はじめに
Deep learningをフルスクラッチで書いてきましたが,そろそろ内容も分かってきたので,ライブラリを使えるようになろうということで
Tensorflowを導入しました
英語のDocumentationが分かりやすいですが,自分が詰まったところのメモを!
自分なりにクラスとか作って
テンプレートも作成してみていますのでよかったら
まだ未完成ですが
github : https://github.com/Shunichi09/Deep_learning_tensorflow
ちなみにtensorflowのいいところは
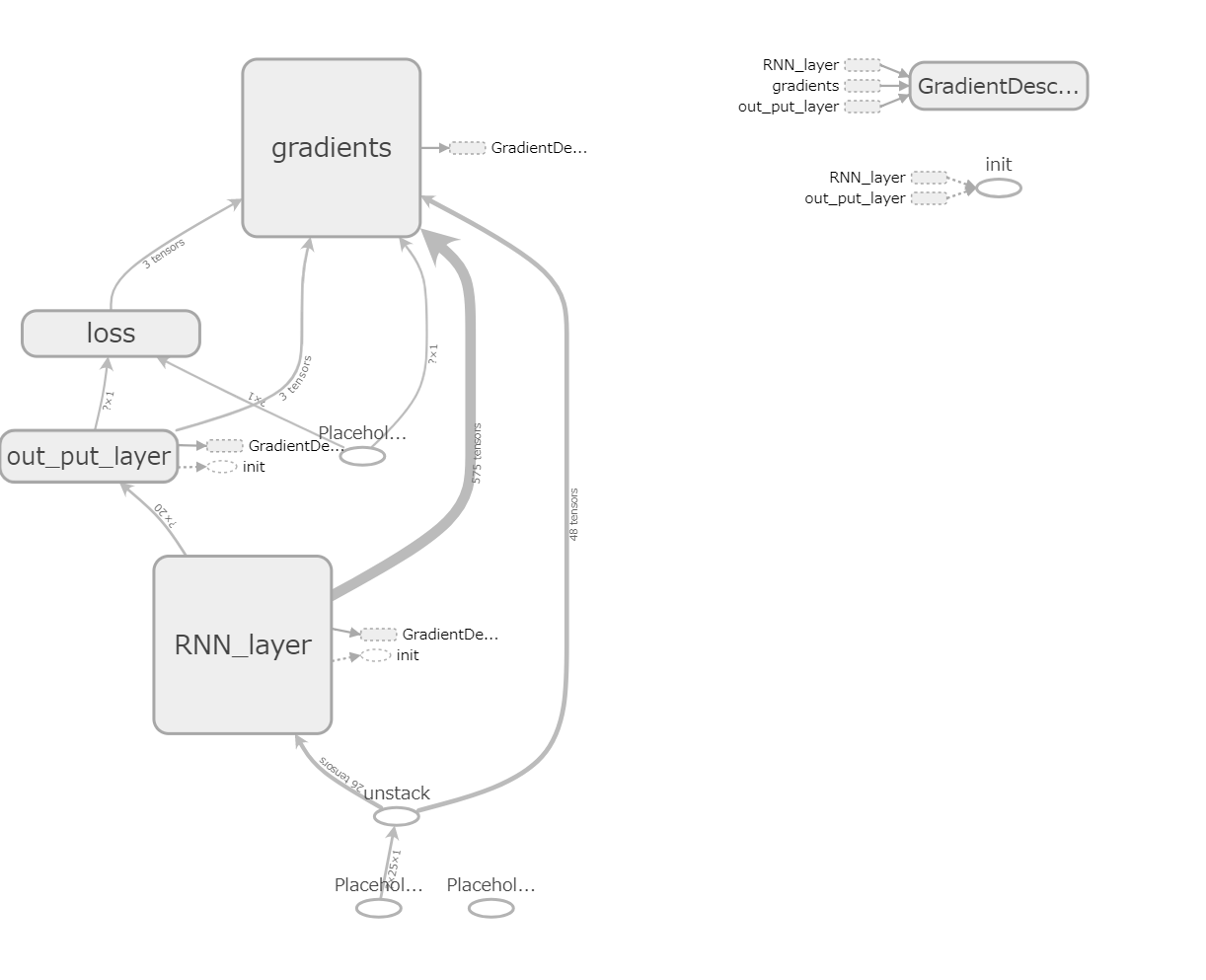
以下の図みたい自分の書いたレイヤーが簡単に見えることです
これレイヤーダブルクリックとかすると細部まで見れます
これがめちゃくちゃ強力です
機械学習においてもっとも大切な可視化が簡単にできますから
おしながき
- 変数管理について
- 名前空間の使用
- sess run と sess eval について
- tensorboardについて
- 重みの保存と読み込みについて
変数管理とは
ここでのポイントは,tensorflowはすべて,tensorで物事を管理するよってことです
つまり,numpyとかではありません なのでもちろん
print(a)
# 出力例 Tensor("out_put_layer/add:0", shape=(?, 1), dtype=float32)
とかで中身を見れないのは有名な話です
しかも
tf.matmul(a, b)
とかは基本的にはtensor同士でやりとりをしないといけません
ではどうやってみればいいんでしょうか?どうやって計算すればいいんでしょうか?
ここがtensorflowを理解する第一歩になるかと思います
tensorflowには大きく分けて2つの変数があります
変数という表現が正しいかはわかりませんが...
- placehoder
- variables
です
それぞれの違いを説明します
placeholder
空の入れ物を作っておく,変数というか,入れ物
NNでいう教師信号tや入力xに使用する
tensorflowは自身のモデルをまず作成することが必要になります
その時に,placehoderという事前になんか分からないけどサイズと入れ物だけ作っておかせて!!
ってやつがこれになります
sessionについては後で説明しますが,こういう形のtensorは後で
sess.run(train_step, feed_dict= {
x:X_[start:end],
t:T_[start:end]
}) # feed_dictで与えられる
こんな感じで与えることができます
この場合事前に
x = tf.placeholder(tf.float32, shape=[None, self.time_length, self.n_in]) # 行ベクトルで入るイメージ
t = tf.placeholder(tf.float32, shape=[None, self.n_out])
このような形で宣言しておくことが必要になります
session 作成あとに
sess.run でfeed dictにあげることが可能!!
ということですね
variables
一方こっちはいわゆる変数です
NNだと,重みとか,バイアスとかに使われます
宣言は
w = tf.Variables('値', name='')
です
なので,値をわたすことが必要になります
ここで良く,名前空間とか,~空間がとかいろいろでてきます
?
ってなるわけですがそんなに面倒な話ではないと思います
さっきの図でいうと,out_put_layerみたいにきれいにまとまっていましたね?
それが空間です
with tf.variable_scope('out_put_name'):
self.weight = weight_variables((self.n_hidden_1, self.n_out), name='W_out'))
self.biase = bias_variable((self.n_out), name='b_out' ))
y = tf.matmul(lstm_output, self.weight) + self.biase # 線形活性
なのでこんな感じで宣言します
つまり,宣言するときにその空間の中に作ってね!!とやることで
tensorboardとかでみるときに複雑になりません
これは,ほかにも空間の作り方がありますが,複雑なことをしなければこれで十分だと思います
ちなみにレイヤーごとに関数化してカプセル化,さらにそのネットワークを同じ重みやバイアスで再利用したい場合は,変数の再利用という別のことが必要になります
これはtf.variablesが呼ばれるたびに新しい名前で作り続けるからです(間違いを防ぐため)
?という人は基本的には無視で良いと思います
with tf.variable_scope("shared_variables") as scope:
i_1 = tf.placeholder(tf.float32, [1000, 784], name="i_1")
my_network(i_1)
scope.reuse_variables() # 再利用可能
i_2 = tf.placeholder(tf.float32, [1000, 784], name="i_2")
my_network(i_2)
sess.run と tensor.evalについて
先ほど変数は簡単には中身をみれません
それは一般的な変数ではなく,tensorを使用しているからだといいました
でも中身みたい!!
ってときは
sessionを作成する必要があります
tensorflowはこのsessionを作成することで計算グラフが作成されます
そうしないとうんともすんともいいません
なのでsessionを作成してから,runすることでうまくいきます
例えばこんな風に!
ここで注意点はtensorflowはsessionをwith文でよく使います
こうすることで,sessionが閉じられていないのに他のことを行ってしまうことを防ぐためです
安全にsessionを使いましょう!
そしてもう一点今回は,tf.constantなので良いですが
変数を使う場合は必ず初期化してからお使いください
以下の一文がないと動きませんのでご用心
# 初期化作業
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
const1 = tf.constant(2)
const2 = tf.constant(3)
with tf.Session() as sess:
const1_result = sess.run(const1)
const2_result = sess.run(const2)
print(const1_result)
print(const2_result)
ここでは,tf.Session()でSessionを作成し,今まで宣言した,変数がすべてsessionへと反映されます
そして,それをrunすることで中身が出てくるわけです
なんとなくrunすることで変数の中身がでてきそうな感じはありますが
const1 = tf.constant(2)
const2 = tf.constant(3)
with tf.Session() as sess:
const1_result = const1.eval(session=sess)
print(const1_result)
の方が分かりやすいと思います?
好みなのかな...
違いはお気づきかと思いますが
- evalはtensorに使用します
- runはsessionに使用します
これ参考になりました
https://seishin55.hatenablog.com/entry/2017/04/23/155707
tensorboardについて
さて可視化できるこのツールが最強なわけですが
このつかいかたはいたって簡単です
LOG_DIR = os.path.join(os.path.dirname(__file__), 'log') # これでtensorboard使える
if os.path.exists(LOG_DIR) is False:
os.mkdir(LOG_DIR)
file_names = os.listdir(LOG_DIR)
for file_name in file_names: # logファイルが残っていたら消去
os.remove(LOG_DIR + '/' + file_name)
# ここまではtensorboard使うためのプログラム
をプログラムの初めに入れておいてください
そして
# SummaryWriterでグラフを書く
summary_writer = tf.summary.FileWriter(LOG_DIR, sess.graph)
summaries = tf.summary.merge_all()
# SummaryWriterクローズ
summary_writer.close()
をsessionを宣言した後に,いれてください(with文使ってもよいと思います)
学習が終わった後にいれると良いと思います
これだけです
少しNNで使うときはやることがあるので以下のサイトを参照
で保存できたらターミナルで
tensorboard --logdir=./log
でいけます
リンク先にいけって言われるので
そのリンク先をブラウザ上にうつとできます,クロームがいいと思います
重みの保存について
NNで大事なのはこれですね
やってみましょう
まず,重みのフォルダを作っておいて
LOG_DIR = os.path.join(os.path.dirname(__file__), 'log') # これでtensorboard使える
PARAM = os.path.join(os.path.dirname(__file__), 'params') # これでparam消せる
if os.path.exists(LOG_DIR) is False:
os.mkdir(LOG_DIR)
file_names = os.listdir(LOG_DIR)
for file_name in file_names: # logファイルが残っていたら消去
os.remove(LOG_DIR + '/' + file_name)
file_names = os.listdir(PARAM)
for file_name in file_names:
os.remove(PARAM + '/' + file_name)
と宣言
これによって,もし重みがあったら消すようにしてます
NN学習用のファイルでこれを宣言し
学習が終わった後に
saver = tf.train.Saver()
saver.save(sess, './params/model.ckpt')
print('Save has done!!')
と書く
これで保存完了
で,使いたいときは
sessionを作成した後に!!
print('Load Parameter...')
saver = tf.train.Saver()
saver.restore(sess, './params/model.ckpt')
print('Load has done!!')
ってすればよい
注意点は
これを宣言したときにはすでに事前に作った変数が存在していること!!!
つまり,まったく同じネットワークの構成じゃないとうまくいきません
当たり前ですが
次回はこれ使ったプログラムで遊んでみます
大体の流れはこんな感じ
学習プログラム
# !/usr/bin/env python3.6
# -*- coding: utf-8 -*-
# tensorflow MEMO
# https://jasdeep06.github.io/posts/Understanding-LSTM-in-Tensorflow-MNIST/
# ↑は、rnn_staticの使い方説明している
import tensorflow as tf
import os, sys
import numpy as np
from sklearn.utils import shuffle
import math
import matplotlib.pyplot as plt
from utils import weight_variables, bias_variable
from optimizer import Adam, SGD
# dataをreadするクラス
class Data_maker():
def __init__(self):
pass
def read_sample_data(self):
'''
sin波(ノイズ付き)の作成
'''
total_size = 250
# 各状態を格納
self.data_dic = {}
self.data_dic['x'] = [i for i in range(total_size)]
self.data_dic['y'] = []
# 何ステップか、何周期
T = 100
for i in range(total_size): # totalsize分繰り返せば終了
noise = 0.05 * np.random.uniform(low=-1.0, high=1.0)
self.data_dic['y'].append(math.sin((i/T) * 2 * math.pi) + noise)
# 正規化
# self._min_max_normalization()
return self.data_dic
def make_data_set(self, time_length, name):
'''
datasetを作成するクラス
引数はT = time_datasize !! name = dataの名前
'''
rate = 0.8 # datasetの割合
data_size = 200
train_size = int(data_size * rate)
x_train = []
t_train = []
# Training_data
for i in range(0, data_size - time_length - 1):
x_train.append(self.data_dic[name][i:i+time_length])
t_train.append(self.data_dic[name][i+time_length])
x_train = np.array(x_train, dtype='f')
t_train = np.array(t_train, dtype='f')
x_test = []
t_test = []
# Test_data(今は同じにしている)
delay = 10
for i in range(delay, delay + data_size - time_length - 1):
x_test.append(self.data_dic[name][i:i+time_length])
t_test.append(self.data_dic[name][i+time_length])
x_test = np.array(x_test, dtype='f')
t_test = np.array(t_test, dtype='f')
return x_train, t_train, x_test, t_test
# RNNを実装する
class Sin_predict_NN():
'''
layerの構成は
LSTM⇒Affine⇒RSM
'''
def __init__(self, input_size, n_hidden_1, batch_size, lr=0.01):
# ハイパーパラメータ系はすべてここに!!
self.n_in = input_size
self.n_hidden_1 = n_hidden_1 # matmulの後のsize
self.n_out = input_size # 今回は出力sizeは同じ
# いつもと同じ感じで溜めておく
self.weights = []
self.biases = []
# 最適化の学習率
self.lr = lr
# バッチサイズ
self.batch_size = batch_size
# time_size
self.time_length = 25
# 記録用
self.history = {}
self.history['loss'] = []
def inference(self, x, keep_prob, name_change=False):
'''
ネットワークの構成の定義
:param batch
:param 隠れ層数
:param dropoutしない確率
'''
# LSTM層
# unpackする(入力)
# 入力のサイズ構成は[batchsize ,time_step, depth(xの次元)]
x = tf.unstack(x, self.time_length, 1)
RNN_name = 'RNN_layer'
out_put_name = 'out_put_layer'
if name_change:
RNN_name = 'RNN_layer_pre'
out_put_name = 'out_put_layer_pre'
# 時間順のtensorへ
with tf.variable_scope(RNN_name): # たぶん同じだわ tf.nn.rnn_cell.BAsicRNNもおなじ
# lstm_cell = tf.contrib.rnn.BasicRNNCell(n_hidden)
# lstm_cell = tf.nn.rnn_cell.BasicRNNCell(self.n_hidden_1)
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(self.n_hidden_1)
lstm_outputs, states = tf.nn.static_rnn(lstm_cell, x, dtype=tf.float32)
lstm_output = lstm_outputs[-1] # 最後のものだけもらう
# 活性化層
with tf.variable_scope(out_put_name):
self.weights.append(weight_variables((self.n_hidden_1, self.n_out), name='W_out'))
self.biases.append(bias_variable((self.n_out), name='b_out' ))
y = tf.matmul(lstm_output, self.weights[-1]) + self.biases[-1] # 線形活性
print(y)
return y
def calc_loss(self, y, t):
'''
平均二乗誤差計算
:param yは出力
:parma tは教師
'''
with tf.variable_scope('loss'):
mse = tf.reduce_mean(tf.square(y - t))
tf.summary.scalar('mse', mse)
return mse
def fit(self, x_train, t_train, epochs=100, batch_size=100, p_keep=0.5, verbose=False):
'''
ここでネットワークを作成する(後で使えるように保持しておく)
:params x_train
:params t_train
:params batch_size
:params p_keeep
:params verbose
'''
# 最適化しない変数の定義(入力と教師)
x = tf.placeholder(tf.float32, shape=[None, self.time_length, self.n_in]) # 行ベクトルで入るイメージ
t = tf.placeholder(tf.float32, shape=[None, self.n_out])
keep_prob = tf.placeholder(tf.float32) # Dropoutするときに使う
self._x = x
self._t = t
self._keep_prob = keep_prob
# モデル作成
y = self.inference(x, keep_prob)
loss = self.calc_loss(y, t)
train_step = SGD(loss, self.lr)
# 初期化作業
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
self._sess = sess
# print(id(self._sess), id(sess)) 同じIDになっていること確認
N_train = len(x_train)
n_batches = N_train // self.batch_size
for epoch in range(epochs):
X_, T_ = shuffle(x_train, t_train) # たぶん同期してシャフルしてくれるんだと思うけど
for i in range(n_batches):
start = i * self.batch_size
end = start + self.batch_size
sess.run(train_step, feed_dict= {
x:X_[start:end],
t:T_[start:end]
}) # feed_dictで変数を与えることができる、dropout時はここにいれる
# 評価(本当はここvalidation_dataね!!)
loss_ = loss.eval(session=sess, feed_dict={
x:x_train,
t:t_train
})
self.history['loss'].append(loss_)
print('epoch = {0} | loss = {1}' .format(epoch, loss_))
w1 = self.weights[-1].eval(session=sess)
print('w1 = {0}' .format(w1))
# 学習時で終了したので
print('Save parameter and Graph...')
# SummaryWriterでグラフを書く
summary_writer = tf.summary.FileWriter(LOG_DIR, sess.graph)
summaries = tf.summary.merge_all()
# SummaryWriterクローズ
summary_writer.close()
saver = tf.train.Saver()
saver.save(sess, './params/model.ckpt')
print('Save has done!!')
return self.history
def main():
input_size = 1
time_length = 25 # 25で与える
batch_size = 10
n_hidden_1 = 20
epochs = 100
# dataset作成
data_maker = Data_maker()
data_maker.read_sample_data()
x_train, t_train, x_test, t_test = data_maker.make_data_set(time_length, 'y')
x_train = x_train.reshape((x_train.shape[0],time_length, 1))
t_train = t_train.reshape((x_train.shape[0], 1))
# print('x_train = {0}'.format(x_train))
# print('t_train = {0}'.format(t_train))
sin_predict_NN = Sin_predict_NN(input_size, n_hidden_1, batch_size, lr=0.01)
history = sin_predict_NN.fit(x_train, t_train, epochs=epochs)
plt.plot(range(len(history['loss'])), history['loss'])
plt.show()
if __name__ == '__main__':
LOG_DIR = os.path.join(os.path.dirname(__file__), 'log') # これでtensorboard使える
PARAM = os.path.join(os.path.dirname(__file__), 'params') # これでparam消せる
if os.path.exists(LOG_DIR) is False:
os.mkdir(LOG_DIR)
file_names = os.listdir(LOG_DIR)
for file_name in file_names: # logファイルが残っていたら消去
os.remove(LOG_DIR + '/' + file_name)
file_names = os.listdir(PARAM)
for file_name in file_names:
os.remove(PARAM + '/' + file_name)
# ここまではtensorboard使うためのプログラム
main()
予測プログラム
# !/usr/bin/env python3.6
# -*- coding: utf-8 -*-
# tensorflow MEMO
# https://jasdeep06.github.io/posts/Understanding-LSTM-in-Tensorflow-MNIST/
# ↑は、rnn_staticの使い方説明している
import tensorflow as tf
import os, sys
import numpy as np
from sklearn.utils import shuffle
import math
import matplotlib.pyplot as plt
from utils import weight_variables, bias_variable
from optimizer import Adam, SGD
from NN_train import Data_maker, Sin_predict_NN
class Sin_predict_NNGen(Sin_predict_NN): # 継承しておく
def predict(self, x_test, sample_time):
'''
保存してあるネットワークを読み込み,予測を行う
:params x_test(reshape済み)
'''
# 予測したもの
self.predict_ys = []
if tf.train.get_checkpoint_state('./params/'):
# 最適化しない変数の定義(入力と教師)
x = tf.placeholder(tf.float32, shape=[None, self.time_length, self.n_in]) # 行ベクトルで入るイメージ
t = tf.placeholder(tf.float32, shape=[None, self.n_out])
keep_prob = tf.placeholder(tf.float32) # Dropoutするときに使う
self._x = x
self._t = t
self._keep_prob = keep_prob
# モデル作成
y = self.inference(x, keep_prob)
loss = self.calc_loss(y, t)
with tf.Session() as sess:
# 読み込み
print('Load Parameter...')
saver = tf.train.Saver()
saver.restore(sess, './params/model.ckpt')
print('Load has done!!')
count = 0
# 予測を行う
while count < sample_time:# samplingtimeよりも小さかったら
predict_y = y.eval(session=sess, feed_dict={
x:x_test
})
self.predict_ys.append(predict_y.flatten())
count += 1
x_test = x_test.flatten()
x_test = np.append(x_test[1:], predict_y)
x_test = x_test.reshape((1, self.time_length, self.n_in))
return self.predict_ys
else:
print('There is NO parmas !! Please Learning')
sys.exit()
def main():
input_size = 1
time_length = 25 # 25で与える
batch_size = 10
n_hidden_1 = 20
# dataset作成
data_maker = Data_maker()
data_maker.read_sample_data()
x_train, t_train, x_test, t_test = data_maker.make_data_set(time_length, 'y')
x_train = x_train.reshape((x_train.shape[0],time_length, 1))
t_train = t_train.reshape((x_train.shape[0], 1))
sin_predict_NNGen = Sin_predict_NNGen(input_size, n_hidden_1, batch_size, lr=0.01) #
x_test = x_test[0, :]
x_test = x_test.reshape((1, time_length, 1))
predict_ys = sin_predict_NNGen.predict(x_test, 250)
plt.plot(range(len(predict_ys)) ,predict_ys)
plt.plot(range(len(t_test)), t_test)
plt.show()
if __name__ == '__main__':
main()