はじめに
SalesforceのYoutubeチャンネルにて、インドのバンガロールで開催したTDXイベントの面白い動画を見つけました。これはAgentforceのアーキテクチャを細かく解説しており、去年話題になったAtlas推論エンジンの内部を見れるものになっています。こちらの記事ではそんなAgentforceのアーキテクチャをこの動画をベースに日本語で解説していきたいと思います。
Architect's Guide to Agentforce | TDX Bengaluru
AIエージェントとは

こちらの講演ではAIエージェントの定義を従来のソフトウェアと比較して以下のように簡単に紹介していました。
"エージェントは生成AIを利用して自律的に意思決定をする"
そして、この自律的に意思決定をするのに必要になってくるのが 「推論エンジン」 で、エージェントが利用する基盤モデルである生成AIと並んで、もしくはそれ以上に重要になってくるものになります。Salesforceではこの推論エンジンを独自で開発し 「Atlas推論エンジン」 という名前で発表をしています。この記事ではその推論エンジンの簡単なアーキテクチャが紹介されていたので、後ほど説明します。
その前にAgentforceとはどんなものなのかを以下にて解説します。
Agentforceの全体像
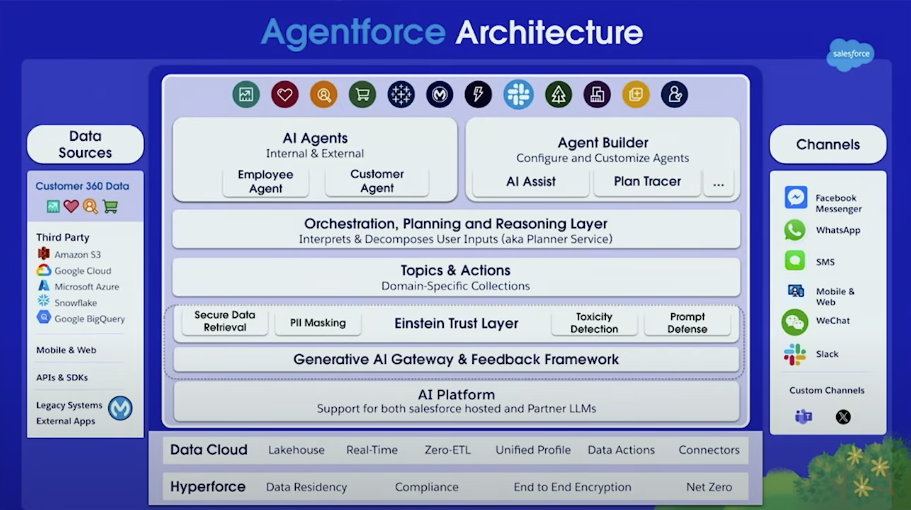
これはAgentforceの簡易的なアーキテクチャになっていますが、全体感を掴むのにちょうど良いスライドになっています。
左側にはデータソースが配置されており、Customer360における全てのデータやそれに加え多くのサードパーティのデータソースを含めることができます。
中央にはSalesforceのAgentforceのエージェント層が描かれています。左上にはInternalとExternalがあり、これは社内で使えるエージェント(従業員エージェント)、そして顧客に対してのエージェント(カスタマーサポートエージェントなど)の両方が利用できることが示されています。そして右上のAgent Builderでは顧客によるノーコード、ローコードカスタムエージェントを作成することができます。その中にはトピックやアクション、指示などを簡単に構築できるようにするためのAIアシスタント機能などが含まれています。
その下にはオーケストレーションと推論のレイヤーが記載されています。後ほどこの部分は掘り下げます。
Einstein Trust Layerでは、生成AIのゲートウェイやフィードバックのフレームワーク、PIIフィルタリングなど。要するにエンタープライズの企業が生成AIを安心・安全に利用できる仕組みがEinstein Trust Layerによって提供されています。
そしてこれらの最も基盤となり重要となる要素が、Data CLoudとHyperforceになります。
最後に右側にはチャネルが記載されており、これらのエージェントをデプロイして利用する場所になります。もちろんSalesforceのSlackとはシームレスに連携しますし、それ以外の代表的なSNSなど、特に日本ではLINEなどの連携はとても需要があると思います。
Atlas推論エンジンのアーキテクチャ

クライアントの要求を理解するフェーズ
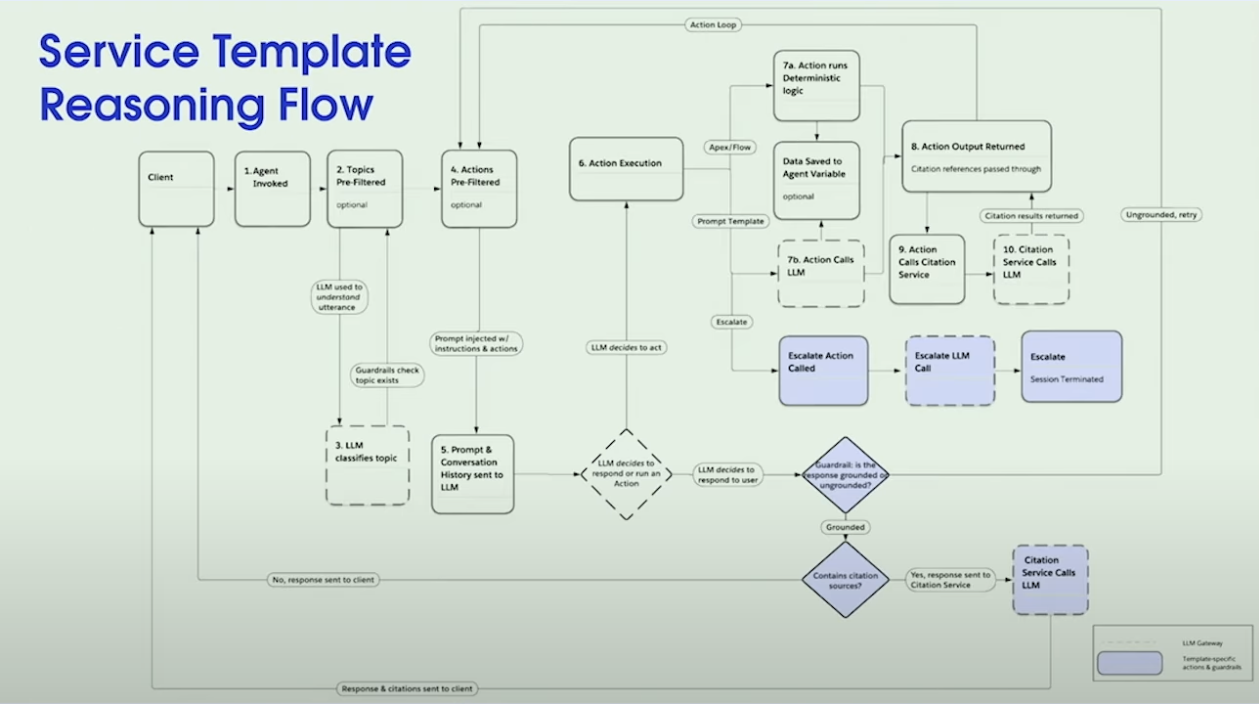
こちらは推論エンジンの中で起こっている簡易的なアーキテクチャフローになります。
左側にクライアントが表示されていますが、例えばLINEのチャンネルやSalesforceのLightningPlatformなどがこれにあたります。基本的にはクライアント側で何かしらのトリガーをきっかけにエージェントが呼び出されることになります。
そして呼び出されたら、エージェントが呼び出せるトピックの範囲を絞り込む作業が開始します。そしてプロンプトをLLMに送信し、エージェントに対する依頼を元に最も近しいトピックを分類します。つまりこの作業はエージェントがユーザーの指示を、つまりユーザーは何が目的で、どんなことをして欲しいのかななどといった要求を適切に理解するフェーズになります。
アクションの決定とゴール達成のためのループ
ステップ4からになりますが、ここにもアクションのプリフィルターがあります。エージェントがジョブを実行するために使用できるアクション、またはツールの範囲をフィルターします。ここにもプロンプトがあり生成AIを利用します。トピックはわかったけど、何をするべきか利用可能なアクションを絞り込みます。そしてユーザーの要求に対して応答するか、それとも直接アクションを行うか決定します。
LLMが直接アクションを実行すると意思決定した場合、ステップ6のアクション実行に進みます。ここはループのフレームワークが採用されていることがわかります。このループを繰り返し、ゴールを達成に向けて推論と行動を繰り返します。
ユーザーへの応答を作成するにはプロンプトテンプレートを選択して、何かしらのインデックス検索を行う必要があります。もしくはフローやAPI、APEXを呼び出してアクションを実行します。
これらを何度も繰り返し、ゴールを達成できたとエージェントが判断した場合、そのアウトプットをクライアントに返却します。
これらのアーキテクチャはとても簡略化したもので、実はもう少し深く見てみると以下のようなレイヤーがあります。
エスカレーションとガードレール
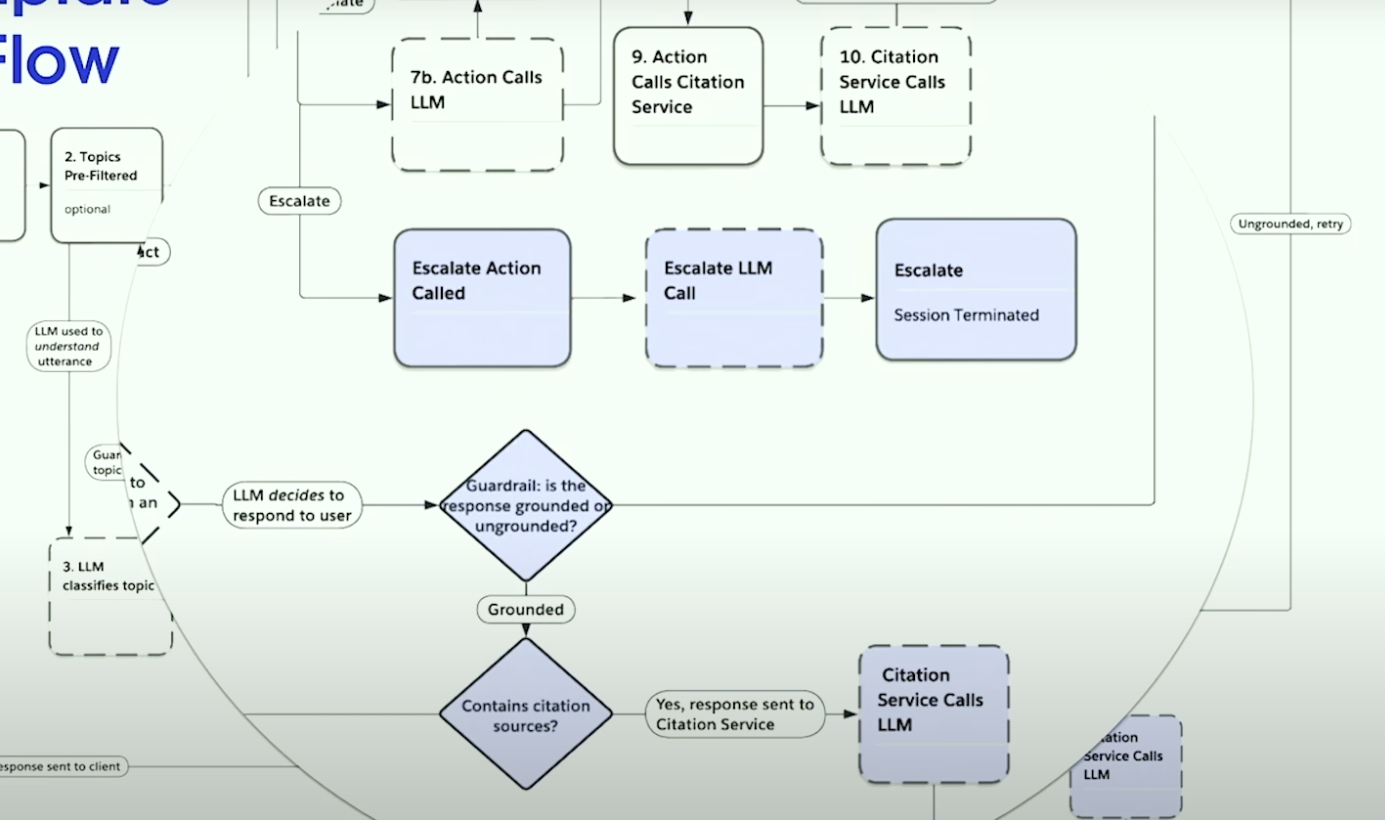
こちらは先ほどのアーキテクチャを少し拡大したものになります。
例えば、SalesforceのService Agentのテンプレートにはエスカレーションが存在します。このエスカレーションはエージェントが判断できなかったり、何かしらの判断を人間に仰ぎたいときのオプションで、この推論エンジンの中にも組み込まれていることがわかります。
またガードレールもこの中に存在しています。応答がクライアントに返却される前に、応答が根拠があるものなのかを確認するオプションがあります。Service Agentでは引用を返却するような機能が組み込まれています。
さいごに
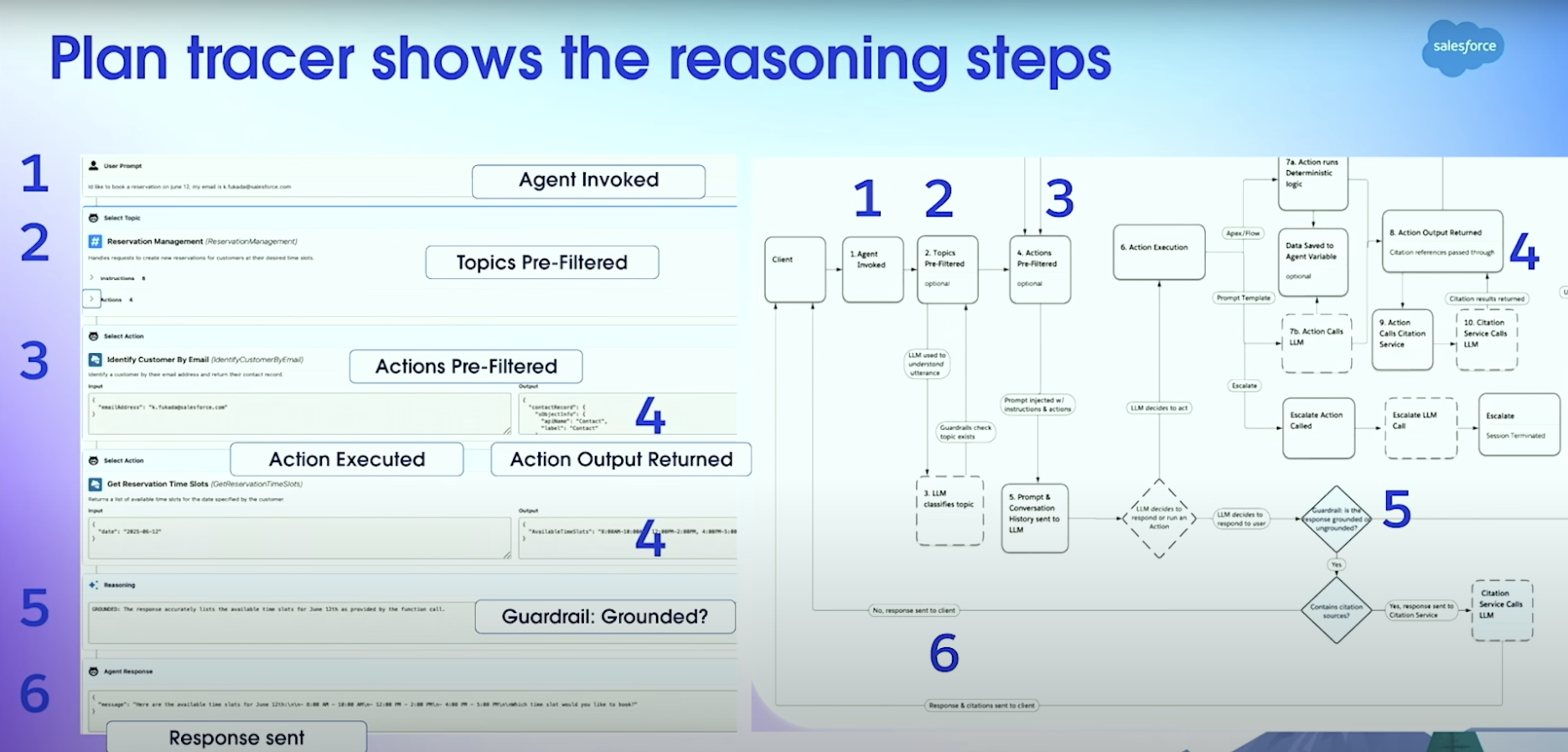
これらの推論ステップは、エージェントのトレース画面で全て確認することができます。気になる方はぜひAgentforceにアクセスしてPlaygroundから確認してみてください。
本記事はArchitect's Guide to Agentforce | TDX Bengaluruより推論エンジンのアーキテクチャを解説しました。この記事では11:20-以降の内容には触れていません。エージェントのベストプラクティスなどを解説しているのでぜひご興味がある方はご覧ください。