はじめに
JuliaGPU / CUDAnative を試してみて非常に良かったので、とりあえず概要を紹介する。
書ききれなかったことは別記事に仕立てるかもしれない。
CUDAnative は、CuArrays と比べて
- 低レベルのコーディングが必要
- 最適化されていて高速
開発者から最適化についての言及
https://discourse.julialang.org/t/cudanative-is-awesome/17861/2
JuliaGPU / ArrayFire でイジングモデルを計算する
https://qiita.com/Lirimy/items/3ecb550af79cc674e480
※ ArrayFire は CuArrays と同程度に高抽象度の外部ライブラリ
CUDAnative の詳しい使い方は見当たらないが
https://github.com/JuliaGPU/CUDAnative.jl/tree/master/examples
が参考になった
この記事のノートブック
https://nbviewer.jupyter.org/gist/Lirimy/c825ab9cc45c45a2173c52254d4802c9
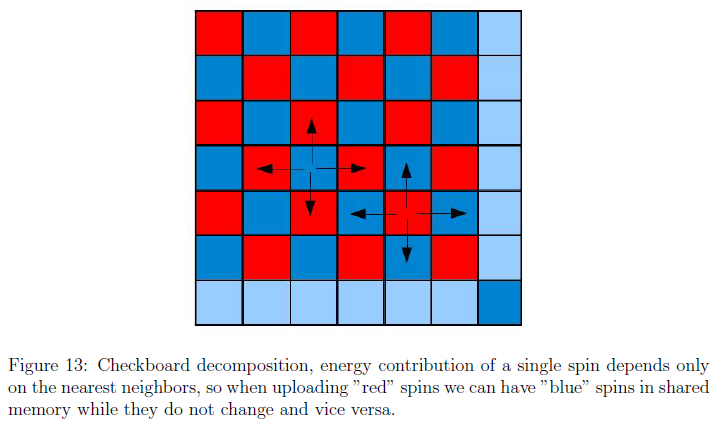
イジングモデルの並列処理
GPU 計算では、多数のコアを利用した並列化によってパフォーマンスを上げている。
一方、イジングモデルでは、スピンは隣のスピンの影響を受けるため、隣接するスピンを同時に評価することができない。
影響が直接及ばないスピンならば、並列に評価することができる。
スピン全体を格子模様で塗りわけて、色ごとに交互に評価すればよい。
Simulation of Ising spin model using CUDA
http://www.vinkovic.org/Projects/MindExercises/radnje/2011_Jurisic.pdf
※ GPU のパフォーマンスは CPU と比較して 50-200 倍との記述あり
CUDA プログラミング
GPU での処理を記述する
GPU で呼び出される関数、いわゆるカーネルを書いていく。
並列処理以外の部分については、黒木玄による CPU 実装をほぼそのまま踏襲した。
https://nbviewer.jupyter.org/gist/genkuroki/4fa46c68c56ee0f3b1a6fc8ec628b9d7
using CUDAnative
function _update!(s, rnd, m, n, β, white=false)
i = (blockIdx().x-1) * blockDim().x + threadIdx().x
j = (blockIdx().y-1) * blockDim().y + threadIdx().y
if i ≤ m && j ≤ n && iseven(i+j) == white
@inbounds ajs = (
s[ifelse(i+1 ≤ m, i+1, 1), j] +
s[ifelse(i-1 ≥ 1, i-1, m), j] +
s[i, ifelse(j+1 ≤ n, j+1, 1)] +
s[i, ifelse(j-1 ≥ 1, j-1, n)]
)
@inbounds prob = CUDAnative.exp_fast(-β * s[i, j] * ajs)
@inbounds s[i, j] = ifelse(rnd[i, j] < prob, -s[i, j], s[i, j])
end
return
end
- CPU で計算するときの For ループの中身だけを抜き出したと考えればよい
- 関数内で、スレッド番号などから、自身が割り当てられたインデックスを求めている
- もしインデックスに対応するスピンがなければ処理をスキップする(スピンの数が 32 の倍数でない場合)
- 格子模様によるマスキングも、同じように処理のスキップで対応する(他の方法もある)
GPU でスレッドを立ち上げる
@cuda マクロでカーネルを呼び出す。
using Random: rand!
using CuArrays.CURAND
m = 3072
n = 4096
rnd = curand(m, n)
s = @. Int32(2 * (rnd < 0.5f0) - 1)
βc = Float32(log(1+sqrt(2)))
threads = (32, 32)
blocks = @. ceil(Int, (m, n) / threads)
# Main
for _ in 1:100
rand!(rnd)
@cuda blocks=blocks threads=threads _update!(s, rnd, m, n, βc, true)
@cuda blocks=blocks threads=threads _update!(s, rnd, m, n, βc, false)
end
- GPU では 32 スレッド (Warp) を単位として処理する
- スレッドのまとまりをブロックという
- ブロックあたりのスレッド数には制限がある(GTX 980 なら 1024)
-
CuArraysで得た配列をCUDAnativeのカーネルで利用できる - 乱数をカーネル内で得るのは
難しそう記述が長くなりそうだったので、引数で渡した
ギャラリー
臨界温度での定常状態(静止画)

全体をおよそ 100000 回評価後
$4096\times3072$ を 1/8 に縮小
臨界温度での定常状態(動画)

$4096\times3072$ を 1/16 に縮小
全体を 16 回評価/フレーム
30 フレーム
ベンチマーク
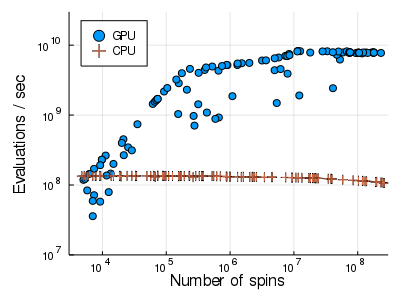
- GPU は CPU と比較して、適した条件ではおよそ 80 倍高速
- モデルのサイズが小さいと CPU とパフォーマンスが変わらない
- 逆に大きすぎても($32768\times32768$)メモリが不足する
- 最低でも $512\times512$ 、できれば $4096\times4096$ は欲しい