この記事はOBSを使ってゲーム実況画面にスコアなどを表示してみよう(その1)の続きです
旧題「デレステ配信オーバーレイに使用した技術と実装」
著作権情報 THE IDOLM@STER™& ©Bandai Namco Entertainment Inc.
アイドルマスターシンデレラガールズとは
AndroidとiOS対応の音ゲームです。
機能紹介
タイトル画面

- 実際の配信画像
![THE iDOLM@STER Cinderella Girls_ Starlight Stage [Master_Master+].mp4_snapshot_00.02.59.557.jpg](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F423236%2F0cb8c7ed-1dd8-84de-f6fc-bf6e35647e9b.jpeg?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=a1909e8af83f2e78b40371ffd881e270)
楽曲、難易度選択検出

- 実際の配信画像
![THE iDOLM@STER Cinderella Girls_ Starlight Stage [Master_Master+].mp4_snapshot_01.04.14.589.jpg](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F423236%2F29eb41c0-7f7d-6cd1-13b4-fa6c34fdaa4d.jpeg?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=57d52f9465e9eb524c9cd9b28f17ada7)
ライブ終了検知、グラフ描写
- 実際の配信画像
![THE iDOLM@STER Cinderella Girls_ Starlight Stage [Master_Master+].mp4_snapshot_01.05.46.673.jpg](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F423236%2Fcb1066cd-329c-f45e-da53-50fd556c628e.jpeg?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=61369c753c98cbadfdb90a454730be4c)
開発環境(使用ソフトウェアおよびハードウェア)
- 開発環境:ThinkPad P50@windows10
- キャプチャデバイス:【2023新登場 l キャプチャーボード】 USB3.0 & HDMI 変換アダプタ HD画質録画 HD1080P/4Kパススルー機能 HDMI ビデオキャプチャー ゲーム録画/HDMIビデオ録画/ライブ配信用キャプチャー ボード 電源不要 小型軽量 低遅延 Switch/PS5/PS4/PS3/Xbox用サポート Windows 7/8/10 Linux OBS Potplayer YouTube Niconico Twitch対応 日本語取扱説明書付き
- Androidデバイス:Galaxy S24
- IDE:VScode
- パッケージ管理:Yarn/Poetry
- OBS Studio(Open Broadcaster Software)
OSSのライブストリーミングおよび録画ソフトウェア
WebSource(ウェブソース)機能は、ウェブページのコンテンツをキャプチャしてストリームや録画に組み込むための機能。公式サイトの説明ではChromium Embedded Framework(CEF)
システム概要
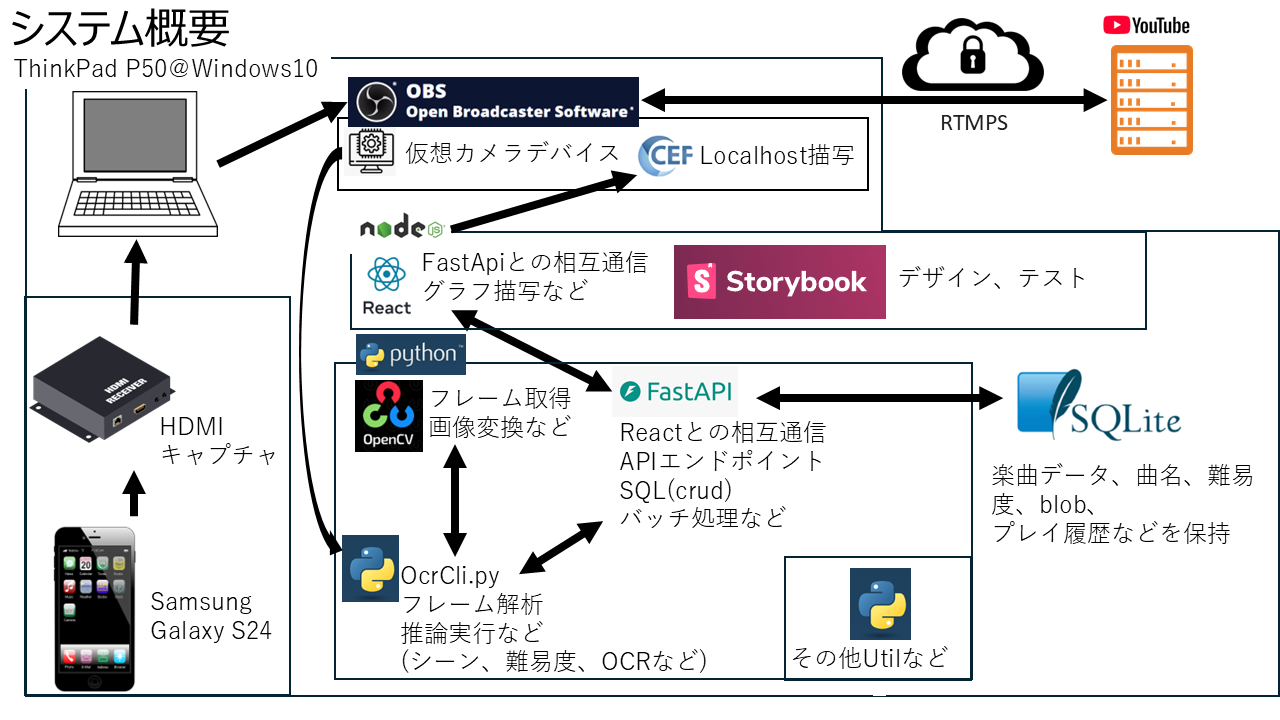
アイドルマスターシンデレラガールズの画面構成と分類手法
検知対象画面検知
- 検知対象外画面(例:ホーム画面など)

- 検知対象画面(楽曲+難易度選択画面)
画面下部中央の構成要素が変化する
学習データとして、この要素を切り出したものを使用し
Tire1モデルとして推論モデルを構築した
楽曲+難易度選択画面
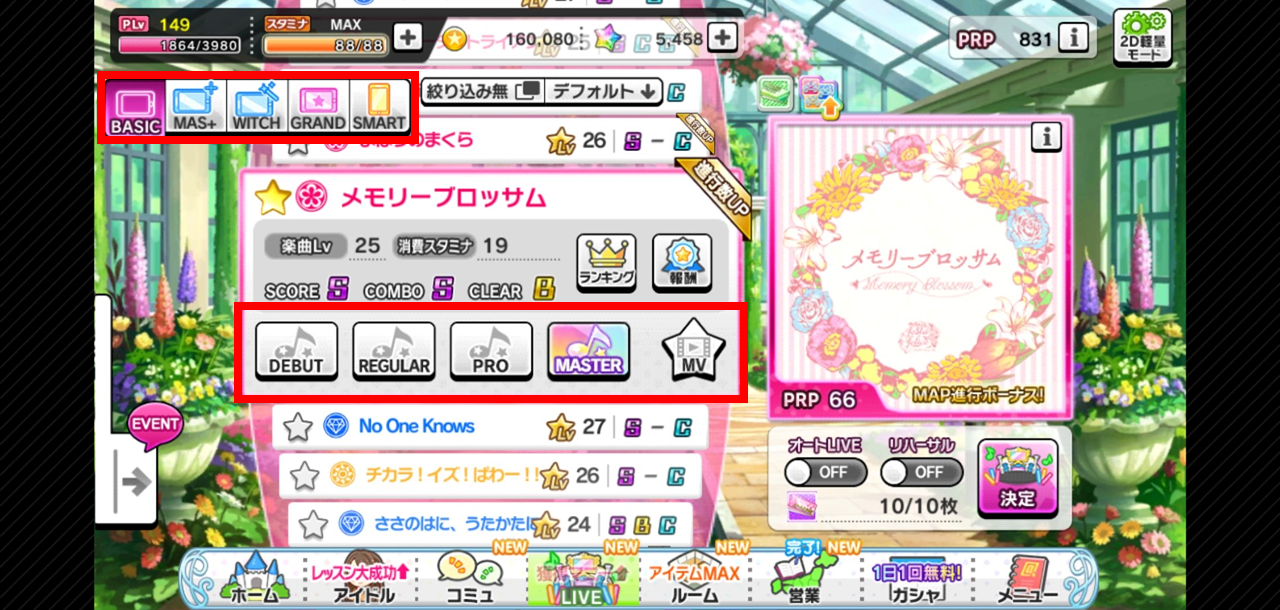
楽曲+難易度選択画面では画面上部左の構成要素が変化する
これをTire2モデルとして推論モデルを構築した
Tire2より下の分類として画面中央のレベル選択要素がある
これをTire3モデルとして推論モデルを構築した
Tire1~3と選択難易度対応表
| Tire1 | Tire2 | Tire3 | 選択難易度 |
|---|---|---|---|
| Live | Basic | Debut | DEBUT |
| Live | Basic | Regular | REGULAR |
| Live | Basic | Pro | PRO |
| Live | Basic | Master | MASTER |
| Live | Basic | Mv | |
| Live | Master+ | MASTER+ | |
| Live | Witch | WITCH | |
| Live | Grand | Piano | PIANO |
| Live | Grand | Forte | FORTE |
| Live | Grand | GrandMv | |
| Live | * | Other | |
| Live | * | ComfirmModal | |
| Live | Other | ||
| Live | ComfirmModal | ||
| Other | |||
| ComfirmModal |
ComfirmModalはLive開始ボタンを押したのち消費スタミナや消費チケットを確認するモーダル
import os
import cv2
import uuid
import numpy as np
import keyboard # キーボード入力を監視するためのライブラリ
from PIL import Image, ImageChops
# スクリプト自身のパスを取得
script_dir = os.path.dirname(os.path.abspath(__file__))
# トレーニングデータのディレクトリを設定
train_data_dirs = {
'1':os.path.join(script_dir, '..'...,
'2':os.path.join(script_dir, '..'...,
...
}
# マスク画像のパスを設定
mask_paths = {
'1': os.path.join(script_dir, '..'...,
'2': os.path.join(script_dir, '..'...,
...
}
# キャプチャデバイスの設定
cap = cv2.VideoCapture()
if not cap.isOpened():
raise Exception("Failed to open capture device")
def apply_mask(frame, mask_path):
mask = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE)
if mask is None:
raise Exception(f"Failed to load mask image: {mask_path}")
# マスクを反転
mask = cv2.bitwise_not(mask)
# マスクを二値化
_, binary_mask = cv2.threshold(mask, 1, 255, cv2.THRESH_BINARY)
# アルファチャンネルを追加
b, g, r = cv2.split(frame)
alpha = binary_mask
frame = cv2.merge([b, g, r, alpha])
# バウンディングボックスを取得
x, y, w, h = cv2.boundingRect(binary_mask)
return frame[y:y+h, x:x+w] # トリミング
def save_frame(frame, tire_type):
uuid = str(uuid.uuid4())
save_path = os.path.join(train_data_dirs[tire_type], f'{uuid}.png')
cv2.imwrite(save_path, frame)
print(f"Saved frame to {save_path}")
recording = False
tire_type = None
while True:
ret, frame = cap.read()
if not ret:
print("Failed to capture frame")
break
if keyboard.is_pressed('q'):
break
elif keyboard.is_pressed('1'):
tire_type = '1'
recording = True
elif keyboard.is_pressed('2'):
tire_type = '2'
recording = True
...
if recording and tire_type:
masked_frame = apply_mask(frame, mask_paths[tire_type])
save_frame(masked_frame, tire_type)
cap.release()
import os
import winsound
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader, random_split
import matplotlib.pyplot as plt
from PIL import ImageFile
# トランケートされた画像を無視する設定
ImageFile.LOAD_TRUNCATED_IMAGES = True
# スクリプト自身のパスを取得
script_dir = os.path.dirname(os.path.abspath(__file__))
# データセットのベースディレクトリを相対パスで指定
base_data_dir = os.path.join(script_dir, '..', 'train_data', 'SceanDetect')
# データの前処理
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 各サブディレクトリごとにモデルを作成
for category in os.listdir(base_data_dir):
winsound.Beep(440, 2000)
data_dir = os.path.join(base_data_dir, category)
if not os.path.isdir(data_dir):
continue
# データセットの読み込み
dataset = datasets.ImageFolder(data_dir, transform=transform)
# データセットをトレーニングとテストに分割
train_size = int(0.8 * len(dataset))
test_size = len(dataset) - train_size
train_dataset, test_dataset = random_split(dataset, [train_size, test_size])
# データローダーの作成
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# モデルの定義(ResNet18を使用)
model = models.resnet18(pretrained=True)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, len(dataset.classes))
# 損失関数とオプティマイザの定義
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# トレーニングループ
num_epochs = 10
train_losses = []
test_losses = []
train_accuracies = []
test_accuracies = []
winsound.Beep(1000, 500)
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
train_losses.append(running_loss / len(train_loader))
train_accuracies.append(100 * correct / total)
model.eval()
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
outputs = model(inputs)
loss = criterion(outputs, labels)
running_loss += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
test_losses.append(running_loss / len(test_loader))
test_accuracies.append(100 * correct / total)
print(f'Category: {category}, Epoch {epoch+1}/{num_epochs}, Train Loss: {train_losses[-1]}, Test Loss: {test_losses[-1]}, Train Accuracy: {train_accuracies[-1]}, Test Accuracy: {test_accuracies[-1]}')
winsound.Beep(880, 500)
# モデルの保存
model_save_path = os.path.join(script_dir, '..', 'Models', f'model_{category}.pth')
torch.save({
'model_state_dict': model.state_dict(),
'num_classes': len(dataset.classes),
'class_to_idx': dataset.class_to_idx
}, model_save_path)
winsound.Beep(440, 1000)
winsound.Beep(440, 3000)
winsound.Beep()は音が鳴るなり法隆寺
テンプレートマッチングを採用しなかった理由
当初は非選択時の画面要素をNOT要素として楽曲レベル選択を実装していたがうまくいかなかった。原因としては以下が考えられる。
- OBS Virtul Cameraの制約
フレームサイズ640*480、画質 - 配信時と非配信時で認識時に使用する閾値が変動する(OBS、キャプボの問題?)
- デレステ画面遷移においてホーム>ライブ画面(BASIC)で表示される画面とライブ画面(MAS+)>ライブ画面(BASIC)で表示される画面に若干の描写座標、アスペクト比の差異が生じている?
よく分からんけど動いてないからアシ!
選択楽曲名分類手法
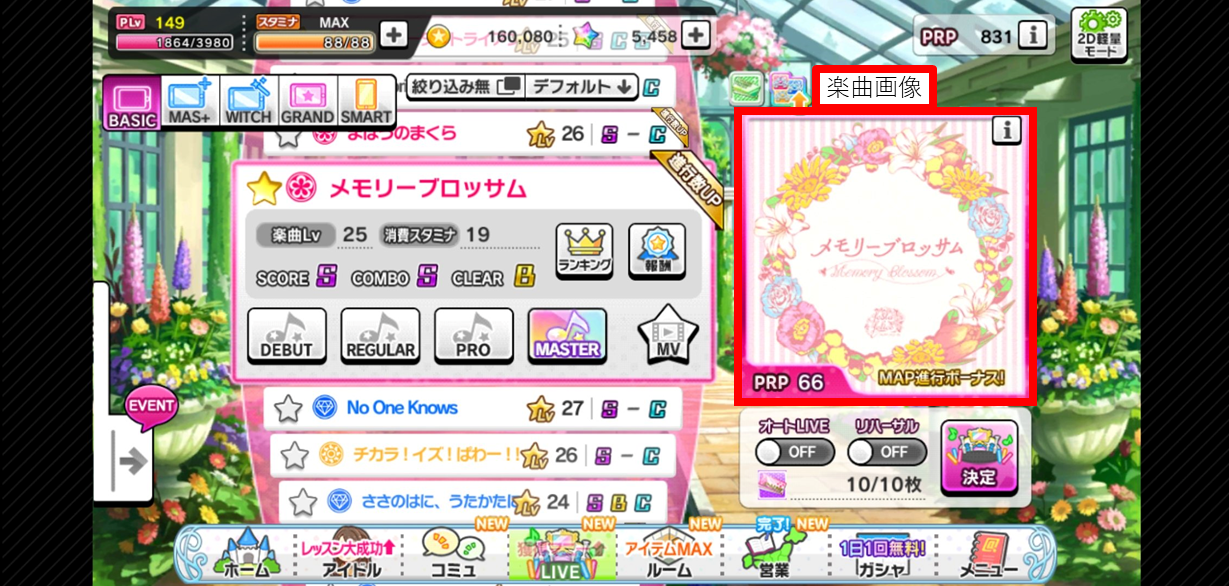
一般的にオフライン手書き文字認識の精度は95%程と言われている。
これは楽曲分類に十分な精度ではあるが計算コストがかかり、リアルタイム性に劣る。
また推論モデル構築には莫大な計算コストがかかり、楽曲追加ごとにモデリングを行うのは現実的でない。
今回は楽曲画像をあらかじめImageHashの複数のアルゴリズムを用いてハッシュ化し、上記画像赤枠で切り出した画像ハッシュ値とのハミング距離が最小のものを選択楽曲とするようにした。
デレステをプレイしている人ならわかると思うがこの手法では「ライブパーティー」や「ぴにゃリクエスト」などから楽曲に入る場合には対応できない。
(import) imagehash: Module("imagehash")
# ハッシュ値と最も近い画像を検索する関数
def find_closest_image(combined_hash, song_images):
ahash, phash, dhash, whash = combined_hash
min_distance = float('inf')
closest_image = None
for uuid, data in song_images.items():
image_ahash = imagehash.hex_to_hash(data['ahash'])
image_phash = imagehash.hex_to_hash(data['phash'])
image_dhash = imagehash.hex_to_hash(data['dhash'])
image_whash = imagehash.hex_to_hash(data['whash'])
distance = (ahash - image_ahash) + (phash - image_phash)\
+(dhash - image_dhash) + (whash - image_whash)
if distance < min_distance:
min_distance = distance
closest_image = uuid
return closest_image
スコア画面OCR
実際にOBS仮想カメラドライバから入力されたスコア画面
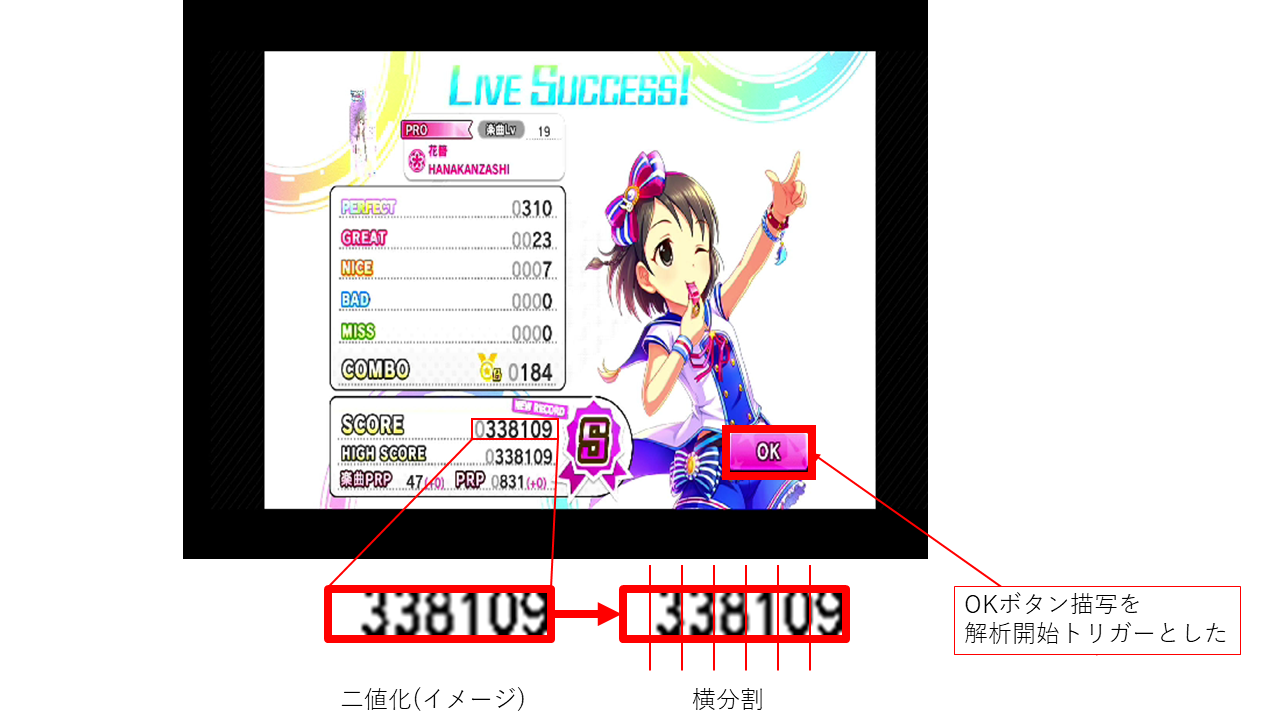
findContours、boundingRectを使用しない理由
ノイズを避けるため意図的に数字認識領域の高さを押さえる必要があった

そうすると例えば3の場合、下図のような端切れが生じる
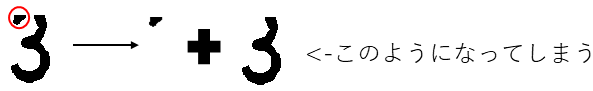
またデレステ内でのスコア表示画面数字は等幅であるため単純なn分割で問題ない。
独自モデル構築のモチベーション
- そもそもの仮想カメラドライブからの入力フレームの画質、サイズの問題
- 既存のOCRエンジンの精度・速度、チューニングの限界
特に速度に関しては大きな不満があった。10数秒ほどかかるのでOCR処理を待つというネガティブなUXが発生し、しかも精度も悪い。ここが大きなモティベーションになった。
独自モデル構築の際の問題点
- スコア画面は実際に楽曲をプレイしないと出せない(学習用データn数問題)
1楽曲4分ほどとして生成できる学習データは理論最大値(4x6+7x2+2+4個/4分= 44個/4分 => 11個/分)
ゲームは1日1時間までとお母さんに言われているのでそうすると660個/日
- マスクを手作業で適当に作ったため以下のような左右に切れ込みが生じる。
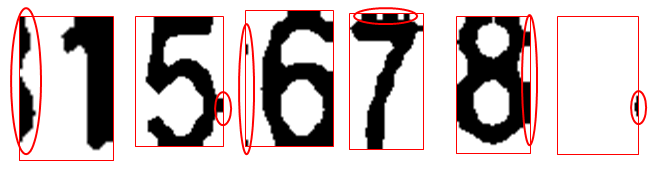
これらはOCR前処理で除去すべき要素ではあるが(めんどくさいので)それら左右にあえてノイズを追加するデータ拡張を行い独自モデルを構築することにした。
というより端に独立して入り込んでる奴は一瞬で行けるとして数字画像に張り付いてる系(上の例でいうなら7と8)を除去する方法を私は知らない
これによりn数問題とノイズの問題を強引に解消することができた。
精度が高いのは当たり前として推論速度の向上は目を見張るものがあった。
![THE iDOLM@STER Cinderella Girls_ Starlight Stage [Master_Master+].gif](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F423236%2F3ca07899-f7d2-5202-34cf-d5cd50a8a223.gif?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=2ddaaddb7cec72a25fecee7d72f3828b)
上記動画において画面遷移の時点で推論、crud、json作成は完了している。
import os
import random
import cv2
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import models, transforms
from torch.utils.data import Dataset, DataLoader
from torch.utils.tensorboard.writer import SummaryWriter
import torch.optim as optim
# 定数の定義
NUM_CLASSES = 11 # 0-9の数字と空白文字
LABELS = [str(i) for i in range(10)] + [' '] # 0-9の数字と空白文字
# スクリプトのパスを取得
script_dir = os.path.dirname(os.path.abspath(__file__))
data_dir = os.path.join(script_dir, '..', 'train_data', 'Digits')
# データセットフォルダ内のすべての画像を読み込む関数
def load_all_images(data_dir):
images = []
labels = []
for folder in os.listdir(data_dir):
folder_path = os.path.join(data_dir, folder)
for filename in os.listdir(folder_path):
if filename.endswith('.png'):
image_path = os.path.join(folder_path, filename)
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE) # 二値化画像として読み込む
_, binary_image = cv2.threshold(image, 128, 255, cv2.THRESH_BINARY)
images.append(binary_image)
if folder == 'Other':
labels.append(10)
else:
labels.append(int(folder))
return images, labels
# 縦に65にリサイズし、縦横比を維持する関数
def resize_image(image, target_height=65):
height, width = image.shape
aspect_ratio = width / height
new_width = int(target_height * aspect_ratio)
resized_image = cv2.resize(image, (new_width, target_height), interpolation=cv2.INTER_LANCZOS4)
return resized_image, new_width, height
# ランダムに左右に数字の切れ端を追加する関数
def add_random_edge(image, all_images):
image, new_width, original_height = resize_image(image)
height, width = image.shape
new_image = np.zeros((65, 40), dtype=np.uint8)
edge_width = random.randint(1, 10) # ランダムな切れ端の幅
random_image = random.choice(all_images) # ランダムな画像を選択
random_image, _, _ = resize_image(random_image)
if random.choice([True, False]):
# 左側に切れ端を追加
edge = random_image[:, :edge_width]
new_image[:, :edge_width] = edge
new_image[:, edge_width:edge_width + width] = image[:, :min(width, 40 - edge_width)]
else:
# 右側に切れ端を追加
edge = random_image[:, -edge_width:]
new_image[:, :min(width, 40 - edge_width)] = image[:, :min(width, 40 - edge_width)]
new_image[:, min(width, 40 - edge_width):min(width, 40 - edge_width) + edge_width] = edge
return new_image
# カスタムデータセットクラス
class DigitDataset(Dataset):
def __init__(self, images, labels, transform=None):
self.images = images
self.labels = labels
self.transform = transform
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
image = self.images[idx]
label = self.labels[idx]
if self.transform:
image = self.transform(image)
return image, label
# データの準備
images, labels = load_all_images(data_dir)
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((65, 40)),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# データ拡張を適用
augmented_images = [add_random_edge(image, images) for image in images]
augmented_labels = labels * 2 # 拡張した分ラベルも増やす
# オリジナルと拡張データを結合
all_images = images + augmented_images
all_labels = labels + augmented_labels
dataset = DigitDataset(all_images, all_labels, transform=transform)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# MobileNetV2の定義
def create_mobilenetv2_model(num_classes):
model = models.mobilenet_v2(weights='IMAGENET1K_V1')
# 最初の畳み込み層を変更して、1チャンネルの入力を受け取るようにする
model.features[0][0] = nn.Conv2d(1, model.features[0][0].out_channels, kernel_size=3, stride=2, padding=1, bias=False)
model.classifier[1] = nn.Linear(model.last_channel, num_classes) # 出力層を指定されたクラス数に変更
return model
model = create_mobilenetv2_model(NUM_CLASSES)
# 損失関数と最適化アルゴリズムの設定
num_epochs = 25
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.OneCycleLR(
optimizer=optimizer,
max_lr=1e-3,
total_steps=len(dataloader) * num_epochs
)
# TensorBoardの設定
writer = SummaryWriter('runs/digit_classification')
# 学習ループ
for epoch in range(num_epochs):
running_loss = 0.0
for i, data in enumerate(dataloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
scheduler.step()
running_loss += loss.item()
# 検証ループ
model.eval()
val_loss = 0.0
with torch.no_grad():
for i, data in enumerate(dataloader, 0):
inputs, labels = data
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
# エポックごとにログを出力
avg_train_loss = running_loss / len(dataloader)
avg_val_loss = val_loss / len(dataloader)
current_lr = optimizer.param_groups[0]['lr']
print(f'[Epoch {epoch + 1}] train loss: {avg_train_loss:.3f}, val loss: {avg_val_loss:.3f}, lr: {current_lr:.6f}')
writer.add_scalar('training loss', avg_train_loss, epoch)
writer.add_scalar('validation loss', avg_val_loss, epoch)
writer.add_scalar('learning rate', current_lr, epoch)
print('Finished Training')
# モデルとラベルのマッピングを保存
model_save_path = 'MobileNetV2_Digits.pth'
torch.save({
'model_state_dict': model.state_dict(),
'label_mapping': LABELS
}, model_save_path)
print(f'Model and label mapping saved to {model_save_path}')
writer.close()
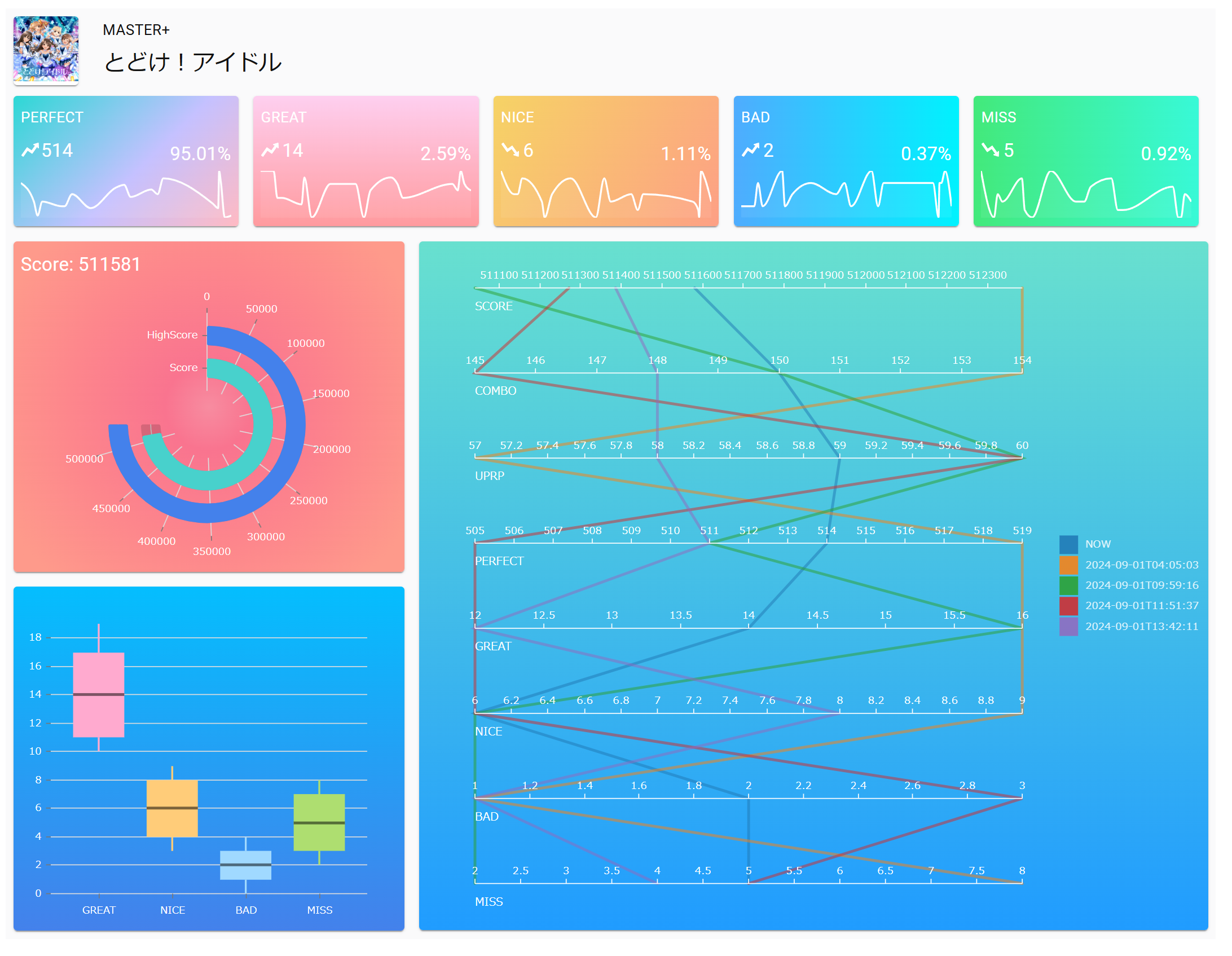
OCR結果と過去レコードに基づくダッシュボード画面作成
フロントエンドは上記技術を採用して作成した。
特にStorybookは実際に渡すデータ等をパターンを変えてテストすることができ非常に重宝した。
ホーム画面
選択楽曲表示画面
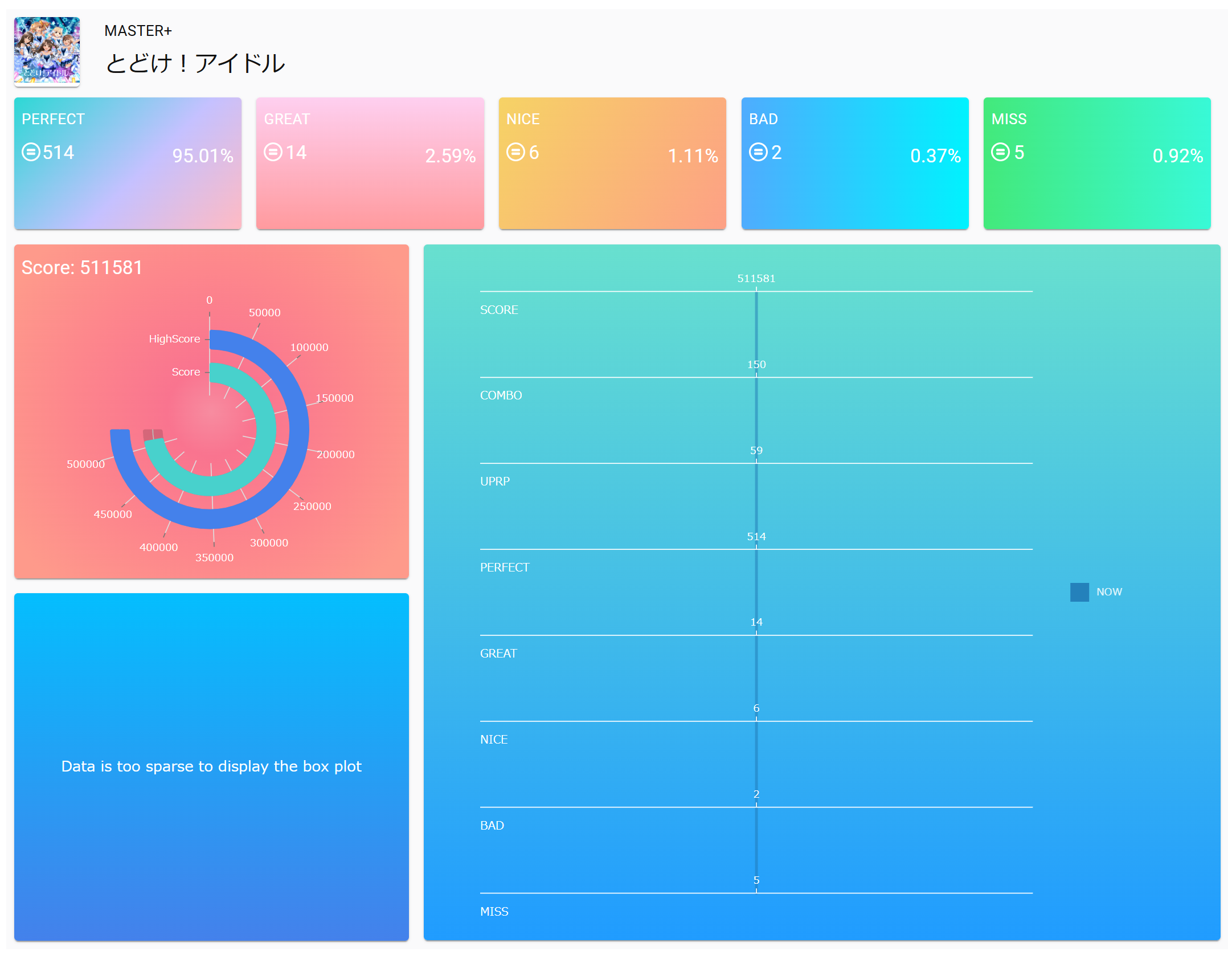
スコア表示画面(過去レコードあり)
スコア表示画面(過去レコードなし)
終わりに
私が社会人になり初めて買ったファーウェイのスマホ(P20 lite?)で通勤時間にやっていたゲームが、まさか令和になった今でもできるのは正直驚きです。13周年ってすごいね!
魅力的な楽曲、キャラデ、ゲームシステムを作り出した優秀なクリエーター、エンジニアを含め関係者の皆様に敬意を表しつつ、これからも末永くサービスが継続されることを祈っております。よろしくお願いいたします。
学マスは中等部や初等部がない!
僕は藤田ことねちゃん!
- 動作動画例
みんなデレステしようぜ!