やりたいこと
フォルダ内に大量にExcelで作ったファイルがありどれがどれかわからないようになったときに「一つずつ調べるのはだるいな」という気持ちになりません?
そこでフォルダ内の~.xlsxのファイルすべての頭のほうだけHTMLにして出力してやります。
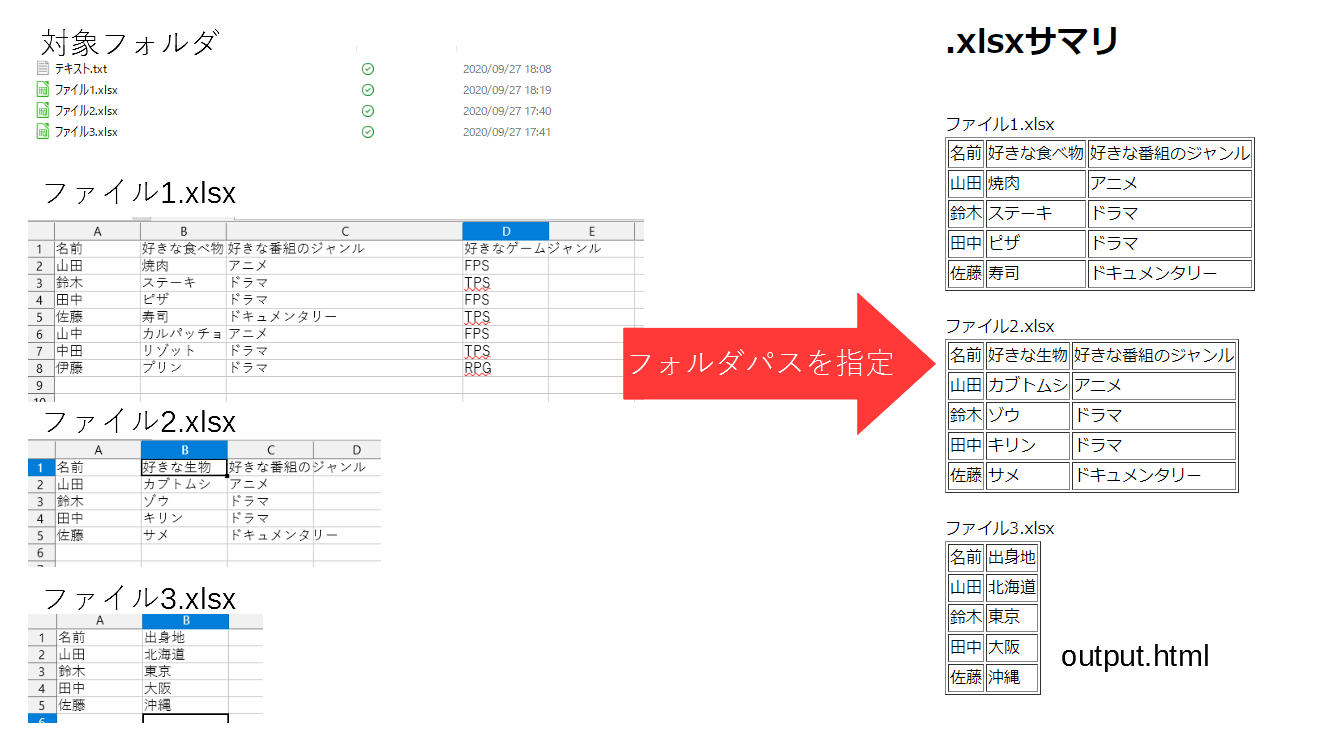
これで探しているファイルがどれかわかって手間も多少は省けるはず…
利用するライブラリなど
Windows 10上でPython 3.8で実行しています。
- os
- フォルダ移動のために利用
- glob
- フォルダ内のファイルを調べるために利用
- io
- ファイルへの書き込みのために利用
- pandas
- .xlsxの読み込み・HTMLへの変換
- webbrowser
- 出力したHTMLをブラウザで開くために利用
ソースコード
ソースコードは以下の通りです。
import glob
import io
import os
import webbrowser
import pandas as pd
folder = input('フォルダパスを入力してください\n')
os.chdir(folder)
files_in_folder = [i.lstrip('.\\') for i in glob.glob("./*")]
xlsx_in_folder = [i for i in files_in_folder if i.endswith('.xlsx')] # .xlsx終わりだけ残す
with io.StringIO() as s:
s.write('<!DOCTYPE html>\n<html lang="jp">\n<head>\n\t<meta '
'charset="UTF-8">\n\t<title>.xlsxサマリ</title>\n</head>\n<body>\n')
s.write('<h1>.xlsxサマリ</h1>\n')
# .xlsxを読み込んで頭5行・頭3列をhtmlにしたものを出力--ここから
for i in xlsx_in_folder:
s.write('<br>\n')
s.write(i) # ファイル名
s.write(pd.read_excel(i, header=None, usecols=[0, 1, 2]).head().to_html(header=None, index=None))
# .xlsxを読み込んで頭5行・頭3列をhtmlにしたものを出力--ここまで
s.write('</body>\n</html>')
output = s.getvalue()
with open("output.html", mode='w', encoding='utf-8') as f:
f.write(output)
webbrowser.open("output.html")
出力
こんな感じでHTMLが出力され、既定のブラウザで開かれます。
