おいしいクラフトビールを見つけたい!
ビールおいしいですよね!!
嬉しいとき,疲れているとき,一人で飲んでも,みんなで飲んでもおいしいです.
そんなビールの中でもクラフトビールは,大手企業の大衆的・大量生産なビールに比べて様々な見た目や味のスタイルが存在するビールで,
本当においしい一杯に出会えたときには感動を覚えたものです.
そんなクラフトビールについての簡単な説明を加えながら,スクレイピングやデータ解析の結果を紹介していきたいと思います.
対象
RateBeer (https://www.ratebeer.com/) には世界中のビールの情報・レビューが掲載されています.
一般的なビール(例えば日本のビール会社)から,ドがつくほどのマイナーなビールまで,本当に何でも載っています.
今回はこちらのRateBeerからスクレイピングで情報を取得し,”おいしい”と思うビールについて明らかにしたいと思います.1
スクレイピングの対象とするのはBrewDogのビールとしました.

画像:BrewDog Punk IPA
BrewDogはイギリス スコットランドのブルワリー(ビールの醸造所)です.
2007年に設立された比較的新しいブルワリーですが,Punk IPAをはじめ世界中で愛されるビールをつくっています.
IPAとはIndia Pale Ale(インディア ペール エール)の略で,その一番の特徴は大量のホップから醸し出される苦味とフルーティーな香りです.
2018年3月時点で500種類を超えるビールが作られており,分析対象としても申し分ないです.
スクレイピング
RateBeerはJavaScriptを使用しています.
そのためWebブラウザをPythonを使って操作し,JavaScriptを実行させたあとに表示されるhtmlを取得します.
今回ブラウザをPythonで操作するためにSeleniumを使います.
さらにGoogle ChromeのHeadlessモードという,バッググラウンドでは実際には普通のブラウザとして動いていますが,
デスクトップには表示されないという開発者向きな機能を使います.
インストールは pip install seleniumでOKです.
表示されたコードはBeautifulsoupを使ってスクレイピングしていきます.
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import re
import pandas as pd
import time
"""Seleniumの設定"""
options = Options()
options.set_headless(True) # headlessモードを有効に
driver = webdriver.Chrome(chrome_options=options, executable_path=r"~~~~~") # PATHを設定する場合
# driver = webdriver.Chrome(chrome_options=options) # PATHを通してある場合はこちら
以上のようにして簡単な初期設定を行います.
以下のコード2では,Beer Listから全てのビールのリンク先および掲載日(Added)を取得します.
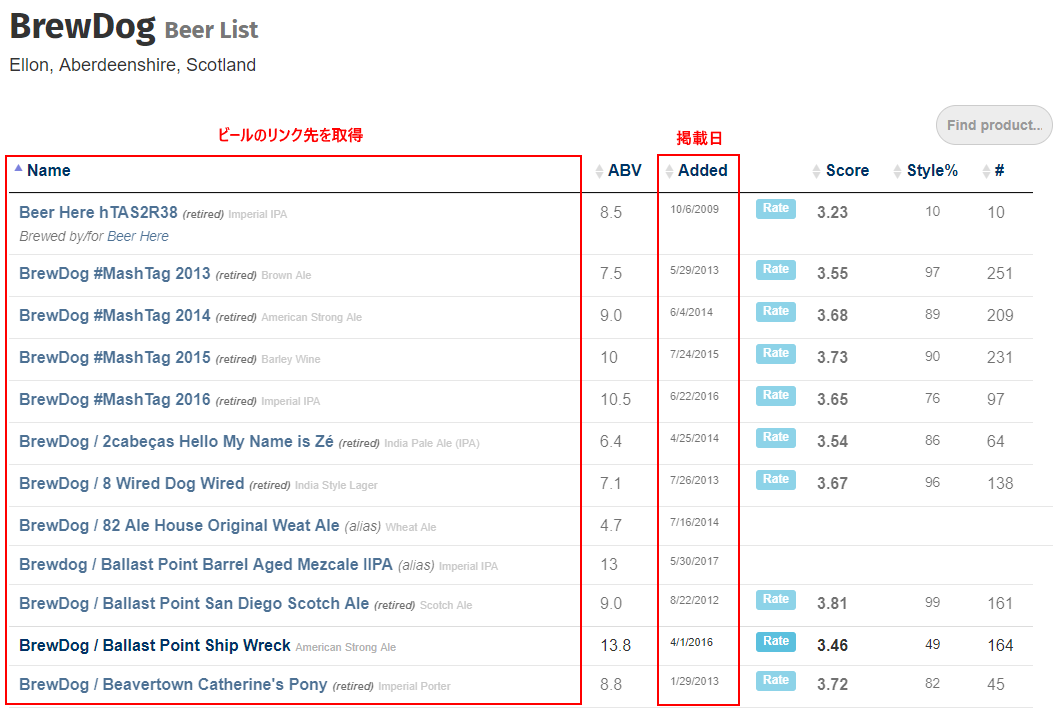
"""ビールのリストから情報を取得"""
driver.get("https://www.ratebeer.com/Ratings/Beer/ShowBrewerBeers.asp?BrewerID=8534") # ブラウザでアクセス.このアドレスを変更する.
html = driver.page_source.encode('utf-8')
soup = BeautifulSoup(html, "html.parser") # BeautifulSoupで扱えるようにパース
soup_brewtable = soup.find("table", {"id": "brewer-beer-table"}) # tableの取得
BeerNames = soup_brewtable.find_all("strong") # ビールの名前とリンク先が格納されている
Added = soup_brewtable.find_all("td", {"class": "real-small text-nowrap text-left hidden-xs "}) # 情報が追加された日付を取得
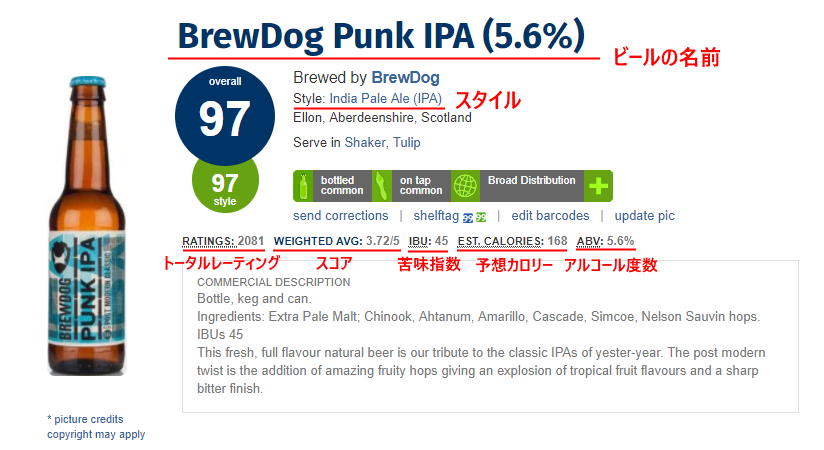
次のコード3では,リンク先に再度アクセスし,ビールの情報を取得,Pandas DataFrameに格納します.
具体的には,「ビールの名前」「スタイル」「トータルレーティング」「スコア」「苦味指数」「予想カロリー」「アルコール度数」です.
(一部のビールについては「MEAN(平均スコア)」「SEASONAL(季節的なビールか)」なども記載されています)
また,一部のビールについてはスコアやスタイルの情報が記載されていません.
このようなビールについては情報を取得しないようにしました.
"""全アイテムの取得"""
for i in range(len(BeerNames)):
driver.get("https://www.ratebeer.com/"+BeerNames[i].a.get("href"))
time.sleep(1) # 負荷をかけないよう1秒のスリープを入れている
html_link = driver.page_source.encode('utf-8')
soup_link = BeautifulSoup(html_link, "html.parser")
BeerName = soup_link.find(itemprop="name").text
if soup_link.find("div", class_="col-md-10") != None: # Not equal に気づくまで時間がかかった
Style = soup_link.find("div", class_="col-md-10").find("a", href=re.compile("beerstyles")).text # ビアスタイルの情報
soup_states = soup_link.find("div", class_="stats-container").find("small").text.replace("\xa0\xa0", ",").replace(": ", ",").replace(", ", ",").split(",")
"""データをDataFrameに格納する(ここの記載方法は改善の余地ありかも?)"""
if i==0:
df=pd.DataFrame([soup_states[1:len(soup_states):2]], index=[BeerName], columns=soup_states[0:len(soup_states):2])
df['STYLE']=Style
df['Added']=Added[i].text
else:
df2=pd.DataFrame([soup_states[1:len(soup_states):2]], index=[BeerName], columns=soup_states[0:len(soup_states):2])
df2['STYLE']=Style
df2['Added']=Added[i].text
df=df.append(df2)
# df.to_csv("beer.csv") #CSVで出力
スクレイピングにはそれなりの時間がかかります.
中身を覗いてみると,以下のように情報が取得できていることがわかります.
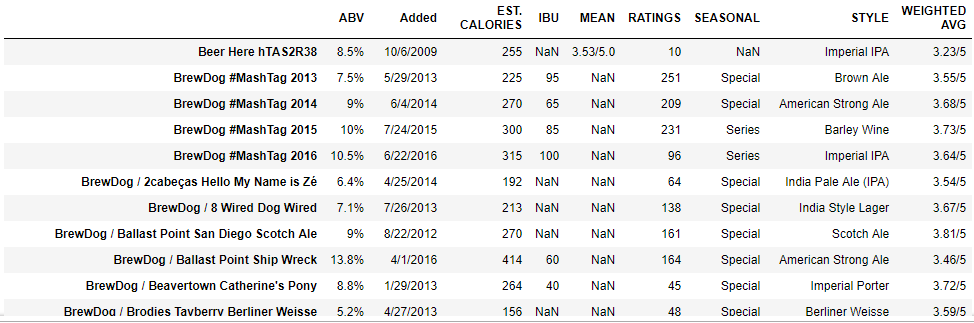
このままでは使いづらいデータもありますので,一部についてはデータ整形を行っておきました.
データ分析
実際にデータを可視化してみましょう.
アルコール度数に対する予想カロリー
まずは「アルコール度数に対する予想カロリー」
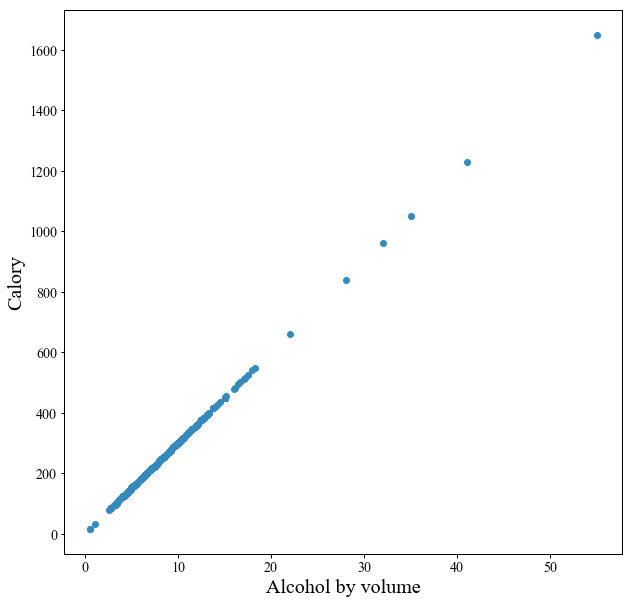
予想カロリーは,12液量オンス(約340ml)あたりの値です.
キレイな直線に乗っています.
こちらはアルコール度数10%で予想カロリー300となっているようです.
さて,この図を見ると大半のビールはアルコール度数~20%ですが,一部には**アルコール度数50%を超える"ビール"**が存在することがわかります.
(340mlで予想カロリーが1600超えは普通のビールの感覚からすると恐ろしいですね…)
こちらは「The End Of History」というビールで,スタイルはEisbock(アイスボック)となっています.
Bockとはドイツ語で羊を意味し,濃いめの色合いと高いアルコール度数が特徴.
Eisbockはボックを凍らせて氷を取り除くことでアルコール度数をさらに高めたスタイル.
度数55%は当時1位の記録だということも特徴ですが,何より驚愕なのはそのボトルです.
リスの剥製の中にボトルが入っているという奇抜さに,動物愛護団体に怒られたらしいです.2
(リンク先に画像があるので興味がある人はどうぞ)
スタイルに対する銘柄数
次に,BrewDogはどのようなビールを作っているのか「スタイルに対する銘柄数」を図にしてみます.
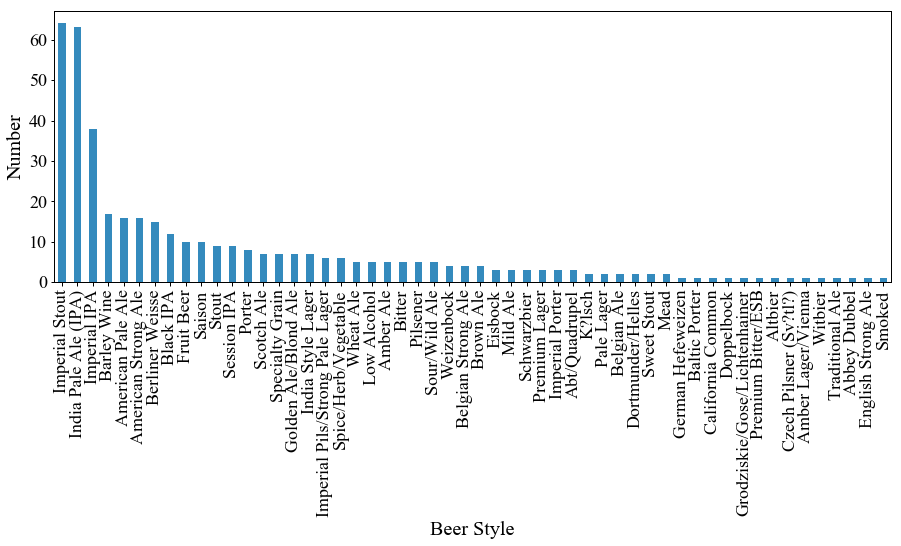
特に上位だけを抽出したのが下の図です.
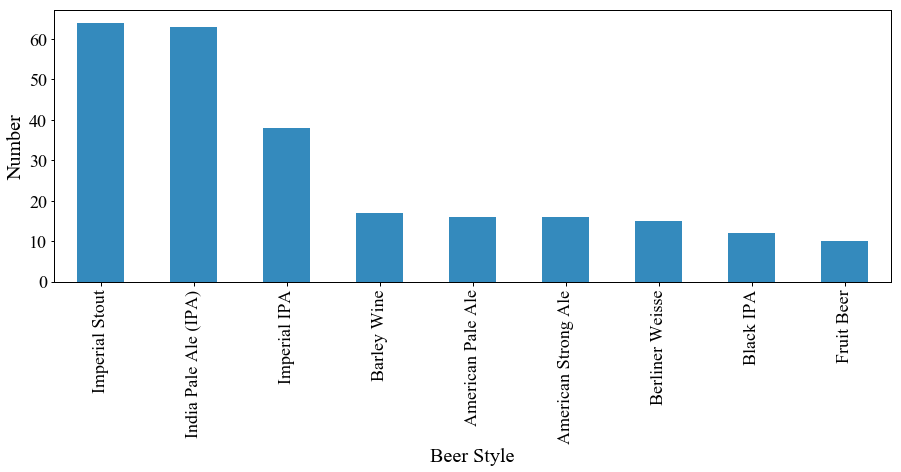
特に上位を見ると,Imperial StoutやIPA,Imperial IPAが突出して多いことがわかります.
英語で「どっしりした、頑強な、丈夫な」などの意味を持つスタウト(Stout).
ロシア皇帝への献上品として作られたとされるのがImperial Stoutであり,
その特徴は焙煎した麦による非常に濃い黒色から醸し出されるコーヒーやチョコレートのような香りと高いアルコール度数.
Imperial IPAは高いアルコール度数,IPAよりもさらに多くのホップを使った苦味の強さが特徴.
このようなビールを多く作っている理由として推測されるのがやはり気候ではないでしょうか.
スコットランドはイギリスの中でも特に北部に位置しており,
体を温めるため,またビールを凍らせないため,高いアルコール度数のビールが多いと考えられます.
年ごとのスタイル数
「年ごとのスタイル数」を積み上げバーで見てみましょう.あまりに種類が多かったので凡例(Legend)は省略しました.
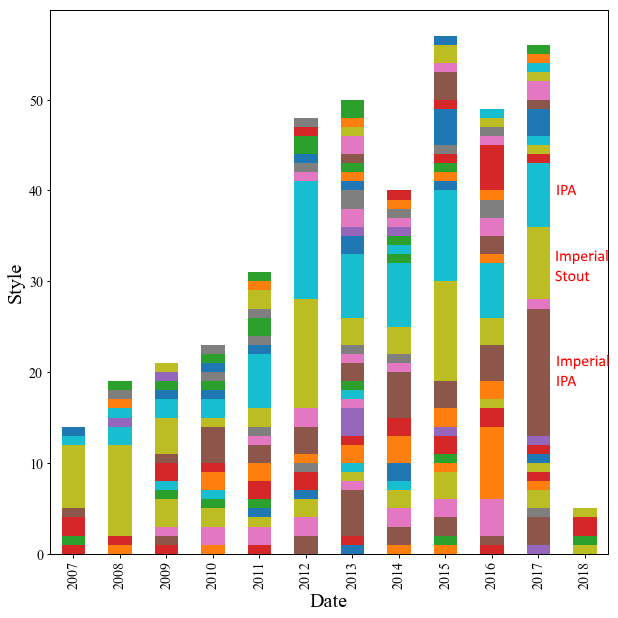
年々醸造数を増やしていることが明らかです.
最初は1年に15-20種類程度でしたが,今では50種類も作ってるんですね!
特に先の3スタイルに注目すると,Imperial Stoutはコンスタントにつくりつつ,
IPAやImperial IPAは徐々に増えつつありました.
ビールにもカスタマイゼーションの波がきているのでは?と感じています.
日付に対するスコア
次に「日付に対するスコア」を見ていきます.
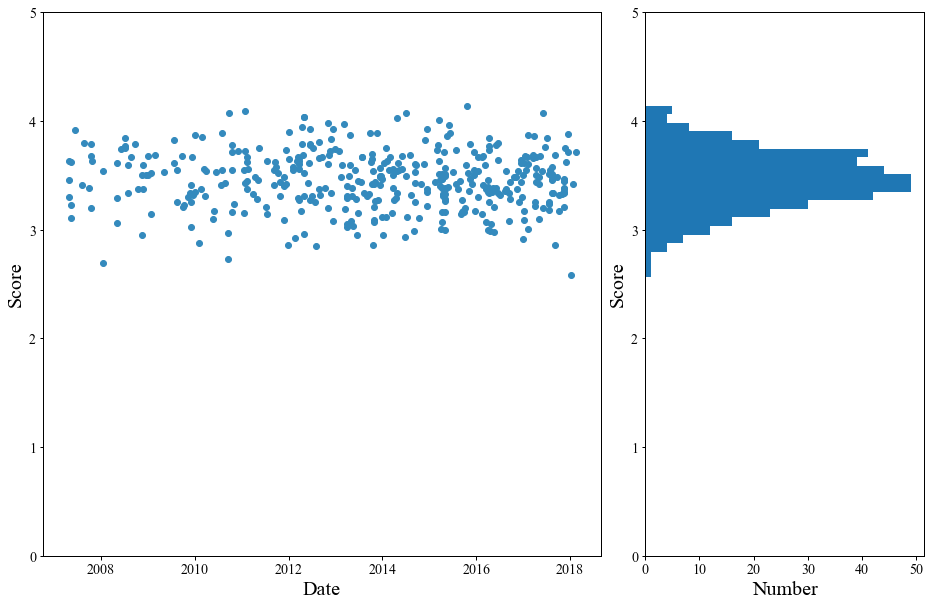
スコアの平均値は3.45でした.
スコアについて簡単に補足すると,RateBeerではレビューの点数をベイズ推定でスコアとして定めています.
単純な平均点ではなく,たくさんビールを飲んで様々なビールを飲んだ人がおいしい(5点)と言えばスコアが高くなるものと思われます.
さて,BrewDogのビールに言えることは,「どのビールも出来が良い」ということです.
どのビールもスコア3.4-3.5にまとまっているのは,はっきり言って素晴らしい結果です.3
年々良くなっている(or悪くなっている)ということもなさそうですね.
どのビールを飲んでもおいしいという信頼があるのは,卸業者やレストランの経営者なども安心できるのではないでしょうか.
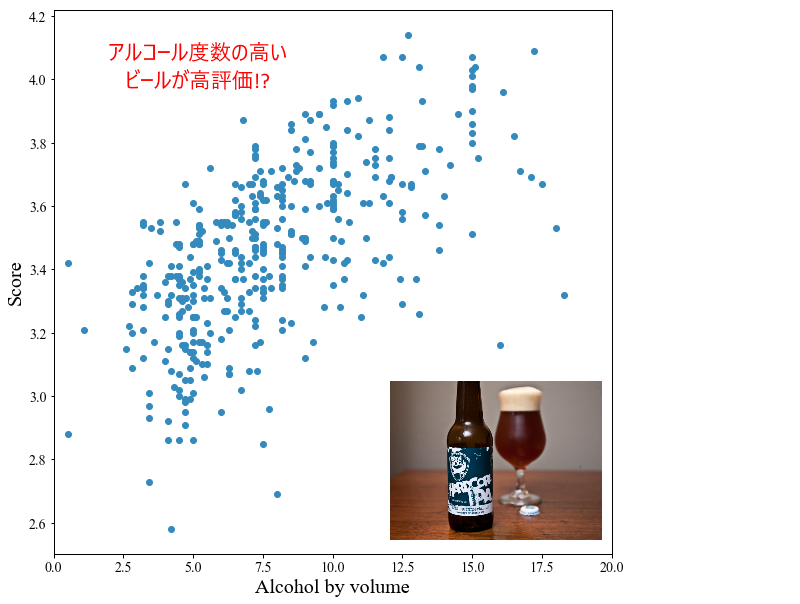
アルコール度数に対するスコア
最後に「アルコール度数に対するスコア」を見ます.
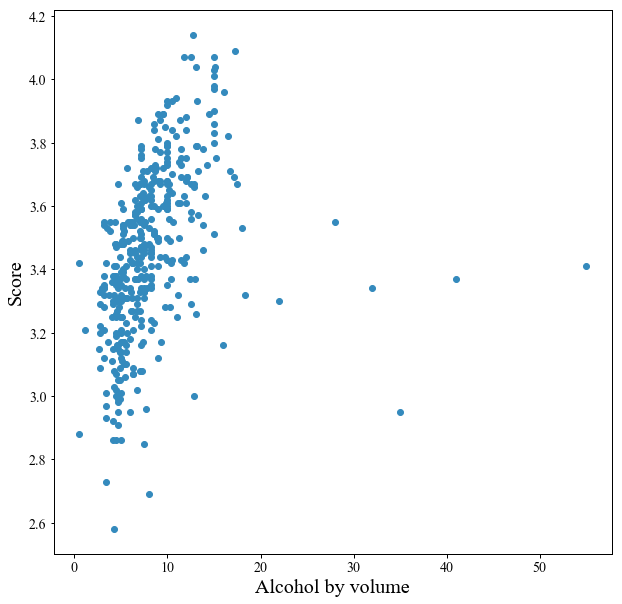
特に~20%だけを抽出したのが下の図です.
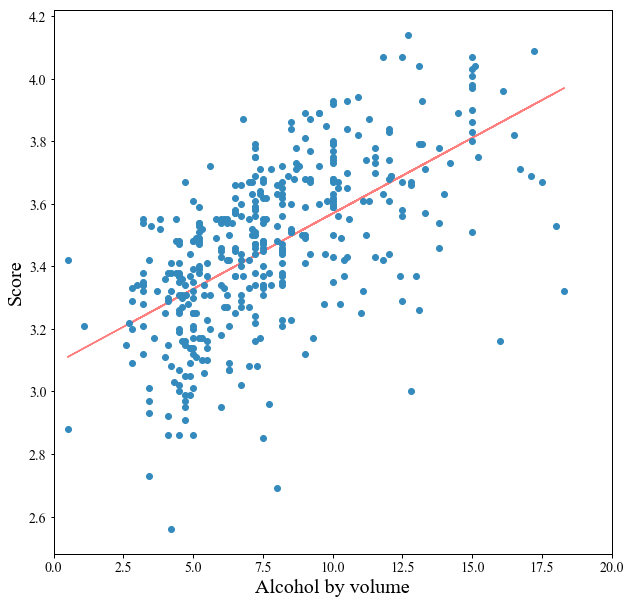
アルコール度数が高くなるとスコアが高くなるという,正の相関がありました.
赤線は最小二乗フィッティングで $ y=0.048x+3.086 $ が得られ,相関係数 $r=0.61$ でした.
気候や金額面もあるとは思いますが,アルコール度数が高いビールほどウケがいいと言ってもいいでしょう.
結論
BrewDogは...
・Imperial Stoutや(Imperial)IPAなどのスタイルを多くつくっている
・どのビールも素晴らしい
・特にアルコール度数が高いビールが高評価
ということがわかりました.
土地柄か日本では高いアルコール度数のビールは多くないですが,つくってみたら案外受け入れられるかもしれません.
世界で高い評価を得てから逆輸入的に日本に入れるのなんてどうでしょう.
ビール会社,ブルワリーの人は検討してみてください(私が喜んで買って飲みます).
さて,スクレイピングを駆使し,クラフトビールのデータを可視化して簡単な分析をしてみました.
好きなビールについて何かしらの貢献ができればと思い取り組んでみましたが,面白い結果が得られとても満足しています.
記事については以上です.
気にいったら「いいね」をお願いします!
参考資料
Beautiful Soupドキュメント
https://tdoc.info/beautifulsoup/
PythonとBeautiful Soupでスクレイピング
https://qiita.com/itkr/items/513318a9b5b92bd56185
Python Webスクレイピング テクニック集「取得できない値は無い」JavaScript対応
https://qiita.com/Azunyan1111/items/b161b998790b1db2ff7a
BeautifulSoup4のfind()とfind_all()について理解を深める
http://mankuro.hateblo.jp/entry/2017/05/02/beautifulsoup4-find-and-find_all/
Pythonで標準偏差と相関係数の計算
https://qiita.com/takaki@github/items/247ada674b594dd8fdce
オマケ:ビールと統計学
かの有名な「統計学入門」(東京大学出版)にはビールに関するコラムがかかれています.
統計学理論はギネス・ビールから
ウィリアム・ゴセットは $ t $ 分布の発見者(導入者)である.
オクスフォード大学のニュー・カレッジで,数学と自然科学を学んで優等賞を受け卒業したあと,アイルランドのダブリンにある有名なビール会社ギネス Guiness に入社した.
ゴセットは常に平均$\tilde{x}$と分散$s^2$を計算しながら,ビールの品質を監視していたが,標本が小さいとき($n$が小さいとき),$s^2$や$s$の値がおかしくなることに気がつき,品質の平均$\tilde{x}$の信頼性に$s/{\sqrt{n}}$を用いてよいかどうか,疑念をもちはじめた.
1908年,「平均が有する可能な誤差」という論文を発表する.
これが,有名な $ t $ 分布の発見である.
大変おもしろい話ですね。
ゴセットもおいしいビールづくりについて考えていたのではないでしょうか。