 出力(100万トークンあたり) | $50 | $25 |
| プロンプトキャッシュ | 対応(90%割引) | 対応(90%割引) |
額面上はFable 5がOpus 4.8の2倍ですが、「タスクあたりのコスト」で考えると話が変わります。Fable 5は難しいタスクをより少ないターン・少ないトークンで完了する傾向があり、リトライ回数が減る分、結果的にOpus 4.8と大差ないケースもあるとされています。
逆に、簡単なタスクにFable 5を使うとオーバースペックで料金だけが膨れます。「全部Fable 5に任せればいいじゃん」とはいかないのが悩ましいところです。
7月7日以降の利用条件変更に注意
2026年7月7日までは、Pro・Max・Team・一部Enterpriseプランで週の利用上限の最大50%までFable 5が追加料金なしで使えます。7月8日以降は利用クレジット(従量課金)に移行する予定です。
ただしAnthropicは「容量が確保でき次第、サブスクの標準機能としてFable 5を戻す意向」も示しています。この辺りは今後のアナウンスを要チェックです。
AWSエンジニアとしての注目ポイント
AWSを普段使いしている身として、ここが一番気になるポイントです。Fable 5はAmazon Bedrockでも利用可能になっており、AWS環境での活用を考えている方向けに要点をまとめます(2026年7月3日時点の情報)。
Amazon Bedrockでの提供状況
Fable 5は7月1日からAmazon Bedrockでもアクセスが復帰しています。DevelopersIOの検証記事によると、提供リージョンは初回リリース時の2リージョン(us-east-1、eu-north-1)から 5リージョンに拡大 されていることが確認されています。
利用方法は以下の2つです。
- Amazon Bedrock -- 既存のAWS環境で推論ワークロードをスケールできる。Converse APIまたはAnthropic Messages APIで呼び出し可能
- Claude Platform on AWS -- Anthropicのネイティブなプラットフォーム体験をAWS上で利用
なお、DevelopersIOの検証記事ではBedrock Mantle(/anthropic/v1/messagesエンドポイント)経由での呼び出しは404エラーとなり、7月1日時点では動作しなかったことが報告されています。現時点ではConverse API(bedrock-runtime)経由での利用が確実です。
30日間のデータ保持が必須
Fable 5の利用には、30日間のデータ保持(provider_data_share)への同意が必要 です。これはBedrockの「Data Retention API」でモードを設定する必要があり、この設定をしないとモデルの呼び出し自体ができません。
→ つまり、ゼロデータ保持(ZDR)ポリシーで運用しているチームは、Fable 5の導入前にセキュリティ・コンプライアンスチームとの調整が必要になります。ここは他のClaudeモデルとは異なる重要なポイントです。
フォールバックのハンドリング
API経由でFable 5を利用する場合、安全分類器がリクエストをブロックすると stop_reason: "refusal" がHTTP 200として返されます。エラーではなく正常レスポンスとして返る点に注意が必要です。
Bedrockを使う場合は、このフォールバックを適切にハンドリングする設計が求められます。具体的には以下のような対応が考えられます。
-
stop_reasonを監視し、"refusal"の場合はOpus 4.8で自動リトライするロジックを実装する - フォールバック先のモデルIDも推論プロファイル(
us./global.プレフィックス付き)を使う必要がある - プロンプトステージでのブロック(推論開始前のブロック)は課金されないが、ミッドストリームのブロック(出力途中のブロック)はブロック前に生成されたトークン分が課金される
おわりに
「Claude Fable 5は弱体化したのか?」の答えは、「モデル自体は弱体化していない。ただし安全分類器の強化により、コーディング系タスクでOpus 4.8にフォールバックされる頻度が増えている」 です。
ベンチマーク2種の結果を改めて整理します。
- BridgeBench(コーディング特化) → デバッグスコアが86.2から25.9に激減。ただしこれは12タスク中9タスクがOpus 4.8にリルートされた結果で、Fable 5が処理したタスクでは6月版と同等の性能
- Arena.ai(汎用評価) → 9項目中5項目でスコア微増。全体としてほぼ横ばいで、モデル本体の性能低下は確認されていない
使い分けとしては、基本はOpus 4.8をデフォルトにしつつ、大規模・高難度のタスクでFable 5に切り替える「タスク別ルーティング」が現時点では最も現実的 です。特にセキュリティ関連のコードを扱う場面ではフォールバックのリスクを考慮してOpus 4.8を直接使う方が安定します。
AWSユーザーとしては、Bedrockでの30日間データ保持要件と、stop_reason: "refusal" のハンドリング設計を事前に検討しておくことをおすすめします。
Anthropicは安全分類器の誤検知を今後数週間で改善すると表明しています。改善が進めば、Fable 5のコーディング性能がベンチマーク上でも回復してくる可能性は十分あります。
→ つまり、Fable 5の真価が問われるのはこれからです。今のうちに自分のユースケースで「どのタスクでフォールバックが起きるか」を試しておくと、改善後にスムーズに切り替えられるはずです!
この記事が参考になったら「いいね」を押してもらえると嬉しいです!
それでは!よいAWSライフを!
参考情報
- Anthropic公式 -- Redeploying Claude Fable 5(2026年6月30日公開)
- Anthropic公式 -- Claude Fable 5 and Claude Mythos 5(2026年6月9日公開)
- Anthropic公式 -- Claude Fable 5 Pricing(2026年7月1日更新)
- BridgeMind AI -- BridgeBench 再テスト結果(2026年7月2日、公式X投稿)
- Arena.ai -- Ranking Comparison Preview(2026年7月2日公開、暫定値)
- ITmedia NEWS -- 「Claude Fable 5」の性能が落ちた? 提供停止前後で比べた結果(2026年7月3日公開)
- AWS公式ブログ -- Anthropic Claude Fable 5 on AWS(2026年7月1日更新)
- DevelopersIO -- 再リリースされた「Claude Fable 5」をAmazon Bedrockで試してみた(2026年7月1日公開)