NFSを用いたシステムのアラートの設定について自分の体験談から注意点をまとめておこうと思います.
意外と気づきにくいところなのでもし今後,NFSを用いてファイルやディレクトリを共有する時に意識するといいかもしれません.
NFSとは
NFSとはNetwork File Systemの略で他のマシンのファイルやディレクトリを共有するシステムです.ファイルサーバに作成しデータをまとめたりする際に使用します.NFSはサーバとクライアントに分かれており,サーバ側のディレクトリを共有する形で使用します.割と簡単に利用できるのでぜひ使ってみてください.参考記事の1番でインストールできます.
実際に起きたこと
自分が使っていた構成を説明します.自分自身はWebサイト上にブログサイトを公開しようと思って6台のVMを用意していました.またその中でファイルを共有するためにNFSサーバとNFSクライアントでディレクトリを共有してました.
当時,PrometheusとNodeExporterを用いてそれぞれのVMのディスク使用率を監視していました.その際に実際に1から6台全てのVMでディスク使用率が高いよというアラートが一斉に出ました.これを最初に見た時,感じたことは「意味がわからん」とういことでした.なんで,1つのVMではなく同時に出るんだという感じでしたね.
当時Prometheusのアラートの設定を以下のようにしていました.
- alert: node-monitoring-disk-usage-high
expr: 1 - (node_filesystem_avail_bytes / node_filesystem_size_bytes) >= 0.8
for: 1m
labels:
severity: "warning"
Prometheusで監視できる対象全てのディスク使用率を見ていました.閾値は0.8です.つまり80%を超えた時にアラートが出ます.
例えば,/dev/mapper/ubuntu--vg-ubuntu--lvの部分を重点的に監視するとかかな.こうすればアラートの発生箇所も抑えられたよね.
原因
原因は結果的にNFSのサーバが原因でした.
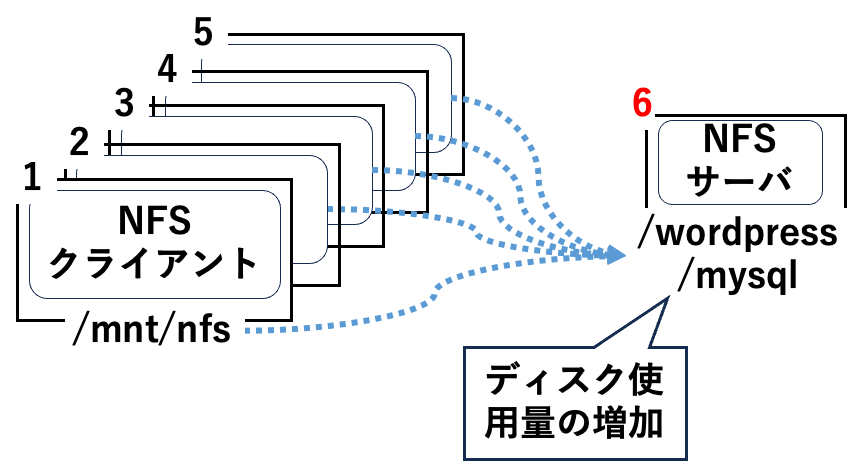
どういうことかというと,NFSサーバとクライアントはディレクトリやファイルを共有します.その中で,NFSサーバがいるVMのディスクの容量が不足すると,共有している他のディレクトリも同様に容量が不足してるよとエラーが出ます.
NFSクライアント側の共有されているディレクトリを見てみると大体56%使用していますよね.
$ df -h
...
Filesystem Size Used Avail Use% Mounted on
outside-nfs3:/home/cdsl/mysql 47G 25G 20G 56% /mnt
...
NFSサーバ側のディレクトリも/dev/mapper/ubuntu--vg-ubuntu--lが56%ですよね.つまりPrometheusはこの値を拾っていたことがわかります.
$ df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 392M 1.2M 390M 1% /run
/dev/mapper/ubuntu--vg-ubuntu--lv 47G 25G 20G 56% /
tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/sda2 2.0G 254M 1.6G 14% /boot
/dev/sda1 1.1G 6.1M 1.1G 1% /boot/efi
tmpfs 392M 4.0K 392M 1% /run/user/1000
これは集中型のシステムであるNFSだからこそ起こることなんでしょうね.このような場合アラートが全てのVMで出てしまうので修正箇所がわからないですよね.
これは大問題です!!!!!!!!!!
なのでPrometheusの設定もちゃんと変えるべきでした.
- alert: node-monitoring-disk-usage-high
expr: 1 - (node_filesystem_avail_bytes{instance = "NFSサーバのいるVMのIP"} / node_filesystem_size_bytes{instance = "NFSサーバのいるVMのIP"} ) >= 0.8
for: 1m
labels:
severity: "warning"
for: 1m
labels:
severity: "warning"
こんな感じで絞れればよかったですね.
最後に
この件で学んだことは監視する際に対象を分けてあげることの重要性と動いているものはなんなのか意識することですね.
僕もまだまだなんでこれからも頑張ります.