大きなデータを取り扱ってみたい!
株価を分析するのって面白そう!
と思い立って調べてみると,海外の株式はPandasのDataReaderで案外簡単にデータとして手に入りますが,
(例えばGoogle financeやFREDなど)
日本の株価は,案外データとして見つかりません.
Yahoo!ファイナンスから引っ張ってくればいいじゃん!という記事は多いですが,
Yahoo!ファイナンスはスクレイピングを禁止しているため,こちらから引っ張ってくるわけにもいきません.
モジュールのjsmを使えば…という意見もあるかもしれませんが,こちらもスクレイピングを使用しています.
本記事は,スクレイピングなしでデータを取得し,ひとつのリストとすることを目的とします.
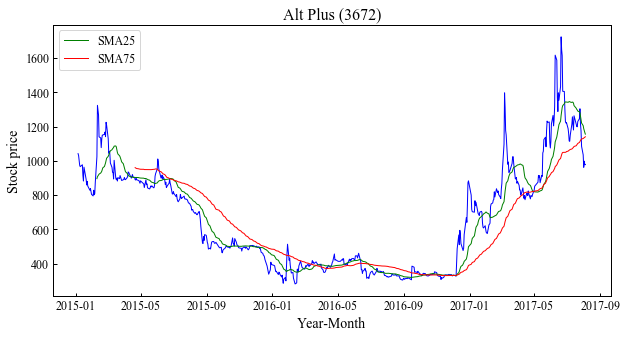
せっかちな人のためのコード
いいから結論だけ教えてくれ!って人のために(がんばってかいた)コードをおいておきます.
細かい点は各自修正をお願いします.
import os
import pandas as pd
import matplotlib.pyplot as plt
os.chdir("C:\\Users\\Kuma_T\\stock") #ファイルの場所を指定,先にデータを入れておく
plt.rcParams['figure.figsize'] = [10, 5]
plt.rcParams['xtick.direction'] = 'in'#x軸の目盛線が内向き('in')か外向き('out')か双方向か('inout')
plt.rcParams['ytick.direction'] = 'in'#y軸の目盛線が内向き('in')か外向き('out')か双方向か('inout')
plt.rcParams['xtick.major.width'] = 1.0 #x軸主目盛り線の線幅
plt.rcParams['ytick.major.width'] = 1.0 #y軸主目盛り線の線幅
plt.rcParams['font.size'] = 12 #フォントの大きさ
plt.rcParams['axes.linewidth'] = 1.0 # 軸の線幅edge linewidth。囲みの太さ
plt.rcParams['font.family'] = 'Times New Roman' #使用するフォント名
code = 3672 #オルトプラス
start = 2015
end = 2017
x = []
y = []
for n in range (start, end+1):
file_name = 'stocks_'+str(code)+'-T_1d_%d.csv' %n #ファイル名を指定
data = pd.read_csv(file_name, header=0, encoding='cp932') #日本語が読めないのでencodingを指定
a =list(pd.to_datetime(data.iloc[:,0], format='%Y-%m-%d')) #そのまま読み込むと日付を認識できないのでdatetimeで
x += a[::-1] #リスト内を逆順にするため[::-1]を適用し,xのリストに足していく
b = list(data.iloc[:,4])
y += b[::-1]
z = pd.DataFrame(y)#DataFrameに変換
sma75 = pd.DataFrame.rolling(z, window=75,center=False).mean()
sma25 = pd.DataFrame.rolling(z, window=25,center=False).mean()
plt.plot(x, y, color="blue", linewidth=1, linestyle="-")
plt.plot(x, sma25, color="g", linewidth=1, linestyle="-", label="SMA25")
plt.plot(x, sma75, color="r", linewidth=1, linestyle="-", label="SMA75")
plt.title("Alt Plus ("+str(code)+")", fontsize=16, fontname='Times New Roman')
plt.xlabel("Year-Month", fontsize=14, fontname='Times New Roman') # x軸のタイトル
plt.ylabel("Stock price", fontsize=14, fontname='Times New Roman') # y軸のタイトル
plt.legend(loc="best")
plt.show()
データの準備
個別銘柄株価データ
http://k-db.com/stocks/
こちらにアクセスすると,日本の株式のデータがCSVファイルで手に入ります.
試しにオルトプラス(3672)を見てみると,
CSVファイルがこちらにあるので特定のフォルダにダウンロードしておきます.
ちなみにこちらのデータは,上側が日付が新しくなっています.
今回は2015-2017のデータをダウンロードしました.
データの読み込み
まずはダウンロードしたフォルダを指定します.
import os
import pandas as pd
import matplotlib.pyplot as plt
os.chdir("C:\\Users\\Kuma_T\\stock") #ファイルの場所を指定,先にデータを入れておく
次に保存したCSVファイルを読み込んでいきます.

stocks_3672-T_1d_2015
stocks_3672-T_1d_2016
stocks_3672-T_1d_2017
というファイルを用意していますので,
銘柄コードを3672
読み込み開始を2015年
読み込み終了を2017年とします.
次に空のリストを作っておきます.
code = 3672 #オルトプラス
start = 2015
end = 2017
x = []
y = []
ループ関数の中を書いていきます.
読み込むファイル名を指定し,Pandasのread_csvで読み込みます(和文でエラーがでるため,encodingを指定しています).
dataの1列目の日付データをiloc[:, 0]で,pd.to_datetimeで日付として読み込み,リストにします.
前述の通り,CSVファイルは上側が日付が新しいので,逆順にして古い日付を上にして空のリストに足していきます.
同様に4列目の終値も空のリストに足していきます.
for n in range (start, end+1):
file_name = 'stocks_'+str(code)+'-T_1d_%d.csv' %n #ファイル名を指定
data = pd.read_csv(file_name, header=0, encoding='cp932') #日本語が読めないのでencodingを指定
a =list(pd.to_datetime(data.iloc[:,0], format='%Y-%m-%d')) #そのまま読み込むと日付を認識できないのでdatetimeで
x += a[::-1] #リスト内を逆順にするため[::-1]を適用し,xのリストに足していく
b = list(data.iloc[:,4])
y += b[::-1]
これで目的の株価のデータをリスト型で得ることができました.
グラフ化して確認
ここまできたらグラフ化して確認しましょう.
plt.plot(x, y, color="blue", linewidth=1, linestyle="-")
plt.show()
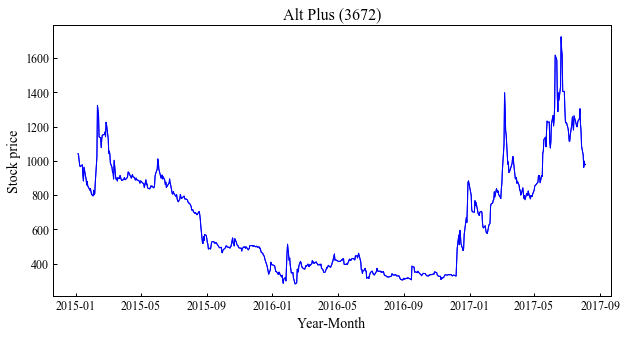
無事にグラフができています.
注意点としては,逆順で読み込んでいないと以下のようになってしまいます.
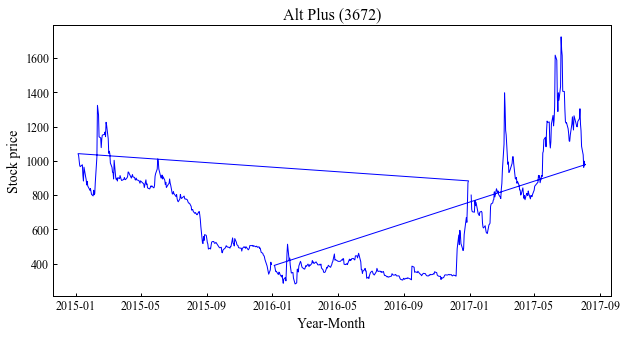
移動平均を追加する
おまけで移動平均を追加してみましょう.
移動平均はPandasのDataFrame.rollingを使用することで簡単に求めることができます.
DataFrame.rollingはその名の通り,DataFrame形式で使用するため,Listを変換しておきます.
z = pd.DataFrame(y)#DataFrameに変換
sma75 = pd.DataFrame.rolling(z, window=75,center=False).mean()
sma25 = pd.DataFrame.rolling(z, window=25,center=False).mean()
plt.plot(x, y, color="blue", linewidth=1, linestyle="-")
plt.plot(x, sma25, color="g", linewidth=1, linestyle="-", label="SMA25")
plt.plot(x, sma75, color="r", linewidth=1, linestyle="-", label="SMA75")
今回は25日移動平均と75日移動平均を追加しています.
最後に
スクレイピングなしで,日本株式のリストを取得できました.
今回はオルトプラス(3672)を使ってみましたが,個別の銘柄で試してみてください.
今度はこちらのデータを使って解析してみたいと思います.
最後におことわりですが,筆者は株もプログラミングもまだまだビギナーです.
何かあればコメントをお願いします.
以下参考にした記事などの紹介
Pythonで機械学習を使った株価予測のコードを書こう
http://www.stockdog.work/entry/2017/02/09/211119
【Python/jsm】日本企業の株価データを銘柄ごとに取得
https://algorithm.joho.info/programming/python/jsm-get-japan-stock/
Python の jsm モジュール で 株価(原系列)時系列データ 取得 して、出力した折れ線グラフを Gmailに添付してメール配信
http://qiita.com/HirofumiYashima/items/471a2126595d705e58b8
Python pandas で日本の株価情報取得とローソク足チャート描画
http://sinhrks.hatenablog.com/entry/2015/02/04/002258
過去のデータからビッグデータ分析で株価を予測する
http://qiita.com/ynakayama/items/420ebe206e34f9941e51
第1回 pandasで株価をスクレイピング 〜S◯I証券風のチャートを描いてみる〜
http://www.stockdog.work/entry/2016/08/26/170152
個別株ではないですが、株式投資の新記事を書きました。
「このゲーム(積立投資)には必勝法がある -持株会ゲーム-」
https://qiita.com/Kuma_T/items/667e1b0178a889cc42f7