はじめに
この記事は データ分析入門してみた(2) - 機械学習 の続編です。
目次
- データサイエンス基礎
- 機械学習の基礎
- 機械学習の応用
- データ分析プロセス(CRISP-DM) ← この記事で説明すること
4. データ分析プロセス(CRISP-DM)
CRISP-DMとは
CRoss-Industry Standard Process for Data Miningの略で、データマイニング・データサイエンス・AI開発などにおいて業界横断で標準的に使えるデータ分析プロセスのこと。
CRISP-DMに沿ってデータ分析を行うことで、効率よくデータ分析を行える。
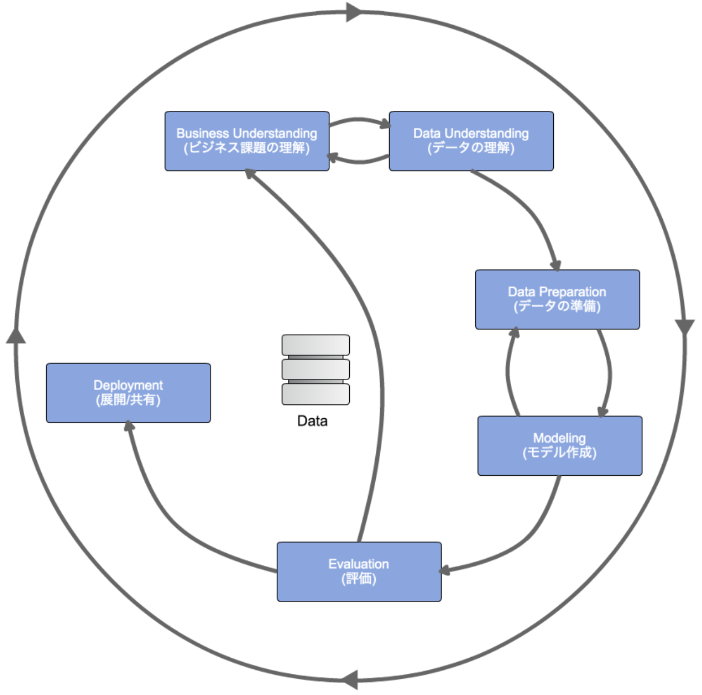
以下で、各フェーズについて説明していく。
フェーズ1: ビジネス理解(Business Understanding)
ビジネスを理解してビジネス課題を特定する。
ただ闇雲に「データ分析」をすれば何か発見できる、と考えるのではなく、「次の一手として何がしたいのか」と、そのために「どういったやり方が考えられるか」を明確にするためにこのフェーズが存在する。
- イシュー(本質的な課題)を特定する
イシューを特定できていないと、意味のある分析結果を生み出すことはできない。
ex: サブスクの会員数が伸び悩んでいる時、どこに原因があるのか突き止めるためにまず、データの基礎分析や可視化を行なっていく。競合の影響で既存会員が解約して行っていることを突き止めた場合、「解約というアクションを取る確率を予測する」という具体的な分析課題になり、モデル構築に落とし込みやすくなる。
フェーズ2: データ理解(Data Understanding)
ビジネス理解で定めた課題を解決するために、必要なデータが揃っていそうか、なければ新たにそれを計測するための仕組みを作るか、課題自体を別な視点から捉えるように考え直すかを決める。
まず、どのような分析によってどのようなことが分かりそうか、仮説を立てる。
そしてEDA(探索的データ分析)のアプローチをとって、仮説を元にさまざまな観点からデータを見ていく。
EDAの作業
-
どこにどんなデータがあるか確認
ER図などをもとに、データの格納場所やデータ間の関連付けなどを確認
(次のデータ準備の段階では、テーブル間のデータの結合が行われる。)
※ データの可視化のためにER図、データ定義書は日頃から整備しておく。これやってないとEDAにかなり時間がかかってしまう。(p150) -
各種統計量の確認
各カラムの平均値・最大値・最小値などの基本的な統計量を確認。
この時、統計量だけだとデータの持つバイアスに気づきづらいので、必ず分布も確認すること。
また、単一のカラムだけでなく複数のカラム間の関係性を見ることも大事(ただし相関関係があっても因果関係があるとは限らないことに注意。) -
欠損値・外れ値の確認
欠損値・外れ値が存在すると推定精度が下がる可能性が高いので、これらを確認することが大事。
フェーズ3: データ準備(DataPreparation)
データを次のモデリングで利用可能な形式に整形する。
データ分析の前加工・前処理(データクレンジング)
この2つのプロセスはかなりの頻度で行ったり来たりを繰り返すことになる。
※ そして、データ分析のプロセスの中で、ここまでの1~3の工程にこそ時間がかかる。
具体的な作業
- データに対するアクセス権限をもらう
- 様々なデータソースに散りばめられたデータを1箇所に集約する()
- ETL(Extract Transform Load)を行って分析を行いやすい形式に変換する
- システムごとに異なるIDの体系を統一するために名寄せする(表記揺れの統一)
- カテゴリ変数をダミー変数化する
- 文字列に対するテキストマイニングなどの処理
- 外れ値除去
- 欠損値の補完
- 型変換
欠損のパターン
-
MCAR(Missing Completely At Random)
「完全に無作為な欠損」 -
MAR(Missing At Random)
「条件付きで無作為な欠損」
データが,測定されている値に依存して欠損する。
ex: 女性の方が男性より体重を計りたくないと考えるので、性別によって欠損率が変わる。 -
MNAR(Missing Not At Random)
「無作為ではない欠損」
欠損確率が欠損データ自体に依存している。
分析に含まれる他の変数を統制した後でも,欠損値の有無が欠損値を持つ変数自身と関係を持つケースを示している。
ex: 収入が低い人ほど収入を報告しない。
cf: https://mmbiostats.com/missing_value_classification
欠損値がある場合、欠損があるサンプル自体を削除するか、欠損箇所を何らかの値で埋める(補完法)の2つのアプローチがある。
特徴量エンジニアリング
前処理を施した後に、有効な特徴量を追加していく。モデルの精度を高める上で重要なフェーズ。
具体的なテクニック
- 日付の処理:日付を年月日や曜日データにブレークダウン
- カテゴリ特徴量に対しての変換処理:One-Hot Encoding, Label Encoding等
- 特徴量同士の掛け合わせで特徴量生成
- クラスタリングで特徴量生成
※ 特徴量エンジニアリングのテクニックを知っておくのは大事だが、近視眼的になりすぎないよう注意。
データマネジメント
データマネジメントとは、データを正しく蓄積・管理することであり、適切に活用できるようにしビジネスに繋げることが目的である。
データ活用の前にきちんとデータマネジメントを行うことが重要である。
- ゴールから逆算
- 設計書の作成・保守
- 無駄なBI・レポーティングを減らす(目的の明確化)
※ データマネジメントはさまざまなステークホルダーで進めるべし。保守運用の観点のメリットを優先してしまい、ビジネス要件を満たせないデータ基盤が出来上がってしまうので注意。
フェーズ4: モデル構築(Modeling)
このプロセスでは様々な手法を利用して、最も良い結果を出すような手法を見つける。
モデリング自体はライブラリが用意されており、それほど時間はかからない。
モデル構築の際に注意することは以下3つが挙げられる。
注意点1: 過学習
過学習とは、手元にあるデータだけにピッタリ合いすぎて将来のデータに対して全く合わないモデルを作ってしまうこと。データには必ずノイズ(誤差)があるため、完璧に当てることはほぼ不可能。フィッティングしすぎるとノイズまで考慮したモデルになり、将来のデータには当てはまらなくなる。
回避方法は下記がある。
-
バリデーション
学習データとテストデータに分けて検証すること。学習データにはよく推定できているのにテストデータにはうまく推定できない場合、過学習を疑うことができる。 - 情報量基準を用いる
AIC(赤池情報量基準)やBIC(ベイズ情報量基準)などを用いてモデル評価もできる。特徴量の入れすぎで過学習してしまうことを防ぐことができる。
しかしながらバリデーションにより評価することが一般的であり、あまり登場機会は多くない。
バリデーションの種類
バリデーションには下記2つがある。
-
ホールドアウト法
モデルを作る学習データと、モデルを評価するテストデータに分割して評価する。
ホールドアウト法は大量のデータセットがあり、モデルの推論に時間がかかる場合などに利用される。 -
交差検証法(クロスバリデーション法)
複数に分かれたデータセットを一つ一つ順番にテストデータにしてモデルを講師くし、最終的に平均値を取り精度を算出する。
一回の訓練が数時間以内で終わるものであれば、交差検証を利用することが多い。
リーゲージ
本来得られるはずのないデータを学習の段階で使用してしまうこと。
データをそのままランダムで学習データとテストデータに分けると、未来の知り得ないデータを学習に使って過去のデータで精度を検証するという状態になる。
これは現実に起きえないため、訓練時には精度の高いモデルができていても、実装してみると全く機能しないことになるため注意。
注意点2: 多重共線性
回帰分析などのモデル構築の際に、説明変数の中に、相関係数が高い組み合わせが存在すること。つまり、モデル内の一部の説明変数が他の説明変数と相関している場合に起きる状態。
そのため特徴量の投入しすぎに注意。
※ 機械学習の文脈で高い予測精度を求める場合は考慮する必要がないため、あまり気にせず特徴量を投入するケースも多い。
注意点3: 不均衡データ
データ構造に偏りがあり、あるクラスは多いが別のクラスのデータは極端に少ないこと。
これがあると一見精度は高そうだが異常データは検知できないモデルを構築してしまう危険性がある。
回避方法は下記がある。
- アンダーサンプリング(サブサンプリング)
最も定番な方法で、少数派のデータ群に合わせて多数派のデータ群を削る方法。
ただし、少数派のデータが少なすぎるとサンプルサイズが大きく減ってモデルの精度が悪くなるため、少数派にも一定量データ必要。 - オーバーサンプリング
アンダーサンプリングとは逆に、少数派のデータを多数派に合わせて増やす方法 - 重み付け
少数派のサンプルに対して重みをつけて重要視する方法。少数派の重みを高める。 - 異常検知問題として扱う
あまりにもデータに偏りがある場合は、そもそも問題の定義を分類問題ではなく異常検知問題として扱ってしまう方法もある。
正常データをもとに正常空間を作り、定めた閾値を超えるデータに関しては異常値とみなす。
フェーズ5: 評価(Evaluation)
モデルの評価。モデル評価が適切にできれば、不適切なモデル選定を減らすことができる。
最初に定めたビジネス上の課題を解決するのに十分な精度が出るものになっているかといった観点で考える。
過学習・多重共線性・不均衡データなどに注意。
評価指標
実務では、下記の中から最適な評価指標を選ぶ。また単一ではなく複数の指標を見ることで、多角的な観点でモデル選定が可能になる。
回帰タスク(量的データを予測するタスク)
- MAE
- MSE
- RMSE
-
寄与率(決定係数)
決定係数は0~1だが、1に近いほど回帰式の当てはまりが良いということになる。決定係数は0.8は超えたい。
※ 評価指標を比べるだけでなく、分布を確認することで精度向上のヒントを見つけられる。
分類タスク(質的データを予測するタスク)
- 正解率
全てのサンプルの中で実測値と予測値が一致した割合。 - 適合率
異常と予測されたクラスのうち、実際に以上だったクラスの割合。 - 再現率
実際に異常だったクラスのうち、どのくらい異常と予測されたかの割合。 - F値
適合率・再現率はトレードオフでありどちらが高い方が良いかはビジネスケースによる。
(ex: 病気に罹患しているかの判定には、なるべく病気にかかっている事実を見逃さないために、再現率が高い方が望ましい)
この2つを組み合わせた指標をF値という。
評価ステップ
- 机上検証
すでの持っている手元のデータから評価する。バリデーションにより検証する。 - 段階的な検証(いきなり全範囲に適用させない)
作成したモデルを用いた予測を、限定的な範囲に適用させて、しばらく実験的に様子を見る。
ex: 一部の店舗に売上予測を導入する
フェーズ6: 実装(Deployment)
データ活用のプロセス。
モデルを作成してビジネス的に使えそうということがわかったらそれで終わりではない。 得られた結果を元に具体的なアクションを取る。
実装時の注意点
主に、現場でのオペレーションとの乖離による障壁が存在する。
- データホルダーだけで進めるのではなく、業務要件やビジネス設計を明確にして、ビジネスサイドとしっかり共有しながら実装を進める。そうしないと導入後は無用の長物となることがある。
- 短期的に機械学習で最適化を行うことが、長期的な最適にはなっていない可能性がある。短期的なマーケティング施策にのみ機械学習を実装する手もある。
- モデルの保守運用の体制を整えておく。そうしなければモデルはどんどん形骸化して当てはまらなくなっていく。モデル構築は一回で終了ではなく、ユーザの行動の変化など常に最新の情報を反映させてモデルも更新していく。
- 誰でも後から見直せるドキュメント作成をしておく。