おいしいクラフトビールを知ってほしい
ビールおいしいですよね!!
食材は四季にあったものがおいしいように,ビールだってシーズンに合わせたものをいただくのが良いんですよ!
クラフトビールは,水・麦・ホップが様々な見た目・香り・味のビールを生みだし,
まさにビール醸造家(ブルワリー)が作り出した芸術品です.
例えば春には桜をイメージしたビール(実際に食べられる桜を原料として使っている)や,冬にはクリスマスをイメージしたビールなどもあります.
とても苦いビールや,甘酸っぱいビール,チョコレートのような味がするビールもあったりします.
そのようなビールを飲むだけの消費者から,自分も何かを生みだす側になりたいと思ってはじめた企画.
前回の記事ではBrewDogのビールに関するデータをスクレイピングしデータ分析を行いました.
おいしいクラフトビールはどれだ? スクレイピング&分析からわかるBrewDogのビールづくり
https://qiita.com/Kuma_T/items/37a4e2e1648647d18f9a
今回もビールについての解説を交えながら,テキスト解析の調査結果を紹介していきたいと思います.

対象
RateBeer (https://www.ratebeer.com/) には世界中のビールの情報・レビューが掲載されています.
一般的なビールから,ドがつくほどのマイナーなビールまで,本当に何でも載っています.
今回もこちらのRateBeerからスクレイピングで情報を取得します.1
スクレイピングの対象とするのはBrewDogのビールとしました.

画像:BrewDog Punk IPA
BrewDogはイギリス スコットランドのブルワリーです.
2007年に設立された比較的新しいブルワリーですが,Punk IPAをはじめ世界中で愛されるビールをつくっています.
2018年3月時点で500種類を超えるビールが作られており,対象として申し分ないです.
画像にもあるPunk IPAのレビューについて,テキストマイニングを行い,形態素解析によって分析します.
Punk IPAは世界で最も飲まれているクラフトビールの一つだと思います.
現在寄せられているレビューの件数は2300件以上!レビュー件数も申し分ないですね.
スクレイピング
RateBeerはJavaScriptを使用しています.
そのためWebブラウザをPythonを使って操作し,JavaScriptを実行させたあとに表示されるhtmlを取得します.
今回もブラウザをPythonで操作するためにSeleniumを使います.
Google ChromeのHeadlessモードを使っています.
表示されたコードはBeautifulsoupを使ってスクレイピングしていきます.
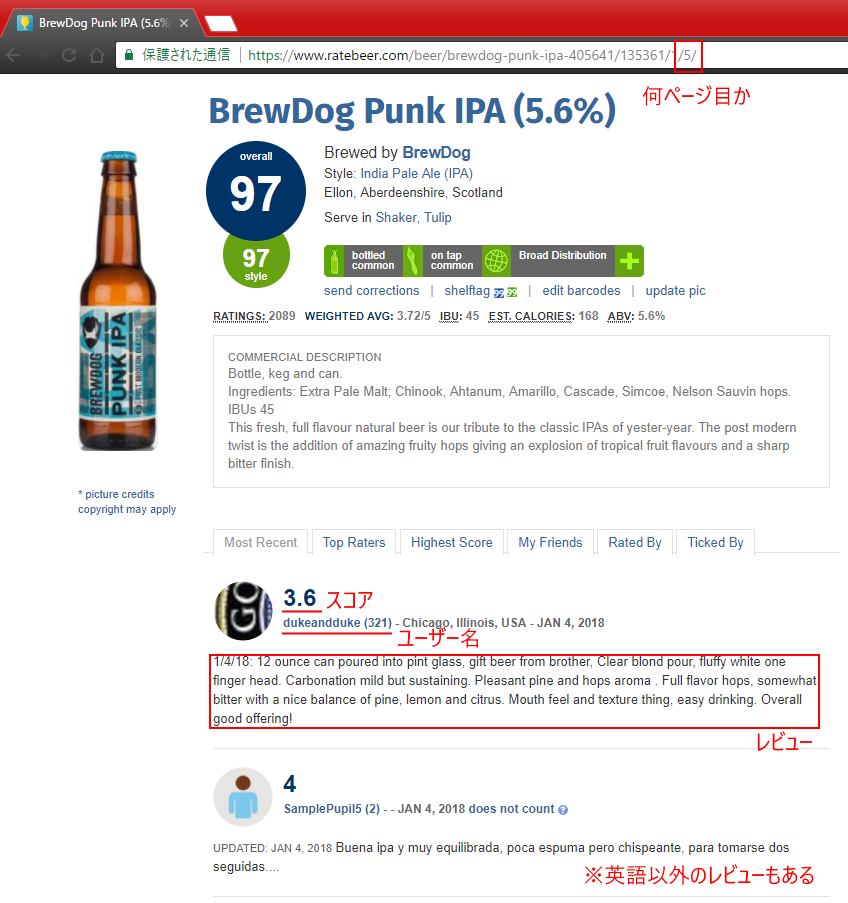
レビューは1ページあたり10件掲載されるので,for文でアドレスを変えながらアクセス→スクレイピングを繰り返します.
レビューとスコア(今回は使いません)および,レビュアー(ユーザー名)をDataFrameに入れていきます.
英語以外のレビューもありますが,大半が英語なので,英語を標本とした解析で問題ないでしょう.
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import re
import pandas as pd
import time
"""Seleniumの設定"""
options = Options()
options.set_headless(True) # headlessモードを有効に
driver = webdriver.Chrome(chrome_options=options, executable_path=r"XXXXXXXX") # PATHを設定する場合
# driver = webdriver.Chrome(chrome_options=options) # PATHを通してある場合はこちら
"""スクレイピング"""
for j in range(1, 231):
address = "https://www.ratebeer.com/beer/brewdog-punk-ipa-405641/135361/1/"+str(j)+"/" # レビューが掲載されているページ
time.sleep(1) # 負荷をかけないように一応スリープを入れている
"""レビューを取得"""
driver.get(address)
html = driver.page_source.encode('utf-8')
soup = BeautifulSoup(html, "html.parser")
review = soup.find_all("div", {"style": r"padding: 20px 10px 20px 0px; border-bottom: 1px solid #e0e0e0; line-height: 1.5;"})
score = soup.find_all("div", {"style": r"display:inline; padding: 0px 0px; font-size: 24px; font-weight: bold; color: #036;"})
reviewer = soup.find_all("small", {"style": r"color: #666666; font-size: 12px; font-weight: bold;"})
"""DataFrameに追加"""
for i in range(10): # 1ページあたり10件のレビュー
if i==0 and j==1:
df=pd.DataFrame([[score[i].text, review[i].text]], columns=["Score", "Review"], index=[reviewer[i].a.text])
else:
df2=pd.DataFrame([[score[i].text, review[i].text]], columns=["Score", "Review"], index=[reviewer[i].a.text])
df=df.append(df2)
# df.to_csv("beer.csv")
自然言語処理
自然言語処理をやっていきましょう.レビューが英語なので今回はNLTK(Natural Language Toolkit)を使います.
NLTK 3.2.5 documentation
http://www.nltk.org/
http://www.nltk.org/nltk_data/
日本語では,MeCab ChaSen Kuromoji Juman++あたりが有名でしょうか.
英語では,Polyglotなども使われていますが,触った感じNLTKが良さげでした.2
マニュアルや機能が充実していることから,とりあえず触ってみたい人にも使いやすいと思います.
英語は,単語間がスペースで区切られているので,とにかくトークン化(分かち書き)が簡単なのが嬉しいです.
NLTKは様々な機能をダウンロードしてから使います.
下記のように, nltk.download("punkt") などですぐに使えるようになります.
import matplotlib.pyplot as plt
import nltk
# from nltk.corpus import stopwords
"""初期設定"""
nltk.download("punkt") #このあたりをダウンロードしておくと良い
nltk.download("averaged_perceptron_tagger")
# nltk.download("stopwords") #以下のストップワードを使っても良い
# nltk.corpus.stopwords.words('english')
"""図の初期設定"""
plt.rcParams['xtick.direction'] = 'out'#x軸の目盛線が内向き('in')か外向き('out')か双方向か('inout')
plt.rcParams['ytick.direction'] = 'out'#y軸の目盛線が内向き('in')か外向き('out')か双方向か('inout')
plt.rcParams['xtick.major.width'] = 1.0 #x軸主目盛り線の線幅
plt.rcParams['ytick.major.width'] = 1.0 #y軸主目盛り線の線幅
plt.rcParams['font.family'] = 'Times New Roman' #使用するフォント名
plt.rcParams['figure.figsize'] = [10, 10]
plt.rcParams['font.size'] = 18 #フォントの大きさ
次に文章をトークン化し,中身を見ながら可視化します.
いろんな方が言うように,本質的ではない言葉を探し出す(辞書にする)のが一番やっかいですね.
実際にやってみるとよくわかりました.(「and」「a」「the」や前置詞などなど)
あと初めて知って共有しておきたかったことはdf2=df2[~df2["word"].str.match(no_words)]のように~を付けるとNotの効果があるということ.
つまりno_wordsに一致しない言葉をdf2に入れ直しているということです.
"""トークン化"""
sentence = []
for i in range(len(df)):
sentence.append(df["Review"][i])
tokens = nltk.word_tokenize(str(sentence))
"""見える化"""
df2=pd.DataFrame(tokens, columns=["word"])
no_words = r",|a$|and|with|the|of|is|:|to$|in$|it$|'|’|but|!|on$|\?|\.|very|this|for|de$|\)|s$|head|I$|that" # |で区切り. $で完全一致
df2=df2[~df2["word"].str.match(no_words)] # "~" でnot
df2=df2["word"].value_counts()
df2[19::-1].plot.barh(color="#348ABD") #横バーは barh
plt.xlabel("Number", fontsize=20)
plt.ylabel("Words", fontsize=20)
# plt.savefig("Words", bbox_inches="tight")
plt.show()
結果
ここからは抽出した言葉のうちトップ20の結果を解説を交えながら見てみましょう.
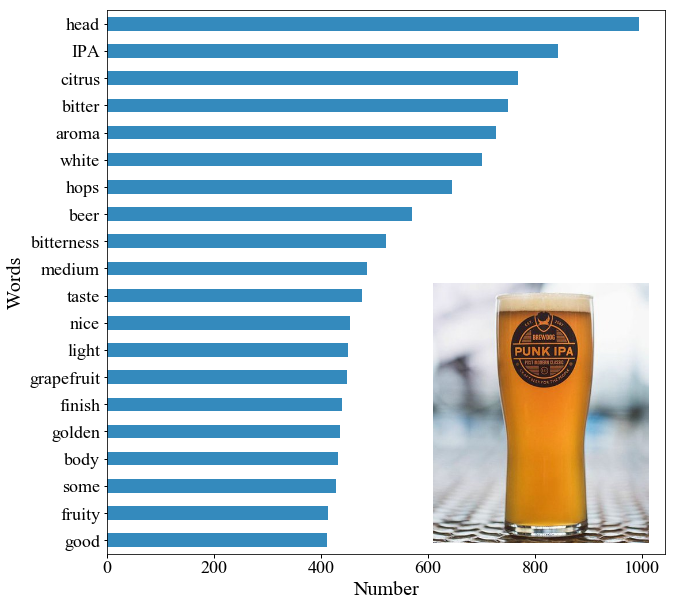
第1位は「head」
ビールのheadは,その名の通り頭である泡の部分を指します.第6位のwhiteと共起されることが多かったですね.
写真の通り白い泡ですので,その特徴をちゃんと抽出できています.
ビールの見た目としてgolden(16位)が入っていますね.
ビールと泡の比率は7:3とよく言われます.泡にはビールの見た目だけでなく,おいしさを閉じ込める効果などもあります.3
ですが!クラフトビールは奥が深い!
原料,熟成度合い,注ぐグラスの形などで泡は大きく変わります.
ビールを飲むとき最初に口にする泡にも注目すると面白いですよ!
第2位は「IPA」
スタイルの一種であるIPAとはIndia Pale Ale(インディア ペール エール)の略で,その一番の特徴は大量のホップから醸し出される苦味とフルーティーな香りです.
通常の3倍くらいホップを投入しているため,おいしい苦味がグーッときます.
Punk IPAはもちろんIPAなのでこれも抽出できていますし,同様にbitter(第4位),bitterness(第9位)なども上位に入っています.
ビールには100を超える種類(スタイル)があります.4
最初は「ラガー」「エール」の違いを楽しむところから始めて,
「IPA(苦い系)」「ヴァイツェン(白ビール系)」「スタウト(黒ビール系)」「フルーツビール(甘酸っぱい系)」などを試してみると好きなジャンルが見えてくると思います.
第3位は「citrus」
シトラスとは柑橘類という意味です.
柑橘類だと曖昧ですが,確かにPunk IPAは苦味に加えてホップが醸し出すfruityさ(第19位)があります.
実際に香りに対するレビューは多く見られ,aroma(第5位),grapefruit(第14位)なども特徴的ですね.
クラフトビールを飲むときには,味だけでなくぜひ香りも楽しんでみてください.
特にお店では,香りが楽しめるようなグラスで提供されることも多いです.
WordCloudでオシャレに見せよう
最後にWordCloudで文字列を表示してみます.
word clouds in Python
http://amueller.github.io/word_cloud/index.html
WordCloudも簡単に自然言語処理をすることができます.
カラー画像をマスクとしてWordCloudを作製する機能がなかなかイケてます.
実際にやってみましょう.
"""WordCloudで見える化"""
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
beer_coloring = np.array(Image.open(r"XXXXXXXXXXX")) # カラーイメージをオープン
image_colors = ImageColorGenerator(beer_coloring) # イメージからカラーを作製
stopwords = set(STOPWORDS)
fpath = r"C:\Windows\Fonts\Meiryo UI\meiryo.ttc" #fontの設定
wordcloud = WordCloud(background_color="white",font_path=fpath, max_words=2000,\
mask=beer_coloring, stopwords=set(stopwords), max_font_size=40, random_state=42).generate(str(tokens).replace("'", ""))
plt.imshow(wordcloud.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
# plt.savefig("WordCloud1.png",format = 'png', dpi=600, bbox_inches="tight")
plt.figure()
plt.imshow(beer_coloring, cmap=plt.cm.gray, interpolation="bilinear")
plt.axis("off")
# plt.savefig("WordCloud2.png",format = 'png', dpi=600, bbox_inches="tight")
plt.show()

めちゃくちゃオシャレな絵ができました!
結論
今回の記事をまとめます.
Punk IPA is ...
・IPA, and bitterness of hops tastes good (IPAで,ホップの苦味がおいしい)
・White head and golden light-medium body (白い泡で,黄金色かつライト-ミディアムなボディ)
・Fruity aroma like citrus (柑橘類のようなフルーティーな香り)
ということがわかりました.実際その通りなのでちゃんとできたなと思います.
今回はスクレイピングを駆使し,テキストマイニングと形態素解析によって簡単な自然言語処理に取り組んでみました.
もっと踏み込んで共起表現などを探すのにも興味がでてきましたね.
プログラミングの知見を増やしつつ,ビールの魅力が伝わったらいいなと思っています.
なので,これからも面白い記事をあげていければと思っています.
今回は以上です.
気にいったら「いいね」をお願いします!
参考文献
【Python】自然言語処理でラーメン屋を分類してみる
https://qiita.com/naotaka1128/items/87d717961bd0c34e7a64
Word Cloudで文章の単語出現頻度を可視化する。[Python]
https://qiita.com/kenmatsu4/items/9b6ac74f831443d29074
【Pythonでテキストマイニング】TwitterデータをWordCloudで可視化してみる
http://www.randpy.tokyo/entry/python_wordcloud
Natural Language Toolkit
http://www.nltk.org/
テキストマイニングツール
https://textmining.userlocal.jp/
-
RateBeerはAPIを公開していますが,API Keyの承認に1-2週間かかるそうです.今回もサーバーに負担をかけないよう配慮しつつスクレイピングしております. ↩
-
その他の選択肢はこちらが参考になると思います: https://www.datasciencecentral.com/profiles/blogs/python-nlp-tools ↩
-
とりあえずはこの辺を見ておくと面白いですよ!: http://www.ozmall.co.jp/restaurant/article/10562/ ↩