これは「祝 .NET 6 GA!.NET 6 での開発 Tips や試してみたことなど、あなたの「いち推し」ポイントを教えてください【PR】日本マイクロソフト Advent Calendar 2021」の13日目の記事です。
.NETでは恒例のパフォーマンス改善ですが、今回はよく利用するFileStreamに対して改善が入っていました。
リリースノートではWindows環境に対しての言及がほとんどでしたが、Linuxやmacでも改善されているよということでしたので、実際どれくらい変わっているのか検証してみました。
結論
.NET6にあげることでファイルアクセスを行っているアプリケーションのパフォーマンスは10〜90%上がる。
- macでは読み書きともに速度が20〜30%程度向上する
- Linuxではバイナリとしての書込速度は10%、読込速度は20%程度向上する
- Windowsは速度が20〜82%程度向上する
- どの環境でもアロケーションは格段に改善されている
検証条件
今回の検証ですべての環境を準備するのは難しかったので、検証の環境はGitHub ActionsのCloud Runnerに実行してもらいました。
GitHub ActionsはWindows、Linux、macすべての環境があり、Publicリポジトリなら課金されないのでパフォーマンス検証するときにはもってこいの環境ですね(本当はそういう用途じゃないんだけどね。。。)。
なお、現時点ではLinuxとWindowsはAzureのVirtual MachinesのDS_v2インスタンスを使っているそうです(GitHub docs参照)。
ベンチマークの測定は.NET Runtimeチームも使用しているBenchmarkDotNetを使っています。
.NET Core 3.1での処理速度をベースラインとして.NET5や.NET6でどのように改善されているかを示しています。
検証に使用したコードはGitHubで公開しています。
書き込み
単一のファイルに対して8000Bずつ100MBを超えるまで書き込みを行い、その処理にかかった時間を計測しています。
バッファサイズを指定できますが、今回はバッファなしの結果のみを記載しています(GitHubにはバッファありもあります)。
string tempDir = Path.Join(Path.GetTempPath(), new Random().Next().ToString());
byte[] writeData = new byte[8_000];
[Benchmark]
public async Task WriteAsync()
{
using (var fs = new FileStream(Path.Join(tempDir, "1.txt"), FileMode.OpenOrCreate, FileAccess.Write, FileShare.None, 1, FileOptions.Asynchronous))
{
for (int i = 0; i < 100_000_000 / 8_000; i++)
{
await fs.WriteAsync(writeData);
}
}
}
いずれの環境でも改善幅に差異がありますが、処理速度が向上していました。
特にWindowsは82%も向上しているのはすごいですね。
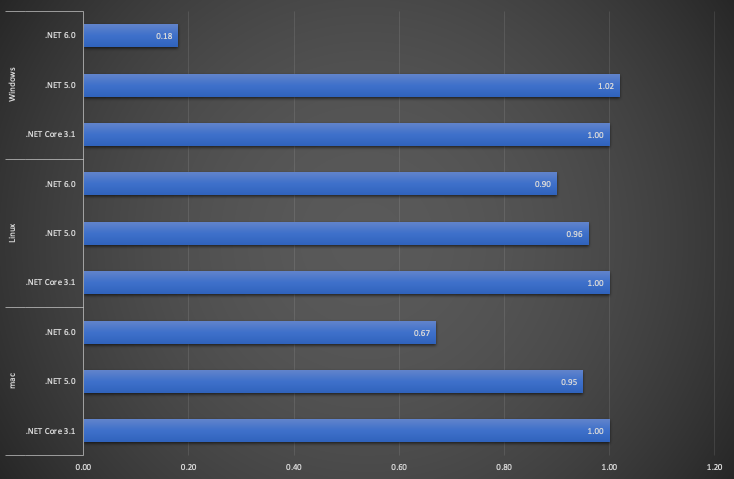
| Platform | Method | Runtime | Mean | Error | StdDev | Median | Ratio | Allocated |
|---|---|---|---|---|---|---|---|---|
| mac | WriteAsync | .NET Core 3.1 | 435.7 ms | 8.65 ms | 22.02 ms | 434.6 ms | 1.00 | 1,400,640 B |
| mac | WriteAsync | .NET 5.0 | 414.8 ms | 8.27 ms | 22.08 ms | 416.5 ms | 0.95 | 1,401,208 B |
| mac | WriteAsync | .NET 6.0 | 290.3 ms | 5.73 ms | 16.34 ms | 286.6 ms | 0.67 | 1,768 B |
| Linux | WriteAsync | .NET Core 3.1 | 115.67 ms | 0.644 ms | 0.716 ms | 115.41 ms | 1.00 | 1,400,616 B |
| Linux | WriteAsync | .NET 5.0 | 111.26 ms | 1.468 ms | 1.442 ms | 110.75 ms | 0.96 | 1,401,120 B |
| Linux | WriteAsync | .NET 6.0 | 104.52 ms | 1.999 ms | 2.053 ms | 103.82 ms | 0.90 | 1,680 B |
| Windows | WriteAsync | .NET Core 3.1 | 1,814.2 ms | 45.39 ms | 132.41 ms | 1,767.9 ms | 1.00 | 3,900,544 B |
| Windows | WriteAsync | .NET 5.0 | 1,835.9 ms | 58.06 ms | 171.19 ms | 1,794.8 ms | 1.02 | 3,900,824 B |
| Windows | WriteAsync | .NET 6.0 | 333.9 ms | 6.65 ms | 9.74 ms | 332.5 ms | 0.18 | 1,632 B |
読取り
100MBのファイルをバイナリもしくはテキストとして読取りを行った時にかかった時間を計測しました。
バイナリ
画像ファイルの読取りなどバイナリを展開するケースを想定して検証しています。
[Benchmark]
public async Task ReadBinaryAsync()
{
using (var fs = new FileStream(binaryFilePath, FileMode.Open, FileAccess.Read, FileShare.None, 1, FileOptions.Asynchronous))
using (var buffer = MemoryPool<byte>.Shared.Rent())
{
await fs.ReadAsync(buffer.Memory);
}
}
すべての環境で処理速度が改善されています。特にWindowsでは65%も処理速度が改善されているので、ほぼ別物という印象を受けますね。
このグラフには表されていないですが、メモリの使用量がいずれの環境でも減少しています。
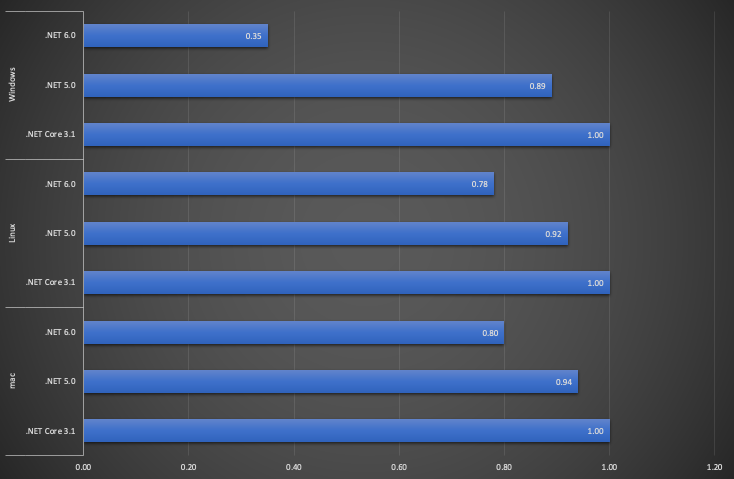
| Platform | Method | Runtime | Mean | Error | StdDev | Ratio | Allocated |
|---|---|---|---|---|---|---|---|
| mac | ReadBinaryAsync | .NET Core 3.1 | 143.6 ms | 1.21 ms | 1.01 ms | 1.00 | 2,931,148 B |
| mac | ReadBinaryAsync | .NET 5.0 | 133.7 ms | 2.53 ms | 2.82 ms | 0.94 | 2,930,384 B |
| mac | ReadBinaryAsync | .NET 6.0 | 114.4 ms | 1.78 ms | 1.66 ms | 0.80 | 880 B |
| Linux | ReadBinaryAsync | .NET Core 3.1 | 99.30 ms | 1.903 ms | 2.115 ms | 1.00 | 2,930,320 B |
| Linux | ReadBinaryAsync | .NET 5.0 | 90.53 ms | 1.770 ms | 2.423 ms | 0.92 | 2,930,360 B |
| Linux | ReadBinaryAsync | .NET 6.0 | 77.67 ms | 1.311 ms | 1.287 ms | 0.78 | 702 B |
| Windows | ReadBinaryAsync | .NET Core 3.1 | 898.0 ms | 17.72 ms | 31.95 ms | 1.00 | 7,439 KB |
| Windows | ReadBinaryAsync | .NET 5.0 | 800.5 ms | 15.49 ms | 24.57 ms | 0.89 | 7,440 KB |
| Windows | ReadBinaryAsync | .NET 6.0 | 310.2 ms | 6.04 ms | 7.85 ms | 0.35 | 1 KB |
テキスト(すべて読取り)
Json.NETなどファイルを文字列で読み取るようなライブラリを使用することを想定して検証しています。
[Benchmark]
public async Task ReadToEndAsync()
{
using (var fs = new FileStream(textFilePath, FileMode.Open, FileAccess.Read, FileShare.None, 1, FileOptions.Asynchronous))
using (var reader = new StreamReader(fs, System.Text.Encoding.UTF8))
{
await reader.ReadToEndAsync();
}
}
どの環境でも.NET6の処理速度が最速となっています。Linuxやmacでは.NET5でも改善されていますが、Windowsでは改善されていなかったようです。
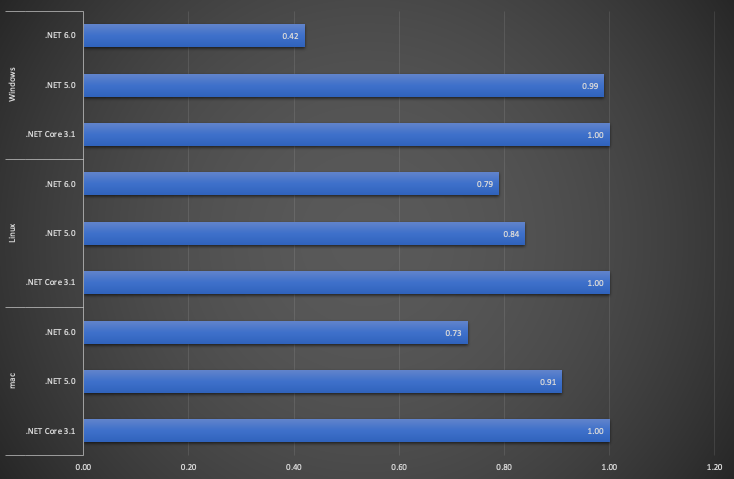
| Platform | Method | Runtime | Mean | Error | StdDev | Ratio | Allocated |
|---|---|---|---|---|---|---|---|
| mac | ReadToEndAsync | .NET Core 3.1 | 994,591.79 μs | 19,614.803 μs | 25,504.785 μs | 1.00 | 471,130,312 B |
| mac | ReadToEndAsync | .NET 5.0 | 914,261.27 μs | 17,205.888 μs | 16,094.398 μs | 0.91 | 471,143,408 B |
| mac | ReadToEndAsync | .NET 6.0 | 725,359.32 μs | 14,249.168 μs | 15,837.912 μs | 0.73 | 458,251,744 B |
| Linux | ReadToEndAsync | .NET Core 3.1 | 716,571.41 μs | 2,057.085 μs | 1,924.199 μs | 1.00 | 471,083,920 B |
| Linux | ReadToEndAsync | .NET 5.0 | 607,833.82 μs | 12,008.877 μs | 16,031.506 μs | 0.84 | 471,087,744 B |
| Linux | ReadToEndAsync | .NET 6.0 | 566,903.26 μs | 1,923.785 μs | 1,799.510 μs | 0.79 | 458,188,592 B |
| Windows | ReadToEndAsync | .NET Core 3.1 | 5,281,795.2 μs | 56,882.44 μs | 50,424.80 μs | 1.00 | 536,077,456 B |
| Windows | ReadToEndAsync | .NET 5.0 | 5,250,030.3 μs | 56,082.39 μs | 49,715.58 μs | 0.99 | 536,054,312 B |
| Windows | ReadToEndAsync | .NET 6.0 | 2,223,889.1 μs | 43,426.38 μs | 42,650.51 μs | 0.42 | 499,137,912 B |
テキスト(一行ずつ読取り)
大きなCSVファイルの解析などでこのようなケースはあると思い、検証してみました。
[Benchmark]
public async Task ReadLineAsync()
{
using (var fs = new FileStream(textFilePath, FileMode.Open, FileAccess.Read, FileShare.None, 1, FileOptions.Asynchronous))
using (var reader = new StreamReader(fs, System.Text.Encoding.UTF8))
{
while (!reader.EndOfStream)
{
await reader.ReadLineAsync();
}
}
}
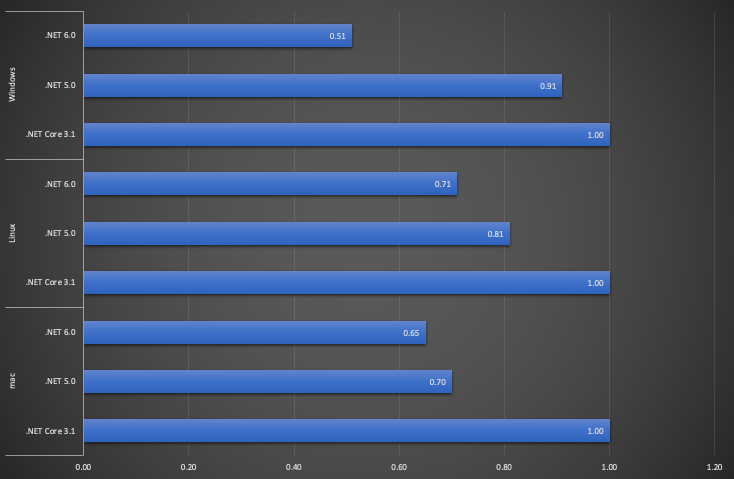
| Platform | Method | Runtime | Mean | Error | StdDev | Ratio | Allocated |
|---|---|---|---|---|---|---|---|
| mac | ReadLineAsync | .NET Core 3.1 | 2,212,384.28 μs | 39,836.519 μs | 59,625.426 μs | 1.00 | 1,259,609,272 B |
| mac | ReadLineAsync | .NET 5.0 | 1,553,304.66 μs | 29,945.133 μs | 44,820.465 μs | 0.70 | 1,259,612,272 B |
| mac | ReadLineAsync | .NET 6.0 | 1,421,562.18 μs | 20,657.507 μs | 18,312.342 μs | 0.65 | 1,246,721,792 B |
| Linux | ReadLineAsync | .NET Core 3.1 | 1,636,147.91 μs | 15,000.364 μs | 13,297.432 μs | 1.00 | 1,259,615,008 B |
| Linux | ReadLineAsync | .NET 5.0 | 1,317,737.00 μs | 21,426.717 μs | 20,042.564 μs | 0.81 | 1,259,616,040 B |
| Linux | ReadLineAsync | .NET 6.0 | 1,155,445.15 μs | 12,888.646 μs | 12,056.047 μs | 0.71 | 1,246,723,232 B |
| Windows | ReadLineAsync | .NET Core 3.1 | 6,924,200.8 μs | 97,166.74 μs | 90,889.82 μs | 1.00 | 1,275,463,704 B |
| Windows | ReadLineAsync | .NET 5.0 | 6,276,452.7 μs | 80,520.90 μs | 75,319.30 μs | 0.91 | 1,274,899,344 B |
| Windows | ReadLineAsync | .NET 6.0 | 3,505,060.1 μs | 48,024.39 μs | 42,572.37 μs | 0.51 | 1,244,165,824 B |
まとめ
プラットフォーム関係なく処理性能・メモリ使用量がかなり改善されていました。
ファイル読込はどのようなアプリケーションでも頻繁に使用されるところ(アプリケーション実行時のDLL読込時とか)なので、すべての人がこの改善を感じることができるのではないかと思います。
今回の改善がStrategy Patternを使用して行ったということで、性能改善の際の参考にもなるのではと思いました。
参考