この記事はApache Spark Advent Calendar二日目の記事として書きました。
Apache Sparkにはその分散処理の特徴を活かした機械学習ライブラリ、MLlib, MLが含まれています。元々オンメモリで分散処理を行うSparkにとってiterativeな計算が必要な場面の多い機械学習のアルゴリズムとは親和性が高く期待の大きかった分野のひとつでもあります。
モデルの大きさ
ところがDeep learningのような最近話題の手法、アルゴリズムでは非常に大きなモデルを扱う場合があります。ここでの大きさとは次元数、合計としてのデータ容量の大きさを含みます。MLlibのアルゴリズムを見てみるとしばしば以下のようにモデルの重みをbroadcastしていることがわかります。
while (!converged && i <= numIterations) {
// 重みをbroadcastしている
val bcWeights = data.context.broadcast(weights)
// Sample a subset (fraction miniBatchFraction) of the total data
// compute and sum up the subgradients on this subset (this is one map-reduce)
val (gradientSum, lossSum, miniBatchSize) = data.sample(false, miniBatchFraction, 42 + i)
.treeAggregate((BDV.zeros[Double](n), 0.0, 0L))(
seqOp = (c, v) => {
// c: (grad, loss, count), v: (label, features)
val l = gradient.compute(v._2, v._1, bcWeights.value, Vectors.fromBreeze(c._1))
(c._1, c._2 + l, c._3 + 1)
},
combOp = (c1, c2) => {
// c: (grad, loss, count)
(c1._1 += c2._1, c1._2 + c2._2, c1._3 + c2._3)
})
}
これは重みが更新されればこれがiterationの度に発生してしまうので、モデルが大きくなってくると非常に負荷の大きな処理になってしまうことがわかります。またこれだとモデルの更新を一つのプロセス(スレッド)で行う必要があり、モデルの更新がボトルネックになってしまうことがあります。(GradientDescentでは各partition毎のtaskで計算されたgradientを集めてきてまとめて更新をかけるようになっています)
分散KVS for Machine Learning
そこでひとつの解決策として出てきたのがParameter Serverです。オリジナルがどこから(誰から?)はわかりませんが有名なところだとGoogleのDistBeliefの論文にmotivationと目的みたいなものが読み取れます。
簡単に言ってしまうとモデルを単一のプロセスで保持してそれをまた配布してというのがボトルネックになりがちなので外出しした特別な分散データベースにモデルを入れておくためのシステムです。
Spark with Parameter Server
もちろんSpark自体、大きなデータセットに対する処理を目的とした分散処理エンジンなのでそこで動かした機械学習モデルも大きくなることはありそうです。であればSparkをParameter Serverと上手く一緒に使えるようにしてあげるのが便利です。以下で議論されています。
SPARK-4590の方はParameter Serverとは何か、どんな実装が現在あるのかという事前調査を行っています。この中で参考にした(調査した)システムとして5つあげられていたのでそんなに実装があるのかと驚きました。汎用的な機械学習ライブラリも含まれているので必ずしもSparkに対する外部ストレージとしてのParameter Serverをあげているわけではなさそうです。
SPARK-6937の方ではもう少し仕様や設計に関した議論が行われています。このチケットのdescriptionの中で簡単にデザインに関する記述がありますが、その中では自前でParameter Serverを実装する方針のようです(Ps-on-Spark)。ExecutorごとにPSClientがいて、特定のプロトコルにしたがってParameter Serverと通信し値の更新などを行います。こいつがcache controlも行うようです。このBSP/SSPの実装によってはbackendとなるParameter Serverも変更できそうです。
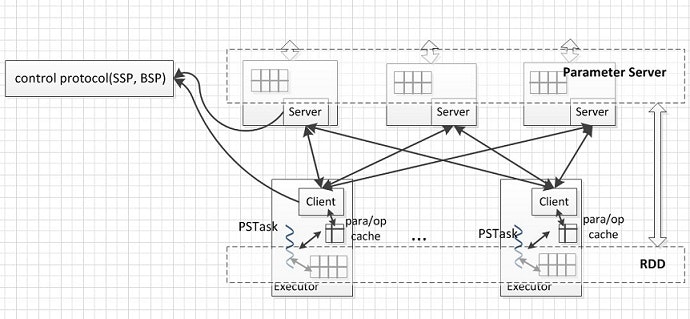
ただParameter Serverを効率的に使うためにはCoreの部分に変更を加える必要があるため、議論が紛糾してしまっています。(実質pending?)
-
runWithPSAPIをRDDに追加 -
PSClient,PSServerを追加。Parameter Serverと各jobとのcoordinationを行う - YARNによって管理される
ParameterServerBackendを追加。PSはYARN上で動く
となっています。今年の前半に議論は止まってしまっているみたいですが、CoreではなくMLlib, MLぐらいへの変更で対応できるように頑張れたら楽しそうだなと思います。