概要
Raspberry Pi 5とRaspberry Pi AI Cameraを使い、物体検出モデルYOLO26を変換するまでの手順と、その実行についてまとめました。
一般的にはYOLOv8n,v11nを用いてultralyticsが提供している変換ツールによりrpkファイルを得ることができますが、今回は現在未対応の26nで行いました。PyTorch,Kerasのモデルで、SRAMメモリの容量が収まりさえすれば、YOLO以外のどのようなモデルでもこの手順で変換することができます。
モデルを変換してそのあと実際にやっていることは、これに非常に似ています。調べている最中にこの存在を知ってしまったので、意地でなんとかつくりきりました。
Raspberry Pi AI Cameraについて
IMX500というAI推論に適したセンサーが搭載されているカメラで、Raspberry Pi本体に負荷をかけずに推論が行える、というものです。
最大解像度は4056 × 3040(10bit, 10fps)で、RGBで入力できるテンソルの最大サイズは640 × 640となっています。
Raspberry Pi 5であれば、推論結果をopencvで出力するくらいは余裕でできるような処理の余裕が生まれます
IMX500を使った推論をするための方法はいくつかあります。
はやいほうから順に手順が少なく簡単にできます
- Raspberry Piにインストールするimx500用のパッケージに付属しているモデル(rpkファイル)を使う
picamera2のサンプルコードとあわせれば、ファイルの作成不要でそのまま実行できます。 - YOLOv8n、11nなどの、変換を簡単に行えるモデルを使う
公式チュートリアルに従っていくと、③に比べて短い手順でrpkファイルが得られます。
picamera2のサンプルコードで読み込むことも可能です
(2.のステップについてもここにまとめてます!) - TensorFlow / PyTorchのモデルをMCTを使って圧縮・量子化して、rpkファイルを得る
自分の使いたいモデルを自由に使う(さらには自作のモデルを使う)ことができる反面、変換の手順が他の方法に比べて多い。
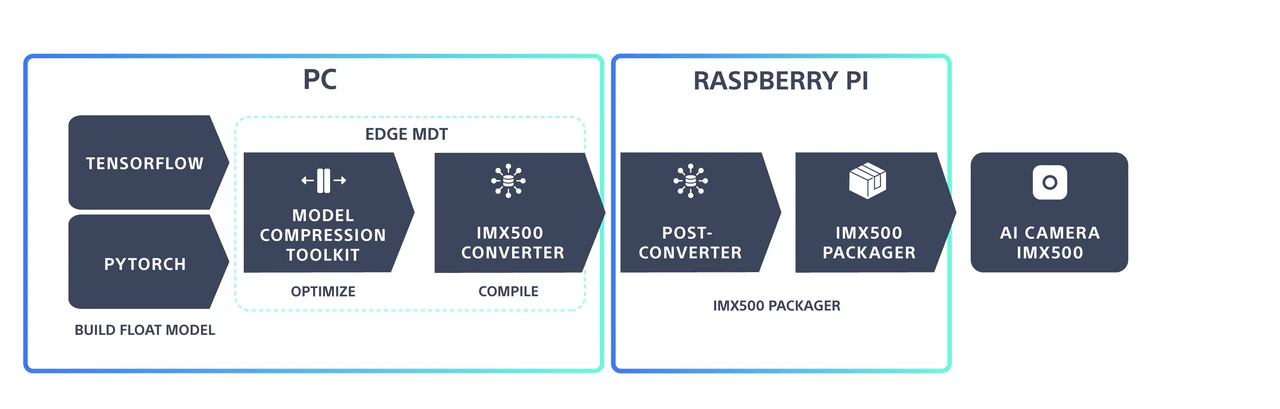
以下、3.の方法についてまとめます。
なお、コードのほとんどはClaude / ChatGPT / Geminiに出力してもらったもので、パラメーター等を一部調整しています
前提となるRaspberry Piでのimx500のセットアップはここでは触れていません。また、Dockerについても細かい説明は省くので、とりあえず実行するためのshellのサンプルをつけます。
モデルの変換
本当はRetinafaceを使おうと思っていたのですがバージョン問題で大沼にはまったため、今回はYOLO26を変換します。
YOLOv8n、YOLO11nはimx500に対して特別なサポートをしており、Ultralyticsがrpkファイルを生成するための処理をまとめてくれています。とっても楽ですので26も対応するといいですね
順序はこんな感じ:
@ WSL Ubuntu 24.04
①YOLOのPytorchファイルをMCTで使い圧縮・量子化(ONNXファイルを作成)
②imx500-converterでPackerOut.zipを作成
@ Raspberry Pi
③imx500-packagerでnetwork.rpkを作成
WSL
WSLでUbuntu 22.04を使います。DockerFileは以下の通りです
Ubuntuのバージョンについては、mct-quantizersとimx500-converterの推奨環境を確認するようにしてください
(とはいえややこしいので、22.04が最も確実に動作すると思います。片方だけが動かない、というようなことも十分ありえます)
FROM ubuntu:22.04
# ---- 基本設定 ----
ENV DEBIAN_FRONTEND=noninteractive \
TZ=Asia/Tokyo \
PYTHONUNBUFFERED=1
# ---- システムパッケージ ----
# Ubuntu 22.04 (jammy) の標準リポジトリに python3.11 が含まれるため
# deadsnakes PPA は不要 (PPA追加は gpg-agent を必要とし Docker 内で失敗する)
RUN apt-get update && apt-get install -y --no-install-recommends \
wget curl git ca-certificates \
libgl1 libglib2.0-0 libsm6 libxext6 libxrender1 \
python3.11 python3.11-dev python3.11-venv \
&& curl -sS https://bootstrap.pypa.io/get-pip.py | python3.11 \
&& ln -sf /usr/bin/python3.11 /usr/local/bin/python3 \
&& ln -sf /usr/bin/python3.11 /usr/local/bin/python \
&& rm -rf /var/lib/apt/lists/*
# ---- pip アップグレード ----
RUN python3 -m pip install --upgrade pip setuptools wheel
# ---- PyTorch (CPU版; GPU不要なら CUDA不要 → 容量節約) ----
# GPU が必要な場合は pytorch-cuda=12.1 等に差し替えてください
RUN pip install --no-cache-dir \
torch==2.4.1 torchvision==0.19.1 \
--index-url https://download.pytorch.org/whl/cpu
# ---- Ultralytics (YOLO26s ロード用) ----
RUN pip install --no-cache-dir \
ultralytics
# ---- MCT (Model Compression Toolkit) ----
# imx500 TPC を含む最新安定版をインストール
RUN pip install --no-cache-dir \
model-compression-toolkit \
sony-custom-layers
# ---- ONNX / OpenCV ----
RUN pip install --no-cache-dir \
onnx \
onnxruntime \
opencv-python-headless
# ---- 作業ディレクトリ ----
WORKDIR /workspace
# ---- スクリプトをコピー ----
#COPY quantize.py /workspace/quantize.py
# ---- デフォルトコマンド ----
CMD ["python3", "quantize.py", "--help"]
pipのconflictについて
MCTとimx500-converterで、依存関係における衝突が起こるようです。
MCTインストール後にimx500-converterをインストールすると、どうやらonnx, networkx, mct-quantizers, edge-mdt-clがアンインストールされるようで、MCTを利用する①のスクリプトがエラーになりました
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
model-compression-toolkit 2.6.0 requires edge-mdt-cl~=1.1.0, but you have edge-mdt-cl 1.0.0 which is incompatible.
model-compression-toolkit 2.6.0 requires mct-quantizers~=1.7.0, but you have mct-quantizers 1.6.0 which is incompatible.
Successfully installed coloredlogs-15.0.1 conv-allocator-3.17.1 edge-mdt-cl-1.0.0 humanfriendly-10.0 immutabledict-4.3.1 imx500-converter-3.17.3 mct-quantizers-1.6.0 networkx-3.0 onnx-1.17.0 onnxruntime-1.21.1 onnxruntime-extensions-0.13.0 ortools-9.9.3963 pandas-3.0.2 protobuf-4.25.5 sdspconv-3.17.1 stringcase-1.2.0 uni-model-10.0.23 uni-pytorch-3.17.1
このため、Dockerをビルドしたあと①をそのまま実行し、そのあとconverterをインストール、②に進むという手順をとるようにしてください
(もう一度①を実行したいときは、dockerコンテナをリビルドするのが一番はやく確実かと思います)
(docker操作)
以下のbuildを①、②のコードをコピーして保存したWSLのディレクトリ上で実行すると、以降の工程でパスを意識せず実行できます。
docker build . -t mct
docker run -it -v "$(pwd)":/workspace mct bash
(dockerコンテナから出るにはCtrl + p→Ctrl + q)
stop, start と attach
docker ps -a
docker stop [Container ID]
docker start [Container ID]
#then:
docker attach [Container ID]
#leave: Ctrl + p→Ctrl + q
⓪「キャリブレーション」用画像の確保
MCTのモデルの量子化には、「キャリブレーション」という操作のためのデータセットを用意する必要があります。
PTQは、学習済みモデルのOutput Tensorが取りえる値の範囲(クリッピング範囲)を求めて、整数表現のモデルに変換します。 クリッピング範囲を求める計算をキャリブレーションとよび、モデルにデータセットを与えて計算します。
ここで適切なクリッピング範囲を求めるには、キャリブレーション用データセットが、実際の入力に対してある程度の網羅性を持つことが必要です。 そこで単純には、モデル学習に使ったデータセットを用いてキャリブレーションを行います。
チュートリアルなどでは、ダウンロードできるデータセットを用意してくれています。
実環境と同じような画像を用意して、それから出力されるテンソルの値の範囲を推定するという作業のようです。一般的なカメラのキャリブレーションとは違う意味ですね
今回は実環境の画像が確保できるので、自分で撮影した画像をつかいます
-
下記は、人が検出できたときに写真を撮影するキャリブレーション画像を確保するためのプログラムです。
標準のmobilenet用rpkを使って検出しているので、Raspberry Piで実行すればすぐ使えるはずです#calibration.py import os import time from datetime import datetime from picamera2 import Picamera2 from picamera2.devices.imx500 import IMX500 # ========================= # 設定 # ========================= MODEL_PATH = "/usr/share/imx500-models/imx500_network_ssd_mobilenetv2_fpnlite_320x320_pp.rpk" SAVE_DIR = "./calibration_images" PERSON_CLASS_ID = 0 # COCO: person SCORE_THRESHOLD = 0.5 CAPTURE_INTERVAL = 5.0 # 秒(連続保存防止) os.makedirs(SAVE_DIR, exist_ok=True) # ========================= # Picamera2 + IMX500 初期化 # ========================= picam2 = Picamera2() imx500 = IMX500(MODEL_PATH) config = picam2.create_preview_configuration( main={"size": (1280, 720), "format": "RGB888"}, controls={"FrameRate": 30} ) picam2.configure(config) picam2.start()#ここまでは一般的なカメラモジュールと同じです print("IMX500 calibration capture started (Ctrl+C to stop)") last_capture_time = 0.0 # ========================= # メインループ # ========================= try: while True: request = picam2.capture_request() metadata = request.get_metadata() outputs = imx500.get_outputs(metadata)#メタデータを渡して、推論結果を得る person_detected = False if outputs is not None: boxes, scores, classes, _ = outputs #pythonのunpacking #outputsはこのモデルでは要素数4の配列。ログに出して構造をみるとよくわかります for box, score, cls in zip(boxes, scores, classes): if score < SCORE_THRESHOLD: continue if int(cls) == PERSON_CLASS_ID: person_detected = True break now = time.time() if person_detected and (now - last_capture_time) >= CAPTURE_INTERVAL: timestamp = datetime.now().strftime("%Y%m%d_%H%M%S") filename = os.path.join( SAVE_DIR, f"person_{timestamp}.jpg" ) print(f"[CAPTURE] person detected -> {filename}") request.save("main", filename) last_capture_time = now request.release() time.sleep(0.05) except KeyboardInterrupt: print("\nStopping capture...") finally: picam2.stop()
①モデルの圧縮・量子化
ModelCompressionToolkit(MCT)を使い、モデルを圧縮します。
-
MCTについて
Keras (≒ Tensorflow) / PyTorchのモデル、キャリブレーションデータセット(後述)などを与えて量子化を行います
READMEにおいて、MCTは複数の量子化の方法をとることができると記載されています。
Target Platform Capabilitiesをimx500用に設定したうえで(デフォルトがimx500にセットされているようです)、
model_compression_toolkit.ptq. keras_post_training_quantization()
model_compression_toolkit.gptq. keras_gradient_post_training_quantization()
model_compression_toolkit.qat.keras_quantization_aware_training_init_experimental()ptqで精度が低下する場合に、gptqを使うといいよ、という感じのようです
引数を正しく設定すればおそらくどの場合でも動作すると思います。だいたいの引数が共通しています(記載の通り処理負荷と複雑性がトレードオフになります)kerasという名前は今回はじめて知ったのですが、小規模で扱いやすいtensorflowというイメージで捉えてます
Pytorch系のモデルを使う場合は、mctのAPI Docsにあるpytorch_系のメソッドを使用してください。
-
量子化を行うプログラムです。(quantize.py)⓪で用意した画像のフォルダを渡します
""" YOLO26n → MCT PTQ 量子化スクリプト (IMX500 向け) ------------------------------------------------- 【アーキテクチャ上の問題と解決策】 YOLO の _predict_once() は動的ループ + save インデックスを持ち、 torch.fx (MCT が内部で使用) でそのままトレースできない。 for m in self.model: ← Proxy のイテレーション → エラー x = y[m.f] ... 解決策: YOLO のレイヤー接続グラフをモデルロード時に読み取り、 exec() を使って完全にアンロールされた静的 forward を生成する。 生成例: def forward(self, x): _y0 = self._layers[0](x) _y1 = self._layers[1](_y0) _y2 = self._layers[2](_y1) # save _y4 = self._layers[4]([_y0, _y2]) # multi-input ... return _y_last torch.fx はループのない静的コードをトレースできる。 出力: quantized_yolo26n.onnx (fake-quant ONNX → imxconv-pt の入力) 使い方: python quantizepy \ --weights yolo26n.pt \ --images /path/to/calib_images \ --output quantized_yolo26n.onnx \ [--imgsz 640] [--batch 1] [--n_iter 10] """ import argparse import os import pathlib import textwrap import cv2 import numpy as np import torch import torch.nn as nn # ============================================================ # 1. 引数パース # ============================================================ def parse_args(): p = argparse.ArgumentParser() p.add_argument("--weights", default="yolo26s.pt") p.add_argument("--images", required=True, help="キャリブレーション画像フォルダ") p.add_argument("--output", default="quantized_yolo26n.onnx") p.add_argument("--imgsz", type=int, default=640) p.add_argument("--batch", type=int, default=1, help="キャリブ時バッチサイズ (≥4 推奨)") p.add_argument("--n_iter", type=int, default=10, help="イテレーション数 (合計 = batch × n_iter)") p.add_argument("--debug_forward", action="store_true", help="生成した forward コードを表示する") return p.parse_args() # ============================================================ # 2b. torch.fx トレース不可なサブモジュールのモンキーパッチ # ============================================================ def patch_ultralytics_for_fx(model: nn.Module) -> None: """ ultralytics のブロック内にある torch.fx 非対応パターンをパッチする。 問題パターン1 (C2f など): list(tensor.chunk(2, 1)) → Proxy に list() を呼ぶとイテレーション失敗 → 修正: chunk()[0], chunk()[1] の明示インデックスに置換 問題パターン2 (YOLO26 Detect ヘッド): _get_decode_boxes() 内の if self.dynamic or self.shape != shape: → shape の比較が Proxy を bool 評価しようとして失敗 → 修正: デコード処理をスキップし、生の conv 出力だけを返す (IMX500 はデコード前の raw feature map を受け取る) """ import inspect import types # ========================================================= # パッチ1: chunk + list パターン (C2f 系ブロック) # ========================================================= def _try_import(module_path, class_name): try: import importlib mod = importlib.import_module(module_path) return getattr(mod, class_name, None) except ImportError: return None C2f = _try_import("ultralytics.nn.modules.block", "C2f") if C2f: def _c2f_forward(self, x): ab = self.cv1(x).chunk(2, 1) # Proxy のまま保持 y = [ab[0], ab[1]] # getitem でアクセス → OK y.extend(m(y[-1]) for m in self.m) return self.cv2(torch.cat(y, 1)) for m in model.modules(): if isinstance(m, C2f): m.forward = types.MethodType(_c2f_forward, m) # 汎用スキャン: 同じパターンを持つ他のブロック for name, sub in model.named_modules(): src_lines = "" try: src_lines = inspect.getsource(type(sub).forward) except (TypeError, OSError): pass if "list(self.cv1(x).chunk(2, 1))" in src_lines: def _generic_c2f_forward(self, x): ab = self.cv1(x).chunk(2, 1) y = [ab[0], ab[1]] y.extend(m(y[-1]) for m in self.m) return self.cv2(torch.cat(y, 1)) sub.forward = types.MethodType(_generic_c2f_forward, sub) # ========================================================= # パッチ2: Detect ヘッド → raw conv 出力のみ返す # ========================================================= # YOLO26 の Detect ヘッドは end2end / one2one デュアルヘッド構造を持ち、 # _get_decode_boxes() 内で Proxy を bool 評価しようとして失敗する。 # IMX500 の量子化に必要なのは conv 後の生テンソルのみであり、 # ボックスデコード・NMS は imxconv-pt 側が処理するため不要。 # # 対応クラス: # Detect, Detect26, v10Detect, WorldDetect, OBB, OBB26, # Segment, Segment26, Pose, Pose26 … # 共通構造: cv2 (box branch) + cv3 (cls branch) を nl スケール分持つ def _make_raw_detect_forward(head): """ ヘッドの構造を調べ、適切な raw forward を返す。 通常の Detect 系: cv2[i](x[i]) ++ cv3[i](x[i]) → 各スケールを concat して返す YOLO26 の end2end Detect (one2one ヘッドあり): cv2[i] / cv3[i] : one2many ブランチ cv2_one2one[i] / cv3_one2one[i] : one2one ブランチ → IMX500 向けは one2one ヘッドの出力を返す (end2end=True 時) """ has_one2one = (hasattr(head, 'cv2_one2one') and hasattr(head, 'cv3_one2one')) end2end = getattr(head, 'end2end', False) if has_one2one and end2end: # YOLO26 end2end: one2one branch のみ使用 def _forward_raw(self, x): result = [] for i in range(self.nl): result.append(torch.cat( (self.cv2_one2one[i](x[i]), self.cv3_one2one[i](x[i])), 1)) return tuple(result) head_mode = "YOLO26 end2end (one2one branch)" elif has_one2one: # one2one あり end2end なし: one2many を使用 def _forward_raw(self, x): result = [] for i in range(self.nl): result.append(torch.cat( (self.cv2[i](x[i]), self.cv3[i](x[i])), 1)) return tuple(result) head_mode = "YOLO26 (one2many branch)" else: # 通常の Detect / YOLOv8 系 def _forward_raw(self, x): result = [] for i in range(self.nl): result.append(torch.cat( (self.cv2[i](x[i]), self.cv3[i](x[i])), 1)) return tuple(result) head_mode = "standard Detect" return _forward_raw, head_mode # Detect 系のクラス名一覧 (isinstance チェック用) _DETECT_CLASS_NAMES = { "Detect", "Detect26", "v10Detect", "WorldDetect", "OBB", "OBB26", "Segment", "Segment26", "Pose", "Pose26", } for name, sub in model.named_modules(): cls_name = type(sub).__name__ if cls_name in _DETECT_CLASS_NAMES or ( hasattr(sub, 'cv2') and hasattr(sub, 'cv3') and hasattr(sub, 'nl') ): if not hasattr(sub, 'cv2') or not hasattr(sub, 'cv3'): continue raw_fwd, head_mode = _make_raw_detect_forward(sub) sub.forward = types.MethodType(raw_fwd, sub) print(f" Detect ヘッドパッチ: {name} ({cls_name}) → {head_mode}") print(" サブモジュールパッチ完了") # ============================================================ # 2. torch.fx トレース可能な静的ラッパーの生成 # ============================================================ def build_traceable_wrapper(detection_model: nn.Module, debug: bool = False) -> nn.Module: """ YOLO の DetectionModel から torch.fx トレース可能な 静的ラッパーモジュールを生成して返す。 アルゴリズム: 1. detection_model.model (レイヤーリスト) を走査 2. 各レイヤーの .f (入力元インデックス) を読み取る 3. exec() でアンロールされた forward を生成 4. TraceableYOLO に各レイヤーを ModuleList として登録 """ layers = list(detection_model.model) save_set = set(detection_model.save) # スキップ接続で参照されるインデックス # ------ forward コードの生成 ------ lines = ["def forward(self, x):"] var_map: dict[int, str] = {} # layer_index -> 変数名 for i, m in enumerate(layers): f = m.f # 入力元: -1 | int | list[int] var_out = f"_y{i}" # 入力を決定 # YOLO の f=-1 は「直前レイヤーの出力」を意味する (元の入力 x ではない) def resolve(j, _i=i): if j == -1: return "x" if _i == 0 else var_map[_i - 1] return var_map[j] if isinstance(f, int): inp_expr = resolve(f) else: inp_expr = "[" + ", ".join(resolve(j) for j in f) + "]" lines.append(f" {var_out} = self._layers[{i}]({inp_expr})") var_map[i] = var_out # 最後のレイヤーの出力を返す last_var = var_map[len(layers) - 1] lines.append(f" return {last_var}") forward_code = "\n".join(lines) if debug: print("\n=== 生成された静的 forward ===") print(forward_code) print("=" * 40) # ------ ラッパークラスを構築 ------ class TraceableYOLO(nn.Module): def __init__(self, layer_list): super().__init__() self._layers = nn.ModuleList(layer_list) # exec で生成した forward をクラスにバインド namespace: dict = {} exec(compile(forward_code, "<yolo_static_forward>", "exec"), namespace) TraceableYOLO.forward = namespace["forward"] wrapper = TraceableYOLO(layers) wrapper.eval() return wrapper # ============================================================ # 3. キャリブレーション用 representative_data_gen # ============================================================ SUPPORTED_EXTS = {".jpg", ".jpeg", ".png", ".bmp", ".webp", ".tiff"} def make_representative_dataset(images_dir: str, imgsz: int, batch_size: int, n_iter: int): image_paths = sorted([ str(p) for p in pathlib.Path(images_dir).rglob("*") if p.suffix.lower() in SUPPORTED_EXTS ]) if not image_paths: raise FileNotFoundError( f"'{images_dir}' に対応画像が見つかりません" ) total_needed = batch_size * n_iter if len(image_paths) < total_needed: reps = (total_needed // len(image_paths)) + 1 image_paths = (image_paths * reps)[:total_needed] else: image_paths = image_paths[:total_needed] def preprocess(path: str) -> np.ndarray: img = cv2.imread(path) if img is None: raise IOError(f"読み込み失敗: {path}") img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) h, w = img.shape[:2] scale = imgsz / max(h, w) nh, nw = int(h * scale), int(w * scale) img = cv2.resize(img, (nw, nh), interpolation=cv2.INTER_LINEAR) canvas = np.full((imgsz, imgsz, 3), 114, dtype=np.uint8) ph = (imgsz - nh) // 2 pw = (imgsz - nw) // 2 canvas[ph:ph+nh, pw:pw+nw] = img canvas = canvas.astype(np.float32) / 255.0 return np.transpose(canvas, (2, 0, 1)) # CHW def representative_dataset_gen(): for i in range(n_iter): batch = [preprocess(image_paths[i * batch_size + j]) for j in range(batch_size)] yield [torch.from_numpy(np.stack(batch, axis=0))] # [B,C,H,W] return representative_dataset_gen # ============================================================ # 4. MCT PTQ # ============================================================ def run_mct_ptq(model: nn.Module, representative_dataset_gen, imgsz: int): import model_compression_toolkit as mct tpc = mct.get_target_platform_capabilities( tpc_version="1.0", device_type="imx500" ) core_config = mct.core.CoreConfig( quantization_config=mct.core.QuantizationConfig( shift_negative_activation_correction=True, ) ) print("=== MCT PTQ 開始 ===") quantized_model, quantization_info = \ mct.ptq.pytorch_post_training_quantization( in_module=model, representative_data_gen=representative_dataset_gen, target_platform_capabilities=tpc, core_config=core_config, ) print("=== MCT PTQ 完了 ===") return quantized_model, quantization_info # ============================================================ # 5. ONNX エクスポート (fake-quant → imxconv-pt 入力形式) # ============================================================ def export_onnx(quantized_model: nn.Module, representative_dataset_gen, output_path: str): import model_compression_toolkit as mct print(f"=== ONNX エクスポート → {output_path} ===") mct.exporter.pytorch_export_model( model=quantized_model, save_model_path=output_path, repr_dataset=representative_dataset_gen, ) size_mb = os.path.getsize(output_path) / 1024 / 1024 print(f" 完了: {size_mb:.1f} MB") # ============================================================ # 6. メイン # ============================================================ def main(): args = parse_args() # ---- モデルロード ---- print(f"[1/4] モデルをロード中: {args.weights}") from ultralytics import YOLO yolo = YOLO(args.weights) det_model = yolo.model det_model.eval() # ---- サブモジュールパッチ ---- print("[2/4] torch.fx トレース可能な静的ラッパーを生成中...") print(" サブモジュールのモンキーパッチを適用中...") patch_ultralytics_for_fx(det_model) # ---- 静的ラッパーへ変換 ---- traceable = build_traceable_wrapper(det_model, debug=args.debug_forward) # 動作確認 dummy = torch.zeros(1, 3, args.imgsz, args.imgsz) with torch.no_grad(): out = traceable(dummy) print(f" 動作確認 OK: 出力型={type(out).__name__}") # ---- representative_data_gen ---- print(f"[3/4] キャリブレーション設定") print(f" 画像フォルダ : {args.images}") print(f" 合計サンプル : {args.batch} × {args.n_iter} = " f"{args.batch * args.n_iter}") rep_gen = make_representative_dataset( images_dir=args.images, imgsz=args.imgsz, batch_size=args.batch, n_iter=args.n_iter, ) # ---- MCT PTQ ---- print("[4/4] MCT PTQ 実行中 (IMX500 TPC v1.0)...") q_model, _ = run_mct_ptq(traceable, rep_gen, args.imgsz) # ---- ONNX エクスポート ---- export_onnx(q_model, rep_gen, args.output) print("\n完了!") print(f" 出力: {args.output}") print(" 次: bash imxconv-pt -i quantized_yolo26n.onnx -o PackerOut/") if __name__ == "__main__": main()
dockerコンテナ内で;
python quantize.py \
--weights yolo26n.pt \
--images calibration_images_front \
--output quantized_yolo26n.onnx \
--imgsz 480
圧縮されたONNXファイルが出力されます。
(精度比較)
AITRIOSデプロイガイドに量子化前後の制度比較を行なうサンプルコードが貼ってあります。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
import onnx
import onnxruntime as ort
import numpy as np
import argparse
import mct_quantizers as mctq
def loss_accuracy(correct, total, loss, elements):
accuracy = correct / total
loss = loss / elements
return loss, accuracy
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--float_model_path', type=str, default='./weight.pth', help='The path to the float PyTorch model')
parser.add_argument('--quantized_model_path', type=str, default='./quantized.onnx', help='The path to the quantized ONNX model')
parser.add_argument('--dataset_path', type=str, default='./dataset/val', help='The path to the dataset')
parser.add_argument('--input_tensor_size', type=int, default=224, help='Input tensor size')
args = parser.parse_args()
# Load dataset
transform = transforms.Compose([
transforms.Resize((args.input_tensor_size, args.input_tensor_size)),
transforms.ToTensor(),
])
dataset = datasets.ImageFolder(args.dataset_path, transform=transform)
data_loader = torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False)
# Load and evaluate the float model
float_model = models.mobilenet_v2()
num_ftrs = float_model.classifier[1].in_features
float_model.classifier[1] = nn.Linear(num_ftrs, 2)
float_model.load_state_dict(torch.load(args.float_model_path, map_location='cuda' if torch.cuda.is_available() else 'cpu', weights_only=True))
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
correct_float = 0
total_float = 0
loss_float = 0.0
# Load and evaluate the quantized ONNX model
ort_session = ort.InferenceSession(args.quantized_model_path, mctq.get_ort_session_options(), providers=['CUDAExecutionProvider' if torch.cuda.is_available() else 'CPUExecutionProvider'])
correct_quantized = 0
total_quantized = 0
loss_quantized = 0.0
criterion = nn.CrossEntropyLoss()
float_model.to(device)
float_model.eval()
num = 1
# Check each prediction
for data in data_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
# Float model prediction
outputs_float = float_model(images)
loss_float += criterion(outputs_float, labels).item()
_, predicted_float = torch.max(outputs_float.data, 1)
total_float += labels.size(0)
correct_float += (predicted_float == labels).sum().item()
# Quantized model prediction
images_np = images.cpu().numpy() # Move to CPU for ONNX
ort_inputs = {ort_session.get_inputs()[0].name: images_np}
ort_outs = ort_session.run(None, ort_inputs)
outputs_quantized = torch.tensor(ort_outs[0]).to(device)
loss_quantized += criterion(outputs_quantized, labels).item()
_, predicted_quantized = torch.max(outputs_quantized.data, 1)
total_quantized += labels.size(0)
correct_quantized += (predicted_quantized == labels).sum().item()
print("\r",num,end="")
if predicted_quantized != predicted_float:
print("\n==========")
print("correct_label : ", labels.cpu().numpy(), "\n")
print("float_model_result\nprediction : ", predicted_float.cpu().numpy(), "\nscore : ", str(outputs_float.cpu().detach().numpy()), "\n")
print("quantized_model_result\nprediction : ", predicted_quantized.cpu().numpy(), "\nscore : ", str(ort_outs[0]))
num += 1
print("\n==========")
float_model_loss, float_model_acc = loss_accuracy(correct_float, total_float, loss_float, len(data_loader))
quantized_model_loss, quantized_model_acc = loss_accuracy(correct_quantized, total_quantized, loss_quantized, len(data_loader))
print("float_model_result:", float_model_loss, float_model_acc)
print("quantized_model_result:", quantized_model_loss, quantized_model_acc)
if __name__ == "__main__":
main()
②PackerOut.zipの作成
IMX500 Converterを用いて、モデルをバイナリ化します。(この中でどのような処理が行われているかは、そこまで考えなくてもよいと思います)
Ubuntu または Raspberry Piで実行します。今回はそのままWSL-Docker上で続けています
Dockerコンテナに入り、実行前にpip install imx500-converter[pt] を行います。
imxconv-pt -i quantized_yolo26n.onnx -o PackerOut_n/ --overwrite-output
PackerOut.zipが生成されます。
SRAMメモリのサイズ
大きなモデルを変換しようとすると、オンチップSRAMのサイズ制限(8MB)によってエラーになる可能性があります。
ConvFe error (ISM): Not enough memory, available: 8.00MB, required: 17.25MB
このエラーが出てきたときは、テンソルサイズを下げる(--imgszオプションの値で設定できます)か、モデルを変更して①からやり直します。26nでも640x640では収まりきらず、今回480x480で変換しました。
③network.rpkの作成
IMX500 Packagerを用いて、実際に使用するnetwork.rpkを作成します。
PackagerはRaspberry Pi上でしか実行することができません。PackerOut.zipをRaspberry Piにコピーしておきます
sudo apt-get install jq=1.6-2.1 libarchive-dev=3.4.3-2+deb11u1
sudo apt install imx500-tools
imx500-package -i ./PackerOut.zip -o ./
モデルを利用するコード | 混雑測定
ここからが本題のはずなのですが、変換の工程を完成させるのに2ヶ月を要することになりました。
コンセプト
カメラは1秒ごとに、[今画角内にいる人数]と[この1秒のあいだに画角から消えた(通過した)人数]を記録し、csvファイルに出力します。
通過については前のフレームと比較することで各人のトラッキングを行い、一定フレーム検出されなくなったとき、最後に検出した位置が画面端であれば通過したと判定するという仕組みになっています。
コード
今回のメインコードです。Claude作成です
```jsx
#!/usr/bin/env python3
"""
people_flow.py ─ Raspberry Pi AI Camera 人流計測プログラム
IMX500 + YOLO26n RPK を使用して、レーンを通過する人数を計測します。
使い方:
本番実行: python3 people_flow.py
デバッグ: python3 people_flow.py --preview
ROI確認: python3 people_flow.py --calibrate
設定指定: python3 people_flow.py --config /path/to/config.json
"""
from __future__ import annotations
import argparse
import csv
import json
import logging
import signal
import sys
import threading
import time
from datetime import datetime
from pathlib import Path
from typing import Dict, List, Optional
import numpy as np
from picamera2 import MappedArray, Picamera2, Preview
from picamera2.devices import IMX500
from picamera2.devices.imx500 import NetworkIntrinsics
try:
import cv2
_HAS_CV2 = True
except ImportError:
_HAS_CV2 = False
# ─────────────────────────────────────────────────────────────────────────────
# 定数
# ─────────────────────────────────────────────────────────────────────────────
PERSON_CLASS = 0 # COCO class id for "person"
MODEL_SIDE = 480 # IMX500 へ渡す入力サイズ (正方形)
DEFAULT_CONFIG = Path("/home/pi/camera/config.json")
LOG_FILE = Path("/home/pi/camera/people_flow.log")
# デフォルト設定値(config.json で上書き可)
_DEFAULTS: dict = {
"rpk_path": "/home/pi/camera/network.rpk",
"output_dir": "/home/pi/camera/consequence",
# 通過方向: "left_to_right" または "right_to_left"
"direction": "left_to_right",
# 検出閾値
"confidence_threshold": 0.35,
"nms_iou_threshold": 0.45,
# ROI フィルタ
# bbox 重心 Y がこの比率未満 (= 画面上部) なら遠方レーンとみなし除外
"roi_y_min_ratio": 0.40,
# bbox 高さがこの比率未満なら除外(小さすぎる人物)
"min_bbox_height_ratio": 0.18,
# トラッカー
"min_track_iou": 0.25,
"max_lost_frames": 8,
# 画面端からこの比率以内に達したトラックを「通過」と判定
"exit_zone_ratio": 0.10,
# CSV 記録間隔 [秒]
"tick_interval_seconds": 1.0,
# 自動終了 [分](systemd timer のバックアップ)
"run_duration_minutes": 40,
}
# ─────────────────────────────────────────────────────────────────────────────
# ロギング
# ─────────────────────────────────────────────────────────────────────────────
LOG_FILE.parent.mkdir(parents=True, exist_ok=True)
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s [%(levelname)s] %(message)s",
handlers=[
logging.StreamHandler(sys.stdout),
logging.FileHandler(LOG_FILE, encoding="utf-8"),
],
)
log = logging.getLogger(__name__)
# ─────────────────────────────────────────────────────────────────────────────
# 設定読み込み
# ─────────────────────────────────────────────────────────────────────────────
def load_config(path: Path) -> dict:
cfg: dict = {}
if path.exists():
with open(path, encoding="utf-8") as f:
cfg = json.load(f)
else:
log.warning(f"設定ファイルが見つかりません ({path})。デフォルト値を使用します。")
merged = {**_DEFAULTS, **cfg}
return merged
# ─────────────────────────────────────────────────────────────────────────────
# 検出解析ユーティリティ
# ─────────────────────────────────────────────────────────────────────────────
def _iou(a: np.ndarray, b: np.ndarray) -> float:
"""2 ボックス間の IoU を計算 (x1, y1, x2, y2 形式)。"""
ix1 = max(a[0], b[0]); iy1 = max(a[1], b[1])
ix2 = min(a[2], b[2]); iy2 = min(a[3], b[3])
inter = max(0.0, ix2 - ix1) * max(0.0, iy2 - iy1)
union = (a[2]-a[0])*(a[3]-a[1]) + (b[2]-b[0])*(b[3]-b[1]) - inter
return float(inter / union) if union > 0 else 0.0
def _nms(boxes: np.ndarray, scores: np.ndarray, thresh: float) -> List[int]:
"""Greedy NMS。スコア降順に処理し、重複 (IoU>=thresh) を除去。"""
if len(boxes) == 0:
return []
order = np.argsort(scores)[::-1]
keep: List[int] = []
while len(order):
i = int(order[0])
keep.append(i)
if len(order) == 1:
break
ious = np.array([_iou(boxes[i], boxes[j]) for j in order[1:]])
order = order[1:][ious < thresh]
return keep
def _sigmoid(x: np.ndarray) -> np.ndarray:
return 1.0 / (1.0 + np.exp(-np.clip(x, -88, 88)))
def _decode_head(
pred4d: np.ndarray,
side: int,
debug: bool = False,
head_idx: int = 0,
) -> tuple:
"""
1 つの特徴マップヘッドをデコードする。
入力 : (C, H, W) C = 4 + num_cls
出力 : boxes (N,4) 正規化座標 [0,1], scores (N,) person スコア
MCT / ultralytics YOLO 量子化後の出力フォーマット:
ch 0-3 = LTRB (Left/Top/Right/Bottom) stride 単位
l = グリッドセンターから左端までの距離 [stride 単位]
t = グリッドセンターから上端までの距離 [stride 単位]
r = グリッドセンターから右端までの距離 [stride 単位]
b = グリッドセンターから下端までの距離 [stride 単位]
ch 4-83 = クラスロジット (sigmoid 未適用)
変換式:
x1_px = grid_cx_px - l * stride
y1_px = grid_cy_px - t * stride
x2_px = grid_cx_px + r * stride
y2_px = grid_cy_px + b * stride
"""
C, H, W = pred4d.shape
n_cls = C - 4
stride = float(side) / W
if PERSON_CLASS >= n_cls:
return np.empty((0, 4)), np.empty((0,))
# (C, H, W) -> (H*W, C)
pred = pred4d.reshape(C, H * W).T # (H*W, C)
# グリッドセンター座標 [ピクセル]
xs = (np.arange(W) + 0.5) * stride
ys = (np.arange(H) + 0.5) * stride
grid_x, grid_y = np.meshgrid(xs, ys)
grid_cx = grid_x.reshape(-1) # (H*W,)
grid_cy = grid_y.reshape(-1)
# LTRB [stride 単位]
l = pred[:, 0]
t = pred[:, 1]
r = pred[:, 2]
b = pred[:, 3]
# ピクセル座標へ変換し正規化
x1_px = grid_cx - l * stride
y1_px = grid_cy - t * stride
x2_px = grid_cx + r * stride
y2_px = grid_cy + b * stride
boxes = np.clip(
np.stack([x1_px, y1_px, x2_px, y2_px], axis=1) / side,
0.0, 1.0,
)
# クラスロジット -> sigmoid -> person スコア
scores = _sigmoid(pred[:, 4 + PERSON_CLASS])
# ── デバッグ出力 ──────────────────────────────────────────────────────
if debug:
top_mask = scores >= 0.5
n_top = int(np.sum(top_mask))
bbox_abs_max = float(np.abs(pred[:, :4]).max())
log.info(
f" HEAD[{head_idx}] stride={stride:.0f} fmt=LTRB"
f" bbox_abs_max={bbox_abs_max:.3f} n_person>=0.5: {n_top}"
)
if n_top > 0:
idxs = np.where(top_mask)[0]
for ii in idxs[:5]:
gi = int(ii % W)
gj = int(ii // W)
bx = boxes[ii]
log.info(
f" anchor(row={gj},col={gi})"
f" l={l[ii]:.2f} t={t[ii]:.2f} r={r[ii]:.2f} b={b[ii]:.2f}"
f" -> x1={bx[0]:.3f} y1={bx[1]:.3f}"
f" x2={bx[2]:.3f} y2={bx[3]:.3f}"
f" score={scores[ii]:.3f}"
)
return boxes, scores
def parse_yolo(
np_outputs,
conf: float,
nms_thr: float,
side: int = MODEL_SIDE,
log_first: bool = False,
debug_bbox: bool = False,
) -> List[np.ndarray]:
"""
YOLO26n (ultralytics 形式) の IMX500 出力テンソルを解析する。
IMX500 は stride ごとに複数のテンソルを返す。
stride 8 -> (1, 84, 60, 60)
stride 16 -> (1, 84, 30, 30)
stride 32 -> (1, 84, 15, 15)
もしくは単一テンソルで (1, 84, 4725) のようにアンカーを結合して返す場合もある。
どちらも自動判定して対応する。
Returns
-------
list of np.ndarray, shape (4,)
(x1, y1, x2, y2) の正規化座標 [0, 1] のリスト。
"""
if np_outputs is None or len(np_outputs) == 0:
return []
# ── デバッグログ(初回のみ)──────────────────────────────────────────────
if log_first:
log.info(f"[出力テンソル数] {len(np_outputs)}")
for i, t in enumerate(np_outputs):
# チャンネルごとの bbox 生値を確認
t_tmp = t[0] if t.ndim == 4 else t
log.info(
f" [{i}] shape={t.shape} dtype={t.dtype} "
f"min={float(t.min()):.3f} max={float(t.max()):.3f}"
)
if t_tmp.ndim == 3:
for ch, name in enumerate(["ch0(cx)", "ch1(cy)", "ch2(w)", "ch3(h)"]):
ch_vals = t_tmp[ch]
log.info(
f" {name}: min={float(ch_vals.min()):.3f}"
f" max={float(ch_vals.max()):.3f}"
f" mean={float(ch_vals.mean()):.3f}"
f" |>1|:{int(np.sum(np.abs(ch_vals) > 1))}"
f" |>side/2|:{int(np.sum(np.abs(ch_vals) > side/2))}"
)
all_boxes: List[np.ndarray] = []
all_scores: List[np.ndarray] = []
for head_idx, raw in enumerate(np_outputs):
# バッチ次元を除去 -> (C, ...) にする
t = raw
if t.ndim == 4 and t.shape[0] == 1:
t = t[0] # (C, H, W)
elif t.ndim == 3 and t.shape[0] == 1:
t = t[0] # (C, N) ← アンカー結合形式
if t.ndim == 3:
# (C, H, W) 形式 ─ ヘッドごとに分割デコード
C, H, W = t.shape
if C < 5:
# チャンネル軸が小さい -> (H, W, C) かもしれない
t = t.transpose(2, 0, 1)
C, H, W = t.shape
boxes, scores = _decode_head(
t, side,
debug=(log_first or debug_bbox),
head_idx=head_idx,
)
elif t.ndim == 2:
# (C, N) または (N, C) ─ アンカー結合形式
if t.shape[0] < t.shape[1]:
t = t.T # -> (N, C)
C = t.shape[1]
n_cls = C - 4
if PERSON_CLASS >= n_cls:
continue
raw_cx = t[:, 0]; raw_cy = t[:, 1]
raw_w = t[:, 2]; raw_h = t[:, 3]
cx, cy, w, h = raw_cx, raw_cy, raw_w, raw_h
x1 = np.clip((cx - w / 2) / side, 0, 1)
y1 = np.clip((cy - h / 2) / side, 0, 1)
x2 = np.clip((cx + w / 2) / side, 0, 1)
y2 = np.clip((cy + h / 2) / side, 0, 1)
boxes = np.stack([x1, y1, x2, y2], axis=1)
scores = _sigmoid(t[:, 4 + PERSON_CLASS])
else:
log.warning(f"想定外のテンソル次元数: {t.shape}")
continue
if len(scores) == 0:
continue
all_boxes.append(boxes)
all_scores.append(scores)
if not all_boxes:
return []
boxes = np.concatenate(all_boxes, axis=0)
scores = np.concatenate(all_scores, axis=0)
# 信頼度フィルタ
mask = scores >= conf
if not np.any(mask):
return []
boxes = boxes[mask]
scores = scores[mask]
# NMS
keep = _nms(boxes, scores, nms_thr)
return [boxes[i] for i in range(len(boxes)) if i in set(keep)]
def roi_filter(
dets: List[np.ndarray],
y_min: float,
min_h: float,
) -> List[np.ndarray]:
"""
y_min : bbox 重心 Y がこの値未満なら除外(上部 = 奥のレーン)
min_h : bbox 高さがこの値未満なら除外(小さい検出)
値はいずれも正規化 [0, 1] ベース。
"""
return [
b for b in dets
if (b[1] + b[3]) / 2 >= y_min and (b[3] - b[1]) >= min_h
]
# ─────────────────────────────────────────────────────────────────────────────
# トラッカー
# ─────────────────────────────────────────────────────────────────────────────
class _Track:
"""1 人の追跡単位。"""
_nxt_id = 1
def __init__(self, bbox: np.ndarray) -> None:
self.id: int = _Track._nxt_id
_Track._nxt_id += 1
self.bbox = bbox.copy()
self.cx: float = float((bbox[0] + bbox[2]) / 2)
self.lost: int = 0
self.counted: bool = False # 通過カウント済みか
def update(self, bbox: np.ndarray) -> None:
self.bbox = bbox.copy()
self.cx = float((bbox[0] + bbox[2]) / 2)
self.lost = 0
class PeopleTracker:
"""
IoU ベースの Greedy マッチングで人物を追跡し、
画面端から退出した人数を通過カウントとして返す。
スレッド安全性: このクラスは pre_callback スレッドからのみ使用する。
"""
def __init__(self, cfg: dict) -> None:
self._dir = cfg["direction"]
self._exit_r = cfg["exit_zone_ratio"]
self._max_lost = cfg["max_lost_frames"]
self._min_iou = cfg["min_track_iou"]
self._trks: Dict[int, _Track] = {}
# -------------------------------------------------------------------------
def update(self, dets: List[np.ndarray]) -> int:
"""
dets: 今フレームの person bbox (x1,y1,x2,y2) normalized のリスト
Returns: このフレームで退場(通過)した人数
"""
passed = 0
if not dets:
return self._age_all()
det_arr = np.array(dets) # (N, 4)
tids = list(self._trks.keys())
# 既存トラックなし -> 全て新規
if not tids:
for b in det_arr:
t = _Track(b)
self._trks[t.id] = t
return 0
# IoU 行列
tb = np.array([self._trks[tid].bbox for tid in tids])
iou = np.zeros((len(tids), len(det_arr)))
for i, bt in enumerate(tb):
for j, bd in enumerate(det_arr):
iou[i, j] = _iou(bt, bd)
# Greedy マッチング(スコア降順)
matched_t: set = set()
matched_d: set = set()
tmp = iou.copy()
while tmp.max() >= self._min_iou:
r, c = map(int, np.unravel_index(tmp.argmax(), tmp.shape))
self._trks[tids[r]].update(det_arr[c])
matched_t.add(tids[r])
matched_d.add(c)
tmp[r, :] = -1.0
tmp[:, c] = -1.0
# マッチされなかったトラック -> lost カウントアップ
to_del: List[int] = []
for tid in tids:
if tid not in matched_t:
tr = self._trks[tid]
tr.lost += 1
if tr.lost >= self._max_lost:
if self._in_exit(tr.cx) and not tr.counted:
passed += 1
tr.counted = True
to_del.append(tid)
for tid in to_del:
del self._trks[tid]
# マッチされなかった検出 -> 新規トラック
for j, b in enumerate(det_arr):
if j not in matched_d:
t = _Track(b)
self._trks[t.id] = t
return passed
# -------------------------------------------------------------------------
def _age_all(self) -> int:
"""検出なしフレーム: 全トラックの lost をインクリメント。"""
passed = 0
to_del = []
for tid, tr in self._trks.items():
tr.lost += 1
if tr.lost >= self._max_lost:
if self._in_exit(tr.cx) and not tr.counted:
passed += 1
tr.counted = True
to_del.append(tid)
for tid in to_del:
del self._trks[tid]
return passed
# -------------------------------------------------------------------------
def _in_exit(self, cx: float) -> bool:
"""cx が退場ゾーン内かどうか。"""
if self._dir == "left_to_right":
return cx > (1.0 - self._exit_r)
return cx < self._exit_r
def count(self) -> int:
return len(self._trks)
# ─────────────────────────────────────────────────────────────────────────────
# CSV 出力
# ─────────────────────────────────────────────────────────────────────────────
def write_csv(out_dir: str, ts: str, in_frame: int, passed: int) -> None:
"""
日付ファイル名の CSV に 1 行追記。ファイルが存在しない場合はヘッダを書く。
既存ファイルがある場合は追記(日付をまたぐことはないが再起動に対応)。
"""
path = Path(out_dir) / f"{datetime.now():%Y-%m-%d}.csv"
is_new = not path.exists()
with open(path, "a", newline="", encoding="utf-8") as f:
w = csv.writer(f)
if is_new:
w.writerow(["timestamp", "people_in_frame", "passed_count"])
w.writerow([ts, in_frame, passed])
# ─────────────────────────────────────────────────────────────────────────────
# プレビュー / キャリブレート描画
# ─────────────────────────────────────────────────────────────────────────────
def draw_overlay(
arr: np.ndarray,
dets: List[np.ndarray],
cfg: dict,
in_frame: int,
calibrate: bool,
) -> None:
"""
MappedArray の配列に OpenCV でアノテーションを描画する。
calibrate=True のとき、bbox ごとに cy・高さをラベル表示する。
"""
if not _HAS_CV2:
return
h, w = arr.shape[:2]
# ROI ライン(赤)─ この線より上の bbox は除外される
ry = int(cfg["roi_y_min_ratio"] * h)
cv2.line(arr, (0, ry), (w, ry), (0, 0, 200), 2)
cv2.putText(arr, f"ROI y>{cfg['roi_y_min_ratio']:.2f}",
(4, max(ry - 4, 12)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 200), 1)
# 退場ゾーンライン(青)
if cfg["direction"] == "left_to_right":
ex = int((1.0 - cfg["exit_zone_ratio"]) * w)
else:
ex = int(cfg["exit_zone_ratio"] * w)
cv2.line(arr, (ex, 0), (ex, h), (200, 60, 0), 2)
# 検出 bbox(緑)
for b in dets:
x1, y1 = int(b[0] * w), int(b[1] * h)
x2, y2 = int(b[2] * w), int(b[3] * h)
cv2.rectangle(arr, (x1, y1), (x2, y2), (0, 200, 0), 2)
if calibrate:
bh = b[3] - b[1]
cy = (b[1] + b[3]) / 2
cv2.putText(arr, f"cy={cy:.2f} h={bh:.2f}",
(x1 + 2, max(y1 - 4, 12)),
cv2.FONT_HERSHEY_SIMPLEX, 0.42, (0, 200, 0), 1)
# ステータステキスト
mode_label = "CALIBRATE" if calibrate else "LIVE"
cv2.putText(arr,
f"[{mode_label}] In:{in_frame} {datetime.now():%H:%M:%S}",
(8, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (255, 255, 255), 2)
# ─────────────────────────────────────────────────────────────────────────────
# メイン
# ─────────────────────────────────────────────────────────────────────────────
def main() -> None:
ap = argparse.ArgumentParser(description="人流計測 ─ IMX500 + YOLO26n")
ap.add_argument("--config", default=str(DEFAULT_CONFIG),
help="設定ファイルパス (default: %(default)s)")
ap.add_argument("--preview", action="store_true",
help="QTGL プレビュー表示(要ディスプレイ / X11 転送)")
ap.add_argument("--calibrate", action="store_true",
help="ROI 確認モード: CSV 書き込みなし・時間制限なし・bbox 詳細表示")
ap.add_argument("--debug-bbox", action="store_true",
help="毎フレーム bbox 生値をログ出力(デコード形式の調査用)")
args = ap.parse_args()
cfg = load_config(Path(args.config))
Path(cfg["output_dir"]).mkdir(parents=True, exist_ok=True)
log.info("=" * 60)
log.info("人流計測プログラム 起動")
log.info(f" RPK : {cfg['rpk_path']}")
log.info(f" 方向 : {cfg['direction']}")
log.info(f" ROI 上限 Y : {cfg['roi_y_min_ratio']}")
log.info(f" 最小 bbox 高 : {cfg['min_bbox_height_ratio']}")
log.info(f" 出力先 : {cfg['output_dir']}")
log.info(f" モード : {'CALIBRATE' if args.calibrate else 'LIVE'}")
log.info("=" * 60)
# ── 終了管理 ──────────────────────────────────────────────────────────────
if args.calibrate:
deadline = float("inf") # 時間制限なし
else:
deadline = time.time() + cfg["run_duration_minutes"] * 60
stop_event = threading.Event()
def _sig(sig, _):
log.info(f"シグナル {sig} を受信 -> 停止処理")
stop_event.set()
signal.signal(signal.SIGTERM, _sig)
signal.signal(signal.SIGINT, _sig)
# ── IMX500 / picamera2 初期化 ──────────────────────────────────────────────
imx500 = IMX500(cfg["rpk_path"])
intrinsics = imx500.network_intrinsics or NetworkIntrinsics()
fps = intrinsics.inference_rate or 10.0
picam2 = Picamera2(imx500.camera_num)
cam_cfg = picam2.create_preview_configuration(
controls={"FrameRate": fps},
buffer_count=12,
)
picam2.configure(cam_cfg)
# ── 共有状態(コールバックスレッド ↔ メインスレッド)─────────────────────
_lock = threading.Lock()
_in_frame = 0 # 現フレームの人数(コールバックが更新)
_tick_passed = 0 # 次ティックまでの通過累計(コールバックが加算、メインがリセット)
tracker = PeopleTracker(cfg) # コールバックスレッドからのみアクセス
_first_call = True # 初回フレームのデバッグログ用
want_overlay = (args.preview or args.calibrate) and _HAS_CV2
# ── カメラコールバック ─────────────────────────────────────────────────────
def _cb(request) -> None:
nonlocal _in_frame, _tick_passed, _first_call
meta = request.get_metadata()
np_out = imx500.get_outputs(meta, add_batch=True)
dets = parse_yolo(
np_out,
cfg["confidence_threshold"],
cfg["nms_iou_threshold"],
log_first=_first_call,
debug_bbox=args.debug_bbox,
)
dets = roi_filter(
dets,
cfg["roi_y_min_ratio"],
cfg["min_bbox_height_ratio"],
)
_first_call = False
passed = tracker.update(dets)
cnt = tracker.count()
with _lock:
_in_frame = cnt
_tick_passed += passed
# プレビュー / キャリブレート描画
if want_overlay:
try:
with MappedArray(request, "main") as m:
draw_overlay(m.array, dets, cfg, cnt, args.calibrate)
except Exception as exc:
log.debug(f"描画エラー: {exc}")
picam2.pre_callback = _cb
# ── カメラ起動 ─────────────────────────────────────────────────────────────
if want_overlay:
try:
picam2.start_preview(Preview.QTGL)
except Exception:
log.warning("QTGL プレビュー起動に失敗しました。オーバーレイなしで続行します。")
picam2.start()
imx500.set_auto_aspect_ratio()
log.info("カメラ起動完了。計測を開始します。")
if args.calibrate:
log.info("ROI 確認モード: CSV は書き込みません。Ctrl+C で終了してください。")
# ── メインループ ───────────────────────────────────────────────────────────
last_tick = time.time()
try:
while not stop_event.is_set() and time.time() < deadline:
time.sleep(0.05) # 50 ms ポーリング
now = time.time()
if now - last_tick >= cfg["tick_interval_seconds"]:
with _lock:
in_f = _in_frame
passed = _tick_passed
_tick_passed = 0
ts = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
log.info(
f"{ts} | in_frame={in_f:2d} | passed={passed:2d}"
+ (" [CALIBRATE]" if args.calibrate else "")
)
if not args.calibrate:
write_csv(cfg["output_dir"], ts, in_f, passed)
last_tick = now
except Exception as exc:
log.exception(f"メインループで例外が発生しました: {exc}")
finally:
log.info("終了処理中...")
picam2.stop()
if want_overlay:
try:
picam2.stop_preview()
except Exception:
pass
log.info("計測終了。")
if __name__ == "__main__":
main()
この測定コードを利用した分析研究については 実験報告書 をご覧ください。 もう少々お待ちください!
参考ページまとめ
rpkファイルを得るまでのこの手順それぞれについての説明どうしが、うまく関連付けられていないのが問題だと思いました。導線が明確になっていると、もっと理解しやすくなるように思います
MCTとは(PyTorch)(概説) 旧リンク(開けなくなっています)
model_compression_toolkit.ptq.pytorch_post_training_quantization()
exporter Module
IMX500 Converter
IMX500 Packager
AI Camera - Raspberry Pi Documentation
-
変換コードを作成するプロンプト
これまでの会話のコンテクストを無視してください。
Raspberry Pi AI Camera(https://www.raspberrypi.com/documentation/accessories/ai-camera.html#conversion)において、
YOLO26s(https://docs.ultralytics.com/ja/models/yolo26/)をimx500で使えるrpkファイルに変換します。
まずこれらの資料をよみ、流れを理解してください。- https://github.com/SonySemiconductorSolutions/mct-model-optimization
- https://sonysemiconductorsolutions.github.io/mct-model-optimization/api/api_docs/methods/pytorch_post_training_quantization.html#ug-pytorch-post-training-quantization
- https://sonysemiconductorsolutions.github.io/mct-model-optimization/api/api_docs/modules/exporter.html
- https://developer.aitrios.sony-semicon.com/en/docs/raspberry-pi-ai-camera/imx500-converter?version=3.17.3
- https://developer.aitrios.sony-semicon.com/en/docs/raspberry-pi-ai-camera/imx500-packager?version=2025-09-30&progLang=
- https://developer.aitrios.sony-semicon.com/edge-ai-sensing/documents/keras-model-deployment-guide?version=2025-12-15&progLang=#_quantization_of_the_model
- https://developer.aitrios.sony-semicon.com/edge-ai-sensing/documents/console-user-manual?version=2025-12-15&progLang=#_Quantization
- https://github.com/SonySemiconductorSolutions/mct-model-optimization 特に、./tutorials
①YOLOのPytorchファイルにMCTを使い圧縮・量子化
②imx500-converterでPackerOut.zipを作成(bash imxconv-pt)
③imx500-packagerでnetwork.rpkを作成(bash imx500-package)
というようになります。ここでは、①の手順のためのpythonスクリプトを出力してください。資料の内容について、特にこれらに注意してください:
- MCTやconverterのバージョンは若干不安定なところが残っており、Python 3.12系は避けたほうがよいと思われます。
ここでは、Ubuntu 22.04のdockerイメージからスクリプトを実行することを想定しています。その他のよりよい方法があれば提案してください
環境はWindows, WSL2 ディストリビューションUbuntu 24.04です
Dockerの実装が可能であれば、DockerFileを出力してください。 - YOLO26s.ptをMCTのPTQで量子化します。他の手段にすべき特別な必要性が見つからなければ、モデルのロードにはYOLO()を使用してください。( https://docs.ultralytics.com/ja/modes/export/#how-do-i-enable-int8-quantization-when-exporting-my-yolo26-model )
- 同様、他の手段にすべき特別な必要性が見つからなければ、TPCはimx500用を用いてください。
- model_compression_toolkit.ptq.pytorch_post_training_quantization()の引数representative_data_genにはcallableを渡す必要があります。
画像を保存したフォルダのパスを指定して、そのフォルダ内の画像を返していくようなgeneratorを定義します。定義の方法については https://colab.research.google.com/github/SonySemiconductorSolutions/mct-model-optimization/blob/main/tutorials/notebooks/mct_features_notebooks/pytorch/example_pytorch_post_training_quantization.ipynb が参考になると思いますが、画像を読み込む点は相違しているので注意してください - ②以降で使用しますから、 https://sonysemiconductorsolutions.github.io/mct-model-optimization/api/api_docs/modules/exporter.html https://developer.aitrios.sony-semicon.com/en/docs/raspberry-pi-ai-camera/imx500-converter?version=3.17.3 を参照し、imx500-converterが受け取れる形式でのエクスポートをおねがいします
- この次に変換したモデルを使用するシチュエーションと作成してほしいコードについて指示します。
-
メインコードを作成するプロンプト
calibraition_image画像の例を添付する
Raspberry Pi AI Camera(https://www.raspberrypi.com/documentation/accessories/ai-camera.html#conversion)において、
YOLO26n(https://docs.ultralytics.com/ja/models/yolo26/)を変換したrpkファイルを用いて、人流を測定するプログラムを作ります。これらの文献も参考にしてください。
-
https://developer.aitrios.sony-semicon.com/en/docs/raspberry-pi-ai-camera/raspberry-pi-ai-camera-tutorial?version=2025-09-30&progLang=
(ただし、size480x480でMCT / imx500-converter / packagerによるモデルの圧縮・変換はすでに完了しており、rpkファイルが利用可能です。exampleのimx500_classification_demo.pyなどをそのまま使っても、後述するデータを得ることができませんから、実行するpythonファイルを作成(もしくはexampleファイルを修正)する必要があります) - https://github.com/SonySemiconductorSolutions/mct-model-optimization
- https://github.com/SonySemiconductorSolutions/aitrios-rpi-sample-apps/tree/main/examples/line-monitor(似たような実装をしています。)
- Notion”Raspberry Pi AI Cameraで人流分析する(Ⅱ)” https://www.notion.so/Raspberry-Pi-AI-Camera-2e994c67881b801fa41ce08d6196b7fc
シチュエーションをまとめます。
カメラは人が一方向に通過する‹レーン›の一部を上のほうから見下ろすように設置されており、並んでいる3~5人が画角内に収まります。例となる画像を添付します。
今回の分析に必要なことは、ふたつの値を同時に計測することです。
カメラには、左(もしくは右)の端から人が映り、その逆側に向かって歩いていきます。
通過方向は一方向ですが、今回作成するプログラムを複数のRaspberry Piデバイスで実行することを想定しており、実行する環境ごとに通過する方向が異なります。必要であれば、端末に応じて予期された方向をプログラムに与えることができます。
画角上おもに顔から胸元にかけてが映ることを想定してください。カメラの外へと移動したら、その人は「通過した」と判断します。
「単位時間ごとの、カメラに映っている人数」
「単位時間ごとの、通過した人数の合計」このデータを収集することによって、レーンが混雑する時間帯と、通過する速度を分析します。
カメラに映っている人数を数えるだけでは、画角内に入る人と画角から出ていく人が同じスピードで移動しているときなどに通過した人数を把握することができないということに留意してください。
他のレーンが画角の奥に映り込む可能性があります。進行方向も同じ向きなので、スレショルドの適切な調整もしくはパウンディングボックスの大きさなどを利用して、映り込んでいるレーンの情報を含めないようにする必要があると思われます
毎日12:20から40分間プログラムを自動実行することを想定しています。基本的にRaspberry PiにはRealVNC、SSHを使用して接続しますが、かなりWi-Fi強度の弱い場所に本体を設置することになるため都度インターネットを利用しようとすると処理速度が低下する可能性があります。
バッテリーから電源を供給してRaspberry Piを起動しており、充電をはさむため常駐することはできません。12:20より前にバッテリーを接続して起動するようにはしますが、毎日特別な操作を必要とせずプログラムを起動する手段についても別途確認ししめしてください。
(cronでしょうか。その場合はプログラムを時間で終了するための機構はpythonスクリプト側に搭載するようにします。若干不安定な印象なので、確実な手段を探してください)csvファイルに結果を出力します。
実行時の日付を参照し、名前に日付を含むファイルを生成してください。また既にその日のファイルが存在する場合はファイルを分けず追記するようにしてください。
csvにはタイムスタンプ、その単位時間で映っている人数、その単位時間で通過した人数をデータとして持ちます。先述したネットワークの問題もあり、プレビュー関連がめんどうになっています。デバッグ時にはパウンディングボックス等を含むプレビューを確認したいですが、実際に実行するときはディスプレイをみない(SSHで叩くならプレビューがエラーになってしまう)ので、切り替えできる形などにしていただけるとありがたいです。
不明点があれば私に教えてください。それに対する回答を示したあと、コードの作成を指示します。
-
https://developer.aitrios.sony-semicon.com/en/docs/raspberry-pi-ai-camera/raspberry-pi-ai-camera-tutorial?version=2025-09-30&progLang=
-
おまけ 2. v8n、11nのエクスポート
チュートリアルだけでは引っかかる点もあるかと思うので、手順をまとめておきます。
WSL Ubuntu、Docker上で進めています。
2025/8時点のimx500-converter v3.16.1はPython3.12に対応していなかったため、Ubuntu 22.04を使用しています
3.17.3でPython3.12も使えるようになったとのことなので、24.04で行っても問題ないと思います
詳細はこちら(version選択に気をつけてください)FROM ubuntu:22.04 RUN apt update -y && apt upgrade -y RUN apt install -y python3-pip libgl1-mesa-dev libglib2.0-0 RUN pip3 install --upgrade pip RUN pip3 install ultralytics opencv-python torchvision mct-quantizers WORKDIR /usr/src/appディレクトリを作ってDockerfileを保存したら、
docker build -t ubuntu-yolo:22.04 . docker run -it -v "$(pwd)":/usr/src/app ubuntu-yolo:22.04 bashここでは、カレントディレクトリをコンテナ内の/usr/src/appにマウントしています。Dockerfileと同じディレクトリにファイルを配置しておくと、コンテナにアタッチしたときにアクセスが簡単になります
(Windows環境ではpwdのかわりにcdを使用してください)コンテナに入ったら、 Ultralytics YOLOチュートリアルのエクスポート用のコードを実行します
(yolo11n.ptが読み込めずにエラーになったら、ダウンロードして同じフォルダに置いてください)from ultralytics import YOLO # Load a YOLO11n PyTorch model model = YOLO("yolo11n.pt") #model = YOLO("yolo11n.pt") # Export the model model.export(format="imx", data="coco8.yaml")(imx500-converterのpyTorch版とその依存パッケージを自動でインストールする仕様)
※AITRIOSのデプロイガイドで言及されていたパッケージtorchvisionについて、自動インストールに入っていなさそうな挙動でしたが、念のためDockerfileに書き加えてあります
!!! ※自動インストールでパッケージを追加した場合、**1回目の実行は必ずエラーが発生します。**これはNumpyなどの依存パッケージがインストール直後に適用されないために、no module named ~~などになってしまうため。もう一度実行してください。
yolo11n_imx_modelというフォルダーが生成されればOK。
Raspberry Piにフォルダーを移動させておきます。以下Raspberry Piで実行
sudo apt update && sudo apt full-upgrade sudo apt install imx500-all imx500-tools sudo apt install python3-opencv python3-munkres sudo rebootcd yolo11n_imx_model imx500-package -i packerOut.zip -o ./network.rpkが完成したら、YOLOチュートリアルに従ってpicamera2のサンプルコードで実行するか、
この先のように自作のコードで利用することができます