はじめに
運用AWSアカウントにあるDynamoDBからデータを抽出、
開発AWSアカウントのS3に格納をGlueで行う。
一見そこまで難しくないかなという見積もりだったのですが・・・
これが自分にとってかなりハードルが高かった作業だったので、
備忘録として残しておきたいと思います。
目次
1.事前準備及び前提条件
2.ポリシー作成
3.AWS Glue Studioでスクリプトを頂戴する
4.DynamoDBテーブル読み込み
5.DynamoDBとS3のマッピング
6.S3へ出力するためのスクリプト
7.Glue JOB作成
8.処理結果
9.おわりに
10.参考ドキュメント
1.事前準備及び前提条件
やりたいことのイメージ図

大事だと思うところ4点挙げておきます。
1.クロスアカウントの設定
運用AWSアカウント側で以下権限を持ったロール作成を行います。※1
・DynamoDBの参照権限
・信頼されたエンティティに<開発AWSアカウント>を追加
作成後ロールのarnを開発AWSアカウントに連携します。
arn:aws:iam::<運用AWSアカウント>:role/role-dynamoDBReadOnlyAccess-SnowFlake
2.GlueでPysparkを動作できるようにインストールしておきます。
3.DynamoDB内の情報を取得しておく。
・テーブル名
・リージョン
・カラム名とデータ型
4.S3やGlueはすでに運用されている想定で行います。
2.ポリシー作成
<開発AWSアカウント>が<運用AWSアカウント>のDynamoDBへアクセスできるようにポリシーを作成します。※2

AWSコンソール>IAM>ロールと降りていき既存のロールにポリシーを作成します。
今回は「GlueDev」ロールにポリシーを作成します。ロールをクリック。

今回初めてロールを作る場合は画像にある「タイプ:AWS管理」の3つのポリシーも追加してください。
既存ロールにポリシーを追加する場合は赤枠の「許可を追加」をクリックします。

するとドロップダウンリストが出てきますので、
「インラインポリシーを作成」をクリックします。

「ビジュアルエディタ」と「JSON」タブのうちJSONタブを開き、
以下のスクリプトを入力します。
{
"Version": "2012-10-17",
"Statement": {
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam::<運用AWSアカウント>:role/role-dynamoDBReadOnlyAccess-SnowFlake"
}
}
その後、下にスクロールし「ポリシーの確認」をクリックします。

ポリシー名を記入します。今回は「dynamodb_cross_account」で作成しました。
「ポリシーの作成」をクリックして完了です。
3.AWS Glue Studioでスクリプトを頂戴する
AWSコンソール>AWS Glueを開きます。

AWS Glue Studio を開きます。※3

「View jobs」をクリック

デフォルトでは赤枠の箇所がS3になっていますのでDynamoDBに設定を変更しま
す。
その後「Create」をクリック

フロー図が表示されたら「Script」タブをクリックします。

スクリプトを全部コピーします。

import sys
from awsglue.transforms import *
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.utils import getResolvedOptions
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node DynamoDB table
DynamoDBtable_node1 = glueContext.create_dynamic_frame.from_catalog(
database="", table_name="", transformation_ctx="DynamoDBtable_node1"
)
# Script generated for node ApplyMapping
ApplyMapping_node2 = ApplyMapping.apply(
frame=DynamoDBtable_node1, mappings=[], transformation_ctx="ApplyMapping_node2"
)
# Script generated for node S3 bucket
S3bucket_node3 = glueContext.write_dynamic_frame.from_options(
frame=ApplyMapping_node2,
connection_type="s3",
format="json",
connection_options={"path": "", "partitionKeys": []},
transformation_ctx="S3bucket_node3",
)
job.commit()
上記の取得してきたスクリプトをベースにして編集していきます。
4.DynamoDBテーブル読み込み
# Script generated for node DynamoDB table
DynamoDBtable_node1 = glueContext.create_dynamic_frame.from_catalog(
database="", table_name="", transformation_ctx="DynamoDBtable_node1"
)
# Script generated for node DynamoDB table
DynamoDBtable_node1 = glueContext.create_dynamic_frame.from_options(
connection_type="dynamodb",
connection_options={
"dynamodb.region": "<リージョン名>",
"dynamodb.input.tableName": "<DynamoDBテーブル名>",
"dynamodb.sts.roleArn": "arn:aws:iam::<運用AWSアカウント>:role/role-dynamoDBReadOnlyAccess-SnowFlake"
},
transformation_ctx="DynamoDBtable_node1",
)
編集後の構文は参考ドキュメント※2のリンク先を参照してください。
DynamoDBの情報と連携されたロールを設定しています。
5.DynamoDBとS3のマッピング
次はDynamoDBとS3のマッピングを行います。
# Script generated for node ApplyMapping
ApplyMapping_node2 = ApplyMapping.apply(
frame=DynamoDBtable_node1, mappings=[], transformation_ctx="ApplyMapping_node2"
)
# Script generated for node ApplyMapping
ApplyMapping_node2 = ApplyMapping.apply(
frame=DynamoDBtable_node1, mappings=[
("DynamoDB側の項目1","データ型","S3側に出力する項目1","データ型"),
("DynamoDB側の項目2","データ型","S3側に出力する項目2","データ型"),
("DynamoDB側の項目3","データ型","S3側に出力する項目3","データ型"),
("DynamoDB側の項目4","データ型","S3側に出力する項目4","データ型"),
.
.
.
("DynamoDB側の項目N","データ型","S3側に出力する項目N","データ型")
],
transformation_ctx="ApplyMapping_node2"
)
DynamoDB側の項目とターゲットになるS3へ出力する際のマッピング作業になります。
括弧内前半はDynamoDBの内容、後半はS3の内容になります。
今回はDynamoDBの項目名とS3の項目名は同じ名称にしました。
6.S3へ出力するためのスクリプト
ここに関しては特に難しいことはありません。
格納するS3のファイルパスを設定します。
# Script generated for node S3 bucket
S3bucket_node3 = glueContext.write_dynamic_frame.from_options(
frame=ApplyMapping_node2,
connection_type="s3",
format="json",
connection_options={"path": "", "partitionKeys": []},
transformation_ctx="S3bucket_node3",
)
# Script generated for node S3 bucket
S3bucket_node3 = glueContext.write_dynamic_frame.from_options(
frame=ApplyMapping_node2,
connection_type="s3",
format="json",
connection_options={"path": "<格納したいS3パス>", "partitionKeys": []},
transformation_ctx="S3bucket_node3",
)
7.Glue JOB作成
レガシー版でジョブ作成を行いました。(新しいバージョンにも慣れないとですね・・・)
「ジョブの追加」をクリックします。

任意のJOB名を記載後、Typeを「Spark」、
Glue versionを「Spark 3.1 Python 3 (Glue Version 3.0)」、
このジョブ実行では「ユーザーが作成する新しいスクリプト」を選択します。

スクリプトが保存されているS3パス・・・こちらに関してはスクリプトを保管している場所を指定します。
今回は下部の一時ディレクトリも同箇所に設定しました。

設定後、「次へ」クリックします。

下部へスクロールし、「ジョブを保存してスクリプトを編集する」をクリックします。

4~6で編集したスクリプトを貼り付けて、保存をします。
これにてJOB作成完了しました。

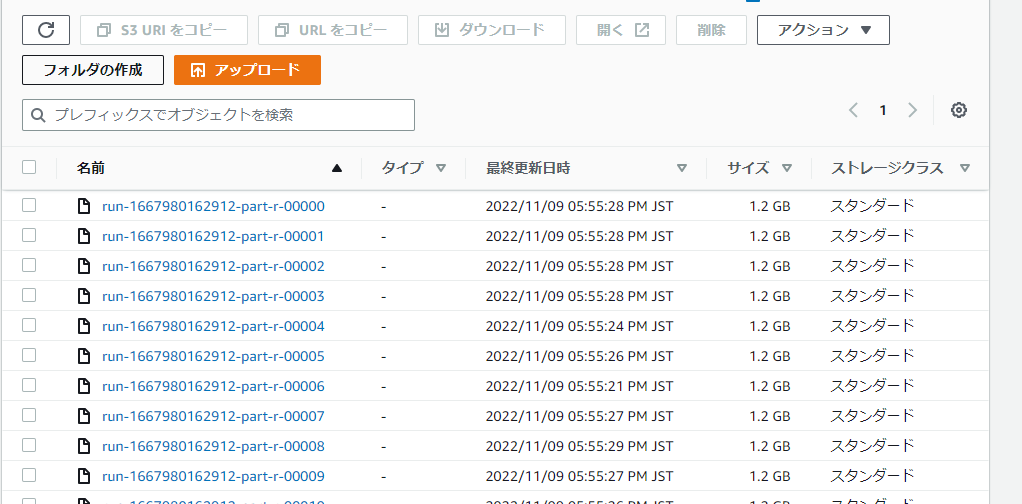
8.処理結果
処理実行をしまして結果がS3に格納されました。
出力形式はJSONファイルになります。
9.おわりに
クロスアカウントの設定をしてGlueでS3に格納という処理が珍しいみたいで、
ネットの海を彷徨ってもなかなか見つからず、
ゴールにたどり着くのに時間がかかってしまいました。
たくさんヒントをいただいたのでなんとか形にできました。
教えてくださった方々にこの場をお借りして感謝を致します。
できるの思い込みは良くないですね・・・
最初は疑ってかからないといけないと反省した事象でした。
この後JSONファイルをテーブルデータにしたお話は以前に投稿しました。
Snowflakeに出力したお話なので併せて読んでみてください。
10.参考ドキュメント
※1
※2
※3
※4