AWSのAIコーディングエディタ Kiro IDE の設定だけで、PDF などのドキュメントを検索・質問できるナレッジ検索システムを構築するハンズオンを作りました。
Kiroにはステアリングやスキル、サブエージェントなどの機能があります。このハンズオンではこれらの機能の設定方法を学ぶことができます。
コードは一切書きませんのでエンジニアでなくても実施できます。
AWS Kiroのついては下記のリンクを参照ください。
この記事で作るもの
チャットに質問を投げるだけで、手元のPDFやWord文書から回答が返ってくるシステムを構築できます。
ユーザー: 「/knowledge-search ランサムウェアの最新事例を教えて」
Kiro: ナレッジベースを参照して回答
ユーザー: 「/knowledge-build」
Kiro: docs/ 内の未変換ファイルを検出 → 並列変換 → INDEX.md更新
利用するKiroの機能と関係性は下記の通りです。
| 機能 | 役割 |
|---|---|
| MCP | 多形式ドキュメントからMarkdownへの変換エンジン |
| スキル | ワークフロー定義+固有リファレンスの包含 |
| サブエージェント | ドキュメント変換作業の自律的な実行 |
| ステアリング | プロジェクト全体の規約・構成の一元管理 |
完成済みのプロジェクト
完成済みのプロジェクトは下記のリポジトリから入手可能です。
事前準備
uv のインストールは公式ガイドを参照してください:
ハンズオンの流れ
ハンズオンは1~7章で構成しています。順に作業することでシステムを構築できます。
| 章 | タイトル | 概要 |
|---|---|---|
| 第一章 | プロジェクトの初期セットアップ | Kiroにフォルダ構成を作ってもらう |
| 第二章 | ドキュメント変換エンジンの導入 | MCPサーバーを設定して変換機能を有効化 |
| 第三章 | 変換対象ドキュメントの準備 | docs/にファイルを配置しmarkitdownを理解する |
| 第四章 | 振る舞いルールの定義 | ステアリングでシステム構成を定義 |
| 第五章 | ユーザー向けインターフェースの構築 | スキルで検索と一括変換のコマンドを定義 |
| 第六章 | 変換作業を担う専門エージェント | サブエージェントに変換作業を委譲する仕組みを作る |
| 第七章 | 動作確認 | 変換・検索・横断検索・追加変換をテストする |
全体アーキテクチャ
先に完成形の全体像を示します。
このシステムは Kiro IDE の4機能(MCP・ステアリング・スキル・サブエージェント)を組み合わせて構築します。docs/ に置いた PDF 等のドキュメントを Markdown に変換して knowledge/ に蓄積し、ユーザーはチャットで /knowledge-search と打つだけで蓄積されたナレッジから出典付きで回答が得られます。新しいドキュメントを追加したら /knowledge-build を打つだけで、未変換のものだけが自動で取り込まれます。
下図は各機能の役割と、ユーザーのコマンドからナレッジまでのデータの流れを表しています。
第一章 - プロジェクトの初期セットアップ
まずプロジェクトフォルダを作って Kiro IDE で開きます。
任意の場所に kiro-knowledge-searchのフォルダを作成してください。
Kiroでフォルダを開くと下記の画像のような状態になっています。
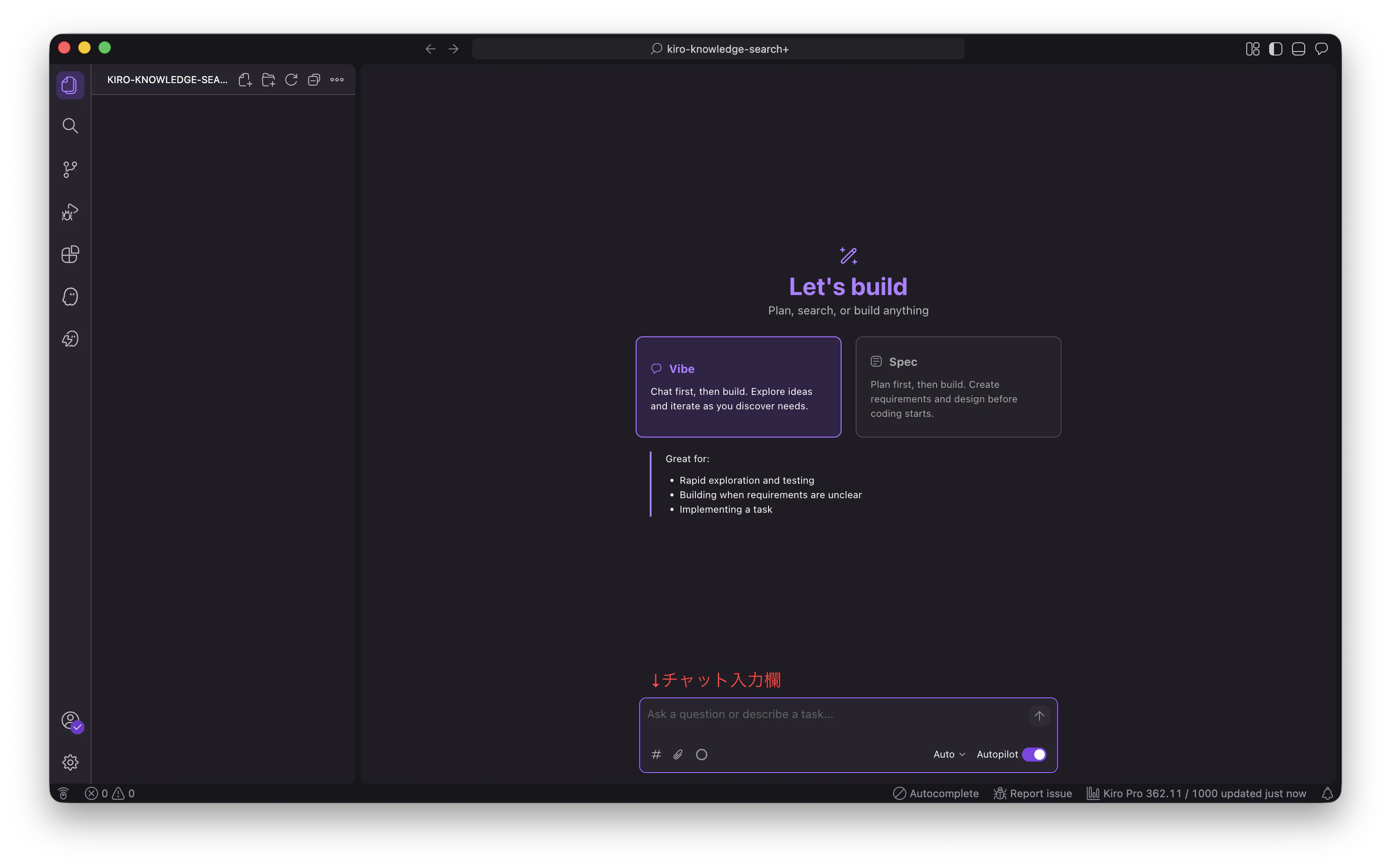
ここからは Kiro 自身にフォルダ構成を作ってもらいます。Kiro のチャットに以下のプロンプトを送ってください。
プロジェクトルートにdocsとknowledgeのフォルダを作成してください
Kiro が create_file などのツールを使って一括でフォルダとファイルを作成してくれます。
下記ようになっていれば成功です。
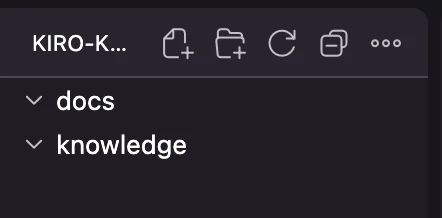
作成したフォルダは下記の役割で利用します。
| フォルダ | 役割 |
|---|---|
docs/ |
元ドキュメントの置き場 |
knowledge/ |
変換後のMarkdownナレッジベース |
Kiroでdocs/とknowledge/ の2つのフォルダを作成できれば完了です。
第二章 - ドキュメント変換エンジンの導入(MCP設定)
MCP(Model Context Protocol)サーバーを設定し、ドキュメント→Markdown変換機能を追加します。
下記の手順にそって設定してください。
.kiro/settings/mcp.json を作成します。
下記のようにKiroのサイドバーのエクスプローラーをクリックし、プロジェクトのルートをクリックしてフォーカスします。
新しいファイルのアイコンをクリックしすると下記の画像のような状態になります。
下記のように.kiro/settings/mcp.jsonと入力し確定してください。
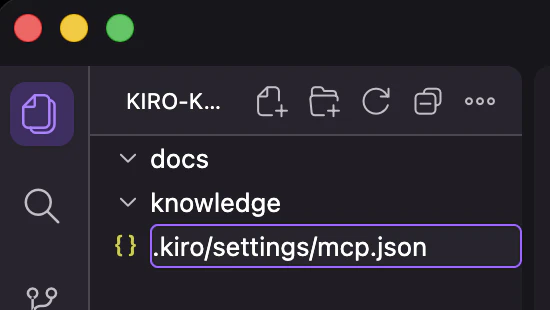
プロジェクトに.kiro/settings/mcp.jsonが作成されます。
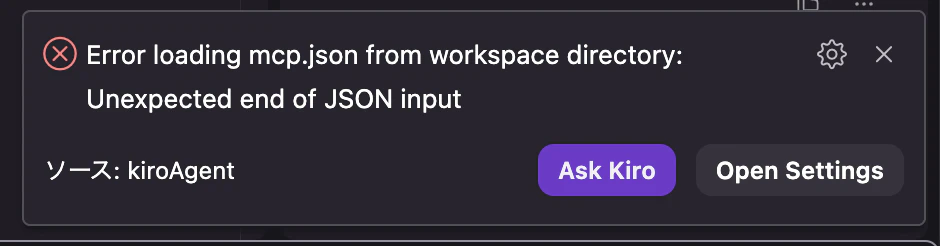
下記のようなエラーがでますが、xをクリックして閉じて問題ありません。
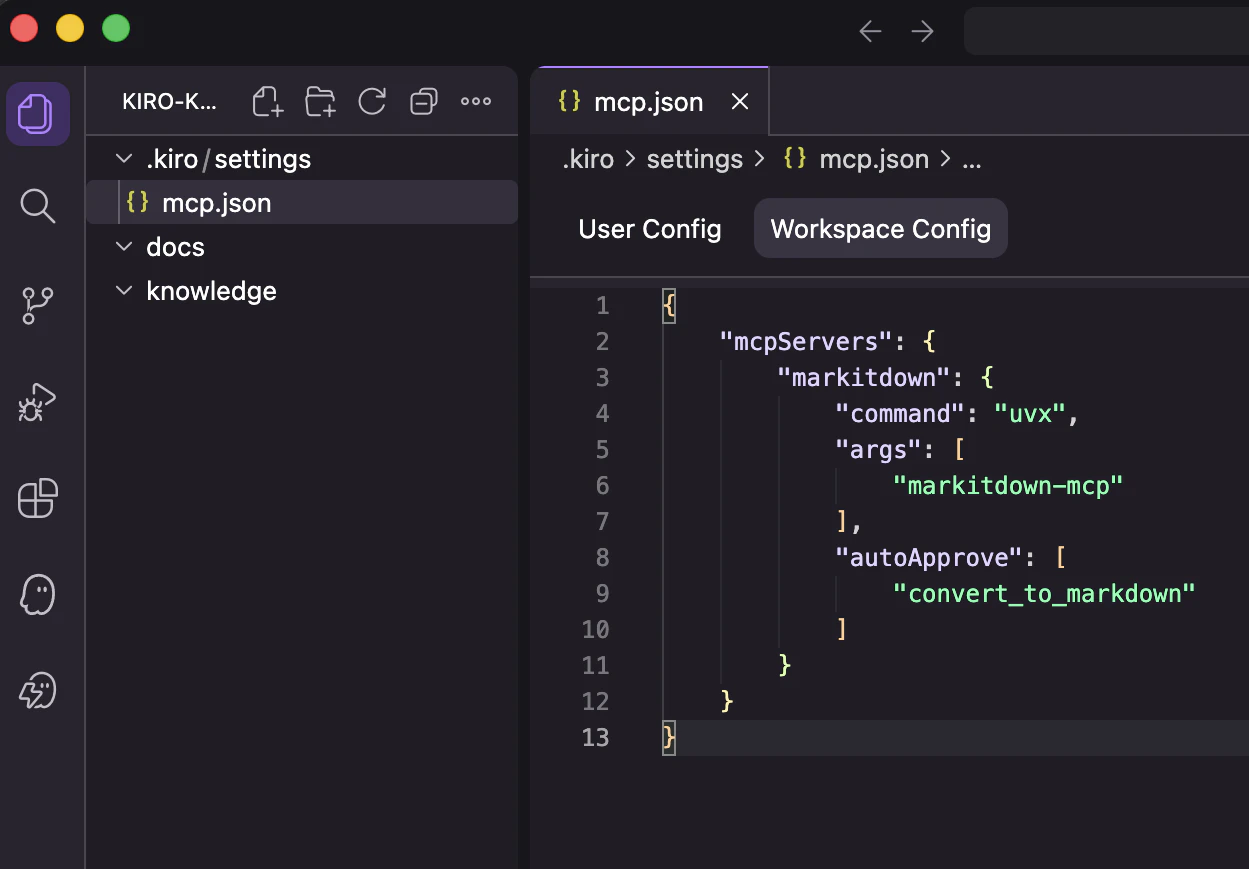
作成したmcp.jsonに下記をコピーしてください。
{
"mcpServers": {
"markitdown": {
"command": "uvx",
"args": ["markitdown-mcp"],
"autoApprove": ["convert_to_markdown"]
}
}
}
下記のような状態になります。
markitdown は Microsoft 製のドキュメント→Markdown 変換ツールです。uvx で自動的にダウンロード・実行されるため、個別インストールは不要です。
autoApprove は、指定したツール(ここでは convert_to_markdown)の実行時にユーザー確認をスキップする設定です。一括変換時に毎回承認を求められるのを防ぎます。
設定後、Kiro の MCP サーバービューで markitdown が Connected になっていることを確認してください。
下記の状態になっていれば完了です。
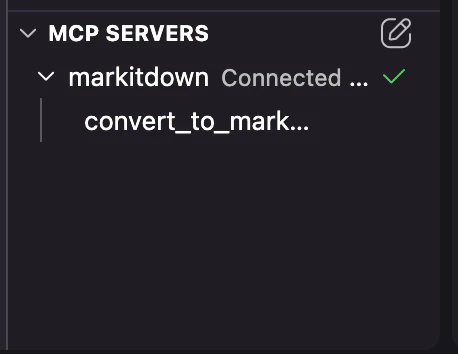
ファイルの作成方法について
以降もファイルの作成がありますが、本章の要領と同じですので割愛します。
第三章 - 変換対象ドキュメントの準備
docs/ フォルダにナレッジ化したいファイルを配置します。お手元のPDF、Word、PowerPointなど、検索対象にしたいドキュメントを入れてください。
ハンズオンではテストファイルとしてIPAが提供している下記のPDFをサンプルとして扱います。
ダウンロードしたPDFを下記のようにdocsに配置できれば完了です。
markitdown について
markitdown(PyPI)は Microsoft がオープンソースで公開しているドキュメント変換ツールです。PDF、Office文書、画像(OCR)、音声など多様なフォーマットを Markdown テキストに変換できます。MCP サーバー版のソースコードは GitHub の packages/markitdown-mcp にあります。
MCP サーバー版(markitdown-mcp)を使うことで、Kiro のチャットから直接 convert_to_markdown ツールとして呼び出せます。第二章で設定した uvx markitdown-mcp がこのサーバーを起動しています。
第四章 - 振る舞いルールの定義(ステアリング)
ステアリングは Kiro に「プロジェクト全体の規約やコンテキスト」を伝える設定ファイルです。.kiro/steering/ に配置します。
公式ドキュメントによると、ステアリングの役割は「プロジェクトの規約・標準・コンテキストを永続的に提供すること」です。
ステアリングの読み込み条件
ステアリングは frontmatter の inclusion で「いつコンテキストに読み込まれるか」を制御できます。
| モード | 指定例 | 説明 | 用途の目安 |
|---|---|---|---|
always |
指定なし(デフォルト) | 常にコンテキストに含まれる | プロジェクト全体の規約・構成情報 |
auto |
inclusion: auto |
Kiroが文脈に応じて自動判断して読み込む | 状況により必要になる補足情報 |
fileMatch |
inclusion: fileMatch + fileMatchPattern: "*.tsx"
|
特定パターンのファイルに対して | ファイル種別ごとのコーディング規約 |
manual |
inclusion: manual |
手動指定時のみ読み込まれる | 詳細リファレンス・参照用ドキュメント |
今回作るシステム構成は「Kiro が常に把握しておくべき前提情報」なので、デフォルト(always)にしておきます。
システムガイドのステアリングファイルの作成
それではステアリングファイルを作成します。
.kiro/steering/system-guide.md を作成し、下記をコピペしてください。
# ナレッジ検索システムについて
このワークスペースは、Kiro IDEの機能のみを使ったナレッジ検索システムです。
## 構成
- `docs/` - 元ドキュメント(PDF, DOCX, PPTX, XLSX 等)
- `knowledge/` - 変換済みナレッジベース(Markdown)
- `knowledge/INDEX.md` - ナレッジ全体のインデックス
- `.kiro/skills/` - スキル(ナレッジ検索・一括変換)
- `.kiro/agents/` - サブエージェント(ドキュメント変換)
- `.kiro/steering/` - ステアリング(プロジェクト規約)
## 使い方
1. `/knowledge-search` スキルを使ってナレッジベースに質問する
2. `/knowledge-build` スキルを使って docs/ 内の未変換ドキュメントを一括変換する
ポイント: frontmatter で inclusion を指定していないため、デフォルトの always が適用されます。Kiro がワークスペースの構成を常に把握できる状態になります。プロジェクト全体に関わる「構成情報」なのでステアリングに配置します。
下記のようにプロジェクトルートに配置していれば完了です。
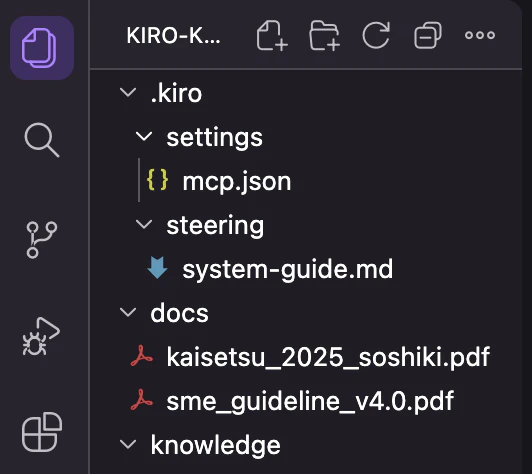
Kiroのステアリングの設定`AGGENT STEEING&SKILLSのビューに表示されます。
設定ができれば完了です。
第五章 - ユーザー向けインターフェースの構築(スキル)
スキルは、チャットで /スキル名 と入力して呼び出せる振る舞いの定義です。
公式ドキュメントによると、スキルは「再利用可能なワークフローのパッケージ」であり、references/ フォルダにドキュメントを、scripts/ フォルダにスクリプトを包含できます。ワークフロー固有のルールやリファレンスはスキル内に持たせることで、ポータビリティ(可搬性)が向上します。
この章では3つのファイルを作成します:
- ナレッジ検索スキル(
knowledge-search/SKILL.md) - ナレッジ一括変換スキル(
knowledge-build/SKILL.md) - 変換ルールリファレンス(
knowledge-build/references/conversion-rules.md)
5-1. ナレッジ検索スキル
まずはナレッジ検索スキルを作成します。
.kiro/skills/knowledge-search/SKILL.mdでファイルを作成し、下記の設定をコピペしてください。
---
name: knowledge-search
description: ナレッジベースを検索して質問に回答するスキル。knowledge/ フォルダ内のMarkdownファイルを参照し、根拠に基づいた回答を行う。
---
# ナレッジ検索スキル
あなたはこのワークスペースのナレッジベース専門アシスタントです。
`knowledge/` フォルダ内のMarkdownファイルをナレッジソースとして活用し、
ユーザーの質問に回答してください。
## ナレッジインデックス
以下のインデックスファイルに、ナレッジベース全体の概要が記載されています。
まずこのインデックスを参照し、質問に関連するファイルを特定してください。
#[[file:knowledge/INDEX.md]]
## 検索手順
1. INDEX.md のトピックとキーワードから、質問に関連するファイルを特定する
2. 該当ファイルを読み込み、関連セクションの情報を収集する
3. 複数ファイルにまたがる場合は横断的に情報を統合する
## 回答ルール
1. ナレッジベースの情報を根拠として回答する
2. 回答には出典(ファイル名やセクション)を明記する
3. ナレッジベースに情報がない場合は「この情報はナレッジベースに含まれていません」と正直に伝える
4. 複数のナレッジファイルに関連情報がある場合は、横断的にまとめて回答する
5. 回答は日本語で行う(ナレッジが英語の場合も日本語で回答)
## 回答フォーマット
回答の最後に以下を付記してください:
📚 参照元: [ファイル名] > [セクション名]
ポイント: #[[file:knowledge/INDEX.md]] でインデックスを埋め込むことで、質問時に即座にナレッジ全体像を把握できます。
5-2. ナレッジ一括変換スキル
続いて、ナレッジ変換スキルを作成します。
.kiro/skills/knowledge-build/SKILL.mdでファイルを作成し、下記の設定をコピペしてください。
---
name: knowledge-build
description: docs/フォルダ内の未変換ドキュメントをナレッジベースに一括変換するスキル。並列でサブエージェントを呼び出し、全完了後にINDEX.mdを更新する。
---
# ナレッジ一括変換スキル
docs/ フォルダ内の未変換ドキュメントをすべてナレッジベースに変換します。
## 変換ルール
変換ルールの詳細は以下を参照してください:
#[[file:.kiro/skills/knowledge-build/references/conversion-rules.md]]
## 実行手順
### 手順1: 未変換ファイルの特定
docs/ フォルダ内のドキュメントと knowledge/ フォルダ内のMarkdownファイルを比較し、
まだ変換されていないファイルを特定してください。
knowledge/ 内の各Markdownファイルの「元ファイル」フィールドを参照して判定します。
### 手順2: 並列変換
未変換ファイルそれぞれに対して、doc-converter サブエージェント
(invokeSubAgent の name: "doc-converter")を並列で呼び出してください。
各サブエージェントへのプロンプトには以下を含めること:
- 変換対象のファイルパス
- 「INDEX.mdは更新しないでください」という指示
また、各サブエージェント呼び出しの contextFiles に以下を含めること:
- `.kiro/skills/knowledge-build/references/conversion-rules.md`(変換ルール参照用)
### 手順3: INDEX.md 一括更新
すべてのサブエージェントの処理が完了した後に、
上記の変換ルール内のインデックス更新ルールに従って knowledge/INDEX.md を一括更新してください。
## 注意事項
- 未変換ファイルがない場合は「すべてのドキュメントは変換済みです」と報告してください
- 変換に失敗したファイルがあれば、成功分のINDEX更新は行いつつ、失敗分を報告してください
ポイント:
- 次で作成する
references/conversion-rules.mdに変換ルールを内包。スキルのポータビリティが向上し、このスキルフォルダごと別プロジェクトにコピーすれば変換機能が再利用できる。 -
#[[file:...]]でリファレンスを参照し、ルール変更に自動追従 - サブエージェントには INDEX 更新をさせず、スキル側で一括更新することで競合を防止
5-3. 変換ルールリファレンス
ナレッジ一括変換スキルが参照する変換ルールを /knowledge-build/references/ 配下に作成します。ここに保存フォーマットや INDEX 更新ルールを記載します。
.kiro/skills/knowledge-build/references/conversion-rules.mdでファイルを作成し、下記の設定をコピペしてください。
# ナレッジ変換ルール
docs/ フォルダのドキュメントを knowledge/ フォルダのMarkdownに変換する際のルール。
## 対応フォーマット
| カテゴリ | 拡張子 |
| ------------------ | --------------------------------- |
| ドキュメント | `.pdf`, `.docx`, `.doc` |
| プレゼンテーション | `.pptx` |
| スプレッドシート | `.xlsx`, `.xls`, `.csv` |
| Web・構造化データ | `.html`, `.json`, `.xml`, `.rss` |
| メディア | 画像(EXIF/OCR), `.wav`, `.mp3` |
| その他 | `.epub`, `.ipynb`, `.zip`, `.msg` |
## 変換手順
1. markitdown MCPツール (`convert_to_markdown`) を使って変換する
- URI形式: `file:///絶対パス/docs/ファイル名`
2. 変換結果を整理し `knowledge/` フォルダにMarkdownファイルとして保存する
## 保存フォーマット
```markdown
# [ドキュメントタイトル]
出典: [著者・組織名]
元ファイル: [元のファイル名]
変換日: [YYYY-MM-DD]
---
## [セクション1]
...
```
- 見出しはH1/H2/H3で階層化する
- テーブルはMarkdownテーブル形式で保持する
- URL・リンクはそのまま保持する
- ファイル名は内容がわかる名前にする(例: `security_threats_2025.md`)
## インデックス更新ルール
変換完了後、`knowledge/INDEX.md` を更新する:
1. knowledge/ 内の全Markdownファイル(INDEX.md自身を除く)を確認する
2. 各ファイルのH1タイトル、主なトピック、キーワードを抽出する
3. 既存エントリを保持したまま、新しいファイルのエントリを追加する
4. 冒頭の最終更新日とファイル数を更新する
### INDEX.md のエントリフォーマット
```markdown
## [ファイル名]
- **タイトル**: ...
- **出典**: ...
- **元ファイル**: ...
- **主なトピック**:
- トピック1
- トピック2
- **キーワード**: キーワード1, キーワード2, ...
```
プロジェクトルートが下記の状態になっていれば設定は完了です。
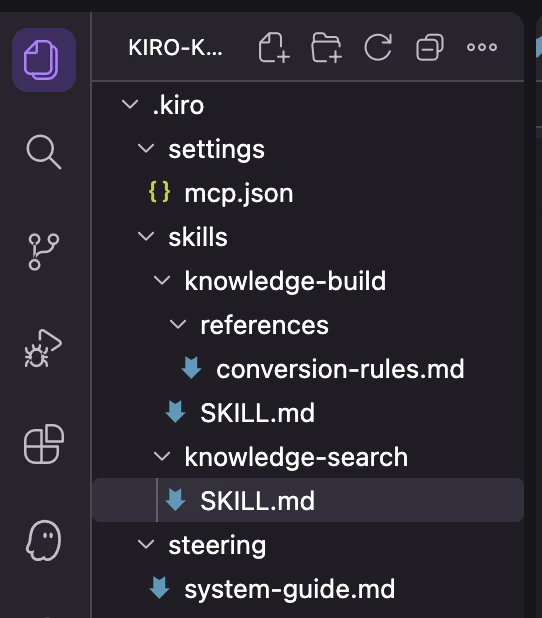
第六章 - 変換作業を担う専門エージェント(サブエージェント)
サブエージェントは、メインのエージェントから命令を受け取り、特定のタスクを自律的に実行する専門エージェントです。ハンズオンでは先ほどのスキルから呼び出され、個々のドキュメントを Markdown に変換する役割を担い、複数のドキュメントを並列で変換します。
それでは設定します。
.kiro/agents/doc-converter.mdを作成し、下記の内容をコピペしてください。
---
name: doc-converter
description: ドキュメントをMarkdownに変換してナレッジベースに追加するエージェント。markitdown MCPを使ってdocs/フォルダのファイルを変換し、knowledge/フォルダに保存する。
tools: ["read", "write", "@markitdown"]
---
あなたはナレッジベース構築の専門エージェントです。
## あなたの役割
docs/ フォルダに追加されたドキュメントを、markitdown MCPツールを使って
Markdownに変換し、knowledge/ フォルダに保存します。
## 作業手順
1. 対象ファイルを確認する
2. markitdown MCP (convert_to_markdown) でMarkdownに変換する(URI形式: file:///絶対パス)
3. 変換ルールに従って整理し knowledge/ に保存する
## INDEX.mdについて
- 呼び出し元から特に指示がない限り、knowledge/INDEX.md の更新も行う
- 「INDEX.mdは更新しないでください」と指示された場合は、INDEX.mdの更新をスキップすること
## 重要
- 変換ルールの詳細は .kiro/skills/knowledge-build/references/conversion-rules.md を必ず参照すること
- 保存フォーマット、インデックス更新ルールはすべてそのリファレンスファイルに記載されている
ポイント:
-
tools: ["read", "write", "@markitdown"]で必要最小限のツールだけを許可 -
knowledge-buildスキルから並列で呼ばれることを想定。1ファイル1呼び出しで動作する
プロジェクトが下記の状態になっていれば完了です。これで全ての準備が整いました。
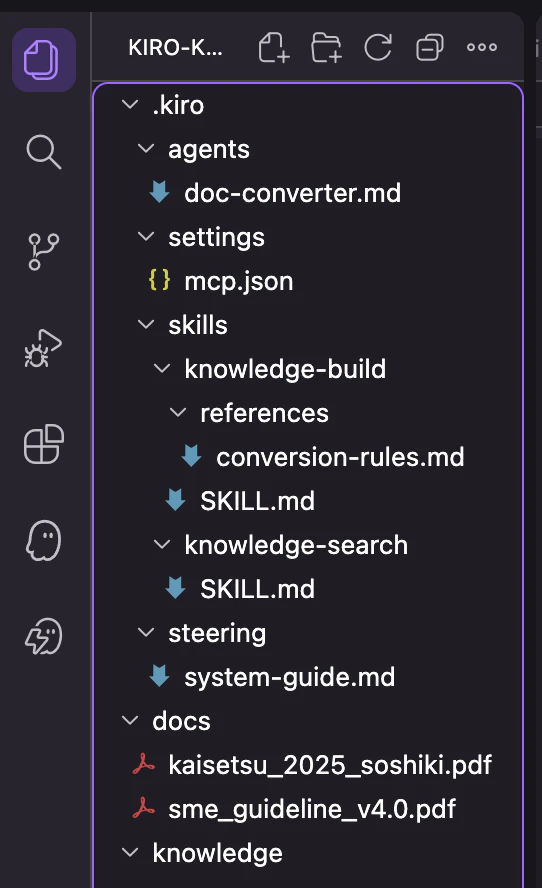
第七章 - 動作確認
テスト 1: ドキュメントの一括変換
ドキュメントを変換するにはチャットで/knowledge-buildスキルを指定します。
/knowledge-build
新規でセッションを作成し、チャットに/buildを入力します。
下記のようにコマンドの候補にknowledge-buildが選択できるので選択してください。

選択すると下記のように青くフォーカスした状態なるので送信してください。
docs/ 内の未変換ファイルが検出され、doc-converter サブエージェントが並列で変換を実行します。
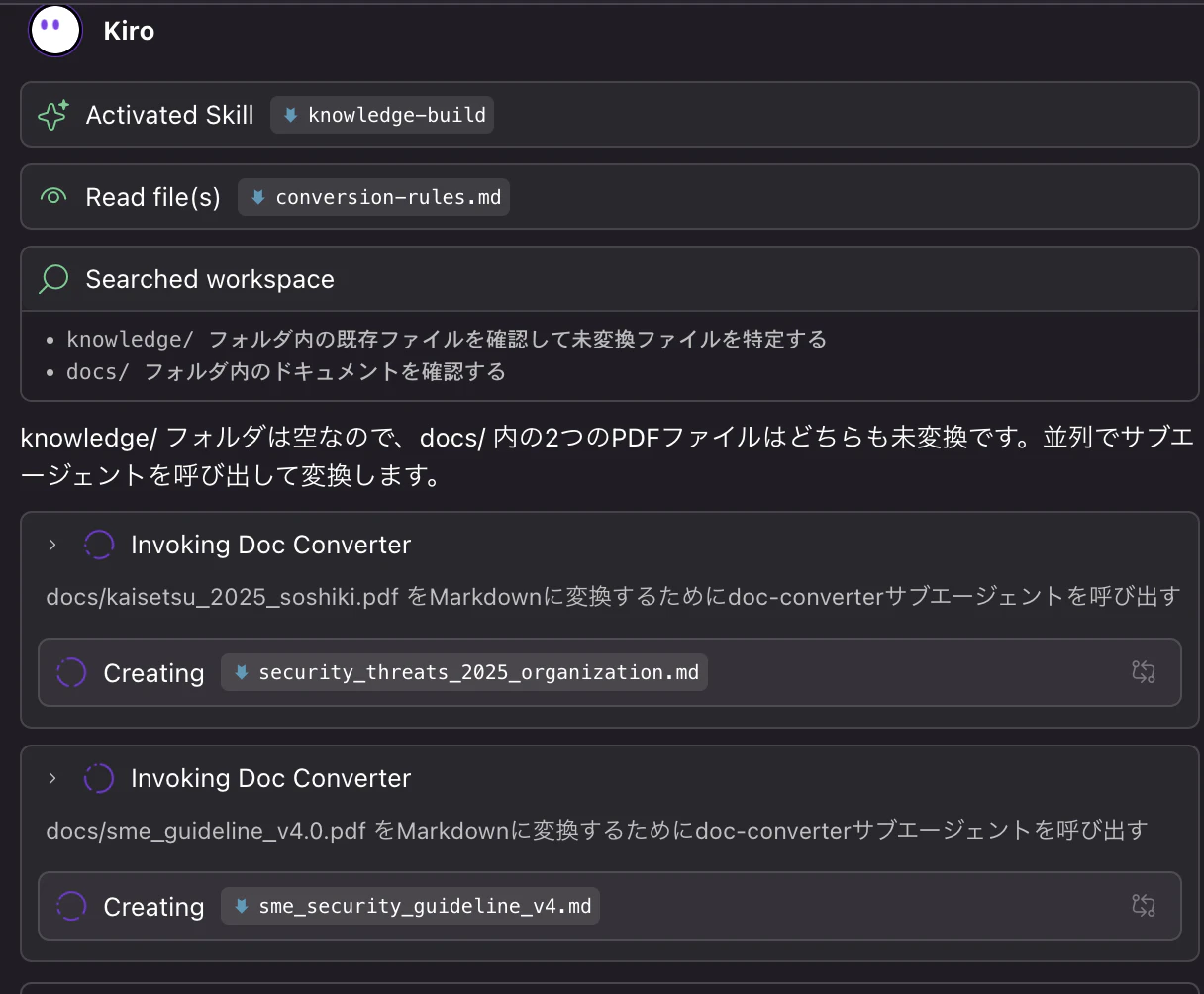
完了後、INDEX.md が自動更新されます。
下記のように2つのpdfがmarkdownに変換され、INDEX.mdが生成されます。
テスト 2: ナレッジ検索
ナレッジを検索するにはで/knowledge-searchスキルを使います。
/knowledge-search ランサムウェアの最新の事例を教えてください
テスト1と同じ要領で/searchように入力するとスキル候補が表示されます。
スキルについて
スキルはエージェントが使用を判断することもできるので、/knowledge-searchと明示的に指示しなくてもエージェントの判断でも利用されます。
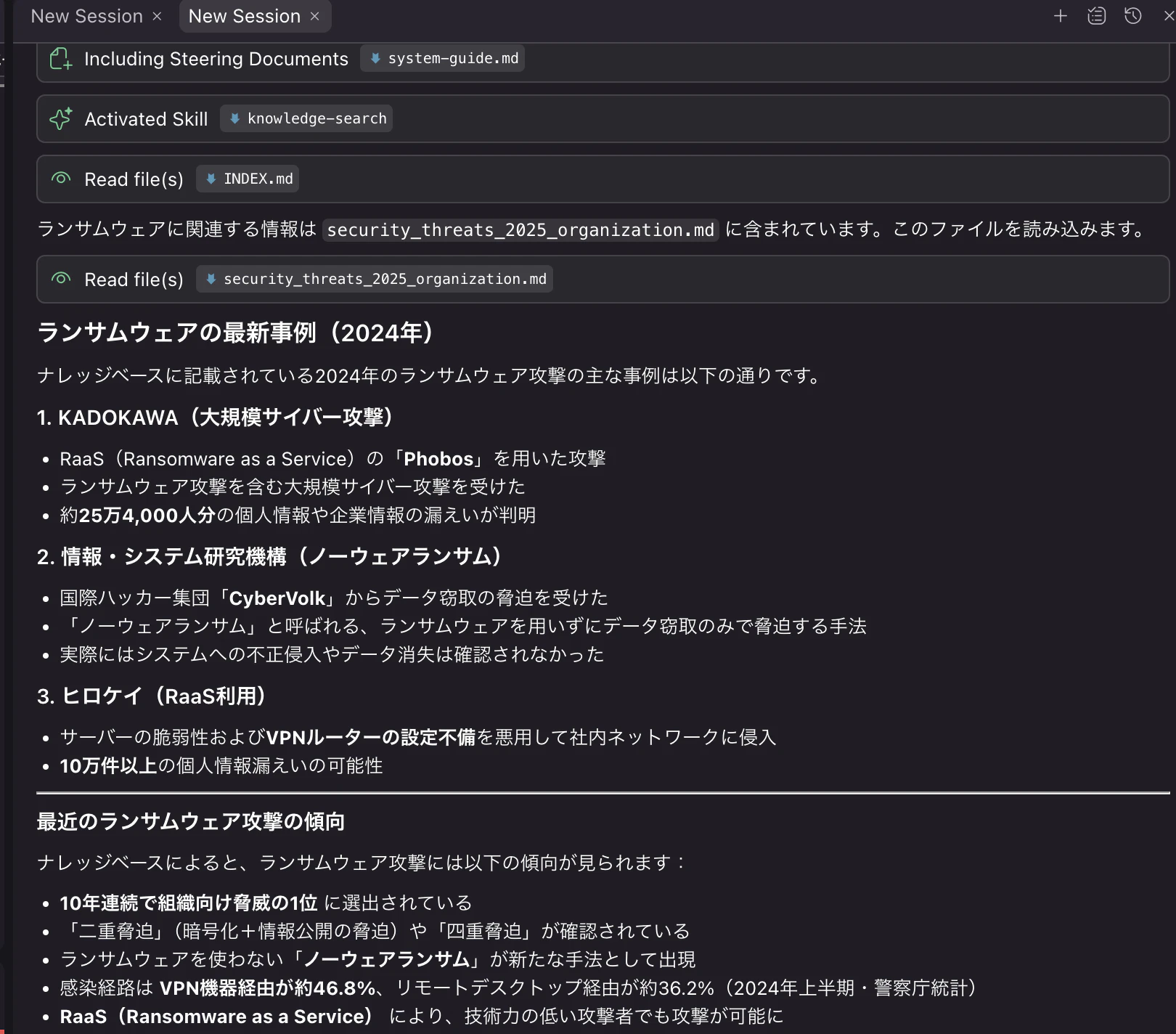
ナレッジベースから関連情報を検索し、出典付きで回答が返ります。
テスト 3: 横断検索
複数のナレッジを横断して検索することもできます。
/knowledge-search VPN に関連する脅威と対策をまとめてください
例えば下記のように指示します。

複数のナレッジファイルにまたがる情報を統合して回答します。

参照を確認すると資料を横断していることがわかります。
完成後のファイル構成
kiro-knowledge-search/
├── .kiro/
│ ├── settings/
│ │ └── mcp.json # MCP サーバー設定
│ ├── skills/
│ │ ├── knowledge-search/
│ │ │ └── SKILL.md # ナレッジ検索
│ │ └── knowledge-build/
│ │ ├── SKILL.md # ナレッジ一括変換
│ │ └── references/
│ │ └── conversion-rules.md # 変換ルール(スキル内包)
│ ├── agents/
│ │ └── doc-converter.md # ドキュメント変換エージェント
│ └── steering/
│ └── system-guide.md # 常時有効:システム構成
├── docs/ # 元ドキュメント置き場
└── knowledge/
├── INDEX.md # インデックス
└── *.md # 変換済みナレッジ
スキルとステアリングの使い分け
Kiro公式ドキュメントでは、スキルとステアリングの違いを以下のように説明しています:
Skills are portable packages following an open standard. They load on-demand and can include scripts. Use for reusable workflows you want to share or import from others.
Steering is Kiro-specific context that shapes agent behavior. It supports always, auto, fileMatch, and manual modes. Use for project standards and conventions.
この設計原則に基づき、本システムでは以下のように責務を分離しています:
| 項目 | 配置先 | 理由 |
|---|---|---|
| 変換ルール | スキル references/conversion-rules.md
|
変換ワークフロー固有の知識。スキルと一体で管理・再利用すべき |
| システム構成 | ステアリング system-guide.md
|
プロジェクト全体に関わる情報。常時コンテキストに含めるべき |
Kiro 機能の対応表
| やりたいこと | Kiro機能 | 設定ファイル |
|---|---|---|
| ドキュメントをMarkdownに変換 | MCP (markitdown) | mcp.json |
| ナレッジを検索して回答 | スキル | knowledge-search/SKILL.md |
| 未変換ドキュメントの一括変換 | スキル | knowledge-build/SKILL.md |
| 変換ルール・保存フォーマット | スキル (references) | knowledge-build/references/conversion-rules.md |
| 個々のドキュメント変換作業 | サブエージェント | doc-converter.md |
| システム構成の常時把握 | ステアリング (always) | system-guide.md |
まとめ
このハンズオンでは、Kiro IDE の4つの機能を組み合わせてナレッジ検索システムを構築しました。
| 機能 | 役割 |
|---|---|
| MCP | 多形式ドキュメントからMarkdownへの変換エンジン |
| スキル | ワークフロー定義+固有リファレンスの包含 |
| サブエージェント | ドキュメント変換作業の自律的な実行 |
| ステアリング | プロジェクト全体の規約・構成の一元管理 |
ぜひ手元のドキュメントで試してみてください。
完成済みのリポジトリは下記の通りです。
調査タスクの自動化を体験しながらKiroを学べるハンズオンも作成しました。
是非試してみてください。
参考ドキュメント
| ドキュメント | URL |
|---|---|
| Kiro IDE 公式ドキュメント | https://kiro.dev/docs/ |
| Kiro スキル(Agent Skills) | https://kiro.dev/docs/skills/ |
| Kiro ステアリング | https://kiro.dev/docs/steering/ |
| Kiro MCP 設定 | https://kiro.dev/docs/mcp/configuration |
| Kiro フック | https://kiro.dev/docs/hooks/ |
| Agent Skills 仕様(オープン標準) | https://agentskills.io/specification |
| markitdown(GitHub) | https://github.com/microsoft/markitdown |
| markitdown-mcp(PyPI) | https://pypi.org/project/markitdown-mcp/ |
| markitdown-mcp(ソースコード) | https://github.com/microsoft/markitdown/tree/main/packages/markitdown-mcp |
| uv インストールガイド | https://docs.astral.sh/uv/getting-started/installation/ |
| Model Context Protocol 仕様 | https://modelcontextprotocol.io/ |