この記事はDTP Advent Calendar 2019 の9日目の記事です。
昨日はtazさんによる『DTPerたちと同人誌作成しています』でした。
Adobe CC アンソロジーは興味深い内容が多く参考にしております。
さて、6日目の記事『データのない紙原稿からテキストを取り出すためにあれこれした話』とかぶり気味ですが……
数年前にスクリーンショットでOCRという記事を書いていますが、実際に仕事で使ってみたのでその所感をまとめました。
OCR(光学式文字認識)
OCRとは、手書きや画像から文字を抽出しテキストデータをして扱えるようにする技術。
今回はCloud Vision APIを利用していますので詳細はドキュメントや他の記事をご参照ください。
Cloud Vision APIドキュメント
作業の流れ
改版の依頼で来たデータはAdobe Illustratorで作られた見開きアウトライン済みのもの。フリーレイアウトなので1ファイルずつだとテキスト整理の方が大変になるのは明白なので必要な部分だけをキャプチャーしてテキスト化していきました。
遭遇した事例
今回の作業では下記のような現象に遭遇しました。
- 記号類は半角になる
- ルビが抽出されないことがある
- 色が付いていると正しく認識されないことがある
- カラムに分かれていると順番がおかしくなることがある
- 分数は正しく認識されない
- ない文字が出現することがある
それでは一つ一つみていきましょう。
上段がCloud Visionに投げた画像で、下段が返ってきたテキストを表示しています。
◎記号類は半角になる
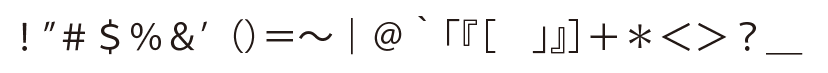 |
|---|
!"#$%&'() =~ | @^[[[ ]』]+*<>?_
これはアメリカの企業だからしょうがないのかな?(languageHintsはja)
◎ルビが抽出されないことがある
 |
|---|
人類守護の神々、エデンの山路を去つて、罪と死の二怪魔がタイグリスの川邊にあらはれたその日
から、地上の形勢は俄かに一變して、第二の天國であつた安樂園にさへ、木枯吹きすさぶ小夜更け
て、夜露つめたい芝生の上に、アダムは獨り足を投げだして、月のない空を仰ぎながら、彗星のやう
に逸し去つた昨日の快樂の行方を慕ひ、隕石のやうに堕落した今のこの身の行末を想ふのである。
:つゆ
小夜更けてのさよが抽出されていませんし、夜露が:つゆとなってしまっています。
◎色が付いていると正しく認識されないことがある
 |
|---|
●(十一)失樂園
後方の●が抽出されていません。
 |
|---|
●(十一)失楽園●
文字色をBlackに変更後だと正しく抽出できいます。
さて、ここで面白い(?)現象を
 |
|---|
●(十一)失楽園
●(十一)失楽園・
文字色がグレーとBlackを同時にCloud Visionに投げると後ろ側が●ではなく・と返ってきてしまいます。
ということで、一行ずつ作業しましたよ……
◎カラムに分かれていると順番がおかしくなることがある
 |
|---|
●(十一)失樂園
人類守護の神々、エデンの山路を去つて、罪と死の
て、月のない空を仰ぎながら、彗星のやうに逸し去
つた昨日の快樂の行方を慕ひ、隕石のやうに堕落し
た今のこの身の行末を想ふのである。
二怪魔がタイグリスの川邊にあらはれたその日か
ら、地上の形勢は俄かに一變して、第二の天國であ
さよ
つた安樂園にさへ、木枯吹きすさぶ小夜更けて、夜
露つめたい芝生の上に、アダムは獨り足を投げだし
なんでこうなった?(笑
カラムの間隔で返ってくるテキストの行ごとの順番が変わるので1カラムずつ作業した方が楽。
(座標も返ってくるので自力で並び順を制御してもいいかも……)
◎分数は正しく認識されない
 |
|---|
分数は14抽出できない
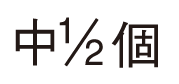 |
|---|
中2個
このように分数は苦手なようです。
 |
|---|
分数は1/4抽出できない
画像のように少しずつずらして1文字ずつにすれば抽出可能!
◎ない文字が出現することがある
サンプル画像が用意できなかったのですが、1と出てくることが度々ありました。何かを誤変換しているのかちょっとわかりませんでした……
まとめ
スクリーンショットをそのままOCRでテキスト抽出できるのはとても便利でした。(数年前の自分えらい)
Cloud Vision APIのOCRは手書き文字にも対応し、精度も高いので利用シーンはますます増えてくるのではないでしょうか。とはいえ今回遭遇したように一筋縄でいかないのも事実。特性を理解し上手に利用していきましょう。
さて、あしたはしたたか企画さん。
どんな記事が出てくるかとても楽しみですね!
おまけ
サンプルデータで使用したテキストは失楽園からですが、本日は著者のジョン・ミルトンの誕生日です。
(繁野天來述 失樂園物語 新潮社版)