【この記事でできること】
- e-Gov法令API Version2 から法令データを取得する方法
- Python で法令データを加工・検索する方法
- ベクトルDB(Chroma)を使った検索精度向上
- Gemma 3:4B を使ったミニQAエージェントの構築
【対象読者】
- e-Gov法令APIを使ってみたい人
- Pythonで法令データを扱いたい人
- LLM × 法令データの活用例を知りたい人
【完成イメージ】
- 法令名や条文を自然言語で質問すると、Python+LLMが回答するミニQAエージェントが動く
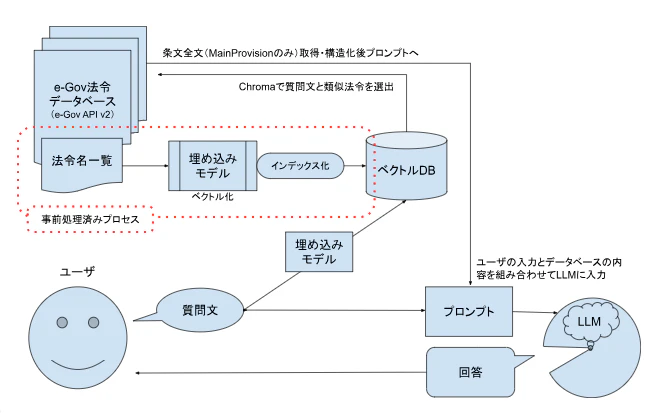
ローカルSLM Gemma 3:4B × Chroma × e-Gov API v2 の構成とローカルPCで挑戦
本記事の実験は、Interface 2025/12号「ローカルLLMを最新情報に対応させてみる」を参考にしつつ、実装部分はすべて Microsoft Copilot に生成してもらったコードをベースに丸1日で構築しています。そのため「AI を使って法令RAGを作るとどうなるか?」という観点でも読める内容になっています。
GPUは使用せず、ノートブックPCのCPUで動作実験をしています。
概要
この記事では、以下の技術スタックで構成した「日本法令QAエージェント」の現状の仕様と、ローカルPC(頑張ってCPUベース)で運用した経緯をまとめます。
- LLM: Gemma 3:4B(Ollama 経由)
- 検索: Chroma(法令名ベクトル検索)
- 埋め込み: intfloat/multilingual-e5-large(SentenceTransformer)
-
データソース: e-Gov API v2(
law_data/{LawId}) - インターフェイス: Python CLI
筆者の実験環境
OS: Windows 11 Pro(バージョン 25H2)
CPU: Intel(R) Core(TM) i7-10850H CPU @ 2.70GHz
RAM: 32.0 GB
GPU: なし(Intel UHD Graphics 128MB / CPU内蔵型、LLM推論には非対応)
生成した関数一覧
| 関数名 | 役割 | Copilotへの指示例 |
|---|---|---|
call_ollama |
LLM呼び出し(Gemma 3:4B) | 「Ollama API に POST して Gemma 3:4B を呼び出す関数を書いて」 |
extract_articles_from_law_full_text |
e-Gov API v2 の JSON から条文構造を抽出 | 「MainProvision の構造を維持して章・条・項・号を抽出する関数を書いて」 |
fetch_law_full_text_v2_structured |
APIから法令データを取得し、構造化して返す | 「law_data/{LawId} を叩いて、MainProvision を抽出する関数を書いて」 |
load_semantic_search_components |
Chromaと埋め込みモデルの初期化 | 「Chroma の laws コレクションを開いて、multilingual-e5 をロードする関数を書いて」 |
search_laws |
曖昧語から法令候補を検索 | 「クエリを multilingual-e5 で埋め込みして、Chroma で検索する関数を書いて」 |
build_context_from_candidates |
条文全文をLLMに渡すためのコンテキスト構築 | 「法令名・公布日・条文全文を整形して、LLMに渡すコンテキストを作る関数を書いて」 |
law_qa_agent |
質問に対するLLM回答生成 | 「ユーザの質問と法令コンテキストを使って、Gemma に回答させる関数を書いて」 |
main |
CLIインターフェース | 「法令QAエージェントの対話型CLIを書いて」 |
Copilot による高速プロトタイピング
今回の法令QAエージェントは、設計 → 実装 → 動作確認 までをほぼ1日で完了できました。
これは、各関数の実装を Microsoft Copilot に生成してもらいながら進めたことが大きく、自分でゼロから書くよりも圧倒的に早くプロトタイプを構築できました。
特に、e-Gov API v2 の複雑な JSON 構造については、 Copilot のマルチモーダル機能を使い、仕様書PDFやスクリーンショットを読み込ませることで、 階層構造を正確に理解したパーサを自動生成できました。
- Chroma や multilingual-e5 の初期化コードを、正しい呼び出し方で生成
- プロンプト設計の意図を伝えると、そのままテンプレート化
- CLI の対話ループも、自然な形で自動生成
これらが組み合わさり、1日で動くシステムになりました。
モデル選定の試行錯誤と、Gemma 3:4B を選んだことで得られた加速
結論として、Gemma 3:4B は「RAGとの相性」「日本語処理」「プロンプト制御」の点で最も安定していました。
当初は phi-3 系モデルを試しましたが、
- e-Gov API v2 の巨大 JSON の扱い
- 条文構造の保持
- 日本語RAGとの相性
といった点で期待した結果が得られませんでした。
雑誌Interface 2025/12号の三段階実験との比較
(本稿の位置づけ)
この雑誌の記事では、Gemma 3:4B を GPU 上で動かしながら、以下の 三段階の発展モデルで実験が行われていました。
-
LLM単体
- モデルに直接質問し、外部知識を使わずに回答させる
-
LLM+外部ファイル受け渡し
- ローカルのテキストファイルを読み込み、LLM に渡して回答させる
-
RAG(検索+LLM)
- ベクトル検索で関連文書を抽出し、LLM に渡して回答させる
今回構築した法令QAエージェントは、上記の三段階のうち 2 と 3 の中間に相当します。
- 外部ファイルではなく、e-Gov API v2 から法令本文をオンデマンド取得
- 取得した JSON を Copilot が生成したパーサで構造化(章→条→項→号)
- Chroma による 法令名レベルの曖昧検索(TOP_K=1)
- ただし、RAG のように 段落単位の検索(passage-level retrieval)は行わない
つまり、
外部知識を API から自動取得する点では RAG に近いものの、
段落単位検索を行わないため「2.5段階目」のミニマルな法令QAシステムです。
という位置づけになります。
Interface の実験を踏まえつつ、Copilot にコード生成を任せてどこまで構築できるかを検証した点が本稿の特徴です。
あくまで「個人検証用の実験システム」としての位置づけであり、業務で実用に耐えるレベルには達していません。その理由も含めて整理します。
プログラム構成と機能の仕様
1. LLM 呼び出し(Ollama × Gemma 3:4B)
- Ollama の /api/generate に POST する薄いラッパー関数。
from typing import Dict, List, Any
import json
import requests
from datetime import datetime
from sentence_transformers import SentenceTransformer
import chromadb
# --------------------------------------
# 0. Ollama 設定(Gemma 3:4B)
# --------------------------------------
OLLAMA_URL = "http://localhost:11434/api/generate"
OLLAMA_MODEL = "gemma3:4b"
def call_ollama(prompt: str, temperature: float = 0.0) -> str:
payload = {
"model": OLLAMA_MODEL,
"prompt": prompt,
"temperature": temperature,
"stream": False,
}
res = requests.post(OLLAMA_URL, json=payload, timeout=300)
res.raise_for_status()
data = res.json()
return data.get("response", "").strip()
- 役割: 条文全文をコンテキストとして与えたうえで、ユーザの質問に回答を生成する。
-
実装:
-
call_ollama(prompt: str)でhttp://localhost:11434/api/generateに JSON でリクエスト - モデル名は
gemma3:4b固定 -
stream=Falseで一括レスポンス取得 - 返却JSONの
"response"をそのまま文字列として利用
-
2. e-Gov API v2 の JSON パーサー
- MainProvision の階層構造(章→条→項→号)を維持してテキスト化。
# --------------------------------------
# 1. e-Gov API v2 JSON 構造対応パーサー
# --------------------------------------
def extract_articles_from_law_full_text(main_provision: Dict[str, Any]) -> List[str]:
"""
MainProvision の構造を維持しながら、章・条・項・号をすべて抽出する。
- ChapterTitle を章見出しとして挿入
- ArticleCaption を条見出しとして挿入
- ParagraphNum を項番号として挿入
- ItemTitle + ItemSentence を号として挿入
- Sentence.children を完全に結合
"""
output: List[str] = []
def join_text(children):
return "".join(c for c in children if isinstance(c, str))
for chapter in main_provision.get("children", []):
if not isinstance(chapter, dict) or chapter.get("tag") != "Chapter":
continue
chapter_title = ""
for c in chapter.get("children", []):
if isinstance(c, dict) and c.get("tag") == "ChapterTitle":
chapter_title = join_text(c.get("children", []))
output.append(f"\n{chapter_title}\n")
if isinstance(c, dict) and c.get("tag") == "Article":
article_num = c.get("attr", {}).get("Num", "不明")
article_caption = ""
article_lines: List[str] = []
for a_child in c.get("children", []):
tag = a_child.get("tag")
if tag == "ArticleCaption":
article_caption = join_text(a_child.get("children", []))
elif tag == "Paragraph":
para_num = a_child.get("attr", {}).get("Num", "")
para_lines: List[str] = []
for p_child in a_child.get("children", []):
if p_child.get("tag") == "ParagraphNum":
para_num = join_text(p_child.get("children", [])) or para_num
elif p_child.get("tag") == "ParagraphSentence":
for s in p_child.get("children", []):
if s.get("tag") == "Sentence":
para_lines.append(join_text(s.get("children", [])))
elif p_child.get("tag") == "Item":
item_num = ""
item_lines: List[str] = []
for i_child in p_child.get("children", []):
if i_child.get("tag") == "ItemTitle":
item_num = join_text(i_child.get("children", []))
elif i_child.get("tag") == "ItemSentence":
for s in i_child.get("children", []):
if s.get("tag") == "Sentence":
item_lines.append(join_text(s.get("children", [])))
if item_lines:
para_lines.append(f"{item_num} " + "\n".join(item_lines))
if para_lines:
if para_num:
article_lines.append(f"{para_num} " + "\n".join(para_lines))
else:
article_lines.extend(para_lines)
# 条見出しと条番号
header = f"第{article_num}条"
if article_caption:
header += f"({article_caption})"
output.append(header + "\n" + "\n".join(article_lines))
return output
def fetch_law_full_text_v2_structured(law_id: str) -> Dict[str, Any]:
"""
e-Gov API v2 の law_data を取得し、
MainProvision の構造を維持した条文抽出を行う。
- 法令名は revision_info.law_title を優先
- 巨大 JSON 対応(res.content + json.loads)
"""
url = f"https://laws.e-gov.go.jp/api/2/law_data/{law_id}"
try:
res = requests.get(url, timeout=300, stream=True)
raw = res.content
data = json.loads(raw)
except Exception as e:
return {
"law_name": "",
"full_text": "",
"error": f"JSON parse error: {e}"
}
law_info = data.get("law_info", {}) or {}
revision_info = data.get("revision_info", {}) or {}
law_full_text = data.get("law_full_text", {}) or {}
law_name = (
revision_info.get("law_title")
or law_info.get("law_num")
or "名称不明の法令"
)
# MainProvision のみ抽出
main_provision = None
for child in law_full_text.get("children", []):
if isinstance(child, dict) and child.get("tag") == "LawBody":
for sub in child.get("children", []):
if isinstance(sub, dict) and sub.get("tag") == "MainProvision":
main_provision = sub
break
if not main_provision:
return {
"law_name": law_name,
"full_text": "",
"error": "MainProvision not found"
}
articles = extract_articles_from_law_full_text(main_provision)
full_text = "\n\n".join(articles)
return {
"law_name": law_name,
"full_text": full_text,
"error": None
}
-
エンドポイント(法令API Version 2):
https://laws.e-gov.go.jp/api/2/law_data/{LawId}
-
構造処理の方針:
-
対象:
law_full_textの中のLawBody→MainProvisionのみを対象とし、付則などは除外。 - 抽出単位: 章・条・項・号の階層構造を維持しつつテキスト化。
-
処理フロー:
-
Chapter→ChapterTitleを章見出しとして挿入 -
Article→ 条番号(Num)とArticleCaptionをヘッダに -
Paragraph→ParagraphNumと本文 -
Item→ItemTitle(号番号)+ItemSentence本文 -
Sentence.childrenの文字列だけを結合してプレーンテキスト化
-
-
対象:
-
返却形式:
-
fetch_law_full_text_v2_structured(law_id)は以下の dict を返す:-
law_name:revision_info.law_titleを優先 -
full_text: 章・条・項・号を展開した条文全文(テキスト) -
error: 解析失敗時のメッセージ(Noneで正常)
-
-
3. Chroma + multilingual-e5 による曖昧な法令名検索
- 法令名レベルのベクトル検索(TOP_K=1)
# --------------------------------------
# 2. Chroma + multilingual-e5 で曖昧法令検索
# --------------------------------------
CHROMA_DIR = "chroma_law_index"
EMBED_MODEL = "intfloat/multilingual-e5-large"
TOP_K = 1
def load_semantic_search_components():
print(f"Loading embedding model: {EMBED_MODEL}")
model = SentenceTransformer(EMBED_MODEL)
print("Connecting to Chroma...")
client = chromadb.PersistentClient(path=CHROMA_DIR)
collection = client.get_collection("laws")
return model, collection
def search_laws(model, collection, query: str, top_k: int = TOP_K):
e5_query = f"query: {query}"
embedding = model.encode([e5_query]).tolist()
result = collection.query(
query_embeddings=embedding,
n_results=top_k,
)
docs = result["documents"][0]
metas = result["metadatas"][0]
ids = result["ids"][0]
candidates = []
for doc, meta, law_id in zip(docs, metas, ids):
law_name_full = doc.replace("passage: ", "")
candidates.append(
{
"law_id": law_id,
"law_name_full": law_name_full,
"promulgation_date": meta.get("promulgation_date", ""),
}
)
return candidates
# --------------------------------------
# 3. 法令コンテキスト構築(Gemma に渡す)
# --------------------------------------
def format_ymd(ymd: str) -> str:
if not ymd or len(ymd) != 8 or not ymd.isdigit():
return ymd
try:
dt = datetime.strptime(ymd, "%Y%m%d")
return f"{dt.year}年{dt.month}月{dt.day}日"
except Exception:
return ymd
def build_context_from_candidates(candidates: List[Dict[str, Any]]) -> str:
"""
候補法令ごとに v2 JSON を構造的にパースし、
法令名+公布日+本文(付則除外)だけでコンテキストを構築する。
"""
blocks: List[str] = []
for cand in candidates:
law_id = cand["law_id"]
promulgation_date = format_ymd(cand.get("promulgation_date", ""))
fetched = fetch_law_full_text_v2_structured(law_id)
law_name = fetched["law_name"]
full_text = fetched["full_text"]
error = fetched["error"]
if error:
block = f"""[法令]
法令名: {law_name}
公布日: {promulgation_date}
【エラー】
{error}
"""
else:
block = f"""[法令]
法令名: {law_name}
公布日: {promulgation_date}
【条文全文】
{full_text}
"""
blocks.append(block)
return "\n\n==============================\n\n".join(blocks)
-
Chroma:
-
パス:
CHROMA_DIR = "chroma_law_index" -
コレクション:
"laws" - 事前に「法令一覧取得API」(Version 2) から法令情報のインデックスを構築済み前提。
-
パス:
-
埋め込みモデル:
-
intfloat/multilingual-e5-large(SentenceTransformer) - クエリは
query: {質問文}形式に変換して埋め込み。
-
-
検索仕様:
-
TOP_K = 1(最も近い法令のみ採用、ハルシネーション対策) - Chroma の
documentsにはpassage: {法令名}を格納済みとし、ここから法令名を復元。 -
metadatasから公布日(promulgation_date)を取得。
-
-
戻り値:
-
search_laws(...)は[{law_id, law_name_full, promulgation_date}, ...]のリストを返す。
-
4. 法令コンテキスト構築
- プロンプトのルール:
- LawId を出さない
- 「法令名+第◯条第◯項第◯号」で参照
- 定義条は引用
- 推測禁止
# --------------------------------------
# 4. LLM(Gemma 3:4B)で回答生成
# --------------------------------------
def law_qa_agent(question: str, candidates):
laws_context = build_context_from_candidates(candidates)
# --- デバッグ出力 ---
#print("=== DEBUG: laws_context ===")
#print(laws_context)
#print("===========================\n")
prompt = f"""
あなたは日本の法律に詳しいアシスタントです。
ユーザの質問に日本語で簡潔かつ正確に答えてください。
法律用語の定義にかかわるユーザの質問では、条文に明示されていないことは推測しないでください。
回答の中では LawId は一切用いず、「法令名」と「第◯条第◯項第◯号」のみを使って条文を参照してください。
必要に応じて、どの法令・第何条に基づくかも説明してください。
以下に、曖昧語検索で絞り込まれた候補法令の条文全文を示します。
ユーザの質問の回答を作成するために適切な内容についてはその準備に情報を使用してください。
==============================
{laws_context}
==============================
【ユーザの質問】
{question}
【出力フォーマット】
- まず結論を一段落で述べる。
- 次に、根拠となる法令名・条番号を挙げる。
- 条文中に明確な定義(「◯◯とは、…をいう。」など)がある場合は、その部分を引用し、
どの法令の第何条に書かれているかを明示する。
- 条文の趣旨や射程が関係する場合は簡潔に補足する。
"""
return call_ollama(prompt, temperature=0.0)
- 目的: LLM に渡す前に、対象とする法令の条文全文をまとめたテキストブロックを作る。
-
処理:
- 候補法令ごとに
fetch_law_full_text_v2_structuredを呼び出し。 - フォーマット:
- 法令名
- 公布日(
YYYYMMDD→YYYY年M月D日に整形) - 条文全文(MainProvision のみ)
- 複数法令候補がある場合は区切り線(
==============================)で連結。
- 候補法令ごとに
5. CLI インターフェイス
# --------------------------------------
# 5. CLI 本体
# --------------------------------------
def main():
print("日本の法令 QA エージェント(Gemma 3:4B × Chroma × e-Gov API v2)")
print("何か気になることがあれば何でもお尋ねください。")
#print(" - 人工知能関連技術とは何に関する技術ですか?")
print("空行で終了します。\n")
model, collection = load_semantic_search_components()
while True:
user_input = input("あなた> ").strip()
if not user_input:
print("終了します。")
break
candidates = search_laws(model, collection, user_input, top_k=TOP_K)
if not candidates:
print("エージェント> 法令候補が見つかりませんでした。\n")
continue
print("\n[候補法令]")
for i, c in enumerate(candidates, start=1):
print(f"{i}. {c['law_name_full']}(公布日: {format_ymd(c['promulgation_date'])})")
print("\nエージェント> 上記法令も参照して回答を生成します...\n")
try:
answer = law_qa_agent(user_input, candidates)
except Exception as e:
print(f"エージェント> エラー: {e}\n")
continue
print("エージェント>")
print(answer)
print("")
if __name__ == "__main__":
main()
-
起動メッセージ:
- 日本語で簡単な説明と終了方法(空行入力)を表示。
-
対話フロー:
- ユーザ入力の日本語質問を受け取る。
- ベクトル検索で候補法令を 1 件抽出。
- 候補法令名と公布日を表示。
- e-Gov API から条文全文を取得し、LLM に渡して回答生成。
- 回答をそのまま標準出力に表示。
-
エラー処理:
- 法令候補未検出時には「法令候補が見つかりませんでした。」と表示。
- LLM 呼び出し失敗時には例外メッセージをそのまま表示。
ミニ法令QAエージェントで「できること/できないこと」
このミニ法令QAエージェントは「法令名の曖昧検索+条文全文の取得+Gemmaによる回答生成」までは実現できますが、 複数法令の横断検索や高速応答は難しく、あくまでプロトタイプ段階です。
できること
- 曖昧な日本語の質問から、関連しそうな法令を1件推定する。
- 例: 「人工知能関連技術って何を指すのか?」 → 関連法令をベクトル検索。
- 候補法令の MainProvision 部分の条文全文を e-Gov API v2 から取得し、構造を保ったままテキスト化できる。
- 条文本文を LLM に渡し、「どの法令の第何条の定義か」を明示した日本語の回答を生成できる。ただし、LLMは既知の情報を優先している様子。
- 例:「民法709条の損害賠償請求の要件を説明して」など → RAGは、「民法」を参照に選ばない
できない/弱いところ
- 法令候補は常に 1件のみ(TOP_K=1)であり、複数法令にまたがる検討はできない。
→ 複数法令を読み込ませると、処理時間がかかりすぎ、ハルシネーションリスクも増加 - 定義条(第2条など)を狙って抽出・引用するロジックが指定しにくく、LLM 任せになっている。
- 条文以外の情報(通達、解釈通知、判例など)は扱われていない様子。
→ 法令の学習データの範囲が不明 - ユーザの対話履歴を考慮したマルチターン対話はしていない。毎回質問単体で完結。
ローカルPC(CPUベース)での利用限界
1. 処理速度(レイテンシ)の限界
-
LLM推論が遅い:
Gemma 3:4B を CPU のみで動かすと、1問あたり 2〜3 分かかることがあり、 インタラクティブな利用は現実的ではありません。 -
埋め込み生成も重い:
multilingual-e5-large は埋め込みモデルとしては重く、CPU だとクエリ1件あたりのレイテンシが無視できないレベルになる。 -
e-Gov API 呼び出しのオーバーヘッド:
-
law_dataの JSON のサイズは様々で、法令によってはネットワーク+パースにやや時間がかかる。
→ 民法、会社法など基本法は条文数が多い(ただし、既にLLMが学習済みか?)
→ とはいえ、法令APIのレスポンスは早く、データのパース処理完了までのオーバーヘッドは、実務上気にならないレベル。 - 回答のたびに毎回 API を叩くため、往復の遅延は積み重なる。
-
→ 結果として、インタラクティブな対話エージェントとして使うにはレスポンスが遅すぎるというのが正直なところです。
2. モデルサイズとメモリの制約
- Gemma 3:4B を快適に動かすには、一定以上のRAMとCPUコアが必要。
- そもそも動作が遅すぎて、アレクサなど他のデバイスとの連携はもちろん、PC作業との並行を実現する余力は絶望的。
- 将来的に 8B, 12B など大きいモデルに差し替える余地がほぼない。
3. 拡張性・継続運用の限界
- PCを高性能化しても、数年後にはモデルの進化速度に追いつけなくなる可能性が高い。
- ローカルの環境依存(Pythonバージョン、ライブラリ、GPU有無など)が強く、他者と再現共有しづらい。
- LLM側の進化(新モデル、量子化、推論エンジンの改善)を取り込むには、都度ローカルでセットアップし直す必要がある。
現時点での位置づけ
このミニ法令QAエージェントは、所詮、現状では次のような位置づけです。
-
用途:
- 個人の興味関心にもとづく「法令×LLM×RAG」の実験用プロトタイプ
- e-Gov API v2 の JSON 構造理解とパーサ設計の検証
- Chroma+multilingual-e5 による曖昧語→法令名マッピングの試験
-
実用性:
- ローカルCPU環境ではレイテンシが大きく、業務利用のツールとしては現時点では非現実的。
- 会社法務の業務の効率化という観点では、既存のクラウドLLMやGASでの処理の方が即効性が高い。
-
今後の改善方向:
- GPU環境(Colab やクラウドGPU)への移行による高速化
- 法令候補の複数件取得と絞り込みロジックの追加
- 定義条(第2条など)にフォーカスした抽出・表示
- 法令以外の公式資料(ガイドライン、通達等)への拡張
まとめ
- Gemma 3:4B × Chroma × e-Gov API v2 で、日本の法令全般に対応するQAエージェントを構成してみました。
- e-Gov API v2 の
MainProvisionをパースし、「章・条・項・号」を保ったテキスト化ができるようにはなりいました。※法令APIからは施行された最新法令データのみ法令IDが取得できる仕様です。未施行法令データの法令IDは、ダウンロード版で取得できることは確認済みですが、API取得できるのかは仕様確認が不十分でわかりませんでした。 - 曖昧な日本語の質問から、multilingual-e5+Chroma で関連法令を1件選び、条文全文をコンテキストにした LLM 回答は可能になりました。これで、LLMが未学習のデータも補強できます。ユーザ指定で複数の法令を参照したり、新しく公布、改定施行された法律を柔軟に指定できる仕組みにRAG検索を拡張できると有益かと思います。
- しかし、CPUベースのローカル環境ではレイテンシが大きく、外部への機密漏洩リスクを回避する目的があるとしても実用的な対話エージェントとして使うには余りにも力不足です。
- 現状では、確かに「個人の技術検証・学習目的のプロトタイプ」としての価値が中心ですが、 法令×LLM×RAG の実験としては十分に有益であり、今後の発展の土台になると感じました。
この記事が、同様の構成で法令エージェントやRAGシステムを検討している方の参考になれば幸いです。