はじめに
Difyのナレッジベースは、AIアプリの精度や応答の質を高めるうえで非常に有効な機能です。通常はDifyの管理画面からナレッジを手動で追加しますが、CSV形式の大量データを一括でアップロードしたい場面も多いのではないでしょうか。
本記事では、HTMLとJavaScriptを使って、Webブラウザ上から直接DifyのナレッジベースにCSVファイルをアップロードする方法をご紹介します。実際のコードとその解説も交えながら、手軽で分かりやすいインターフェースを通じてナレッジベースを効率的に更新する方法を解説していきます。
なお、今回ご紹介するコードは、Difyを使って実際にアプリを構築する際、AIにプロンプトを与えて生成させたものです。AIを活用した開発の一例としても参考になるかと思います。
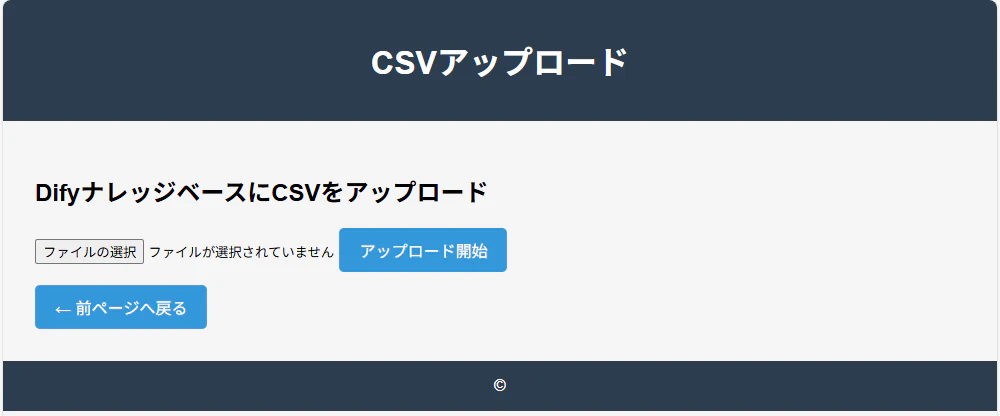
完成図
以下は、このブログで紹介するコードで作成できるCSVアップロード画面の完成図です。
なぜWebサイトからのアップロードが必要か?
- ユーザーインターフェースの提供: Difyの管理画面にアクセスすることなく、特定のユーザーがCSVファイルをアップロードできる環境を提供したい場合。
- 業務プロセスの自動化: 定期的に更新されるCSVデータを、手動ではなくWebサイト経由で自動的にDifyに反映させたい場合。
-
特定用途のツール開発: CSVデータを用いた特定の機能を持つWebアプリケーションの一部として、ナレッジベース更新機能を組み込みたい場合。
加えて、Difyの管理画面では通常15MBまでのファイルしかアップロードできませんが、Webサイト側でファイルを自動的に分割し、チャンクごとに順次アップロードすることで、より大きなデータを効率よくナレッジに登録することが可能になります。これにより、大容量データを扱う業務でもスムーズなナレッジ管理が実現できます。
必要なもの
この実装を進めるにあたり、以下の準備が必要です。
- DifyのAPIキー: Difyアプリケーションの「設定」→「APIアクセス」から取得できます。
- DifyのDataset ID: ナレッジを登録したいDifyのデータセットのIDです。データセットのURL(例: https://cloud.dify.ai/datasets/{DatasetID}
- PapaParseライブラリ: CSVをJavaScriptで簡単にパースするために使用します。CDNで提供されているため、HTMLファイルに読み込むだけで利用可能です。
コードの全体像
今回は、以下の3つのファイルで構成されます。
1.upload.html: ファイル選択とアップロードボタン、ログ表示エリアを持つシンプルなHTMLページ。
2.upload.js: CSVの読み込み、Dify APIへのリクエスト、進捗ログの表示など、すべてのロジックを担うJavaScriptコード。
3.style.css: ページを読みやすくするための簡単なスタイルシート(任意)。
1.upload.html
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8" />
<title>CSVアップロード</title>
<link rel="stylesheet" href="style.css" />
<script src="https://cdnjs.cloudflare.com/ajax/libs/PapaParse/5.4.1/papaparse.min.js"></script>
<script src="upload.js" defer></script>
</head>
<body>
<header>
<h1>CSVアップロード</h1>
</header>
<main>
<h2> DifyナレッジベースにCSVをアップロード</h2>
<input type="file" id="csvInput" accept=".csv" />
<button class="nav-button" onclick="handleUpload()">アップロード開始</button>
<pre id="log"></pre>
//ほかサイトにこのページに埋め込む際に元サイトに戻るコード
<button class="nav-button" onclick="location.href='〇.html'">
← 前ページへ戻る
</button>
</main>
<footer>
© 2025 company
</footer>
</body>
</html>
- PapaParse: CSVパースの強力なライブラリです。defer属性を付与することで、HTMLの解析をブロックせず、スクリプトの準備ができたときに実行されます。
- csvInput: type="file"とaccept=".csv"により、ユーザーはCSVファイルのみを選択できます。
- handleUpload(): ボタンがクリックされたときに呼び出されるJavaScript関数です。
- log: アップロードの進捗や結果を表示するためのタグです。整形されたテキストをそのまま表示するのに適しています。
upload.js
このファイルには、Dify APIとの連携、CSVのパース、チャンク処理など、すべての核心ロジックが含まれています。
// === グローバル設定 ===
// DifyのAPIキーとDataset IDはここに設定してください。
// セキュリティのため、本番環境ではサーバーサイドで管理することをお勧めします。
const apiKey = "YOUR_DIFY_API_KEY"; // ← ここにご自身のAPIキーを設定してください
const datasetId = "YOUR_DATASET_ID"; // ← ここにご自身のDataset IDを設定してください
const chunkSize = 5000; // 1回のAPIリクエストで処理するJSONオブジェクトの最大数
// 既存ドキュメント削除関数
// 指定されたDataset ID内の既存のドキュメントをすべて削除します。
// これにより、重複アップロードや古い情報の蓄積を防ぎます。
async function deleteAllDocuments(datasetId, apiKey) {
const log = document.getElementById('log');
log.textContent += `:開いたフォルダ: 既存のドキュメントを確認中...\n`;
try {
// ドキュメント一覧の取得
const res = await fetch(`http://api.dify.ai/v1/datasets/${datasetId}/documents`, {
headers: { Authorization: `Bearer ${apiKey}` }
});
if (!res.ok) {
log.textContent += `:x: ドキュメント一覧取得失敗 (${res.status} - ${res.statusText})\n`;
return;
}
const data = await res.json();
const documents = data.data || [];
if (documents.length === 0) {
log.textContent += ` 削除対象なし\n`;
return;
}
// 各ドキュメントの削除
for (const doc of documents) {
const del = await fetch(`http://api.dify.ai/v1/datasets/${datasetId}/documents/${doc.id}`, {
method: 'DELETE',
headers: { Authorization: `Bearer ${apiKey}` }
});
log.textContent += del.ok
? `:ごみ箱: 削除成功: ${doc.name}\n`
: `:x: 削除失敗: ${doc.name} (${del.status} - ${del.statusText})\n`;
}
} catch (error) {
log.textContent += `:警告: ドキュメント削除中にエラーが発生しました: ${error.message}\n`;
}
}
// CSV → JSON変換関数(PapaParseを使用)
// CSVテキストデータを正確なJSONオブジェクトの配列に変換します。
function parseCSVtoJSONWithPapa(csvText) {
const results = Papa.parse(csvText, {
header: true, // 1行目をヘッダーとして扱い、オブジェクトのキーに使用
skipEmptyLines: true, // 空行をスキップ
});
// パースエラーがあればログに出力
if (results.errors.length > 0) {
document.getElementById('log').textContent += `:警告: CSVパース中にエラーが発生しました: ${JSON.stringify(results.errors)}\n`;
}
return results.data; // 変換されたJSONデータの配列を返す
}
// メイン処理:アップロードハンドラ関数
async function handleUpload() {
const input = document.getElementById('csvInput');
const log = document.getElementById('log');
const file = input.files[0];
if (!file) {
alert("CSVファイルを選択してください");
return;
}
log.textContent = ""; // ログをクリア
// 既存ドキュメントの削除を実行
await deleteAllDocuments(datasetId, apiKey);
log.textContent += ` CSVファイルの読み込みと変換を開始します...\n`;
const text = await file.text(); // ファイル内容をテキストとして読み込み
const jsonAll = parseCSVtoJSONWithPapa(text); // CSVをJSONに変換
log.textContent += `CSVファイルから ${jsonAll.length} 件のレコードを読み込みました。\n`;
// JSONデータをチャンクに分割してDifyにアップロード
for (let i = 0; i < jsonAll.length; i += chunkSize) {
const jsonChunk = jsonAll.slice(i, i + chunkSize); // チャンクを抽出
// 各JSONオブジェクトを文字列化し、改行で結合して単一のテキストにする
const chunkText = jsonChunk.map(obj => JSON.stringify(obj)).join('\n');
const chunkName = `chunk_${Math.floor(i / chunkSize) + 1}.json`; // チャンク名
log.textContent += ` ${chunkName} (${jsonChunk.length} 件) をアップロード中...\n`;
try {
const res = await fetch(`http://api.dify.ai/v1/datasets/${datasetId}/document/create-by-text`, {
method: "POST",
headers: {
"Authorization": `Bearer ${apiKey}`,
"Content-Type": "application/json"
},
body: JSON.stringify({
name: chunkName, // ドキュメント名
text: chunkText, // ドキュメント内容
indexing_technique: "high_quality", // インデックス手法
process_rule: { // ドキュメントの処理ルール
mode: "custom", // カスタムルールを使用
rules: {
segmentation: { // セグメンテーション(チャンク分割)ルール
separator: "\n", // 改行コードでセグメントを分割
max_tokens: 2000, // 各セグメントの最大トークン数
overlap: 0 // セグメント間の重複なし
},
pre_processing_rules: [ // 前処理ルール
{ id: "remove_extra_spaces", enabled: true }, // 余分なスペース削除
{ id: "remove_urls_emails", enabled: true } // URLやメールアドレス削除
]
}
}
})
});
if (res.ok) {
log.textContent += `:チェックマーク_緑: アップロード成功: ${chunkName}\n`;
} else {
const errorData = await res.json(); // エラーレスポンスの詳細を取得
log.textContent += `:x: アップロード失敗: ${chunkName} (${res.status} - ${res.statusText}) - ${errorData.message || '不明なエラー'}\n`;
}
} catch (error) {
log.textContent += `:警告: ${chunkName} のアップロード中にネットワークエラーが発生しました: ${error.message}\n`;
}
}
log.textContent += `\n:クラッカー: 全チャンクのアップロードが完了しました!\n`;
alert(":クラッカー: アップロード完了!");
}
コードの動き(フロー)
このページでは、Difyと連携してCSVファイルをナレッジベースにアップロードする処理の流れを、7ステップに分けて解説します。
1. グローバル設定の読み込み
まず最初に、以下の基本情報が読み込まれます。
- APIキー:Difyにアクセスするための鍵
- Dataset ID:どのナレッジベースにデータを送るか
- チャンクサイズ:一度に送るデータ量(例:5000件)
2. 「アップロード開始」ボタンが押される
HTMLの「アップロード開始」ボタンがクリックされると、handleUpload() というJavaScript関数が実行されます。
3. ファイルの確認とログのクリア
- ユーザーがCSVファイルを選んでいない場合、処理を中断し、警告を表示します。
- 画面に表示されていたログを一度すべてクリアします。
4. 既存ドキュメントの削除(お掃除)
-
deleteAllDocuments()関数が呼ばれ、Difyに登録されている古いドキュメントをすべて削除します。 - 処理内容:
- Dify APIに「現在のドキュメント一覧」をリクエスト
- 一つずつ削除リクエストを送信
- 削除進行状況をログに表示
5. CSVファイルの読み込みとJSON変換
- ユーザーが選択したCSVファイルの中身をテキストとして読み込みます。
- 読み込んだテキストは
parseCSVtoJSONWithPapa()に渡され、PapaParseライブラリを使ってJSON形式に変換されます。
6. データをチャンクに分割し、Difyに送信
大量のJSONデータは、chunkSize ごとに分割され、以下の処理が繰り返されます:
【チャンク処理の流れ】
1.テキスト化
- 各チャンクを、Difyが読み取りやすいテキスト形式(改行区切り)に変換
2.Dify APIへの送信 -
POSTリクエストで、以下の情報を含めて送信:-
name:このドキュメントに付ける名前 -
text:送るテキストデータ -
indexing_technique:"high_quality" -
process_rule: 情報の分割方法・整形ルール- 例:改行区切り、最大2000トークン、URL除去など
3.ログの表示
- 例:改行区切り、最大2000トークン、URL除去など
-
- 各チャンクごとのアップロード結果(成功/エラー)を画面に表示
7. アップロード完了メッセージ
全チャンクのアップロードが終わると、画面に以下のメッセージが表示されます:
このアップロード処理では、ユーザーがボタンを押すだけで:
- 古いデータの削除
- CSVの読み取りと整形
- チャンク分割とAPI送信
- 結果の表示
までを自動で行う仕組みが整っています。
upload.jsはその中心的な役割を担うスクリプトです。
style.css
基本的なCSSです。
body {
font-family: 'Arial', sans-serif;
margin: 0;
padding: 0;
background: #F5F5F5;
}
header, footer {
background-color: #2C3E50;
color: white;
padding: 1em;
text-align: center;
}
main {
padding: 2em;
}
.iframe-container {
width: 100%;
min-height: 700px;
margin-bottom: 2em;
}
button.nav-button {
display: inline-block;
padding: 10px 20px;
font-size: 16px;
background: #3498DB;
color: white;
border: none;
border-radius: 5px;
cursor: pointer;
}
button.nav-button:hover {
background: #2980B9;
}
}
使い方と実行方法
- 上記のHTML、JavaScript、CSSファイルを、それぞれ
upload.html、upload.js、style.cssという名前で同じフォルダに保存します。 -
upload.jsファイルを開き、
apiKeyとdatasetIdのプレースホルダーを、ご自身のDifyのAPIキーとDataset IDに必ず置き換えてください。 -
upload.htmlファイルを、Google Chrome、Firefox、Safariなどの任意のWebブラウザで開きます。 - 表示されたページで「ファイルを選択」ボタンをクリックし、
DifyナレッジベースにアップロードしたいCSVファイルを選択します。 - 「アップロード開始」ボタンをクリックします。
- ページ下部のログエリアに、
- 既存ドキュメントの削除状況
- CSVの読み込み状況
- 各チャンクのアップロード進捗
がリアルタイムで表示されます。
- すべてのチャンクのアップロードが完了すると、
「アップロード完了!」というアラートが表示されます。
これで、Difyのナレッジベースに新しいCSVデータが登録され、Difyアプリケーションから利用できるようになります。
注意事項と改善点
本番運用にあたっては、以下の3点を特に注意してください。
1. APIキーのセキュリティ
- 現在のコードは、APIキーをクライアント側のJavaScriptに直接記述しています。
- これは開発や検証時には便利ですが、本番環境では重大なセキュリティリスクとなります。
- 推奨対応:APIキーはサーバー側で管理し、クライアントからはサーバーの中継エンドポイント(Node.jsやAPI Gateway、Lambdaなど)を呼び出す方式に切り替えてください。
2. Dify APIのエンドポイントの確認
- サンプルコードはDify Cloud(
https://api.dify.ai/v1/)向けになっています。 - ローカル環境を利用している場合は、APIエンドポイントを
(例:http://localhost/v1/...)
に変更してください。
3. チャンクサイズの最適化
一度に送るデータ量(chunkSize)が大きすぎるとAPIのタイムアウトや失敗の原因になります。逆に小さすぎるとリクエスト回数が増え、処理全体が遅くなることがあります。
推奨値の例:
- 小規模データ:1000〜3000件
- 中〜大規模:5000件(上限付近で要検証)
まとめ
この記事では、DifyのナレッジベースにCSVファイルをWebサイトから直接アップロードする実践的な方法を解説しました。これにより、Difyアプリケーションのナレッジをより柔軟に、そして効率的に管理することが可能になります。
APIキーの管理やエラーハンドリングなど、本番運用においては考慮すべき点がありますが、このコードをベースにして、ぜひご自身のDifyプロジェクトに合わせたカスタマイズを行ってみてください。
おまけ
くすりの窓口にてインターン募集中!! 8.9.10月開催
https://internshipguide.jp/interns/internDetail/17895