はじめに
GraphRAGとは
RAGのビジネス実装が進み、その精度向上に向けては、異なるAI検索手法の組み合わせ、LLMモデルのファインチューニングなど、様々なアプローチが取られてきました。
そのような中、Microsoft ResearchがRAGの新たなアプローチである、GraphRAGに関するレポートを公開し、RAGの精度向上及びユースケースの拡大に向け、今後の発展が期待されています。
今回の記事では、GraphRAGの概要、特徴、利点について解説いたします。
また、次の記事では、実際にAzure OpenAIを活用したGraphRAGをAzure上にデプロイし、検証します。
記事の構成
Graph RAGの解説編、検証編の2つに分けています。
検証編はこちらです。
Azure OpenAIのGraphRAGを解説及び検証(検証編)
解説版目次
- GraphRAGとは
- GraphDBの特徴
- ナレッジグラフの活用事例
- GraphRAGのステップ
GraphRAGとは
GraphRAGは、Graph-based Retrieval-Augmented Generationの略で、LLMが生成したナレッジグラフを使用してプロンプトを拡張し、情報検索及び生成を行います。
ナレッジグラフの特性である関係性分析をRAGに取り入れることで、
従来のRAGの課題であった、データセットの文脈理解が補強され、文書全体のテーマをや意味的な概念をもとに、より関連性の高いコンテンツをコンテキストウィンドウに含めることが出来ます。
※GraphDBやナレッジグラフに馴染みのない方は、下の記事「GraphDBの特徴」を先に参照下さい。
例えば、従来のRAGでは回答が難しいケースは、以下などが挙げられます。
これらに関し、GraphRAGでより精度の高い回答を生成することができます、
- 複数のソース、チャンクから情報を繋ぎ、統合する必要があるクエリ
例:「過去2週間のメールについて最新情報を入手してください」 - 全体的な理解が必要な抽象的なクエリ
例:「〇〇チームの過去2週間の会議の議事録から主題をまとめてください」
「この物語の主題を教えてください」 - エンティティ同士の関係性を捉える必要があるクエリ
例:AさんとBさんの関係性を教えて
これらは、明示的な情報取得タスクではなく、query-focused summarization(クエリに焦点を当てた要約)タスクであり、従来のQFS手法は、典型的なRAGシステムがインデックスするテキスト量に対応できない、とレポート内で説明されています。
GraphDBの特性
GraphDBは、ノード(頂点)とエッジ(辺)を用いてデータを表現するデータベースです。
ノード(頂点)はエンティティを表し、エッジ(辺)はエンティティ間の関係性を表します。
グラフ構造で表現することで、エンティティ間の関係性を直感的に視覚化し、分析することができます。
代表的なグラフデータベースには、Neo4jなどが挙げられます。
GraphDBは、以下のような分野で活用されています。
- 顧客マッチング
- ユーザーの嗜好分析に基づいた商品やコンテンツのレコメンデーション
- 金融システムの不正取引検出、特にマネーロンダリングの検出
- サプライチェーン管理、BoM管理
- SNS分析および友人、コンテンツの推薦
グラフデータベース上で動作するアルゴリズムを用いて、異常なパターンや重要なノードを特定することが可能になります。
以下、代表的なグラフアルゴリズムを紹介します。
- Community Detection:ネットワーク内のノードをコミュニティ(クラスター)に分割するアルゴリズム。
取引ネットワーク内で異常なコミュニティ(例:特定のグループ内でのみ行われる不自然な取引)を特定するのに活用される。 - Shortest Path:ノード間の最短経路を計算するアルゴリズム。
- Centrality Measures:ノードの中心性を評価するアルゴリズム。例えば、Degree Centrality(接続数の多さ)やBetweenness Centrality(他のノード間の経路にどれだけ含まれるか)を用いて、ネットワーク内で影響力の大きいノードを特定する。
ナレッジグラフの活用事例
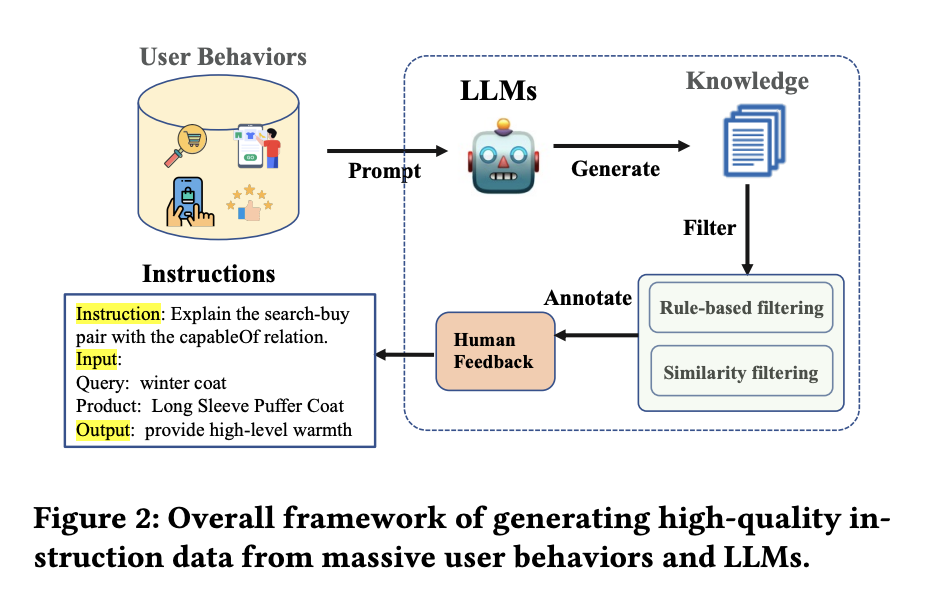
GraphDBを用いたナレッジグラフの活用事例として、AmazonのECサイトで使用されているレコメンドシステム「COSMO」を紹介します。
既存のeコマースナレッジグラフは、ユーザーの行動データをもとに生成され、多くの概念や製品属性を統合しています。
しかし、従来のナレッジグラフでは、ユーザの行動をもとにしても、ユーザーが製品を購入または共同購入する理由や意図を正確に把握することは難しいです。
論文内の例を用いて説明します。
とあるユーザが、「妊婦用の靴」と検索し、滑りにくい靴を購入したとします。
論文内では、検索-購入ペアと表現されています。
我々は、身動きの取りづらい妊婦が、怪我を防止するために滑りにくい靴を購入したのだな、と常識的に理解できます。
こうした、検索-購入ペアの理由を特定するために、LLMが持つ膨大な知識がされています。
すなわち、妊婦が靴を購入した意図として、「妊婦には滑りにくい靴が必要だから」という常識的な知識が獲得されているのです。

Graph RAGのステップ
GraphRAGのには下記の2ステップにより、上記従来のRAGの課題にアプローチしています。
- Index:LLMを用いてテキストデータセット全体からナレッジグラフを作成
- Query:クエリ時にナレッジの階層データを利用してプロンプトを拡張
インデックスステップでは、LLMを使用して、ソース文書からエンティティ知識グラフを生成し、関連するエンティティグループごとにコミュニティ要約を事前生成します。
クエリが与えられると、各コミュニティ要約を使用して部分的な回答を生成し、それらを最終的な回答にまとめます。
これにより100万トークン規模のデータセットに対する全体的な質問に対しても回答することができます。
クエリには、GlobalクエリとLocalクエリがあります。
Globalクエリはデータセット全体から統合的な回答を得るための検索方法です。
対してLocalクエリは特定の文書やデータの一部を対象にして、詳細な情報を検索するための検索手法です。
簡単に違いを説明します。
Globalクエリは、ユーザーのクエリと会話履歴に対して、まず、各コミュニティ要約をテキストチャンクに分割します。次に、これらを中間応答として、優先度付けします。そして、重要な中間応答をもとに回答を生成します。データセット全体のコンテクストを反映できますが、必要な応答速度及びLLMリソースが大きくなります。

一方ローカル検索手法は、ユーザーのクエリと会話履歴に基づいて、知識グラフから意味的に関連するエンティティを特定します。そして、これらのエンティティ周辺のナレッジグラフの情報、更には、関連するテキストチャンクを生の入力文書から抽出し、これらの候補データソースを優先順位付けし、コンテクスト化した上で、ユーザーのクエリに対する応答を生成します。Globalクエリよりもコンテクストの範囲は狭くなりますが、より早く、少ないLLMリソースで応答できます。
https://microsoft.github.io/graphrag/query/local_search/

graphrag-acceleratorの実行
graphragを簡単にAzure上に構築できるIaCとして、graphrag-acceleratorが公開されています。

次の検証編の記事にて、実際にデプロイしていきます。
Azure OpenAIのGraphRAGを解説及び検証(検証編)